Download presentation
Presentation is loading. Please wait.

1
Advanced Multimedia Text Retrieval/Classification Tamara Berg

2
Announcements Matlab basics lab – Feb 7 Matlab string processing lab – Feb 12 If you are unfamiliar with Matlab, attendance at labs is crucial!

3
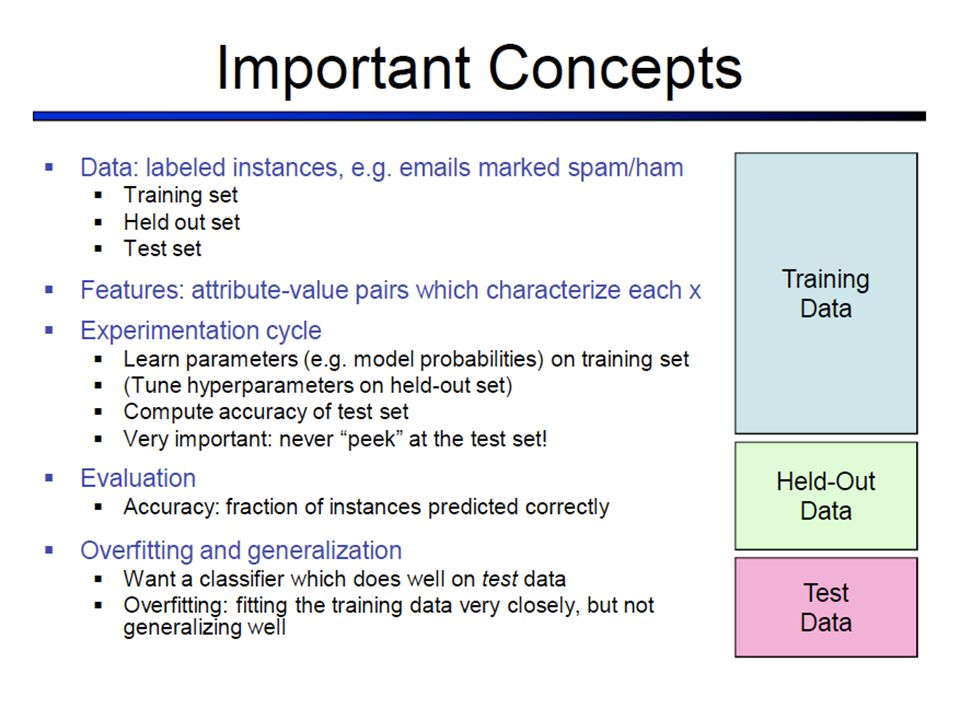
Slide from Dan Klein

5
Today!

6
What does categorization/classification mean?

7
Slide from Dan Klein

11
Slide from Min-Yen Kan

12
Slide from Dan Klein http://yann.lecun.com/exdb/mnist/index.html

13
Slide from Dan Klein

14
Slide from Min-Yen Kan

17
Machine Learning - how to select a model on the basis of data / experience Learning parameters (e.g. probabilities) Learning structure (e.g. dependencies) Learning hidden concepts (e.g. clustering)
 Learning structure (e.g. dependencies) Learning hidden concepts (e.g. clustering).")
19
Representing Documents

20
Document Vectors

21
Represent document as a “bag of words”

22
Example Doc1 = “the quick brown fox jumped” Doc2 = “brown quick jumped fox the”

23
Example Doc1 = “the quick brown fox jumped” Doc2 = “brown quick jumped fox the” Would a bag of words model represent these two documents differently?

24
Document Vectors Documents are represented as “bags of words” Represented as vectors when used computationally Each vector holds a place for every term in the collection Therefore, most vectors are sparse Slide from Mitch Marcus

25
Document Vectors Documents are represented as “bags of words” Represented as vectors when used computationally Each vector holds a place for every term in the collection Therefore, most vectors are sparse Slide from Mitch Marcus Lexicon – the vocabulary set that you consider to be valid words in your documents. Usually stemmed (e.g. running->run)
.")
26
Document Vectors: One location for each word. novagalaxy heat h’wood filmroledietfur 10 5 3 5 10 10 8 7 9 10 5 10 10 9 10 5 7 9 6 10 2 8 7 5 1 3 ABCDEFGHIABCDEFGHI “Nova” occurs 10 times in text A “Galaxy” occurs 5 times in text A “Heat” occurs 3 times in text A (Blank means 0 occurrences.) Slide from Mitch Marcus
 Slide from Mitch Marcus.")
27
Document Vectors: One location for each word. novagalaxy heat h’wood filmroledietfur 10 5 3 5 10 10 8 7 9 10 5 10 10 9 10 5 7 9 6 10 2 8 7 5 1 3 ABCDEFGHIABCDEFGHI “Nova” occurs 10 times in text A “Galaxy” occurs 5 times in text A “Heat” occurs 3 times in text A (Blank means 0 occurrences.) Slide from Mitch Marcus
 Slide from Mitch Marcus.")
28
Document Vectors novagalaxy heat h’wood filmroledietfur 10 5 3 5 10 10 8 7 9 10 5 10 9 10 5 7 9 6 10 2 8 7 5 1 3 ABCDEFGHIABCDEFGHI Document ids Slide from Mitch Marcus

29
Vector Space Model Documents are represented as vectors in term space Terms are usually stems Documents represented by vectors of terms A vector distance measures similarity between documents Document similarity is based on length and direction of their vectors Terms in a vector can be “weighted” in many ways Slide from Mitch Marcus

30
Document Vectors novagalaxy heat h’wood filmroledietfur 10 5 3 5 10 10 8 7 9 10 5 10 9 10 5 7 9 6 10 2 8 7 5 1 3 ABCDEFGHIABCDEFGHI Document ids Slide from Mitch Marcus

31
Comparing Documents

32
Similarity between documents A = [10 5 3 0 0 0 0 0]; G = [5 0 7 0 0 9 0 0]; E = [0 0 0 0 0 10 10 0];
![Similarity between documents A = [ ]; G = [ ]; E = [ ];](http://images.slideplayer.com/19/5738183/slides/slide_32.jpg "Similarity between documents A = [ ]; G = [ ]; E = [ ];")
33
Similarity between documents A = [10 5 3 0 0 0 0 0]; G = [ 5 0 7 0 0 9 0 0]; E = [ 0 0 0 0 0 10 10 0]; Treat the vectors as binary = number of words in common. Sb(A,G) = ? Sb(A,E) = ? Sb(G,E) = ? Which pair of documents are the most similar?
![Similarity between documents A = [ ]; G = [ ]; E = [ ]; Treat the vectors as binary = number of words in common.](http://images.slideplayer.com/19/5738183/slides/slide_33.jpg "Sb(A,G) = . Sb(A,E) = . Sb(G,E) = . Which pair of documents are the most similar .")
34
Similarity between documents A = [10 5 3 0 0 0 0 0]; G = [5 0 7 0 0 9 0 0]; E = [0 0 0 0 0 10 10 0]; Sum of Squared Distances (SSD) = SSD(A,G) = ? SSD(A,E) = ? SSD(G,E) = ?
![Similarity between documents A = [ ]; G = [ ]; E = [ ]; Sum of Squared Distances (SSD) = SSD(A,G) = .](http://images.slideplayer.com/19/5738183/slides/slide_34.jpg "SSD(A,E) = . SSD(G,E) = .")
35
Similarity between documents A = [10 5 3 0 0 0 0 0]; G = [5 0 7 0 0 9 0 0]; E = [0 0 0 0 0 10 10 0]; Angle between vectors: Cos(θ) = Dot Product: Length (Euclidean norm):
![Similarity between documents A = [ ]; G = [ ]; E = [ ]; Angle between vectors: Cos(θ) = Dot Product: Length (Euclidean norm):](http://images.slideplayer.com/19/5738183/slides/slide_35.jpg "Similarity between documents A = [ ]; G = [ ]; E = [ ]; Angle between vectors: Cos(θ) = Dot Product: Length (Euclidean norm):")
36
Some words give more information than others Does the fact that two documents both contain the word “the” tell us anything? How about “and”? Stop words (noise words): Words that are probably not useful for processing. Filtered out before natural language is applied. Other words can be more or less informative. No definitive list but might include things like: http://www.dcs.gla.ac.uk/idom/ir_resources/linguistic_utils/stop_words
: Words that are probably not useful for processing. Filtered out before natural language is applied. Other words can be more or less informative. No definitive list but might include things like:")
37
Some words give more information than others Does the fact that two documents both contain the word “the” tell us anything? How about “and”? Stop words (noise words): Words that are probably not useful for processing. Filtered out before natural language is applied. Other words can be more or less informative. No definitive list but might include things like: http://www.dcs.gla.ac.uk/idom/ir_resources/linguistic_utils/stop_words
: Words that are probably not useful for processing. Filtered out before natural language is applied. Other words can be more or less informative. No definitive list but might include things like:")
38
Classifying Documents

39
Slide from Min-Yen Kan Here the vector space is illustrated as having 2 dimensions. How many dimensions would the data actually live in?

40
Slide from Min-Yen Kan Query document – which class should you label it with?

41
Classification by Nearest Neighbor Classify the test document as the class of the document “nearest” to the query document (use vector similarity to find most similar doc) Slide from Min-Yen Kan
 Slide from Min-Yen Kan")
42
Classification by kNN Classify the test document as the majority class of the k documents “nearest” to the query document. Slide from Min-Yen Kan

49
What are the features? What’s the training data? Testing data? Parameters? Classification by kNN

Similar presentations































>")