Download presentation
Presentation is loading. Please wait.

1
A General Framework for Mining Massive Data Streams Geoff Hulten Advised by Pedro Domingos

2
Mining Massive Data Streams High-speed data streams abundant –Large retailers –Long distance & cellular phone call records –Scientific projects –Large Web sites Build model of the process creating data Use model to interact more efficiently

3
Growing Mismatch Between Algorithms and Data State of the art data mining algorithms –One shot learning –Work with static databases –Maximum of 1 million – 10 million records Properties of Data Streams –Data stream exists over months or years –10s – 100s of millions of new records per day –Process generating data changing over time

4
The Cost of This Mismatch Fraction of data we can effectively mine shrinking towards zero Models learned from heuristically selected samples of data Models out of date before being deployed

5
Need New Algorithms Monitor a data stream and have a model available at all times Improve the model as data arrives Adapt the model as process generating data changes Have quality guarantees Work within strict resource constraints

6
Solution: General Framework Applicable to algorithms based on discrete search Semi-automatically converts algorithm to meet our design needs Uses sampling to select data size for each search step Extensions to continuous searches and relational data

7
Outline Introduction Scaling up Decision Trees Our Framework for Scaling Other Applications and Results Conclusion

8
Decision Trees Examples: Encode: Nodes contain tests Leaves contain predictions Gender? False Age? MaleFemale < 25>= 25 FalseTrue

9
Decision Tree Induction DecisionTree(Data D, Tree T, Attributes A) If D is pure Let T be a leaf predicting class in D Return Let X be best of A according to D and G() Let T be a node that splits on X For each value V of X Let D^ be the portion of D with V for X Let T^ be the child of T for V DecisionTree(D^, T^, A – X)
 If D is pure Let T be a leaf predicting class in D Return Let X be best of A according to D and G() Let T be a node that splits on X For each value V of X Let D^ be the portion of D with V for X Let T^ be the child of T for V DecisionTree(D^, T^, A – X)")
10
VFDT (Very Fast Decision Tree) In order to pick split attribute for a node looking at a few example may be sufficient Given a stream of examples: –Use the first to pick the split at the root –Sort succeeding ones to the leaves –Pick best attribute there –Continue… Leaves predict most common class Very fast, incremental, any time decision tree induction algorithm
 In order to pick split attribute for a node looking at a few example may be sufficient Given a stream of examples: –Use the first to pick the split at the root –Sort succeeding ones to the leaves –Pick best attribute there –Continue… Leaves predict most common class Very fast, incremental, any time decision tree induction algorithm")
11
How Much Data? Make sure best attribute is better than second –That is: Using a sample so need Hoeffding bound –Collect data till:

12
Core VFDT Algorithm Proceedure VFDT(Stream, δ) Let T = Tree with single leaf (root) Initialize sufficient statistics at root For each example (X, y) in Stream Sort (X, y) to leaf using T Update sufficient statistics at leaf Compute G for each attribute If G(best) – G(2 nd best) > ε, then Split leaf on best attribute For each branch Start new leaf, init sufficient statistics Return T x1? y=0 x2? y=0y=1 malefemale > 65<= 65

13
Quality of Trees from VFDT Model may contain incorrect splits, useful? Bound the difference with infinite data tree –Chance an arbitrary example takes different path Intuition: example on level i of tree has i chances to go through a mistaken node

14
Complete VFDT System Memory management –Memory dominated by sufficient statistics –Deactivate less promising leaves when needed Ties: –Wasteful to decide between identical attributes Check for splits periodically Pre-pruning –Only make splits that improve the value of G(.) Early stop on bad attributes
 Early stop on bad attributes")
15
VFDT (Continued) Bootstrap with traditional learner Rescan dataset when time available Time changing data streams Post pruning Continuous attributes Batch mode
 Bootstrap with traditional learner Rescan dataset when time available Time changing data streams Post pruning Continuous attributes Batch mode")
16
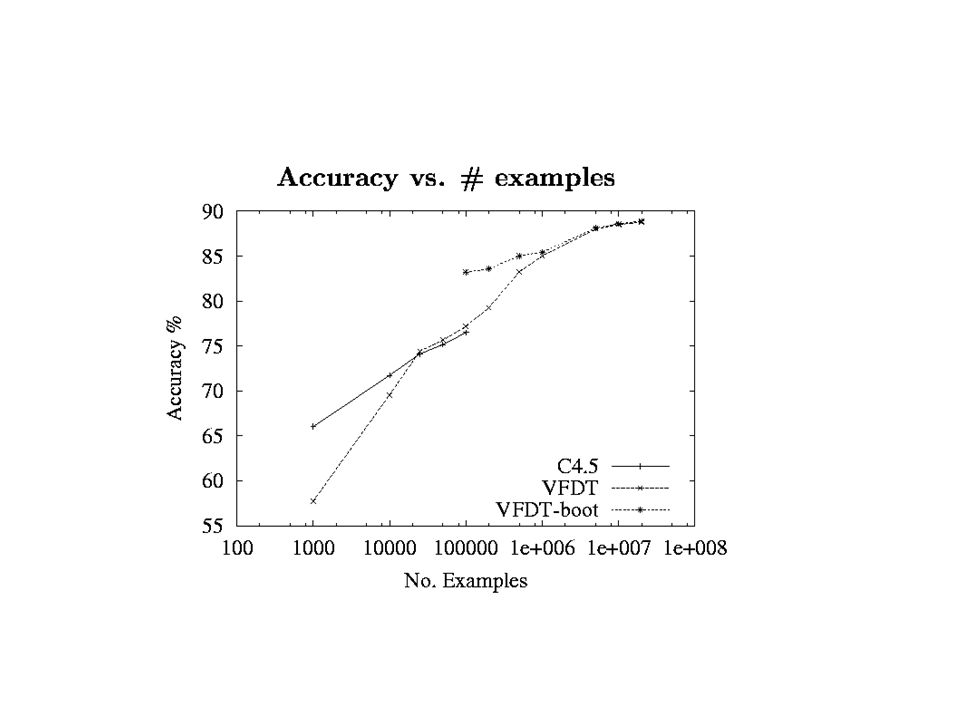
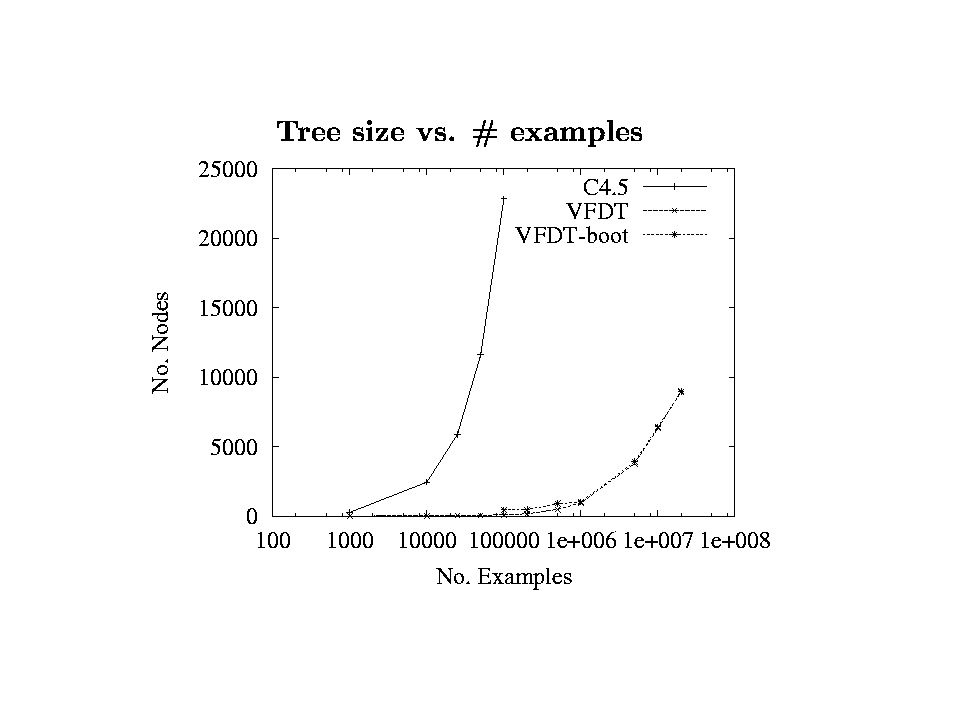
Experiments Compared VFDT and C4.5 (Quinlan, 1993) Same memory limit for both (40 MB) –100k examples for C4.5 VFDT settings: δ = 10^-7, τ = 5% Domains: 2 classes, 100 binary attributes Fifteen synthetic trees 2.2k – 500k leaves Noise from 0% to 30%
 Same memory limit for both (40 MB) –100k examples for C4.5 VFDT settings: δ = 10^-7, τ = 5% Domains: 2 classes, 100 binary attributes Fifteen synthetic trees 2.2k – 500k leaves Noise from 0% to 30%")
19
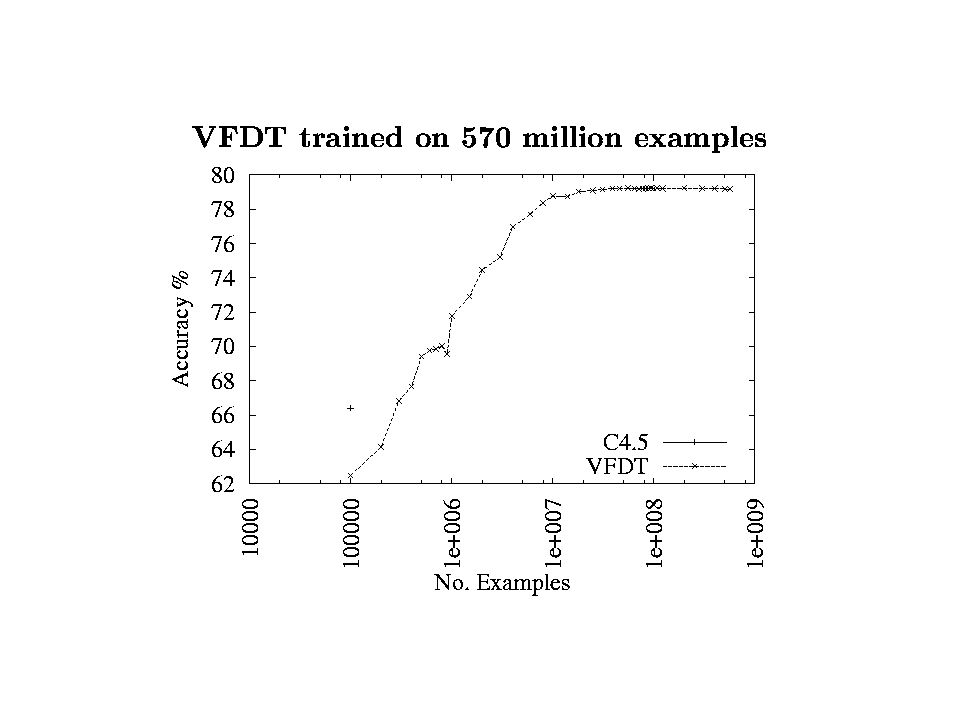
Running Times Pentium III at 500 MHz running Linux C4.5 takes 35 seconds to read and process 100k examples; VFDT takes 47 seconds VFDT takes 6377 seconds for 20 million examples; 5752s to read 625s to process VFDT processes 32k examples per second (excluding I/O)
")
21
Real World Data Sets: Trace of UW Web requests Stream of Web page request from UW One week 23k clients, 170 orgs. 244k hosts, 82.8M requests (peak: 17k/min), 20GB Goal: improve cache by predicting requests 1.6M examples, 61% default class C4.5 on 75k exs, 2975 secs. –73.3% accuracy VFDT ~3000 secs., 74.3% accurate
, 20GB Goal: improve cache by predicting requests 1.6M examples, 61% default class C4.5 on 75k exs, 2975 secs. –73.3% accuracy VFDT ~3000 secs., 74.3% accurate.")
22
Outline Introduction Scaling up Decision Trees Our Framework for Scaling Overview of Applications and Results Conclusion

23
Data Mining as Discrete Search... Initial state –Empty – prior – random Search operators –Refine structure Evaluation function –Likelihood – many other Goal state –Local optimum, etc.

24
Data Mining As Search... Training Data 1.7 1.5 1.8 1.9 2.0

25
Example: Decision Tree... Training Data 1.7 1.5 X1? Xd? ??... X1?... X1? Training Data Initial state –Root node Search operators –Turn any leaf into a test on attribute Evaluation –Entropy Reduction Goal state –No further gain –Post prune

26
Overview of Framework Cast the learning algorithm as a search Begin monitoring data stream –Use each example to update sufficient statistics where appropriate (then discard it) –Periodically pause and use statistical tests Take steps that can be made with high confidence –Monitor old search decisions Change them when data stream changes
 –Periodically pause and use statistical tests Take steps that can be made with high confidence –Monitor old search decisions Change them when data stream changes")
27
How Much Data is Enough?... Training Data 1.65 1.38 Xd? X1?

28
How Much Data is Enough?... Sample of Data 1.6 +/- ε Use statistical bounds –Normal distribution –Hoeffding bound Applies to scores that are average over examples Can select a winner if –Score1 > Score2 + ε 1.4 +/- ε Xd? X1?

29
Global Quality Guarantee δ – probability of error in single decision b – branching factor of search d – depth of search c – number of checks for winner δ* = δbdc

30
Identical States And Ties Fails if states are identical (or nearly so) τ – user supplied tie parameter Select winner early if alternatives differ by less than τ –Score1 > Score2 + ε or –ε <= τ
 τ – user supplied tie parameter Select winner early if alternatives differ by less than τ –Score1 > Score2 + ε or –ε <= τ")
31
Dealing with Time Changing Concepts Maintain a window of the most recent examples Keep model up to date with this window Effective when window size similar to concept drift rate Traditional approach –Periodically reapply learner –Very inefficient! Our approach –Monitor quality of old decisions as window shifts –Correct decisions in fine-grained manner

32
Alternate Searches When new test looks better grow alternate sub-tree Replace the old when new is more accurate This smoothly adjusts to changing concepts Gender? Pets?College? Hair? false true false true

33
RAM Limitations Each search requires sufficient statistics structure Decision Tree –O(avc) RAM Bayesian Network –O(c^p) RAM
 RAM Bayesian Network –O(c^p) RAM")
34
RAM Limitations Active Temporarily inactive

35
Outline Introduction Data Mining as Discrete Search Our Framework for Scaling Application to Decision Trees Other Applications and Results Conclusion

36
Applications VFDT (KDD ’00) – Decision Trees CVFDT (KDD ’01) – VFDT + concept drift VFBN & VFBN2 (KDD ’02) – Bayesian Networks Continuous Searches –VFKM (ICML ’01) – K-Means clustering –VFEM (NIPS ’01) – EM for mixtures of Gaussians Relational Data Sets –VFREL (Submitted) – Feature selection in relational data
 – Decision Trees CVFDT (KDD ’01) – VFDT + concept drift VFBN & VFBN2 (KDD ’02) – Bayesian Networks Continuous Searches –VFKM (ICML ’01) – K-Means clustering –VFEM (NIPS ’01) – EM for mixtures of Gaussians Relational Data Sets –VFREL (Submitted) – Feature selection in relational data")
37
CFVDT Experiments

38
Activity Profile for VFBN

39
Other Real World Data Sets Trace of all web requests from UW campus –Use clustering to find good locations for proxy caches KDD Cup 2000 Data set –700k page requests from an e-commerce site –Categorize pages into 65 categories, predict which a session will visit UW CSE Data set –8 Million sessions over two years –Predict which of 80 level 2 directories each visits Web Crawl of.edu sites –Two data sets each with two million web pages –Use relational structure to predict which will increase in popularity over time

40
Related Work DB Mine: A Performance Perspective (Agrawal, Imielinski, Swami ‘93) –Framework for scaling rule learning RainForest (Gehrke, Ramakrishnan, Ganti ‘98) –Framework for scaling decision trees ADtrees (Moore, Lee ‘97) –Accelerate computing sufficient stats PALO (Greiner ‘92) –Accelerate hill climbing search via sampling DEMON (Ganti, Gehrke, Ramakrishnan ‘00) –Framework for converting incremental algs. for time changing data streams

41
Future Work Combine framework for discrete search with frameworks for continuous search and relational learning Further study time changing processes Develop a language for specifying data stream learning algorithms Use framework to develop novel algorithms for massive data streams Apply algorithms to more real-world problems

42
Conclusion Framework helps scale up learning algorithms based on discrete search Resulting algorithms: –Work on databases and data streams –Work with limited resources –Adapt to time changing concepts –Learn in time proportional to concept complexity Independent of amount of training data! Benefits have been demonstrated in a series of applications

Similar presentations


 Computer Science cpsc502, Lecture 15 Nov, 1, 2011 Slide credit: C. Conati, S.>")





 weijters.>")










