Download presentation
Presentation is loading. Please wait.

1
Lecture 11 Chapter 6. Correlation and Linear Regression

2
6.1 Introduction This chapter is concerned with relationships between continuous variables. Example (see Handout 11) During the 1950s radioactive water leaked into the Columbia river in Washington DC. Data were collected on an exposure index (X), and the cancer mortality rate (Y) (deaths per 100,000 per year) for the years 1959-1964, for each of nine counties downstream: Exposure (x): 8.3 6.4 3.4 3.8 2.6 11.6 1.2 2.5 1.6 Mortality (y): 210 180 130 170 130 210 120 150 140
 During the 1950s radioactive water leaked into the Columbia river in Washington DC. Data were collected on an exposure index (X), and the cancer mortality rate (Y) (deaths per 100,000 per year) for the years , for each of nine counties downstream: Exposure (x): Mortality (y):")
3
Both the variables X and Y are measurements on a continuous scale. We are interested in how these two variables are related, or associated. We are interested in how these two variables are related, or associated. As usual, the sensible thing to do first is to have a look at the data. The best thing to do here is to plot the mortality rate against the exposure index....

5
The plot suggests that there is a clear relationship (association) between the mortality rate and the exposure index. The relationship looks approximately linear (like a straight line). In this chapter we do two things: 1. Use a measure called correlation to describe the strength of the association between two variables. 2. Use a method called linear regression to model the relationship between two variables which are associated in a way which is approximately linear.
. In this chapter we do two things: 1. Use a measure called correlation to describe the strength of the association between two variables. 2. Use a method called linear regression to model the relationship between two variables which are associated in a way which is approximately linear..")
6
6.2 Correlation There are a several different measures of association in usage, but we will only consider the most common, which is called Pearson’s product moment correlation coefficient or more briefly the sample linear correlation coefficient or just the Pearson correlation. It is usually denoted by the letter r.

7
Additional Notes (Slide 1 of 2) The value of r always lies between -1 and +1; Values of r near to +1 indicate a strong positive linear relationship; Values of r near to -1 indicate a strong negative linear relationship; Values of r near to 0 indicate there is very little linear relationship.
 The value of r always lies between -1 and +1; Values of r near to +1 indicate a strong positive linear relationship; Values of r near to -1 indicate a strong negative linear relationship; Values of r near to 0 indicate there is very little linear relationship.")
8
Additional Notes (Slide 2 of 2) Let’s see what Minitab tells us about the Pearson correlation for our example above. We use: Stat>Basic Statistics>Correlation... Minitab tells us two things: the Pearson correlation is r = 0.917 the P-value is 0.000

9
Note that this correlation is close to +1, indicating a strong positive linear relationship. What about the p-value? This is the result of the hypothesis test of the null hypothesis: H 0 : The linear correlation in the population is zero. Our value of p = 0.000 indicates that we reject the null hypothesis. There does appear to be a strong positive linear relationship between exposure and mortality.

10
The correlation coefficient r is a very useful summary measure, but it us often misused. Some points to remember are as follows: 1.A high correlation does not necessarily imply a a cause-and-effect relationship. 2. Although a value of r close to 1 does indicate a strong positive linear association, a linear relationship is not always the most appropriate. Always produce a plot of y against x. 3. A value close to zero indicates no linear relationship. That does not necessarily mean there is no relationship!

11
For the data plotted below, r = 0.020, and the p-value is 0.854. This correctly identifies there is no linear relationship, but there clearly is a relationship!

12
6.3 Simple Linear Regression The correlation coefficient tells us about the strength of a linear relationship, but it doesn’t allow us to do things like make predictions about new data. For this we need a model for the data. If we think there is an approximately linear relationship, we use the equation of a straight line, which relates X and Y: Y = α + βX Y = α + βX Here the values of α (alpha) and β (beta) are the intercept and the slope of the straight line respectively. The slope, β, is usually of much more interest, because it tells us how Y changes with X.
 and β (beta) are the intercept and the slope of the straight line respectively. The slope, β, is usually of much more interest, because it tells us how Y changes with X..")
13
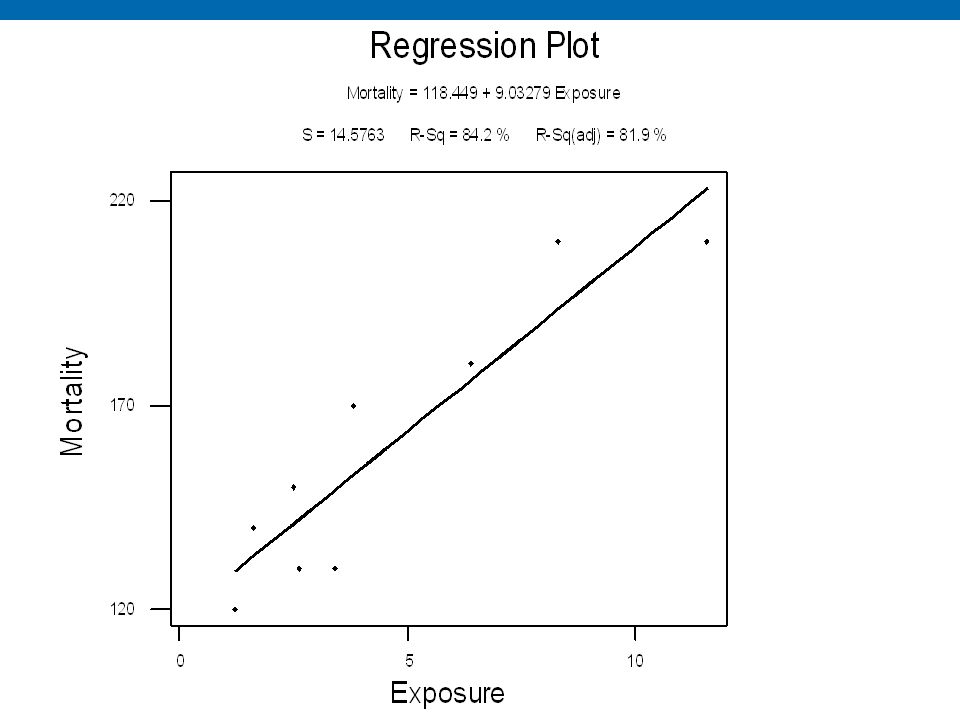
Since we don’t expect the data to lie exactly on a straight line, we always add a random error component, ε (epsilon), so the equation becomes: Y = α + βX + ε(Equation 1) Equation 1 is the equation of a simple linear regression. In order to use it to model our data, we need to choose the values of α and β which work best. E.g. for the exposure-mortality data, we might obtain....

15
Notice that in the plot above, α has been chosen as 118.4, and β as 9.03. This indicates that in our model, the mortality rate increases by 9.03 for every unit increase in the exposure index, and the mortality rate when the exposure index is zero is 118.4. But how were these values chosen? The usual criterion, and the one used above is to use the least squares estimates for α and β...

16
We obtain these in Minitab using: Stat>Regression>Regression... if we want the equation etc., and... Stat>Regression>Fitted Line Plot... Stat>Regression>Fitted Line Plot... if we want the graph with the fitted line superimposed.

Similar presentations