Download presentation
Presentation is loading. Please wait.

1
Lecture 8 Objectives Material from Chapter 9 More complete introduction of MPI functions Show how to implement manager-worker programs Parallel Algorithms for Document Classification Parallel Algorithms for Clustering

2
Outline Introduce MPI functionality Introduce problem Parallel algorithm design Creating communicators Non-blocking communications Implementation Pipelining Clustering

3
Implementation of a Very Simple Document Classifier Manager/Worker Design Strategy Manager description (create initial tasks and communicate to/from workers) Worker description (receive tasks, enter an alternating communication from/to master and computation
 Worker description (receive tasks, enter an alternating communication from/to master and computation")
4
Structure of Main program: Manager/Worker Paradigm MPI_Init (&argc, &argv); // what is my rank? MPI_Comm_rank(MPI_COMM_WORLD, &myrank); // how many processors are there? MPI_Comm_size(MPI_COMM_WORLD, &p); if (myid == 0) Manager(p); else Worker(myid, p); MPI_Barrier(MPI_COMM_WORLD); MPI_Finalize(); return(0);
; // how many processors are there. MPI_Comm_size(MPI_COMM_WORLD, &p); if (myid == 0) Manager(p); else Worker(myid, p); MPI_Barrier(MPI_COMM_WORLD); MPI_Finalize(); return(0);.")
5
More MPI functions MPI_Abort MPI_Comm_split MPI_Isend, MPI_Irecv, MPI_Wait MPI_Probe MPI_Get_count MPI_Testsome

6
MPI_Abort A “quick and dirty” way for one process to terminate all processes in a specified communicator Example use: If manager cannot allocate memory needed to store document profile vectors int MPI_Abort ( MPI_Comm comm, /* Communicator */ int error_code)/* Value returned to calling environment */
/* Value returned to calling environment */")
7
Creating a Workers-only Communicator To support workers-only broadcast, need workers-only communicator Can use MPI_Comm_split Excluded processes (e.g., Manager) passes MPI_UNDEFINED as the value of split_key, meaning it will not be part of any new communicator
 passes MPI_UNDEFINED as the value of split_key, meaning it will not be part of any new communicator")
8
Workers-only Communicator int id; MPI_Comm worker_comm;... if (!id) /* Manager */ MPI_Comm_split (MPI_COMM_WORLD, MPI_UNDEFINED, id, &worker_comm); else /* Worker */ MPI_Comm_split (MPI_COMM_WORLD, 0, id, &worker_comm);
 /* Manager */ MPI_Comm_split (MPI_COMM_WORLD, MPI_UNDEFINED, id, &worker_comm); else /* Worker */ MPI_Comm_split (MPI_COMM_WORLD, 0, id, &worker_comm);.")
9
Nonblocking Send / Receive MPI_Isend, MPI_Irecv initiate operation MPI_Wait blocks until operation complete Calls can be made early –MPI_Isend as soon as value(s) assigned –MPI_Irecv as soon as buffer available Can eliminate a message copying step Allows communication / computation overlap
 assigned –MPI_Irecv as soon as buffer available Can eliminate a message copying step Allows communication / computation overlap")
10
Function MPI_Isend int MPI_Isend ( void *buffer, int cnt, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm, MPI_Request *handle ) Pointer to object that identifies communication operation
 Pointer to object that identifies communication operation")
11
Function MPI_Irecv int MPI_Irecv ( void *buffer, int cnt, MPI_Datatype dtype, int src, int tag, MPI_Comm comm, MPI_Request *handle ) Pointer to object that identifies communication operation
 Pointer to object that identifies communication operation")
12
Function MPI_Wait int MPI_Wait ( MPI_Request *handle, MPI_Status *status ) Blocks until operation associated with pointer handle completes. status points to object containing info on received message

13
Receiving Problem Worker does not know length of message it will receive Example, the length of File Path Name Alternatives –Allocate huge buffer –Check length of incoming message, then allocate buffer We’ll take the second alternative

14
Function MPI_Probe int MPI_Probe ( int src, int tag, MPI_Comm comm, MPI_Status *status ) Blocks until message is available to be received from process with rank src with message tag tag; status pointer gives info on message size.
 Blocks until message is available to be received from process with rank src with message tag tag; status pointer gives info on message size.")
15
Function MPI_Get_count int MPI_Get_count ( MPI_Status *status, MPI_Datatype dtype, int *cnt ) cnt returns the number of elements in message
 cnt returns the number of elements in message")
16
MPI_Testsome Often need to check whether one or more messages have arrived Manager posts a nonblocking receive to each worker process Builds an array of handles or request objects Testsome allows manager to determine how many messages have arrived

17
Function MPI_Testsome int MPI_Testsome ( int in_cnt, /* IN - Number of nonblocking receives to check */ MPI_Request *handlearray, /* IN - Handles of pending receives */ int *out_cnt, /* OUT - Number of completed communications */ int *index_array, /* OUT - Indices of completed communications */ MPI_Status *status_array) /* OUT - Status records for completed comms */
 /* OUT - Status records for completed comms */")
18
Document Classification Problem Search directories, subdirectories for documents (look for.html,.txt,.tex, etc.) Using a dictionary of key words, create a profile vector for each document Store profile vectors
 Using a dictionary of key words, create a profile vector for each document Store profile vectors")
19
Data Dependence Graph (1)
")
20
Partitioning and Communication Most time spent reading documents and generating profile vectors Create two primitive tasks for each document

21
Data Dependence Graph (2)
")
22
Agglomeration and Mapping Number of tasks not known at compile time Tasks do not communicate with each other Time needed to perform tasks varies widely Strategy: map tasks to processes at run time

23
Manager/worker-style Algorithm 1.Task/Functional Partitioning 2.Domain/Data Partitioning

24
Roles of Manager and Workers

25
Manager Pseudocode Identify documents Receive dictionary size from worker 0 Allocate matrix to store document vectors repeat Receive message from worker if message contains document vector Store document vector endif if documents remain then Send worker file name else Send worker termination message endif until all workers terminated Write document vectors to file

26
Worker Pseudocode Send first request for work to manager if worker 0 then Read dictionary from file endif Broadcast dictionary among workers Build hash table from dictionary if worker 0 then Send dictionary size to manager endif repeat Receive file name from manager if file name is NULL then terminate endif Read document, generate document vector Send document vector to manager forever

27
Task/Channel Graph

28
Enhancements Finding middle ground between pre- allocation and one-at-a-time allocation of file paths Pipelining of document processing

29
Allocation Alternatives Documents Allocated per Request n/p Load imbalance 1 Excessive communication overhead Time

30
Pipelining

31
Time Savings through Pipelining

32
Pipelined Manager Pseudocode a 0 {assigned jobs} j 0 {available jobs} w 0 {workers waiting for assignment} repeat if (j > 0) and (w > 0) then assign job to worker j j – 1; w w – 1; a a + 1 elseif (j > 0) then handle an incoming message from workers increment w else get another job increment j endif until (a = n) and (w = p)
 and (w > 0) then assign job to worker j j – 1; w w – 1; a a + 1 elseif (j > 0) then handle an incoming message from workers increment w else get another job increment j endif until (a = n) and (w = p)")
33
Summary Manager/worker paradigm –Dynamic number of tasks –Variable task lengths –No communications between tasks New tools for “kit” –Create manager/worker program –Create workers-only communicator –Non-blocking send/receive –Testing for completed communications Next Step: Cluster Profile Vectors

34
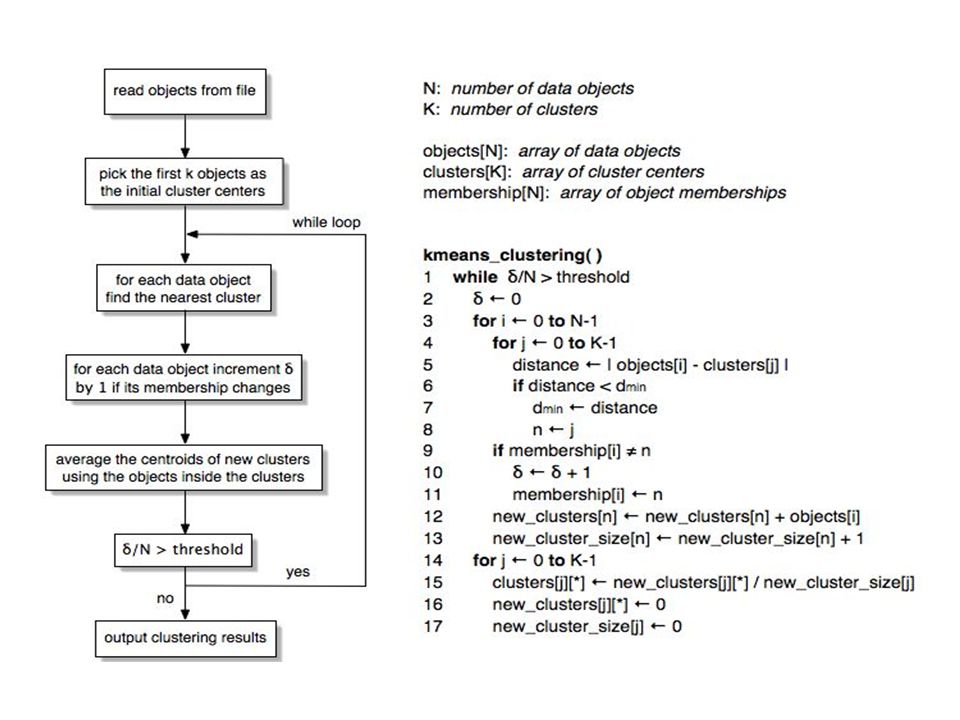
K-Means Clustering Assumes documents are real-valued vectors. Assumes distance function on vector pairs Clusters based on centroids (aka the center of gravity or mean) of points in a cluster, c: Reassignment of instances to clusters is based on distance of vector to the current cluster centroids. –(Or one can equivalently phrase it in terms of similarities)
 of points in a cluster, c: Reassignment of instances to clusters is based on distance of vector to the current cluster centroids. –(Or one can equivalently phrase it in terms of similarities).")
35
K-Means Algorithm Let d be the distance measure between instances. Select k random instances {s 1, s 2,… s k } as seeds. Until clustering converges or other stopping criterion: For each instance x i : Assign x i to the cluster c j such that d(x i, s j ) is minimal. // Now Update the seeds to the centroid of each cluster) For each cluster c j s j = (c j )
 is minimal. // Now Update the seeds to the centroid of each cluster) For each cluster c j s j = (c j ).")
36
K Means Example (K=2) Pick seeds Reassign clusters Compute centroids x x Reassign clusters x x x x Compute centroids Reassign clusters Converged!
 Pick seeds Reassign clusters Compute centroids x x Reassign clusters x x x x Compute centroids Reassign clusters Converged!")
37
Termination conditions Desire that docs in a cluster are unchanged Several possibilities, e.g., –A fixed number of iterations. –Doc partition unchanged. –Centroid positions don’t change. –We’ll choose termination when only small fraction change (threshold value)
.")
39
Quiz: –Describe Manager/Worker pseudo-code that implements the K-means algorithm in parallel –What data partitioning for parallelism? –How are cluster centers updated and distributed?

40
Hints –objects to be clustered are evenly partitioned among all processes –cluster centers are replicated –Global-sum reduction on cluster centers is performed at the end of each iteration to generate the new cluster centers. –Use MPI_Bcast and MPI_Allreduce

Similar presentations

 { int my_rank, ncpus; int left_neighbor, right_neighbor; int data_received=-1;>")











>")





