Download presentation
Presentation is loading. Please wait.

1
Automatic Authorship Identification (Part II) Diana Michalek, Ross T. Sowell, Paul Kantor, Alex Genkin, David Madigan, Fred Roberts, and David D. Lewis

2
Acknowledgements Support –U.S. National Science Foundation DIMACS REU 2004 Knowledge Discovery and Dissemination Program Disclaimer –The views expressed in this talk are those of the authors, and not of any other individuals or organizations.

3
Outline I.Recap II.New Federalist Paper Results III.New E-mail Data Results IV.Conclusions and Future Work

4
The Authorship Problem Given: –A piece of text with unknown author –A list of possible authors –A sample of their writing Problem: –Can we automatically determine which person wrote the text?

5
The Authorship Problem Given: –A piece of text –A list of possible authors –A sample of their writing Problem: –Can we automatically determine which person wrote the text? Approach: –Use style markers to identify the author

6
The Federalist Papers 85 Total 12 Disputed

7
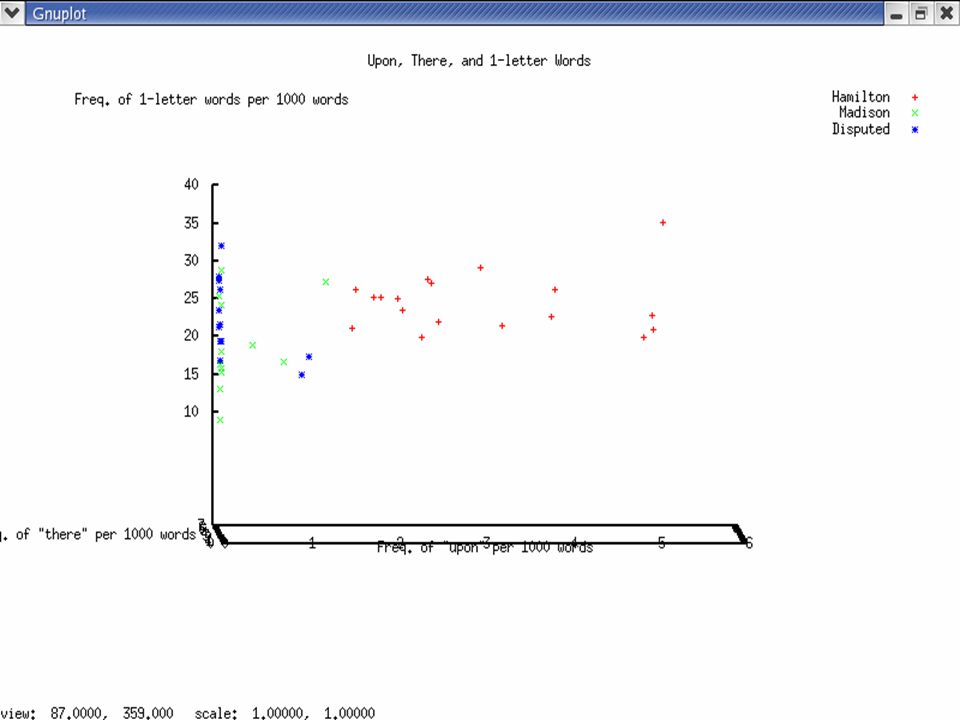
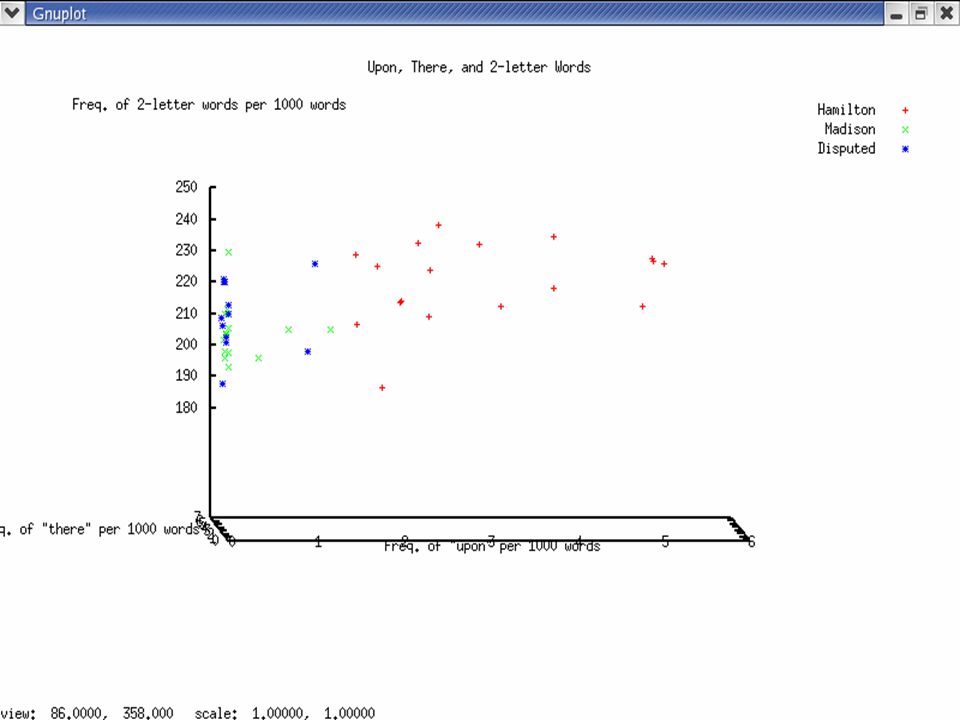
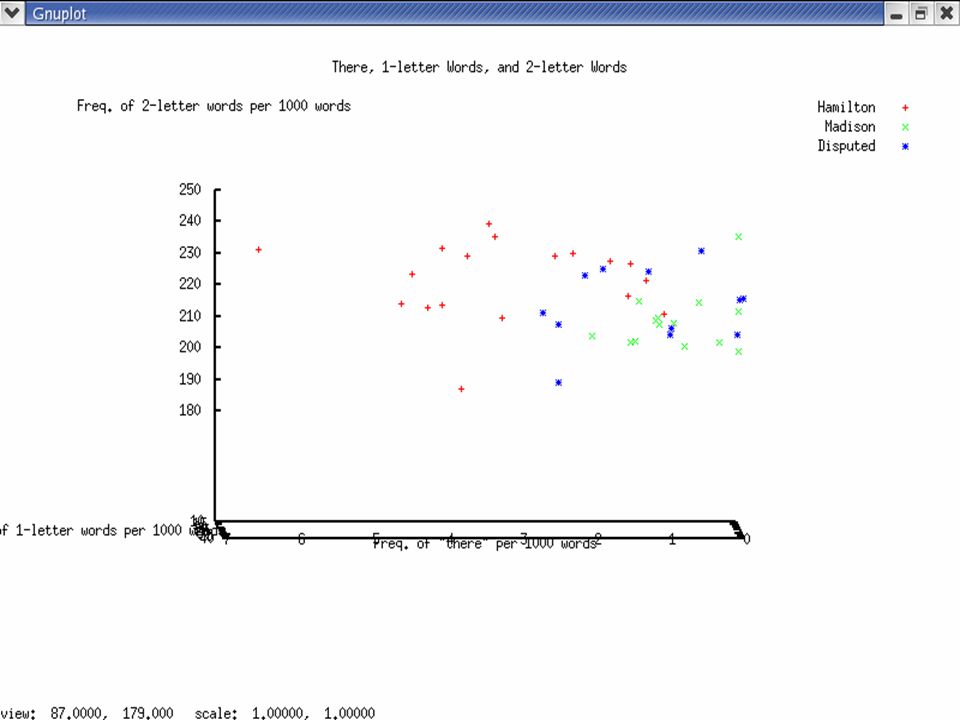
Previous Work: Mosteller and Wallace (1964) Function Words UponAlsoAn ByOfOn ThereThisTo AlthoughBothEnough WhileWhilstAlways ThoughCommonlyConsequently Considerable(ly)AccordingApt DirectionInnovation(s)Language Vigor(ous)KindMatter(s) ParticularlyProbabilityWork(s)
 Function Words UponAlsoAn ByOfOn ThereThisTo AlthoughBothEnough WhileWhilstAlways ThoughCommonlyConsequently Considerable(ly)AccordingApt DirectionInnovation(s)Language Vigor(ous)KindMatter(s) ParticularlyProbabilityWork(s)")
8
Our Previous Work: Trials with the Federalist Papers Wrote scripts in Perl and Python to compute –Sentence length frequencies –Word length frequencies –Ratios of 3-letter words to 2-letter words Analyzed our data with graphing and statistics software.

11
Previous Conclusions Not too helpful…but there is hope! –Try more features –Try different features

13
-

18
Feature Selection Which features work best? One way to rank features: –Make a contingency table for each feature F –Compute abs ( log ( ad / bc ) ) –Rank the log values ab cd F Madison Hamilton Not F
 ) –Rank the log values ab cd F Madison Hamilton Not F.")
19
49 Ranked Features

20
Linear Discriminant Analysis A technique for classifying data Available in the R statistics package Input: –Table of training data –Table of test data Output: –Classification of test data

21
Linear Discriminant Analysis: example Input training data: upon 2-letter 3-letter M 0.000 206.943 194.927 M 0.000 212.915 194.665 M 0.369 202.583 190.775 M 0.000 201.891 213.712 M 0.000 236.943 206.221 H 3.015 235.176 187.940 H 2.458 226.647 201.082 H 4.955 232.432 192.793 H 2.377 232.937 186.078 H 3.788 224.116 196.338 upon 2-letter 3-letter 0.000 226.277 203.163 0.908 205.268 181.653 0.000 225.536 182.627 0.000 217.273 183.053 1.003 232.581 184.962 Input test data: Ouput: m m m m h

22
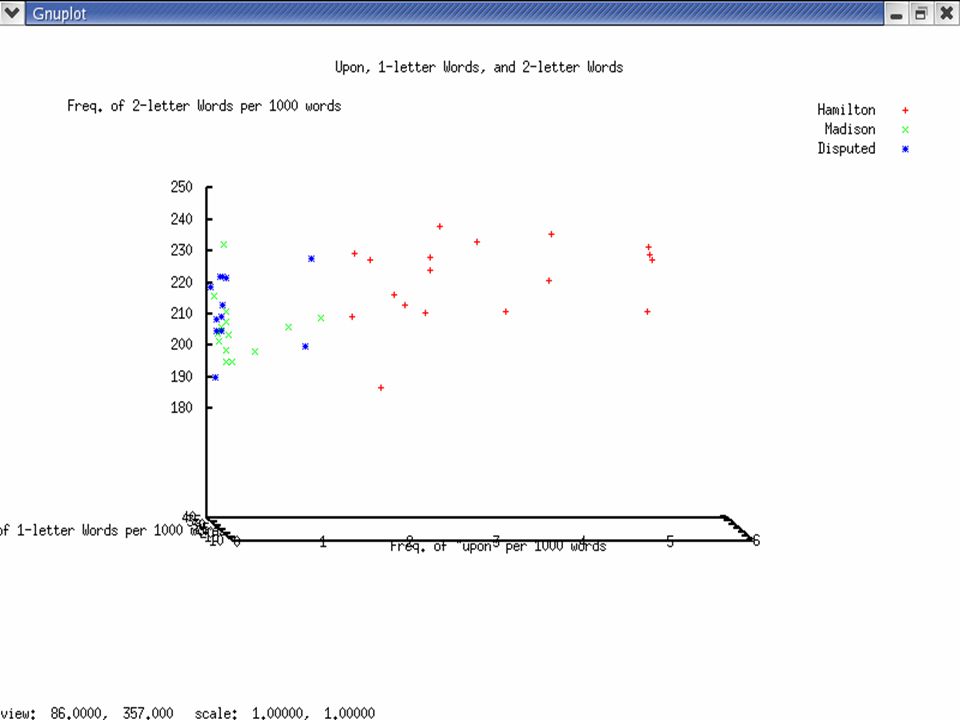
Some more LDA results 12 to Madison: –upon, 1-letter, 2-letter –upon, enough, there –upon, there 11 to Madison: –upon, 2-letter, 3-letter < 6 to Madison –2-letter, 3-letter –there, 1-letter, 2-letter

23
Some more LDA results ClassOutput of lda Features tested 12 Mm m m m m m upon apt 9 2 12 Mm m m m m m to upon 2 3 11 Mm m m m m m h m m m m mon there 2 13 11 Mh m m m m m m m m m m man by 5 10 10 Mm m m m m m h m m m h mparticularly probability 3 9 8 M m m m m m m h h h m h malso of 1 4 8 M m m m h m m h h m m h malways of 1 3 7 M h m m h m h h m h m m mof work 5 2 6 M m m h m m m h h m h h hthere language 1 8 5 M m h m h h m h h h m m hconsequently direction 5 11

24
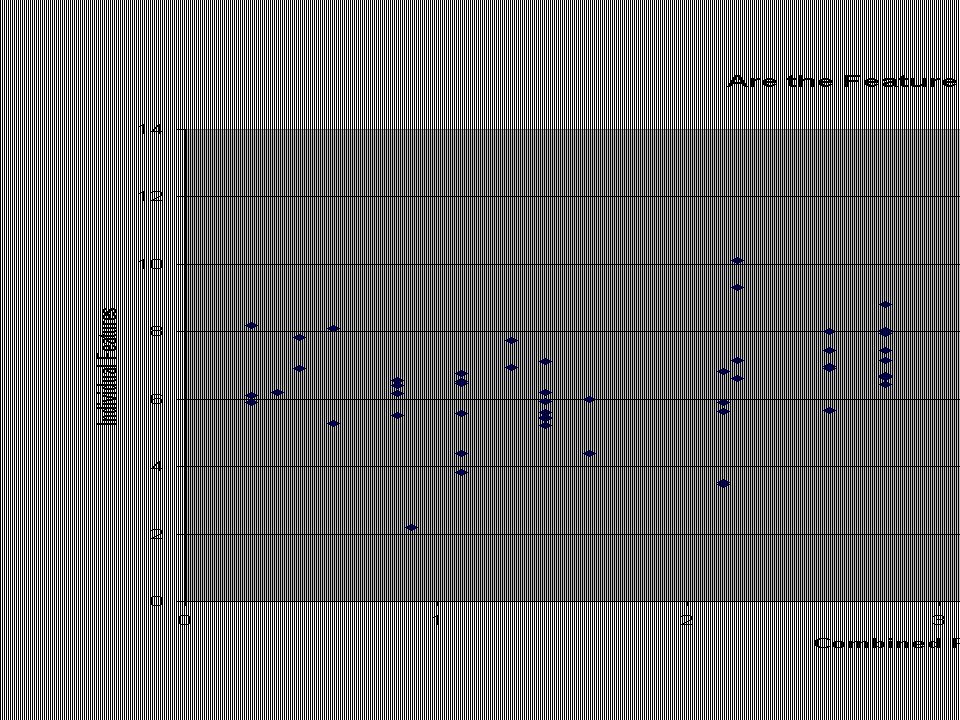
Feature Selection Part II Which combinations of features are best for LDA? Are the features independent? We did some random sampling: –Choose features a, b, c, d –Compute x = log a + log b + log x + log d –Compute y = log (a+b+c+d) –Plot x versus y
 –Plot x versus y.")
26
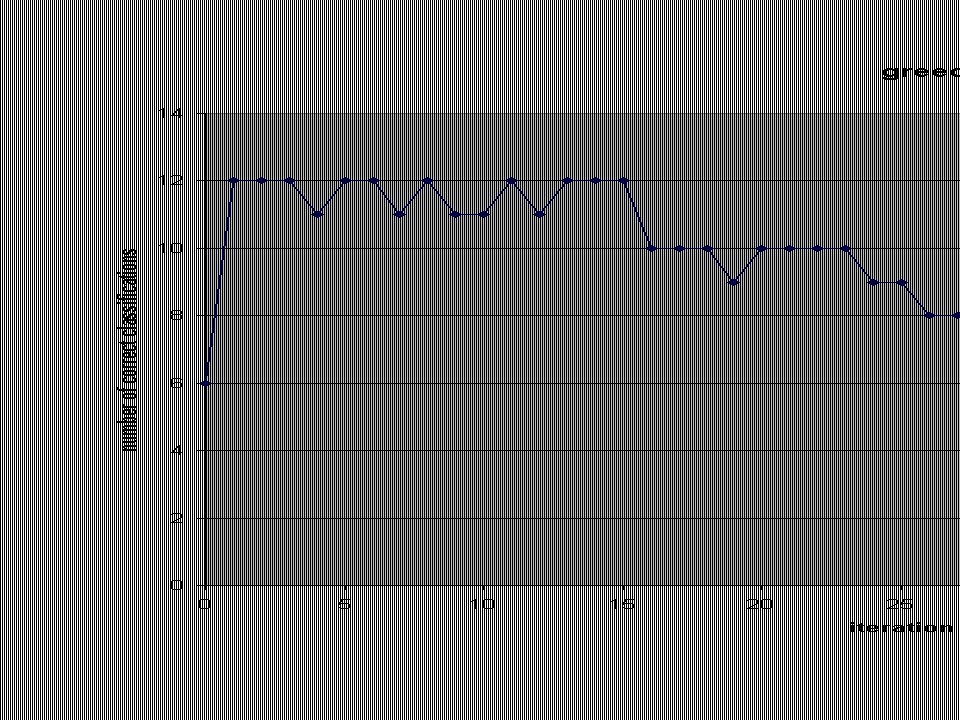
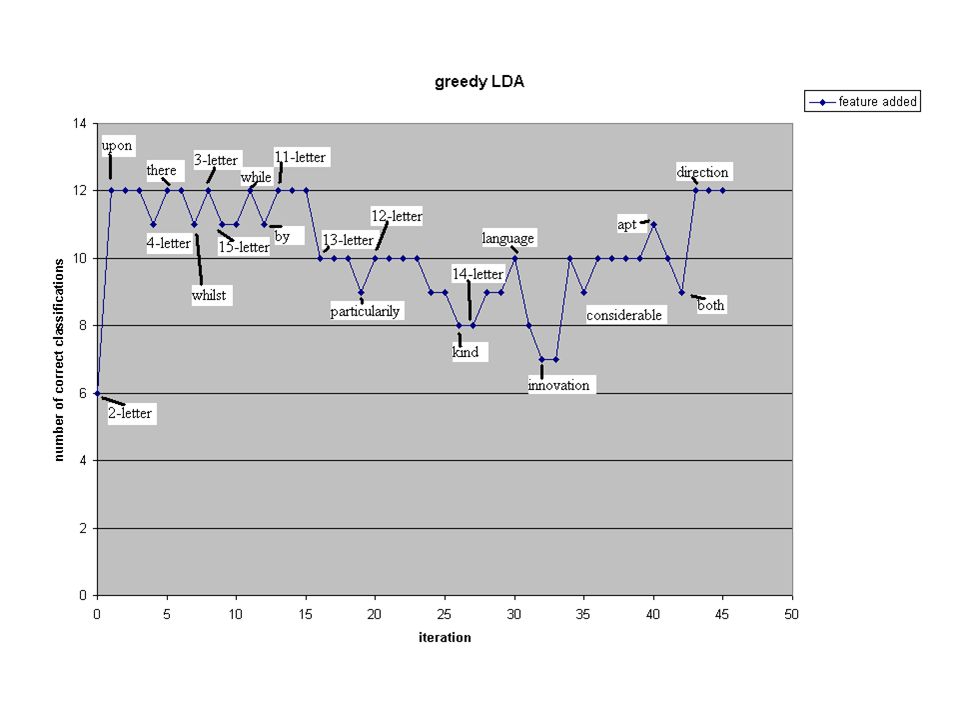
Selecting more features What happens when more than 4 features are used for the lda? Greedy approach –Add features one at a time from two lists –Perform lda on all features chosen so far Is overfitting a problem?

27
First few greedy iterations 6 M 6 H h m h h m h m m h m h m 2-letter words 12 M 0 H m m m m m m upon 12 M 0 H m m m m m m 1-letter words 12 M 0 H m m m m m m 5-letter words 11 M 1 H m m m m m h m m m m m m 4-letter words 12 M 0 H m m m m m m there 12 M 0 H m m m m m m enough 11 M 1 H m m m m m m h m m m m m whilst 12 M 0 H m m m m m m 3-letter words 11 M 1 H m m m m m m h m m m m m 15-letter words

30
Listserv Data 70 Listerv archives Over 1 million e-mail messages Data was gathered by Andrei Anghelescu –http://mms-02.rutgers.edu/ListServ/

31
Our Data One Listserv, “CINEMA-L” 992 authors, 41263 messages We look at 3 authors –sstone 1077messages –thea70 1253 –jmiles_2 1481

32
Frustration

33
Feature Selection How do we find “good” features?

34
More Frustration

35
A Measure of Variance

36
Summary of LDA Results Ran LDA using “I”, “is”, and “think” Trained on 80%, tested on 20% Correctly classified 122/186 documents

37
Future Work Finish our 3 author experiment Use more and different features –Structural –E-mail specific features Analyzing the relationship among features Other authorship id problems –Many authors –Odd-man-out

38
Thanks!!! rsowell@dimax.rutgers.edudianam@dimax.rutgers.edu

Similar presentations














 ) –Rank the log.>")




