Download presentation
Presentation is loading. Please wait.

1
Class of 28 th August

2
Announcements Lisp assignment deadline extended (will take it until 6 th September (Thursday). In class. Rao away on 11 th and 13 th. –Makeup classes next week (probably replayed in the class later) Lisp intro continuation?
 Lisp intro continuation .")
3
Review

4
This one already assumes that the “sensors features” mapping has been done! Even basic survival needs state information.. Review

7
Representation Mechanisms: Logic (propositional; first order) Probabilistic logic Learning the models Search Blind, Informed Inference Logical resolution Bayesian inference How the course topics stack up…
 Probabilistic logic Learning the models Search Blind, Informed Inference Logical resolution Bayesian inference How the course topics stack up…")
15
Class of 30 th August

16
Announcements Makeup class (Will be on CSP) -9-11am Wed (GWC 308) OR -1:30-3:30pm Wed (GWC 110) -Do you want replay of the tape in class or put the tape in Media library?
 -9-11am Wed (GWC 308) OR -1:30-3:30pm Wed (GWC 110) -Do you want replay of the tape in class or put the tape in Media library")
22
What happens when the domain Is inaccessible?

23
Search in Multi-state (inaccessible) version
 version")
29
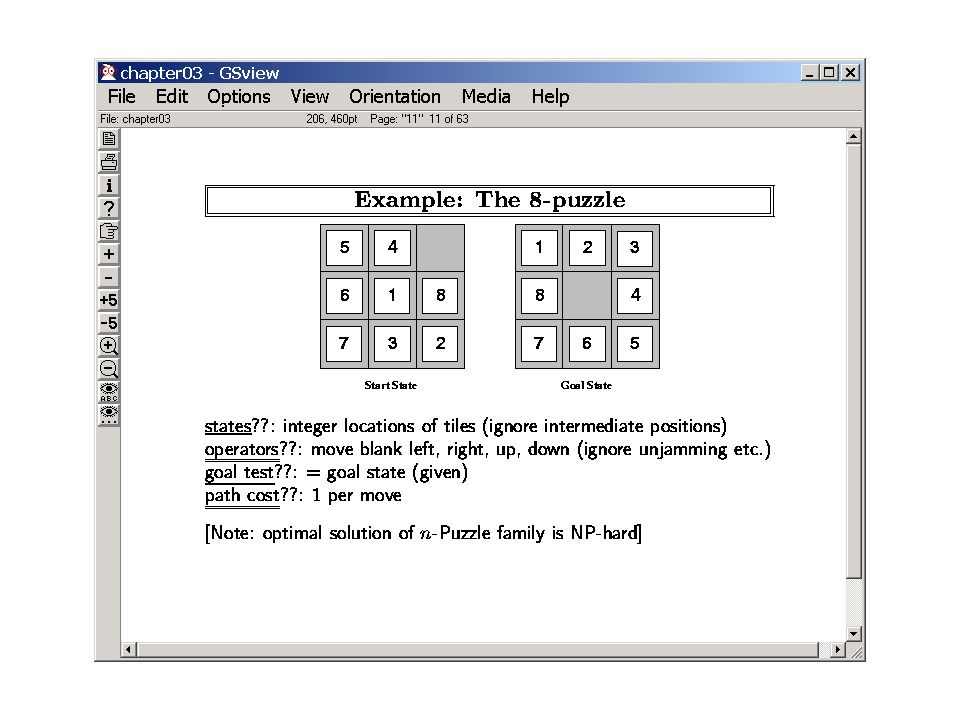
General Search ??

38
Breadth first search on a uniform tree of b=10 Assume 1000nodes expanded/sec 100bytes/node

47
Class of 4 th September

48
Announcements Makeup class (Will be on CSP) -9-11am Wed (GWC 308) -_CSP lecture -1:30-3:30pm Wed (GWC 110) – Project 1 lecture
 -9-11am Wed (GWC 308) -_CSP lecture -1:30-3:30pm Wed (GWC 110) – Project 1 lecture")
50
Explained This without Showing this slide

51
A B C DFS: BFS: IDDFS: A,B,C,D,G A,B,G (A), (A, B, G) D G Note that IDDFS can do fewer Expansions than DFS on a graph Shaped search space.
, (A, B, G) D G Note that IDDFS can do fewer Expansions than DFS on a graph Shaped search space.")
52
Explained the techniques for handling Repeated node expansion Main points: --repeated expansions is a bigger issue for DFS than for BFS --Trying to remember all previously expanded nodes and comparing the new nodes with them is infeasible --Space becomes exponential --duplicate checking can also be exponential --Partial reduction in repeated expansion can be done by --Checking to see if any children of a node n have the same state as the parent of n -- Checking to see if any children of a node n have the same state as any ancestor of n (at most d ancestors for n—where d is the depth of n)
")
53
A B C D G 9 1 1 1 2 Uniform Cost Search No:A (0) N1:B(1)N2:G(9) N3:C(2)N4:D(3)N5:G(5) Completeness? Optimality? Branch & Bound argument (as long as all op costs are +ve) Efficiency? (as bad as blind search..) A B C D G 9 0.1 25 Bait & Switch Graph Proof of optimality: next page.
 Efficiency. (as bad as blind search..) A B C D G Bait & Switch Graph Proof of optimality: next page..")
54
“Informing” Uniform search… A B C D G 9 0.1 25 Bait & Switch Graph No:A (0) N1:B(.1)N2:G(9) N3:C(.2)N4:D(.3)N5:G(25.3) Would be nice if we could tell that N2 is better than N1 --Need to take not just the distance until now, but also distance to goal --Computing true distance to goal is as hard as the full search --So, try “bounds” h(n) prioritize nodes in terms of f(n) = g(n) +h(n) two bounds: h1(n) <= h*(n) <= h2(n) Which guarantees optimality? --h1(n) <= h2(n) <= h*(n) Which is better function? Admissibility Informedness
 <= h2(n) <= h*(n) Which is better function. Admissibility Informedness.")
55
Class of 6 th September

56
“Informing” Uniform search… A B C D G 9 0.1 25 Bait & Switch Graph No:A (0) N1:B(.1)N2:G(9) N3:C(.2)N4:D(.3)N5:G(25.3) Would be nice if we could tell that N2 is better than N1 --Need to take not just the distance until now, but also distance to goal --Computing true distance to goal is as hard as the full search --So, try “bounds” h(n) prioritize nodes in terms of f(n) = g(n) +h(n) two bounds: h1(n) <= h*(n) <= h2(n) Which guarantees optimality? --h1(n) <= h2(n) <= h*(n) Which is better function? Admissibility Informedness
 <= h2(n) <= h*(n) Which is better function. Admissibility Informedness.")
58
h* h1 h4 h5 Admissibility/Informedness h2 h3 Max(h2,h3)
")
59
Proof of Optimality of Uniform search Proof of optimality: Let N be the goal node we output. Suppose there is another goal node N’ We want to prove that g(N’) >= g(N) Suppose this is not true. i.e. g(N’) < g(N) --Assumption A1 When N was picked up for expansion, Either N’ itself, or some ancestor of N’, Say N’’ must have been on the search queue If we picked N instead of N’’ for expansion, It was because g(N) <= g(N’’) ---Fact f1 But g(N’) = g(N’’) + dist(N’’,N’) So g(N’) >= g(N’’) So from f1, we have g(N) <= g(N’) But this contradicts our assumption A1 No N N’ N’’ Holds only because dist(N’’,N’) >= 0 This will hold if every operator has +ve cost
 >= g(N) Suppose this is not true. i.e. g(N’) < g(N) --Assumption A1 When N was picked up for expansion, Either N’ itself, or some ancestor of N’, Say N’’ must have been on the search queue If we picked N instead of N’’ for expansion, It was because g(N) <= g(N’’) ---Fact f1 But g(N’) = g(N’’) + dist(N’’,N’) So g(N’) >= g(N’’) So from f1, we have g(N) <= g(N’) But this contradicts our assumption A1 No N N’ N’’ Holds only because dist(N’’,N’) >= 0 This will hold if every operator has +ve cost.")
60
Proof of Optimality of A* search Proof of optimality: Let N be the goal node we output. Suppose there is another goal node N’ We want to prove that g(N’) >= g(N) Suppose this is not true. i.e. g(N’) < g(N) --Assumption A1 When N was picked up for expansion, Either N’ itself, or some ancestor of N’, Say N’’ must have been on the search queue If we picked N instead of N’’ for expansion, It was because f(N) <= f(N’’) ---Fact f1 i.e. g(N) + h(N) <= g(N’’) + h(N’’) Since N is goal node, h(N) = 0 So, g(N) <= g(N’’) + h(N’’) But g(N’) = g(N’’) + dist(N’’,N’) Given h(N’) <= h*(N’’) = dist(N’’,N’) (lower bound) So g(N’) = g(N’’)+dist(N’’,N’) >= g(N’’) +h(N’’) ==Fact f2 So from f1 and f2 we have g(N) <= g(N’) But this contradicts our assumption A1 No N N’ N’’ Holds only because h(N’’) is a lower bound on dist(N’’,N’)
 >= g(N) Suppose this is not true. i.e. g(N’) < g(N) --Assumption A1 When N was picked up for expansion, Either N’ itself, or some ancestor of N’, Say N’’ must have been on the search queue If we picked N instead of N’’ for expansion, It was because f(N) <= f(N’’) ---Fact f1 i.e. g(N) + h(N) <= g(N’’) + h(N’’) Since N is goal node, h(N) = 0 So, g(N) <= g(N’’) + h(N’’) But g(N’) = g(N’’) + dist(N’’,N’) Given h(N’) <= h*(N’’) = dist(N’’,N’) (lower bound) So g(N’) = g(N’’)+dist(N’’,N’) >= g(N’’) +h(N’’) ==Fact f2 So from f1 and f2 we have g(N) <= g(N’) But this contradicts our assumption A1 No N N’ N’’ Holds only because h(N’’) is a lower bound on dist(N’’,N’).")
61
It will not expand Nodes with f >f* (f* is f-value of the Optimal goal)
")
64
Where do heuristics (bounds) come from? From relaxed problems (the more relaxed, the easier to compute heuristic, but the less accurate it is) For path planning on the plane (with obstacles)? For 8-puzzle problem? For Traveling sales person? Assume away obstacles. The distance will then be The straightline distance Assume ability to move the tile directly to the place distance= # misplaced tiles Assume ability to move only one position at a time distance = Sum of manhattan distances. Relax the “circuit” requirement. Minimum spanning tree
 For path planning on the plane (with obstacles). For 8-puzzle problem. For Traveling sales person. Assume away obstacles. The distance will then be The straightline distance Assume ability to move the tile directly to the place distance= # misplaced tiles Assume ability to move only one position at a time distance = Sum of manhattan distances. Relax the circuit requirement. Minimum spanning tree.")
69
IDA* to handle the A* memory problem Basicaly IDDFS, except instead of the iterations being defined in terms of depth, we define it in terms of f-value –Start with the f cutoff equal to the f-value of the root node –Loop Generate and search all nodes whose f-values are less than or equal to current cutoff. –Use depth-first search to search the trees in the individual iterations –Keep track of the node N’ which has the smallest f- value that is still larger than the current cutoff. Let this f-value be next-largest-f-value -- If the search finds a goal node, terminate. If not, set cutoff = next-largest-f-value and go back to Loop Properties: Linear memory. #Iterations in the worst case? = B d !! (Happens when all nodes have distinct f-values)
.")
Similar presentations



















































.>")





 Suppose suboptimal goal G 2 in the queue. Let n be an unexpanded node on a shortest path to optimal goal G. f(G 2 ) =>")

 Search Algorithms. Homework #1 assigned due 10/4 before Exam 1 2.>")






 Asymptotic ratio of # nodes expanded by IDDFS vs DFS (b+1)/ (b-1) (approximates to 1 when b is large)>")

