Download presentation
Presentation is loading. Please wait.

1
QBM117 Business Statistics
Descriptive Statistics Descriptive Measures for Grouped Data Percentiles and Box Plots

2
Objectives To learn how to calculate the approximate mean and standard deviation for grouped data. To introduce percentiles as another descriptive measure. To introduce the box plot as another graphical technique.

3
Descriptive Measures for Grouped Data
In most cases, measures if locations and variability are computed by using the individual data values. Sometimes we only have data that have been grouped into a frequency distribution, and we do not have access to the raw data. It is therefore useful to be able to calculate approximate descriptive measures directly from a frequency distribution.

4
Approximate Mean and Standard Deviation for Grouped Data
The mean and the standard deviation are the most widely used descriptive measures. And so we will look at how to calculate the approximate mean and standard deviation for grouped data. Keep in mind that by grouping the data, we have lost information, and the descriptive measures obtained from the grouped data will only approximate those of the ungrouped data.

5
Calculating the Approximate Mean and Standard Deviation for Grouped Data
You can calculate the approximate mean and standard deviation for grouped data using the statistics mode on your calculator. We start by calculating the midpoint for each of the classes of the the frequency distribution.

6
We then assume that each observation in a class is assumed to be equal to the midpoint of that class. We then need to enter the data into your calculator and obtain the mean and standard deviation. This will be demonstrated by example.

7
Example 1 Revisit example 5 from week 1 lecture 3 (Exercise 2.41 from text). The number of items returned to a leading Brisbane retailer by its customers were recorded for 25 days.

8
The frequency distribution for the data is given below:
Number of items Frequency >5 up to and including 10 5 >10 up to and including 15 3 >15 up to and including 20 9 >20 up to and including 25 7 >25 up to and including 30 1

9
We now need to calculate the midpoint of each class.
Number of items Midpoint Frequency >5 up to and including 10 7.5 5 >10 up to and including 15 12.5 3 >15 up to and including 20 17.5 9 >20 up to and including 25 22.5 7 >25 up to and including 30 27.5 1

10
We now need to enter the data into the calculator.
Enter the value 7.5 into stats mode on your calculator 5 times. New Casios: SHIFT ; M+ Older Casios: X M+ New Sharps: nf F , M+

11
And then enter the value 12.5 in 3 times.
And then enter the value 27.5 in once.

12
Once you have entered the data in, check to see that you have 25 data values.
Then obtain the mean and standard deviation of these values. mean = 16.7 standard deviation = 5.89 (2d.p.) Hence the approximate mean and standard deviation for the grouped data are 16.7 and 5.89 respectively. Note that the true mean and standard deviation for the ungrouped data are 17 and 6.20 (2d.p.) respectively.
 Hence the approximate mean and standard deviation for the grouped data are 16.7 and 5.89 respectively. Note that the true mean and standard deviation for the ungrouped data are 17 and 6.20 (2d.p.) respectively.")
13
Measures of Relative Standing
Measures of central tendency and dispersion are important. However they are not the only numerical measures that can be used to describe a data set. Measures of relative standing, or order statistics, give information about the position of an observation in the sample.

14
Median We have already looked at a measure of relative standing, the median, which is also a measure of central tendency. Recall that the median is the middle value when the data are arranged in order. Hence the median divides the data set into halves

15
Percentiles It is useful in some situations to know what data value has a certain percentage of the observations above or below it. This measure is know as the percentile of the data. The pth percentile is the value that has at most p% of the observations less than that value, and at most (100-p)% of the observations greater than that value.
% of the observations greater than that value.")
16
Quartiles We have special names for the 25th, 50th and 75th percentiles. These three measures divide the data into quartiles and hence are called quartiles. The 25th percentile is known as the lower quartile, Q1. The 50th percentile is known as the middle quartile, Q2 but more commonly called the median, M. The 75th percentile is known as the upper quartile, Q3.

17
Calculating Percentiles
Arrange the data in ascending order We find the position of the pth percentile by calculating i = (p/100) x n . If i is not an integer, round up. The next integer greater than i denotes the position of the pth percentile. If i is an integer, the pth percentile is the average of the data values in positions i and i+1.
 x n . If i is not an integer, round up. The next integer greater than i denotes the position of the pth percentile. If i is an integer, the pth percentile is the average of the data values in positions i and i+1.")
18
Example 3.14 from text Calculate the quartiles for the set of measurements First we need to order the data

19
The lower quartile is the 25th percentile.
p = 25 n = 15 i = (p/100) x n = (25/100) x 15 = 3.75 i = 3.75 is not an integer and so we round up to 4. The lower quartile is the 4th value. Hence the lower quartile is 5.
 x n. = (25/100) x 15. = i = 3.75 is not an integer and so we round up to 4. The lower quartile is the 4th value Hence the lower quartile is 5.")
20
The median (middle quartile) is the 50th percentile.
p = 50 n = 15 i = (p/100) x n = (50/100) x 15 = 7.5 i = 7.5 is not an integer and so we round up to 8. The median is the 8th value. Hence the median is 12.
 x n. = (50/100) x 15. = 7.5. i = 7.5 is not an integer and so we round up to 8. The median is the 8th value Hence the median is 12.")
21
The upper quartile is the 75th percentile.
p = 75 n = 15 i = (p/100) x n = (75/100) x 15 = 11.25 i = is not an integer and so we round up to 12. The upper quartile is the 12th value. Hence the upper quartile is 21.
 x n. = (75/100) x 15. = i = is not an integer and so we round up to 12. The upper quartile is the 12th value Hence the upper quartile is 21.")
22
Calculating Percentiles in Excel
To calculate percentiles in Excel go to Tools Data Analysis Descriptive Statistics To produce the median select Summary Statistics. To produce the lower quartile select Kth Smallest and enter in the position of the lower quartile. To produce the upper quartile select Kth Largest and enter in the position of the upper quartile from the largest value.

23
Five-Number Summary In a five-number summary, the following five numbers are used to summarise the data: - Smallest data value - Lower quartile - Median - Upper Quartile - Largest data value

24
Example 3.14 revisited The five-number summary for the set of measurements in Example 3.14 is Min = 2 Q1 = 5 M = 12 Q3 = 21 Max = 30

25
Interquartile Range (IQR)
The interquartile range is the difference between the upper and lower quartiles. IQR = Q3 - Q1 The interquartile range is the range of the middle 50% of the data. It is a measure of dispersion that is not sensitive to outliers.

26
Example 3.14 revisited Calculate the inter quartile range for the set of measurements in Example 3.14. Q1 = 5 Q3 = 21 IQR = Q3 - Q1 = 21 – 5 = 16

27
Box Plots Now that we have introduced quartiles, we can present one more graphical technique for quantitative data. A box plot is a graphical display of the five-number summary. It can be used to identify the central location, spread and shape of the data and identifies any possible outliers.

28
Constructing a Box Plot
Order that data. The most efficient way to do this is to construct a stem and leaf display. Calculate the five-number summary. Draw a box with the ends of the box located at the lower and upper quartiles. Draw a vertical line I the box at the location of the median.

29
Identify any outliers. An outlier is any value located at a distance of more than 1.5 x IQR from the box. Draw lines extending from the box to the smallest and largest values within 1.5 x IQR , i.e. the most extreme value that is not an outlier. These lines are called whiskers. Plot any outliers individually.

30
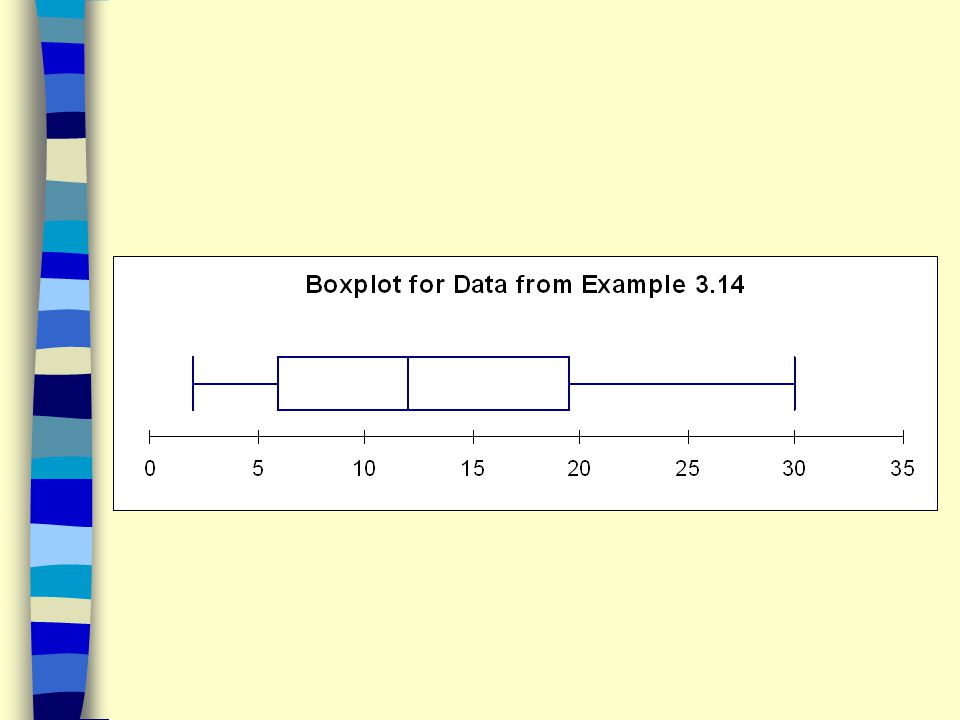
Example 3.14 revisited Construct a box plot for the set of measurements The five-number summary is Min = 2 Q1 = 5 M = Q3 = Max = 30 The inter quartile range is IQR = 16

31
1.5 x IQR = 1.5 X 16 = 24 Q1 – 1.5 x IQR = 5 – 24 = -19 Q x IQR = = 45 There are no data values less than -19 or greater than 45. Therefore there are no outliers.

33
Constructing Box Plots in Excel
There are instructions for constructing a box plot In Excel on page 96 of the text (pg 94 abridged). You will need to use Data Analysis Plus – the macros that come on the disk that accompanies the text.
. You will need to use Data Analysis Plus – the macros that come on the disk that accompanies the text.")
34
Example 3.14 revisited Construct a box plot in Excel for the set of measurements in Example

35
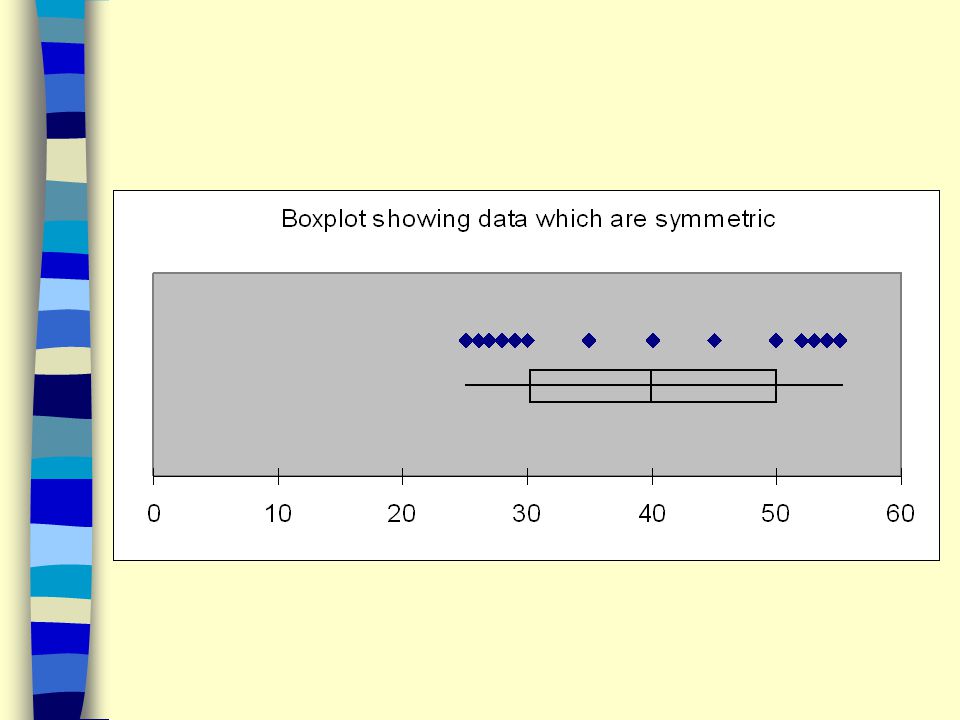
Using the Box Plot to Identify Skewness
If the data set is perfectly symmetric then the box plot will be symmetric. The length of the left whisker will equal the length of the right whisker. The median will divide the box in half.

37
If the data is positively skewed,
the length of the right whisker will be greater than the length of the left whisker, and/or the portion of the box to the right of the median will be greater than the portion of the box to the left of the median.

39
If the data is negatively skewed,
the length of the left whisker will be greater than the length of the right whisker, and/or the portion of the box to the left of the median will be greater than the portion of the box to the right of the median.

41
Outliers As well as providing a graphical summary of a data set, a box plot is useful for identifying outliers. When presenting and analysing data it is important to identify and review outliers. An outlier may be an observation that has been incorrectly recorded. If so, it needs to be corrected before further analysis.

42
An outlier may also be an observation that was incorrectly included in the data set. If so, it can be removed. An outlier may just be an unusual observation that has been recorded correctly and does belong to the data set. In such cases the observation should remain.

43
Using Box Plots to Compare Data Sets
We can use box plots to compare several data sets by constructing a box plot for each data set and displaying the box plots on the same scale. We can then compare the centre, spread and shape of the distributions of the different data sets. If the box plots are not on the same scale, more care needs to be taken when comparing the distributions. .

44
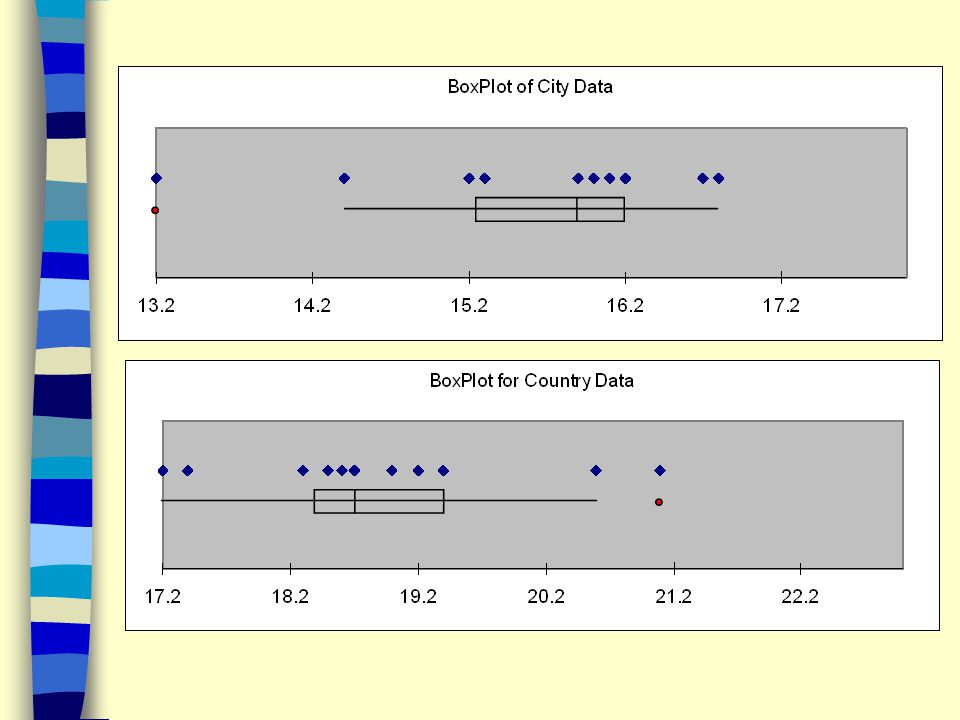
Example In automobile mileage and gasoline-consumption testing, 13 automobiles were road tested for 300 miles in both city and country driving conditions. The following data were recorded for miles-per-gallon performance. City Country Construct box plots for both data sets and compare the performance for city and country driving.

47
Reading for next lecture
Chapter 4 Sections 4.1 – 4.3 Exercises 3.47 3.54 3.57 3.59 3.61

Similar presentations









 Then count the number of values.>")












