Download presentation
Presentation is loading. Please wait.

1
Bioinspired Computing Lecture 4
Artificial Neural Networks: Feed-Forward ANNs Based on slides from Netta Cohen

2
In Lecture 6… We introduced artificial neurons, and saw that they can perform some logical operations that can be used to solve limited classification problems. We also implemented our first learning algorithm for an artificial neuron. Today We will build on the single neuron’s simplicity to achieve immense richness at the network level. We will examine the simplest architecture of feed-forward neural networks and generalise the delta-learning rule to these multi-layer networks. We look at simple applications and

3
MP neuron reminder . output x1 xn
w1 . output xn wn MP neuron (aka single layer perceptron)
")
5
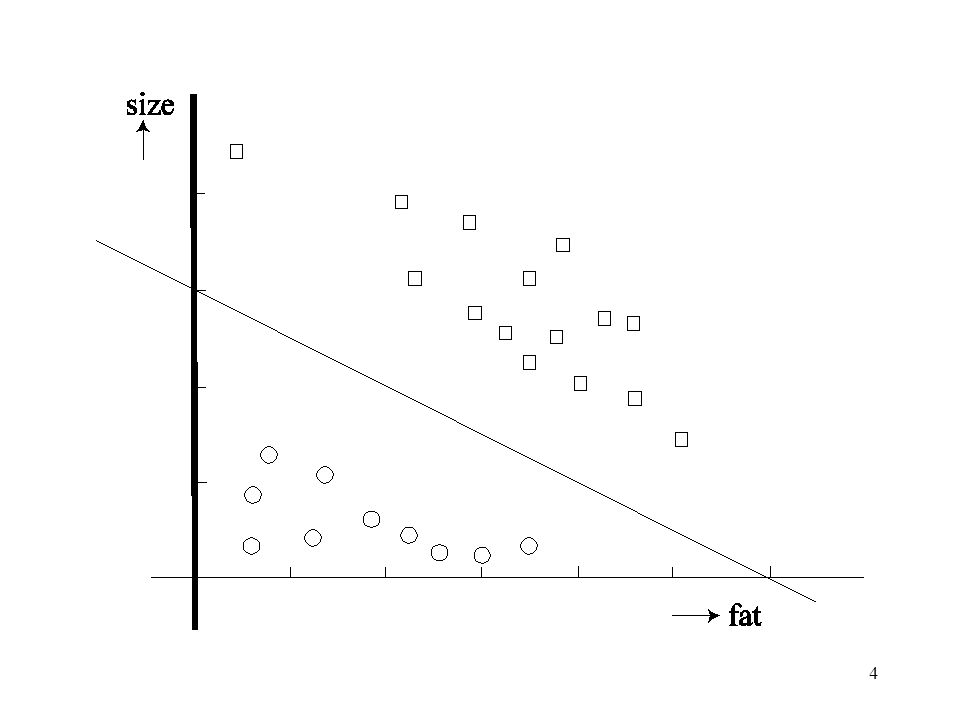
What should I remember? What is linearly separable?
What is a decision line (plane)? How can I find an MP neuron given a decision line? (and vv). Application of the perceptron algorithm, Recap after easter break
 How can I find an MP neuron given a decision line (and vv). Application of the perceptron algorithm, Recap after easter break.")
6
XOR problem How do I set the weights?
No perceptron algorithm for multiple units

7
The Multi-Layer Network
output 1 input Activation Flows Forward Input Units Output Units Units Hidden Step thresholds (which only allow “on” or “off” responses) are replaced by smooth sigmoidal activation functions that are more informative… Error Propagates Backwards
 are replaced by smooth sigmoidal activation functions that are more informative… Error Propagates Backwards.")
8
Backprop Walk-Through…
Which of the weights should be changed, and by how much? Activation Flows Forward Units Hidden Input Units Target Output We need to know which weights contributed most to the error… Once the error is propagated back, we can solve the credit assignment problem… Output Units Output Units ? Error Propagates Backwards

9
Some definitions & notation…
Binary inputs enter the network through an input layer. For training purposes, inputs are taken from a training set, for which the desired outputs are known. Neurons (nodes) are arranged in hidden layers & transmit their outputs forward to the output layer. Units Hidden z k j At each output node, the error: = desired output - actual output. Let desired output = d & Let actual output = o so =d-o. Label hidden layers, e.g. a,…i,j,k,…; label output layer z. Denote weight on a node in layer k by wjk After each training epoch, adjust weights by wjk.
 are arranged in hidden layers & transmit their outputs forward to the output layer. Units. Hidden. z. k. j. At each output node, the error: = desired output - actual output. Let desired output = d & Let actual output = o so =d-o. Label hidden layers, e.g. a,…i,j,k,…; label output layer z. Denote weight on a node in layer k by wjk. After each training epoch, adjust weights by wjk.")
10
Backpropagation in detail
Initialise weights. Pick rate parameter r. Until performance is satisfactory: - Pick an input from the training set - Run the input through the network & calculate the output. - For each output node, compare actual output with desired output to find any discrepancies. - Back-propagate the error to the last hidden layer of neurons (say layer k) as follows: and repeat for each node in layer k.
 as follows: and repeat for each node in layer k.")
11
Backpropagation in detail (cont.)
- Continue to back-propagate error, one layer at a time - Given the errors, compute the corresponding weight changes. For instance, for a node in layer j: r - Repeat for different inputs, while summing over weight changes for each node. Update the network. Halting criterion: typically training stops when a stable minimum is reached in the weight changes, or else when the errors reach an acceptable value (say under 0.1).
.")
12
Backprop Walk-Through (take 2)
Activation Flows Forward z =dz - oz Units Hidden Input Units Target Output k Output Units Output Units ? r j Iterate until trained... Error Propagates Backwards

13
Steepest gradient descent
Gradient is the direction in which the function changes fastest

14
Gradient is … (x,y) -> (x,y) + λ ( dF/dx,dF/dy) Easy to calculate
E.g. f(x,y) = x2 + y2 A way to find local minima or maxima: Symbolically: Is a step which always makes F slightly larger λ negative -> F smaller (x,y) -> (x,y) + λ ( dF/dx,dF/dy)
 = x2 + y2. A way to find local minima or maxima: Symbolically: Is a step which always makes F slightly larger. λ negative -> F smaller. (x,y) -> (x,y) + λ ( dF/dx,dF/dy)")
15
Gradient of what? E = ½(o – d)2
Given input i the weights determine output o d is the desired output for input i (given !) The weights are the only free parameters E is a function of weights !!
 The weights are the only free parameters. E is a function of weights !!")
16
Gradient of error function
Backpropagation calculates gradient of the error function. E = ½(o – d)2 ? The direction of the weight change that minimises E
2. The direction of the weight change that minimises E.")
17
Hidden neurons for curve-fitting
bias hidden input output bias Each hidden unit can be used to represent some feature in our model of the data. Hidden units can be added for additional features. With enough units (and layers), a nnet can fit arbitrarily complex shapes and curves. after
, a nnet can fit arbitrarily complex shapes and curves. after")
18
How do we train a network?
How to choose the learning rate? One solution: adaptive learning rate - The longer we train, the more fine tuned the training, and the slower the rate. How often to update the weights? “batch” learning: the entire training set is run through before updating weights “online” learning: weights updated with every input sample. Faster convergence possible, but not guaranteed (Note: Randomise input order for each epoch of training). How to avoid under- and over-fitting? Under- and Over-fitting might occur when the network size or configuration does not match the complexity of the problem at hand.
. How to avoid under- and over-fitting Under- and Over-fitting might occur when the network size or configuration does not match the complexity of the problem at hand.")
19
How do we train a network (cont.)
Growing and Pruning: growing algorithm: Start with only one hidden unit If training results in too large an error, add another hidden node. Continue training & growing the network, until no more improvement is achieved. Pruning: start with a large network & successively remove nodes until an optimal architecture is found. Neurons are assessed for their relative weight in the net & least significant units are removed. Examples of pruning techniques: “optimal brain damage” and “optimal brain surgeon” reflect difficulty in identifying least significant units.

20
How do we train a network (cont.)
Weight decay: Extraneous curvature often accompanies overfitting. Areas with large curvature typically require large weights. Penalising large weights can smooth out the fit. Thus, weight decay helps avoid over-fitting. Training with noise: Add a small random number to each input, so each epoch will look a little different, and the neural net will not gain by overfitting. Validation sets: A good way to know when to stop training the net (i.e. before overfitting) is by splitting the data into a training set and a validation set. Every once in a while, test the network on the validation set. Do not alter the weights! Once the network performs well on both training and validation sets, stop.
 is by splitting the data into a training set and a validation set. Every once in a while, test the network on the validation set. Do not alter the weights! Once the network performs well on both training and validation sets, stop.")
21
Pros and Cons Feed-forward ANNs can overcome the problem of linear separability: Given enough hidden neurons, a feed-forward network can perform any discrimination over its inputs. After a period of training, ANNs can automatically generalise what they learn to new input patterns that they have not yet been exposed to. ANNs are able to tolerate noisy inputs, or faults in their architecture, because each neuron contributes to a parallel distributed process. When neurons fail, or inputs are partially corrupted, ANNs degrade gracefully.

22
Pros and Cons (cont.) However, unlike the single-unit, the learning algorithm is not guaranteed to find the best set of weight. It may gets stuck at a sub-optimal configuration. Backprop is a form of supervised learning: a “teacher” with all the correct answer must be present, and many examples must be given. Also, unlike Hebbian learning, there is no evidence that backprop takes place in the brain. Feed-forward ANNs are powerful but not entirely natural pattern recognition & categorisation devices…

23
NETtalk An early success for feed-forward ANNs
In 1987 Sejnowski & Rosenberg built a large three-layer perceptron that learned to pronounce English words. The net was presented with seven consecutive characters (e.g., “_a_cat_”) simultaneously as input. NETtalk learned to pronounce the phoneme associated with the central letter (“c” in this example) NETtalk achieved a 90% success rate during training. When tested on a set of novel inputs that it had not seen during training, NETtalk’s performance remained steady at 80%-87%. How did NETtalk work?
 simultaneously as input. NETtalk learned to pronounce the phoneme associated with the central letter ( c in this example) NETtalk achieved a 90% success rate during training. When tested on a set of novel inputs that it had not seen during training, NETtalk’s performance remained steady at 80%-87%. How did NETtalk work")
24
The NETtalk Network teacher target output 26 output units
80 hidden units 7 groups of 29 input units _ a c t 7 letters of text input target letter (after Hinton, 1989)
")
25
NETtalk’s Learning Initially (with random weights) NETtalk babbled incoherently when presented with English input. As back-propagation gradually altered the weights the target phoneme was produced more and more often. As NETtalk learned pronunciation (e.g., the “a” sound in cat), it generalised this knowledge to other similar inputs: Sometimes this generalisation is useful producing the same sound when it saw the “a” in bat Sometimes it is inappropriate producing the same sound when it saw the “a” in mate After repeated training, NETtalk refined its generalisation, learning to use the context surrounding a letter to correctly influence how the letter was pronounced.
, it generalised this knowledge to other similar inputs: Sometimes this generalisation is useful. producing the same sound when it saw the a in bat. Sometimes it is inappropriate. producing the same sound when it saw the a in mate. After repeated training, NETtalk refined its generalisation, learning to use the context surrounding a letter to correctly influence how the letter was pronounced.")
26
NETtalk’s Behaviour After learning, NETtalk’s “knowledge” of pronunciation behaves very much like our own in some respects: NETtalk can generalise its knowledge to new inputs NETtalk can cope with internal noise & corrupted inputs When NETtalk fails, its performance degrades gracefully NETtalk achieves these useful abilities automatically. In contrast, a programmer would have to work very hard to equip a standard database with them. NETtalk’s knowledge is robust and flexible A database is fragile and brittle What does NETtalk’s knowledge look like?

27
NETtalk’s Hidden Unit Subspaces
NETtalk uses the same trick. It uses the hidden units to detect 79 different features… In other words, its weights divide its input space into 79 regions There are 79 regions because there are 79 English letter-to-phoneme relationships. Examining the weights allows us to cluster these features/regions, grouping similar ones together… Each hidden neuron in the net is used to detect a different feature of the input. These features were then used to divide up the input space into useful regions. By detecting which regions an input falls within, the net can tell whether it should return 1 or return 0.

28
NETtalk’s Knowledge How sophisticated is NETtalk’s knowledge?
Does NETtalk possess the concept of a “vowel” or a “\k\”? No – NETtalk can only use its knowledge in a fixed and limited way. Philosophers have imagined that concepts resemble Prolog propositions. They are distinct, general-purpose, logical, and symbolic. They represent facts in the same way that English sentences do and can enter into any kind of reasoning or logic. They are part of the language of thought… In contrast, NETtalk’s knowledge is more like a skill: Muddled together, special purpose, not logical or symbolic. More on this distinction later…

29
Some problems are hard for feedforward ANNs
Parity InContext vs

30
Problems ANNs often depart from biological reality:
Supervision: Real brains cannot rely on a supervisor to teach them, nor are they free to self-organise. Training vs. Testing: This distinction is an artificial one. Temporality: Real brains are continuously engaged with their environment, not exposed to a series of disconnected “trials”. Architecture: Real neurons and the networks that they form are far more complicated than the artificial neurons and simple connectivity that we have discussed so far. Does this matter? If ANNs are just biologically inspired tools, no, but if they are to model mind or life-like systems, the answer is maybe.

31
Problems Problems Fodor & Pylyshyn raise a second, deeper problem, objecting to the fact that, unlike classical AI systems, distributed representations have no combinatorial syntactic structure. Cognition requires a language of thought. Languages are structured syntactically. If ANNs cannot support syntactic representations, they cannot support cognition. F&P’s critique is perhaps not a mortal blow, but is a severe challenge to the naive ANN researcher…

32
Next Lecture on this topic…
More neural networks… More learning algorithms... More distributed representations... How neural networks deal with temporality. Reading Follow the links in today’s slides. In particular, much of today was based on

33
Distributed Representations
In the examples today, nnets learn to represent the information in a training set by distributing it across a set of simple connected neuron-like units. Some useful properties of distributed representations: they are robust to noise they degrade gracefully they are content addressable they allow automatic completion or repair of input patterns they allow automatic generalisation from input patterns they allow automatic clustering of input patterns In many ways, this form of information processing resembles that carried out by real nervous systems.

34
Distributed Representations
However, distributed representations are quite hard for us to understand, visualise or build by hand. To aid our understanding we have developed ideas such as: the partitioning of the input space the clustering of the input data the formation of feature detectors the characterisation of hidden unit subspaces etc. To build distributed representations automatically, we resorted to learning algorithms such as backprop.

35
Problems ANNs often depart from biological reality:
Supervision: Real brains cannot rely on a supervisor to teach them, nor are they free to self-organise. Training vs. Testing: This distinction is an artificial one. Temporality: Real brains are continuously engaged with their environment, not exposed to a series of disconnected “trials”. Architecture: Real neurons and the networks that they form are far more complicated than the artificial neurons and simple connectivity that we have discussed so far. Does this matter? If ANNs are just biologically inspired tools, no, but if they are to model mind or life-like systems, the answer is maybe.

36
Some ways forward… Learning: eliminate supervision
Architecture: eliminate layers & feed-forward directionality Temporality: Introduce dynamics into neural networks.

37
Auto-associative Memory
Auto-associative nets are trained to reproduce their input activation across their output nodes… bed+bath input Once trained, the net can automatically repair noisy or damaged images that are presented to it… hidden …+mirror+wardrobe m w b s output A net trained on bedrooms and bathrooms, presented with an input including a sink and a bed might infer the presence of a mirror and a wardrobe – a bedsit.

38
Auto-association The networks still rely on a feed-forward architecture Training still (typically) relies on back-propagation But… this form of learning presents a move away from conventional supervision since the “desired” output is none other than the input which can be stored internally.

39
A Vision Application Hubert & Wiesel’s work on cat retinas has inspired a class of ANNs that are used for sophisticated image analysis. Neurons in the retina are arranged in large arrays, and each has its own associated receptive field. This arrangement together with “lateral inhibition” enable the eye to efficiently perform edge detection of our visual input streams. An ANN can do the same thing

40
Lateral inhibition A pattern of light falls across an array of neurons that each inhibit their right-hand neighbour. Only neurons along the left-hand dark-light boundary escape inhibition. Lateral inhibition such as this is characteristic of natural retinal networks. Now let the receptive fields of different neurons be coarse grained, with large overlaps between adjacent neurons. What advantage is gained?

41
Lateral inhibition The networks still rely on one-way connectivity
But there are no input, hidden and output layers. Every neuron serves both for input and for output. Still, the learning is not very interesting: lateral inhibition is hard-wired up to fine tuning. While some applications support hard-wired circuitry, others require more flexible functionality.

42
Unsupervised Learning
Autoassociative learning: A first but modest move away from supervision. Reinforcement learning: In many real-life situations, we have no idea what the “desired” output of the neurons should be, but can recognise desired behaviour (e.g. riding a bike). By conditioning behaviour with rewards and penalties, desirable neural net activity is reinforced. Hebbian learning and self-organisation: In the complete absence of supervision or conditioning, the network can still self-organise and reach an appropriate and stable solution. In Hebbian learning, only effective connections between neurons are enhanced.
. By conditioning behaviour with rewards and penalties, desirable neural net activity is reinforced. Hebbian learning and self-organisation: In the complete absence of supervision or conditioning, the network can still self-organise and reach an appropriate and stable solution. In Hebbian learning, only effective connections between neurons are enhanced.")
43
Supervised training External learning rules External supervisor Off-line training a general-purpose net (that has been trained to do almost any sort of classification, recognition, fitting, association, and much more) Artificial nets can be configured to perform set tasks. The training usually involves: The result is typically: Can we design and train artificial neural nets to exhibit a more natural learning capacity?
 Artificial nets can be configured to perform set tasks. The training usually involves: The result is typically: Can we design and train artificial neural nets to exhibit a more natural learning capacity")
44
Natural learning A natural learning experience typically implies:
Internalised learning rules An ability to learn by one’s self … in the real world… without conscious control over neuronal plasticity a restricted learning capacity: We are primed to study a mother tongue, but less so to study math. A natural learning experience typically implies: The result is typically:

45
The life of a squirrel Animals tasks routinely require them to combine reactive behaviour (such as reflexes, pattern recognition, etc.), sequential behaviour (such as set routines) and learning. For example, a squirrel foraging for food must move around her territory without injuring herself identify dangerous or dull areas or those rich in food learn to travel to and from particular areas All of these behaviours are carried out by one nervous system – the squirrel’s brain. To some degree, different parts of the brain may specialise in different kinds of task. However, there is no sharp boundary between learned behaviours, instinctual behaviours and reflex behaviours.
, sequential behaviour (such as set routines) and learning. For example, a squirrel foraging for food must. move around her territory without injuring herself. identify dangerous or dull areas or those rich in food. learn to travel to and from particular areas. All of these behaviours are carried out by one nervous system – the squirrel’s brain. To some degree, different parts of the brain may specialise in different kinds of task. However, there is no sharp boundary between learned behaviours, instinctual behaviours and reflex behaviours.")
46
Recurrent Neural Networks
Activation flows around the network, rather than feeding forward. Randy Beer describes one scheme for recurrent nets: Each neuron is connected to each other neuron and to itself. Connections can be asymmetric. output Some neurons produce outputs. input Some neurons receive external input. RNN neurons are virtually the same as in feed-forward nets, but the activity of the network is updated at each time step. Note: inputs from other nodes as well as one’s self must be counted . Adapted from Randy Beer (1995) “A dynamical systems perspective on agent-environment interaction”, Artificial Intelligence 72:
 A dynamical systems perspective on agent-environment interaction , Artificial Intelligence 72:")
47
The Net’s Dynamic Character
Consider the servile life of a feed-forward net: it is dormant until an input is provided this is mapped onto the output nodes via a hidden layer weights are changed by an auxiliary learning algorithm once again the net is dormant, awaiting input Contrast the active life of a recurrent net: Even without input, spontaneous activity may reverberate around the net in any manner. this spontaneous activity is free to flow around the net external input may modify these intrinsic dynamics if embedded, the net’s activity may affect its environment, which may alter its ‘sensory’ input, which may perturb its dynamics, and so on…

48
What does it do? Initially, in the absence of input, or in the presence of a steady-state input, a recurrent network will usually approach a stable equilibrium. Other behaviours can be obtained with dynamic inputs and induced by training. For instance, a recurrent net can be trained to oscillate spontaneously (without any input), and in some cases even to generate chaotic behaviour. One of the big challenges in this area is finding the best algorithms and network architectures to induce such diverse forms of dynamics.
, and in some cases even to generate chaotic behaviour. One of the big challenges in this area is finding the best algorithms and network architectures to induce such diverse forms of dynamics.")
49
Tuning the dynamics Once input is included, there is a fear that the abundance of internal stimulations and excitations will result in an explosion or saturation of activity. In fact by including a balance of excitations and inhibitions, and by correctly choosing the activation functions, the activity is usually self-contained within reasonable bounds.

50
Dynamical Neural Nets Introducing time
In all neural net discussions so far, we have assumed all inputs to be presented simultaneously, and each trial to be separate. Time was somehow deemed irrelevant. Recurrent nets can deal with inputs that are presented sequentially, as they would almost always be in real problems. The ability of the net to reverberate and sustain activity can serve as a working memory. Such nets are called Dynamical Neural Nets (DNN or DRNN).
.")
51
Dynamical Neural Nets Consider an XOR with only one input node Input:
We provide the network with a time series consisting of a pair of high and low values. input time 1 target output Output: The output neuron is to become active when the input sequence is 01 or 10, but remain inactive when the input sequence is 00 or 11.

52
Supervised learning for RNNs
Backprop through Time: Calculate errors at output nodes at time t Backpropagate the error to all nodes at time t-1 repeat for some fixed number of time steps (usually<10) Apply usual weight fixing formula Real Time Recurrent Learning: Calculate errors at output nodes Numerically seek steepest descent solution to minimise the error at each time step. Both methods deteriorate with history: The longer the history, the harder the training. However, with slight variations, these learning algorithms have successfully been used for a variety of applications. Examples: grammar learning & distinguishing between spoken languages.
 Apply usual weight fixing formula. Real Time Recurrent Learning: Calculate errors at output nodes. Numerically seek steepest descent solution to minimise the error at each time step. Both methods deteriorate with history: The longer the history, the harder the training. However, with slight variations, these learning algorithms have successfully been used for a variety of applications. Examples: grammar learning & distinguishing between spoken languages.")
54
RNNs for Time Series Prediction
Predicting the future is one of the biggest quests of human kind. What will the weather bring tomorrow? Is there global warming? When will Wall Street crash and how will oil prices fluctuate in the coming months? Can EEG recordings be used to predict the next epilepsy attack or ECG, the next heart attack? Such daunting questions have occupied scientists for centuries and computer scientists since time immemorial. Another example dates back to Edmund Halley’s observation in 1676 that Jupiter’s orbit was directed slowly towards the sun. If true, Jupiter would sweep the inner planets with it into the sun (that’s us). The hypothesis threw the entire mathematical elite into a frenzy. Euler, Lagrange and Lambert made heroic attacks on the problem without solving it. No wonder. The problem involved 75 simultaneous equations resulting in some 20 billion possible choices of parameters. It was finally solved (probabilistically) by Laplace in Jupiter, it turns out, was only oscillating. The first half cycle of oscillations will be completed at about 2012.
. The hypothesis threw the entire mathematical elite into a frenzy. Euler, Lagrange and Lambert made heroic attacks on the problem without solving it. No wonder. The problem involved 75 simultaneous equations resulting in some 20 billion possible choices of parameters. It was finally solved (probabilistically) by Laplace in Jupiter, it turns out, was only oscillating. The first half cycle of oscillations will be completed at about")
55
How does it work? A time series represents a process that is discrete or has been discretised in time. input output x t 1 2 4 3 5 7... 6 The output represents a prediction based on information about the past. If the system can be described by a dynamical process, then a recurrent neural net should be able to model it. The question is how many data points are needed (i.e. how far into the past must we go) to predict the future.
 to predict the future.")
56
Next time… Reading Genetic algorithms
Randy Beer (1995) “A dynamical systems perspective on agent-environment interaction”, Artificial Intelligence 72: In particular, much of today was based on
 A dynamical systems perspective on agent-environment interaction , Artificial Intelligence 72: In particular, much of today was based on.")
Similar presentations

>")





>")










>")
 by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley.>")
