Download presentation
Presentation is loading. Please wait.

1
Session 7

2
Applied Regression -- Prof. Juran2 Outline Chi-square Goodness-of-Fit Tests Fit to a Normal Simulation Modeling Autocorrelation, serial correlation Runs test Durbin-Watson Model Building Variable Selection Methods Minitab

3
Applied Regression -- Prof. Juran3 Goodness-of-Fit Tests Determine whether a set of sample data have been drawn from a hypothetical population Same four basic steps as other hypothesis tests we have learned An important tool for simulation modeling; used in defining random variable inputs

4
Applied Regression -- Prof. Juran4 Example: Barkevious Mingo Financial analyst Barkevious Mingo wants to run a simulation model that includes the assumption that the daily volume of a specific type of futures contract traded at U.S. commodities exchanges (represented by the random variable X ) is normally distributed with a mean of 152 million contracts and a standard deviation of 32 million contracts. (This assumption is based on the conclusion of a study conducted in 2013.) Barkevious wants to determine whether this assumption is still valid.
 is normally distributed with a mean of 152 million contracts and a standard deviation of 32 million contracts. (This assumption is based on the conclusion of a study conducted in 2013.) Barkevious wants to determine whether this assumption is still valid..")
5
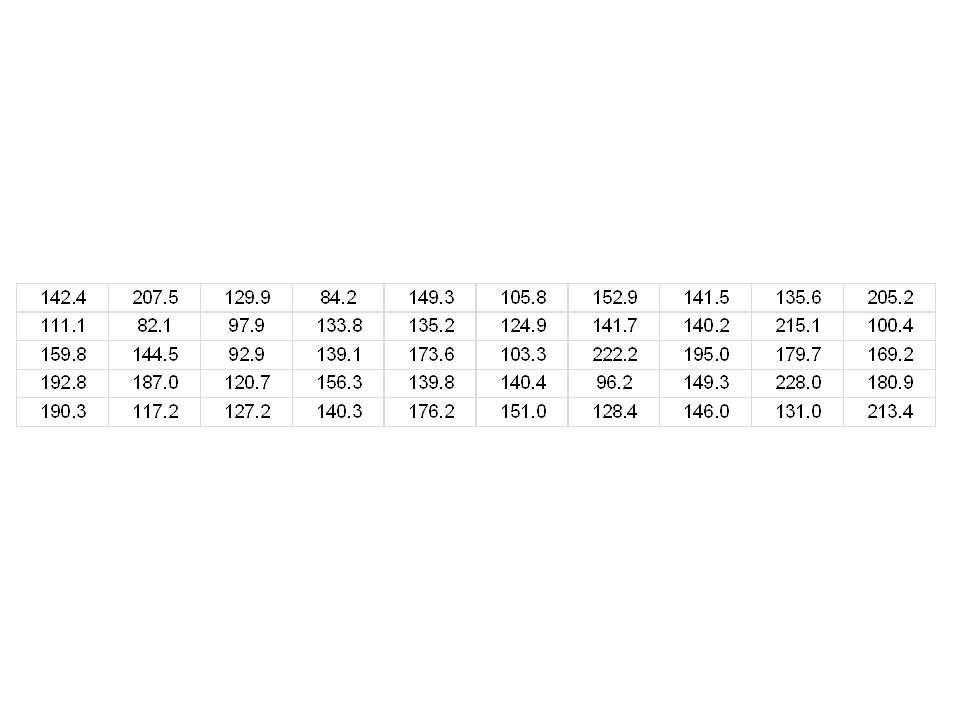
Applied Regression -- Prof. Juran5 He studies the trading volume of these contracts for 50 days, and observes the following results (in millions of contracts traded):
:.")
6
Applied Regression -- Prof. Juran6

7
7 Here is a histogram showing the theoretical distribution of 50 observations drawn from a normal distribution with μ = 152 and σ = 32, together with a histogram of Mingo’s sample data:

8
Applied Regression -- Prof. Juran8 The Chi-Square Statistic

9
Applied Regression -- Prof. Juran9 Essentially, this statistic allows us to compare the distribution of a sample with some expected distribution, in standardized terms. It is a measure of how much a sample differs from some proposed distribution. A large value of chi-square suggests that the two distributions are not very similar; a small value suggests that they “fit” each other quite well.

10
Applied Regression -- Prof. Juran10 Like Student’s t, the distribution of chi- square depends on degrees of freedom. In the case of chi-square, the number of degrees of freedom is equal to the number of classes (a.k.a. “bins” into which the data have been grouped) minus one, minus the number of estimated parameters.
 minus one, minus the number of estimated parameters..")
11
Applied Regression -- Prof. Juran11

12
Applied Regression -- Prof. Juran12

13
Applied Regression -- Prof. Juran13 Note: It is necessary to have a sufficiently large sample so that each class has an expected frequency of at least 5. We need to make sure that the expected frequency in each bin is at least 5, so we “collapse” some of the bins, as shown here.

14
Applied Regression -- Prof. Juran14 The number of degrees of freedom is equal to the number of bins minus one, minus the number of estimated parameters. We have not estimated any parameters, so we have d.f. = 4 – 1 – 0 = 3. The critical chi-square value can be found either by using a chi-square table or by using the Excel function: =CHIINV(alpha, d.f.) = CHIINV(0.05, 3) = 7.815 We will reject the null hypothesis if the test statistic is greater than 7.815.
 = CHIINV(0.05, 3) = We will reject the null hypothesis if the test statistic is greater than")
15
Applied Regression -- Prof. Juran15 Our test statistic is not greater than the critical value; we cannot reject the null hypothesis at the 0.05 level of significance. It would appear that Barkevious is justified in using the normal distribution with μ = 152 and σ = 32 to model futures contract trading volume in his simulation.

16
Applied Regression -- Prof. Juran16 The p -value of this test has the same interpretation as in any other hypothesis test, namely that it is the smallest level of alpha at which H 0 could be rejected. In this case, we calculate the p -value using the Excel function: = CHIDIST(test stat, d.f.) = CHIDIST(7.439,3) = 0.0591
 = CHIDIST(7.439,3) =")
17
Applied Regression -- Prof. Juran17 Example: Catalog Company If we want to simulate the queueing system at this company, what distributions should we use for the arrival and service processes?

18
Applied Regression -- Prof. Juran18 Arrivals

19
Applied Regression -- Prof. Juran19

20
Applied Regression -- Prof. Juran20

21
Applied Regression -- Prof. Juran21

22
Applied Regression -- Prof. Juran22

23
Applied Regression -- Prof. Juran23 Services

24
Applied Regression -- Prof. Juran24

26
Decision Models -- Prof. Juran 26

27
Decision Models -- Prof. Juran 27

28
Decision Models -- Prof. Juran 28

29
Decision Models -- Prof. Juran 29

30
Decision Models -- Prof. Juran30

31
Decision Models -- Prof. Juran31

32
Decision Models -- Prof. Juran32

33
Decision Models -- Prof. Juran33

34
Decision Models -- Prof. Juran34

35
Decision Models -- Prof. Juran35

36
Decision Models -- Prof. Juran36

37
Decision Models -- Prof. Juran37

38
Applied Regression -- Prof. Juran38 Other uses for the Chi-Square statistic Tests of the independence of two qualitative population variables. Tests of the equality or inequality of more than two population proportions. Inferences about a population variance, including the estimation of a confidence interval for a population variance from sample data. The chi-square technique can often be employed for purposes of estimation or hypothesis testing when the z or t statistics are not appropriate. In addition to the goodness-of-fit application described above, there are at least three other important uses for chi-square:

39
Applied Regression -- Prof. Juran39 (A.k.a. Autocorrelation) Are the residuals independent of each other? What if there’s evidence that sequential residuals have a positive correlation? Serial Correlation
 Are the residuals independent of each other. What if there’s evidence that sequential residuals have a positive correlation. Serial Correlation.")
40
Applied Regression -- Prof. Juran40

41
Applied Regression -- Prof. Juran41

42
Applied Regression -- Prof. Juran42 There seems to be a relationship between each observation and the ones around it. In other words, there is some positive correlation between the observations and their successors. If true, this suggests that a lot of the variability in observation Y i can be explained by observation Y i – 1. In turn, this might suggest that the importance of Money Stock is being overstated by our original model.

43
Applied Regression -- Prof. Juran43

44
Applied Regression -- Prof. Juran44

45
Applied Regression -- Prof. Juran45

46
Applied Regression -- Prof. Juran46

47
Applied Regression -- Prof. Juran47

48
Applied Regression -- Prof. Juran48

49
Applied Regression -- Prof. Juran49

50
Applied Regression -- Prof. Juran50

51
Applied Regression -- Prof. Juran51

52
Applied Regression -- Prof. Juran52 A “run” is when the residual is positive (or negative) consecutively. Runs Test ++++++++-- has 2 runs ++--++--++ has 5 runs --+ + +- has 7 runs, and so forth.
 consecutively. Runs Test has 2 runs has 5 runs has 7 runs, and so forth..")
53
Applied Regression -- Prof. Juran53 Let n 1 be the observed number of positive runs and n 2 be the observed number of negative runs. The total number of runs in a set of n uncorrelated residuals can be shown to have a mean of And a variance of

54
Applied Regression -- Prof. Juran54 In our Money Stock case, the expected value is 8.1 and the standard deviation ought to be about 1.97.

55
Applied Regression -- Prof. Juran55 Our Model 1 has 5 runs which is 1.57 standard deviations below the expected value — an unusually small number of runs. This suggests that the residuals are not independent. (This is an approximation based on the central limit theorem; it doesn’t work well with small samples.) Our Model 2 has 7 runs; only 0.56 standard deviations below the expected value.
 Our Model 2 has 7 runs; only 0.56 standard deviations below the expected value..")
56
Applied Regression -- Prof. Juran56 Durbin-Watson Another popular hypothesis-testing procedure: H 0 : Correlation = 0 H A : Correlation > 0 The test statistic is:

57
Applied Regression -- Prof. Juran57 In general, Values of d close to zero indicate strong positive correlation, and values of d close to 2 suggest weak correlation. Precise definitions of “close to zero” and “close to 2” depend on the sample size and the number of independent variables; see p. 346 in RABE for a Durbin-Watson table.

58
Applied Regression -- Prof. Juran58 The Durbin-Watson procedure will result in one of three possible decisions: From the Durbin-Watson table, we see that our Model 1 has upper and lower limits of 1.15 and 0.95, respectively. Model 2 has limits of 1.26 and 0.83.

59
Applied Regression -- Prof. Juran59

60
Applied Regression -- Prof. Juran60

61
Applied Regression -- Prof. Juran61 In Model 1, we reject the null hypothesis and conclude there is significant positive correlation between sequential residuals. In Model 2, we do not reject the null hypothesis; the serial correlation is not significantly greater than zero.

62
Applied Regression -- Prof. Juran62 Residual Analysis from the Tool-Wear Model

63
Applied Regression -- Prof. Juran63

64
Applied Regression -- Prof. Juran64 Normal score calculations:

65
Applied Regression -- Prof. Juran65

66
Applied Regression -- Prof. Juran66

67
Applied Regression -- Prof. Juran67

68
Applied Regression -- Prof. Juran68

69
Applied Regression -- Prof. Juran69 Model Building Ideally, we build a model under clean, scientific conditions: Understand the phenomenon well Have an a priori theoretical model Have valid, reliable measures of the variables Have data in adequate quantities over an appropriate range Regression validates and calibrates the model, not discovers it

70
Applied Regression -- Prof. Juran70 Little understanding of the phenomenon No a priori theory or model Have data that may or may not cover all reasonable variables Have measures of some variables, but little sense of their validity or reliability Have data in small quantities over a restricted range We hope that regression uncovers some magical unexpected relationships This process has been referred to as Creative Regression Analytical Prospecting, or CRAP. “This room is filled with horseshit; there must be a pony in here somewhere.” Unfortunately, we too often find ourselves Data Mining:

71
Applied Regression -- Prof. Juran71 The Model Building Problem Suppose we have data available for n variables. How do we pick the best sub-model from: yielding, perhaps There is no solution to this problem that is entirely satisfactory, but there are some reasonable heuristics.

72
Applied Regression -- Prof. Juran72 Scientific Ideology: In chemistry, physics, and biology, most good models are simple. The principle of parsimony carries over into social sciences, such as business analysis. Statistical Advantages: Even eliminating “significant” variables that don’t contribute much to the model can have advantages, especially for predicting the future. These advantages include less expensive data collection, smaller standard errors, and tighter confidence intervals. Why Reduce the Number of Variables?

73
Applied Regression -- Prof. Juran73 Statistical Criteria for Comparing Models

74
Applied Regression -- Prof. Juran74 Taking into account the possible bias that comes from having an under-specified model, this measure estimates the MSE including both bias and variance: If the model is complete (we have the p terms that matter) the expected value of C p = p. So we look for models with C p close to p. Mallows C p
 the expected value of C p = p. So we look for models with C p close to p. Mallows C p.")
75
Applied Regression -- Prof. Juran75 All-Subsets Forward Backward Stepwise Best Subsets Variable Selection Algorithms

76
Applied Regression -- Prof. Juran76 If there are p candidate independent variables, then there are 2 p possible models. Why not look at them all? This is not really a major computational problem, but can pose difficulties in looking at all of the output. However, some reasonable schemes exist for looking at a relatively small subset of all the possible models. All-Subsets Regression

77
Applied Regression -- Prof. Juran77 Start with one independent variable (the one with the strongest bivariate correlation with the dependent variable), and add additional variables until the next variable in line to enter fails to achieve a certain threshold value. This can be based on a minimum F value in the full-model/reduced-model test, called F IN, or it can be based on the last-in p -value for each candidate variable. Forward selection is basically the same thing as Stepwise, except variables are never removed once they enter the model. Set “ F to remove” to zero. The procedure ends when no variable not already in the model has an F -stat greater than F IN. Forward Regression
, and add additional variables until the next variable in line to enter fails to achieve a certain threshold value. This can be based on a minimum F value in the full-model/reduced-model test, called F IN, or it can be based on the last-in p -value for each candidate variable. Forward selection is basically the same thing as Stepwise, except variables are never removed once they enter the model. Set F to remove to zero. The procedure ends when no variable not already in the model has an F -stat greater than F IN. Forward Regression.")
78
Applied Regression -- Prof. Juran78 Start with all of the independent variables, and eliminate them one by one (on the basis of having the weakest t -stat) until the next variable fails to meet a minimum threshold. This can be an F criterion called F OUT, or a p -value criterion. Backwards elimination starts with all of the independent variables, then removes them one at a time based on the stepwise procedure, except that no variable can re-enter once it has been removed. Set F IN at a very large number such as 100,000 and list all predictors in the Enter box. The procedure ends when no variable in the model has an F -stat less than F OUT. Backward Regression
 until the next variable fails to meet a minimum threshold. This can be an F criterion called F OUT, or a p -value criterion. Backwards elimination starts with all of the independent variables, then removes them one at a time based on the stepwise procedure, except that no variable can re-enter once it has been removed. Set F IN at a very large number such as 100,000 and list all predictors in the Enter box. The procedure ends when no variable in the model has an F -stat less than F OUT. Backward Regression.")
79
Applied Regression -- Prof. Juran79 An intelligent mixture of forward and backward ideas. Variables can be entered or removed using F IN and F OUT criteria or p -value criteria. Stepwise Regression

80
Applied Regression -- Prof. Juran80 The basic (default) method of stepwise regression calculates an F - statistic for each variable in the model. Suppose the model contains X 1,..., X p. Then the F -statistic for X i is with 1 and n - p - 1 degrees of freedom. If the F -statistic for any variable is less than F to remove, the variable with the smallest F is removed from the model. The regression equation is calculated for this smaller model, the results are printed, and the procedure proceeds to a new step. The F Criterion
 method of stepwise regression calculates an F - statistic for each variable in the model. Suppose the model contains X 1,..., X p. Then the F -statistic for X i is with 1 and n - p - 1 degrees of freedom. If the F -statistic for any variable is less than F to remove, the variable with the smallest F is removed from the model. The regression equation is calculated for this smaller model, the results are printed, and the procedure proceeds to a new step. The F Criterion.")
81
Applied Regression -- Prof. Juran81 If no variable can be removed, the procedure attempts to add a variable. An F -statistic is calculated for each variable not yet in the model. Suppose the model, at this stage, contains X 1,..., X p. Then the F -statistic for a new variable, X p+1 is The variable with the largest F -statistic is then added, provided its F -statistic is larger than F to enter. Adding this variable is equivalent to choosing the variable with the largest partial correlation or to choosing the variable that most effectively reduces SSE. The regression equation is then calculated, results are displayed, and the procedure goes to a new step. If no variable can enter, the stepwise procedure ends. The p -value criterion is very similar, but uses a threshold alpha value.

82
Applied Regression -- Prof. Juran82 A handy procedure that reports, for each number of independent variables p, the model with the highest R -square. Best Subsets is an efficient way to select a group of "best subsets" for further analysis by selecting the smallest subset that fulfills certain statistical criteria. The subset model may actually estimate the regression coefficients and predict future responses with smaller variance than the full model using all predictors. Best Subsets

83
Applied Regression -- Prof. Juran83 Excel’s regression utility is not well suited to iterative procedures like this. More stats-focused packages like Minitab offer a more user- friendly method. Minitab treats Forward and Backward as subsets of Stepwise. (This makes sense; they really are special cases where entered variables can’t leave, or removed variables can’t re-enter. Minitab uses the p -value criterion by default. Using Minitab

84
Applied Regression -- Prof. Juran84 Example: Rick Beck

85
Applied Regression -- Prof. Juran85

86
Applied Regression -- Prof. Juran86

87
Applied Regression -- Prof. Juran87 Need to select “regression” several times

88
Applied Regression -- Prof. Juran88

89
Applied Regression -- Prof. Juran89

90
Applied Regression -- Prof. Juran90

91
Applied Regression -- Prof. Juran91

92
Applied Regression -- Prof. Juran92

93
Applied Regression -- Prof. Juran93 Forward Selection of Terms α to enter = 0.25 Analysis of Variance Source DF Adj SS Adj MS F-Value P-Value Regression 6 39.898 6.6496 73.62 0.000 Single 1 1.618 1.6176 17.91 0.000 Divorced 1 0.141 0.1408 1.56 0.212 Credit D 1 10.280 10.2796 113.81 0.000 Credit E 1 15.691 15.6911 173.72 0.000 Children 1 0.933 0.9332 10.33 0.001 Debt 1 2.436 2.4360 26.97 0.000 Error 993 89.693 0.0903 Total 999 129.591 Model Summary S R-sq R-sq(adj) R-sq(pred) 0.300542 30.79% 30.37% 29.39%
 R-sq(pred) % 30.37% 29.39%.")
94
Applied Regression -- Prof. Juran94 Coefficients Term Coef SE Coef T-Value P-Value VIF Constant 0.1762 0.0283 6.23 0.000 Single 0.1078 0.0255 4.23 0.000 1.47 Divorced 0.0429 0.0343 1.25 0.212 1.06 Credit D 0.3377 0.0317 10.67 0.000 1.10 Credit E 0.5480 0.0416 13.18 0.000 1.08 Children -0.0750 0.0233 -3.21 0.001 1.46 Debt -0.000001 0.000000 -5.19 0.000 1.16 Regression Equation Default = 0.1762 + 0.1078 Single + 0.0429 Divorced + 0.3377 Credit D + 0.5480 Credit E - 0.0750 Children - 0.000001 Debt

95
Applied Regression -- Prof. Juran95 Regression – Regression – Best Subsets

96
Applied Regression -- Prof. Juran96

97
Applied Regression -- Prof. Juran97

98
Applied Regression -- Prof. Juran98

99
Applied Regression -- Prof. Juran99 Best Subsets Regression: Default versus Married, Divorced,... Response is Default D C C C C C M i W r r r r h a v i e e e e i I r o d d d d d l n r r o i i i i d c i c w t t t t r A o R-Sq R-Sq Mallows e e e e g m Vars R-Sq (adj) (pred) Cp S d d d A B C D n e e 1 9.4 9.3 8.9 299.3 0.34294 X 1 6.3 6.2 6.0 344.1 0.34882 X 2 13.0 12.8 12.4 250.0 0.33625 X X 2 12.0 11.8 11.2 265.1 0.33828 X X 3 25.1 24.8 24.4 79.9 0.31227 X X X 3 15.7 15.4 14.9 214.2 0.33127 X X X 4 28.0 27.7 27.1 40.2 0.30630 X X X X 4 27.5 27.3 26.7 46.2 0.30719 X X X X 5 29.3 29.0 28.1 22.8 0.30355 X X X X X 5 28.9 28.5 27.7 29.0 0.30449 X X X X X 6 30.0 29.6 28.7 15.1 0.30224 X X X X X X 6 29.7 29.2 28.4 20.0 0.30298 X X X X X X 7 30.5 30.0 29.0 10.4 0.30138 X X X X X X X 7 30.3 29.8 28.9 12.6 0.30172 X X X X X X X 8 30.7 30.1 29.1 9.2 0.30105 X X X X X X X X 8 30.6 30.1 29.0 10.1 0.30118 X X X X X X X X 9 30.8 30.2 29.1 9.5 0.30094 X X X X X X X X X 9 30.8 30.1 29.0 10.1 0.30104 X X X X X X X X X 10 30.8 30.1 29.0 11.0 0.30102 X X X X X X X X X X
 (pred) Cp S d d d A B C D n e e X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X.")
100
Applied Regression -- Prof. Juran100 Summary Chi-square Goodness-of-Fit Tests Fit to a Normal Simulation Modeling Autocorrelation, serial correlation Runs test Durbin-Watson Model Building Variable Selection Methods Minitab

Similar presentations








>")










