Download presentation
Presentation is loading. Please wait.

1
ÓC-DAC Noida’2004 Efforts in Language & Speech Technology Natural Language Processing Lab Centre for Development of Advanced Computing (Ministry of Communications & Information Technology) ‘Anusandhan Bhawan’, C 56/1 Sector 62, Noida – 201 307, India karunesharora@cdacnoida.com
 ‘Anusandhan Bhawan’, C 56/1 Sector 62, Noida – , India")
2
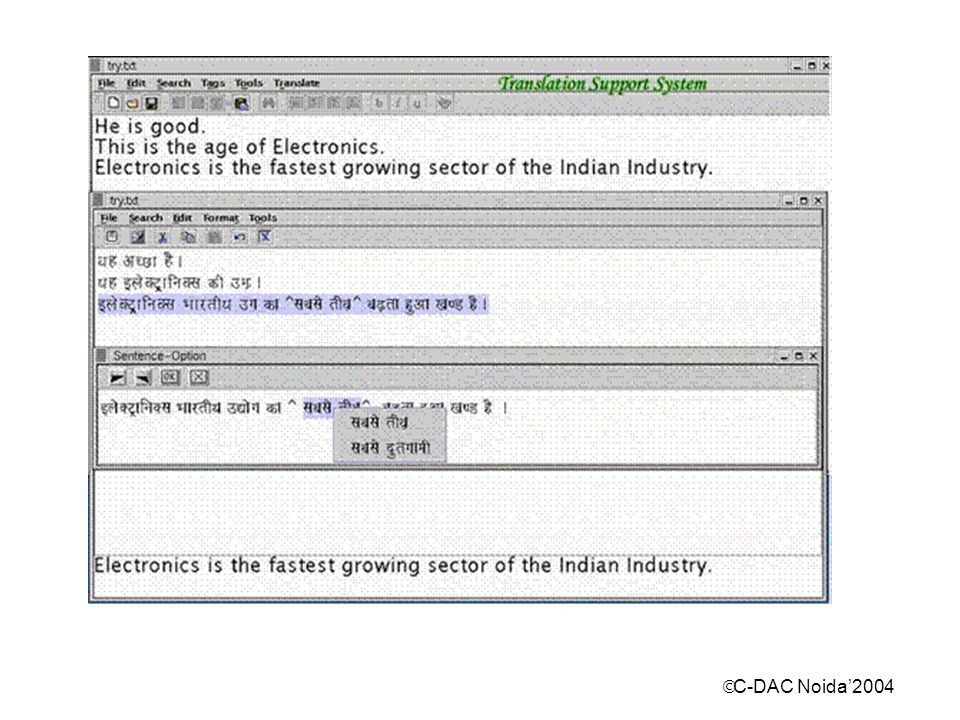
ÓC-DAC Noida’2004 Technology : Angla Bharati (Rule base) developed by IIT Kanpur. System developed jointly by IIT,Kanpur and CDAC Noida Operating system support : LINUX/ WINDOWS Performance : 85% correct parsing, 60% correct translation Embedded Text Editor,Pre Processor and Post editor Lexicon :25,000 root words Translation Support System

3
ÓC-DAC Noida’2004 Translation Support System (English to Hindi) Morphological Analyzer Lexical Dictionary Pattern Directed Parsing Parsing CORPUS CORPUS Rule Base Pseudo Language Output Hindi Text Generator Hindi Text Generator Post Editor Post Editor English Sentence
 Morphological Analyzer Lexical Dictionary Pattern Directed Parsing Parsing CORPUS CORPUS Rule Base Pseudo Language Output Hindi Text Generator Hindi Text Generator Post Editor Post Editor English Sentence")
4
ÓC-DAC Noida’2004

6
Test suite for Translation Support Systems

7
ÓC-DAC Noida’2004 Knowledge Management Parallel Corpus & Tools

8
ÓC-DAC Noida’2004 Gyan Nidhi : Parallel Corpus ‘GyanNidhi’ which stands for ‘Knowledge Resource’ is parallel in 12 Indian languages, a project sponsored by TDIL, DIT, MC &IT, Govt of India

9
ÓC-DAC Noida’2004 Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus What it is? The multilingual parallel text corpus contains the same text translated in more than one language. What Gyan Nidhi contains? GyanNidhi corpus consists of text in English and 11 Indian languages (Hindi, Punjabi, Marathi, Bengali, Oriya, Gujarati, Telugu, Tamil, Kannada, Malayalam, Assamese). It aims to digitize 1 million pages altogether containing at least 50,000 pages in each Indian language and English. National Book Trust India Sahitya Akademi Navjivan Publishing House Publications Division SABDA, Pondicherry Source for Parallel Corpus
. It aims to digitize 1 million pages altogether containing at least 50,000 pages in each Indian language and English. National Book Trust India Sahitya Akademi Navjivan Publishing House Publications Division SABDA, Pondicherry Source for Parallel Corpus.")
10
ÓC-DAC Noida’2004 GyanNidhi Block Diagram

11
ÓC-DAC Noida’2004 Platform : Windows Data Encoding : XML, UNICODE Portability of Data : Data in XML format supports various platforms Applications of GyanNidhi Automatic Dictionary extraction Creation of Translation memory Example Based Machine Translation (EBMT) Language research study and analysis Language Modeling Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus
 Language research study and analysis Language Modeling Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus")
12
ÓC-DAC Noida’2004 Tools: Prabandhika: Corpus Manager Categorisation of corpus data in various user-defined domains Addition/Deletion/Modification of any Indian Language data files in HTML / RTF / TXT / XML format. Selection of languages for viewing parallel corpus with data aligned up to paragraph level Automatic selection and viewing of parallel paragraphs in multiple languages –Abstract and Metadata –Printing and saving parallel data in Unicode format

13
ÓC-DAC Noida’2004 Sample Screen Shot : Prabandhika

14
ÓC-DAC Noida’2004 Tools: Vishleshika : Statistical Text Analyzer Vishleshika is a tool for Statistical Text Analysis for Hindi extendible to other Indian Languages text It examines input text and generates various statistics, e.g.: Sentence statistics Word statistics Character statistics Text Analyzer presents analysis in Textual as well as Graphical form.

15
ÓC-DAC Noida’2004 Sample output: Character statistics Above Graph shows that the distribution is almost equal in Hindi and Nepali in the sample text. Most frequent consonants in the Hindi Most frequent consonants in the Nepali Results also show that these six consonants constitute more than 50% of the consonants usage.

16
ÓC-DAC Noida’2004 Vishleshika: Word and sentence Statistics

17
ÓC-DAC Noida’2004 Speech Technology and tools

18
ÓC-DAC Noida’2004 Vishleshika Statistical AnalysisTool Gyan Nidhi Corpus Phonetically Rich sentence set Manual Verification and Editing Studio Recording by Professionals Segmentation and labeling using Praat / Emulabel XML Meta Data Creation Annotated Speech Corpora for Hindi, Punjabi and Marathi languages

19
ÓC-DAC Noida’2004

20
ModuleDescription TTS Shell TTS shell is multi-threaded interface that call different TTS modules and returns messages that user can process to generate different events. Voice Builder It is a utility that helps in building syllable database. It reduces the space utilization and helps in performing fast search. Query Tool for Voice Builder Tool for reading voice file and retrieving the information about the “UNIT” from the file i.e.: Wave Data. Text Parser This unit breaks the Normalized text into logical units like: Sentences, Words and Syllables etc Prosody Matching & Syllable concatenation “PSOLA” technique for smooth joining of speech samples is being followed Synthesizer Function: For writing wave data directly onto a sound card or wave file. Modules under TTS

21
ÓC-DAC Noida’2004 Other Areas of expertise OCR for Devanagri Script Digital Library for Indian languages Word Processing tools like Spell Checker, Transliteration, Terminology Development, Document analysis, Font converters Indian Language eContent Creation

22
ÓC-DAC Noida’2004 Areas for future work Machine Translation Standardization Lexware Database design Working on the global approach ‘BhashaSetu’ which is a amalgamation of different approaches to squeeze the best of each approach Development of Translation system Test Bed Knowledge Management Automatic Text Summarization tool for Hindi and other Indian languages Standardization of Parts of Speech TagSet for Hindi extendible to other Indian languages Parts of Speech Tagger development for Indian languages Automated Terminology Development tools Sentence alignment tool for Indian languages Development of manually tagged parallel corpus up to word level Speech Technology Speech to Speech Translation System Development of Semi-automated speech annotation tools

23
ÓC-DAC Noida’2004 Thank You

Similar presentations