Download presentation
Presentation is loading. Please wait.

1
The Basics: Pipelining J. Nelson Amaral University of Alberta 1

2
The Pipeline Concept Bauer p. 32 2

3
3 Pipeline Throughput and Latency IFIDEXMEMWB 5 ns4 ns5 ns10 ns4 ns Consider the pipeline above with the indicated delays. We want to know what is the pipeline throughput and the pipeline latency. Pipeline throughput: instructions completed per second. Pipeline latency: how long does it take to execute a single instruction in the pipeline.

4
4 Pipeline Throughput and Latency IFIDEXMEMWB 5 ns4 ns5 ns10 ns4 ns Pipeline throughput: how often is an instruction completed? Pipeline latency: how long does it take to execute an instruction in the pipeline? Is this right?

5
5 Pipeline Throughput and Latency IFIDEXMEMWB 5 ns4 ns5 ns10 ns4 ns Simply adding the latencies to compute the pipeline latency, only would work for an isolated instruction IFMEMID I1 L(I1) = 28ns EXWB MEMID IF I2 L(I2) = 33ns EXWB MEMID IF I3 L(I3) = 38ns EXWB MEMID IF I4 L(I5) = 43ns EXWB We are in trouble! The latency is not constant. This happens because this is an unbalanced pipeline. The solution is to make every stage the same length as the longest one.

6
6 Pipeline Throughput and Latency IFIDEXMEMWB 5 ns4 ns5 ns10 ns4 ns The slowest pipeline state also limits the latency!! IFMEMID I1 L(I1) = L(I2) = L(I3) = L(I4) = 50ns EXWB IFMEMID I2 L(I2) = 50ns EXWB IFMEMIDEXWB IFMEMIDEX 0102030405060 I3 I4
 = L(I2) = L(I3) = L(I4) = 50ns EXWB IFMEMID I2 L(I2) = 50ns EXWB IFMEMIDEXWB IFMEMIDEX I3 I4.")
7
7 Pipeline Throughput and Latency IFIDEXMEMWB 5 ns4 ns5 ns10 ns4 ns How long does it take to execute 20000 instructions in this pipeline? (disregard bubbles caused by branches, cache misses, and hazards) How long would it take using the same modules without pipelining? What is the speedup due to pipelining?
 How long would it take using the same modules without pipelining. What is the speedup due to pipelining .")
8
8 Pipeline Throughput and Latency IFIDEXMEMWB 5 ns4 ns5 ns10 ns4 ns The speedup that we got from the pipeline is: How can we improve this pipeline design? We need to reduce the unbalance to increase the clock speed.

9
9 Pipeline Throughput and Latency IFIDEX MEM1 WB 5 ns4 ns5 ns 4 ns Now we have one more pipeline stage. What is the throughput now? MEM2 5 ns What is the new latency for a single instruction?

10
10 Pipeline Throughput and Latency IFIDEX MEM1 WB 5 ns4 ns5 ns 4 ns MEM2 5 ns IF MEM1 ID I1 EXWB MEM1 IF MEM1 ID I2 EXWB MEM1 IF MEM1 ID I3 EXWB MEM1 IF MEM1 ID I4 EXWB MEM1 IF MEM1 ID I5 EXWB MEM1 IF MEM1 ID I6 EXWB MEM1 IF MEM1 ID I7 EXWB MEM1

11
11 Pipeline Throughput and Latency IFIDEX MEM1 WB 5 ns4 ns5 ns 4 ns MEM2 5 ns How long does it take to execute 20000 instructions in this pipeline? (disregard bubles caused by branches, cache misses, etc, for now) What is the speedup that we get from pipelining?
 What is the speedup that we get from pipelining .")
12
12 Pipeline Throughput and Latency IFIDEX MEM1 WB 5 ns4 ns5 ns 4 ns MEM2 5 ns What have we learned from this example? 1. It is important to balance the delays in the stages of the pipeline 2. The throughput of a pipeline is 1/max(delay). 3. The latency is N max(delay), where N is the number of stages in the pipeline.
. 3. The latency is N max(delay), where N is the number of stages in the pipeline..")
13
Execution Snapshot Bauer p. 33 13

14
Pipeline with Control Unit Bauer p. 34 14

15
Data Hazards and Forwarding Example 1: i:R7 ← R12 + R15 i+1:R8 ← R7 – R12 i+2:R15 ← R8 + R7 Read-After-Write (RAW) dependencies (true dependencies) Write-After-Read (WAR) dependencies (anti dependencies) Bauer p. 35 15

16
Data Hazards and Forwarding v v v Bauer p. 36 16

17
Forwarding Bauer p. 37 17

18
Load-ALU RAW Dependency Example 2: i:R6 ← Mem[R2] i+1:R7 ← R6 + R4 The data from the load is not available until the Mem/WB of instruction i, but it is needed at the ID/EX of instruction i+1 Cannot forward back on time! Bauer p. 36 18
![Load-ALU RAW Dependency Example 2: i:R6 ← Mem[R2] i+1:R7 ← R6 + R4 The data from the load is not available until the Mem/WB of instruction i, but it is needed at the ID/EX of instruction i+1 Cannot forward back on time.](http://images.slideplayer.com/16/5190190/slides/slide_18.jpg "Bauer p")
19
Bubble because of load Bauer p. 38 19

20
Priority on Forwarding Example: i:R10 ← R4 + R5 i+1:R10 ← R4 – R10 i+2:R8 ← R10 + R7 The RAW from i+1 to i+2 must take priority over the RAW from i to i+2. Bauer p. 38 20

21
Forwarding from Mem/WB to Mem Example: i:R5 ← Mem[R6] i+1:Mem[R8] ← R5 Bauer p. 39 21 After the load, the contents of the Mem/WB register must be forwarded to be written to memory (not only to R5).
![Forwarding from Mem/WB to Mem Example: i:R5 ← Mem[R6] i+1:Mem[R8] ← R5 Bauer p.](http://images.slideplayer.com/16/5190190/slides/slide_21.jpg "After the load, the contents of the Mem/WB register must be forwarded to be written to memory (not only to R5)..")
22
Pipelining with Forwarding and Stall Bauer p. 38 22

23
Control Hazards (branches) Bauer p. 40 23
 Bauer p")
24
Control Hazards: Exceptions and Interruptions Exceptions can occur in any stage (except WB) – IF: page faults – ID: Illegal opcodes – EX: arithmetic exceptions – Mem: illegal address, page faults Interruptions: – I/O termination, time-outs – Power failures Bauer p. 40 24

25
Handling Exceptions/Interruptions Save the Process State Schedule Process Restart Clear Exception Condition Abort Program “Correct” Exception “Correct” Exception Perform Unrelated Task ? Bauer p. 41 25

26
Precise Exceptions in a Pipeline If an exceptions happens in instruction i: Instructions i-1, i-2, … complete normally and contribute to the saved state of the process Instructions i, i+1, i+2, … become no-ops After the exception is handled, execution re-starts at instruction i – The PC saved is the PC of instruction i. Bauer p. 41 26 i i-1 i-2 i+2 i+1 ⋅⋅⋅ Complete normally no-op Exception happens here → ←Execution re-starts here

27
Implementing Precise Exceptions in the Pipeline 1.Flag the pipeline register at the right of the stage where exception was detected – This Flag moves along the pipeline 2.Set all control lines at a stage with the flag to transform the instruction into a no-op 3.Stop instruction fetching 4.When the flag reaches the Mem/WB stage, save the PC of that instruction as the exception PC Bauer p. 41 27

28
Program Order X Temporal Order divide-by-zero exception page-fault exception Which exception occurs first in time? Which exception should be handled first? Bauer p. 41 28

29
Bauer p. 38 29 Design Issues: Can’t avoid Load/ALU instr. bubble Branch resolution in EX stage → Two-cycle branch penalty Mem stage unused for ALU instr

30
Alternative Pipelining Design: Avoiding the load latency penalty Example: i: R4 ← Mem[R8] i+1: R7 ← R4 + R5 Bauer p. 43 30
![Alternative Pipelining Design: Avoiding the load latency penalty Example: i: R4 ← Mem[R8] i+1: R7 ← R4 + R5 Bauer p.](http://images.slideplayer.com/16/5190190/slides/slide_30.jpg)
31
Avoiding the load latency penalty Example: i: R4 ← Mem[R8] i+1: R7 ← R4 + R5 Bauer p. 43 31
![Avoiding the load latency penalty Example: i: R4 ← Mem[R8] i+1: R7 ← R4 + R5 Bauer p](http://images.slideplayer.com/16/5190190/slides/slide_31.jpg "Avoiding the load latency penalty Example: i: R4 ← Mem[R8] i+1: R7 ← R4 + R5 Bauer p")
32
Address Generation Latency Penalty Example: i: R5 ← R6 + R7 i+1: R9 ← Mem[R5] Can’t forward from future. Has to stall. Bauer p. 43 32
![Address Generation Latency Penalty Example: i: R5 ← R6 + R7 i+1: R9 ← Mem[R5] Can’t forward from future.](http://images.slideplayer.com/16/5190190/slides/slide_32.jpg "Has to stall. Bauer p")
33
Other changes AG used for branch resolution AG unused for ALU operations Bauer p. 43 33

34
Tradeoffs: Bauer p. 43 34 Avoids load/ALU bubble X additional ALU unit Move branch resolution to AG → same penalty AG stage unused for ALU operations Stalls for ALU/Store instr. dependency

35
Which one is better? MIPS Intel 486 Bauer p. 44 35

36
Pipelining Functional Units: the EX stage Parameters of interest: – number of stages – minimum number of cycles before two independent (no RAW) instructions of the same type can enter the functional unit Bauer p. 44 36

37
Single-Precision Floating Point Representation Most standard floating point representation use: 1 bit for the sign (positive or negative) 8 bits for the range (exponent field) 23 bits for the precision (fraction field) SEF 2381 From: Patt and Patel, pp. 33 P-H. p. 245 Bauer p. 45 exponent fraction sign 37

38
Special Floating Point Representations In the 8-bit field of the exponent we can represent numbers from 0 to 255. We studied how to read numbers with exponents from 0 to 254. What is the value represented when the exponent is 255 (i.e. 11111111 2 )? An exponent equal 255 = 11111111 2 in a floating point representation indicates a special value. When the exponent is equal 255 = 11111111 2 and the fraction is 0, the value represented is infinity. When the exponent is equal 255 = 11111111 2 and the fraction is non-zero, the value represented is Not a Number (NaN). Hen/Patt, pp. 301 P-H. p. 246 Bauer p. 45 38
. An exponent equal 255 = in a floating point representation indicates a special value. When the exponent is equal 255 = and the fraction is 0, the value represented is infinity. When the exponent is equal 255 = and the fraction is non-zero, the value represented is Not a Number (NaN). Hen/Patt, pp. 301 P-H. p. 246 Bauer p")
39
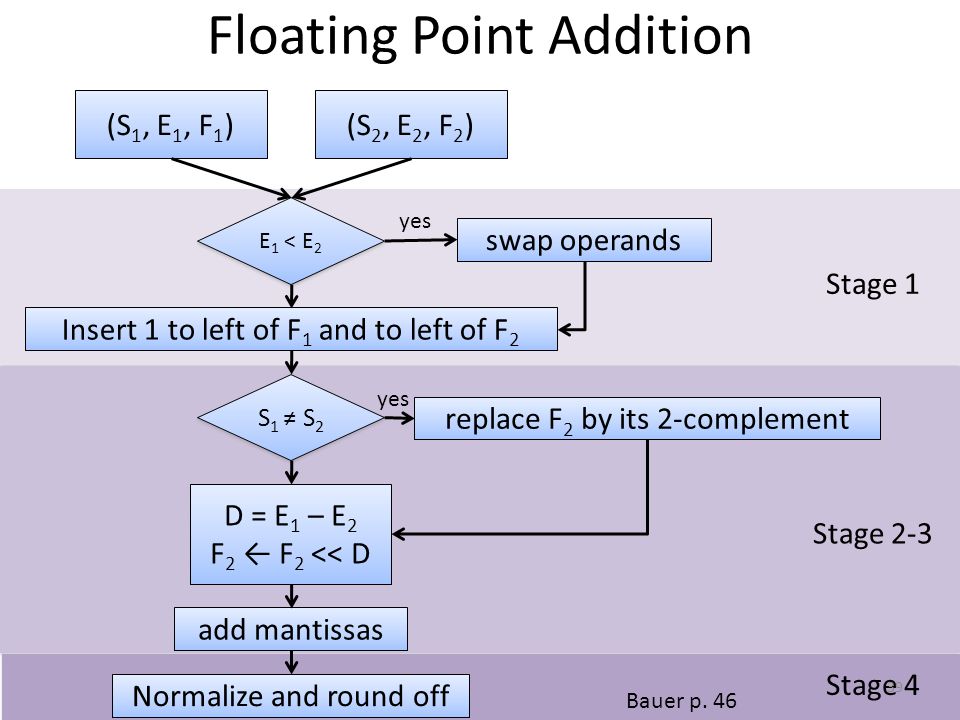
Stage 1 Stage 2-3 Stage 4 Floating Point Addition (S 1, E 1, F 1 )(S 2, E 2, F 2 ) E 1 < E 2 Insert 1 to left of F 1 and to left of F 2 S 1 ≠ S 2 D = E 1 – E 2 F 2 ← F 2 << D add mantissas Normalize and round off swap operands yes replace F 2 by its 2-complement yes Bauer p. 46 39
Similar presentations


Define pipelining 2)Calculate the speedup achieved by pipelining for a given number of instructions. 3)Define how pipelining improves.>")


>")










 with each A i taking approximately.>")


