Download presentation
Presentation is loading. Please wait.

1
Introduction to Bioinformatics - Tutorial no. 12
Expression Data Analysis: - Clustering - GEO - EPClust

2
Application of Microarrays
We only know the function of about 20% of the 30,000 genes in the Human Genome Gene exploration Faster and better Applications: Evolution Behavior Cancer Research

3
Microarray Analysis Unsupervised Grouping: Clustering
Pattern discovery via grouping similarly expressed genes together Three techniques most often used k-Means Clustering Hierarchical Clustering Kohonen Self Organizing Feature Maps

4
Hierarchical Agglomerative Clustering
Michael Eisen, 1998 Cluster (algorithm) TreeView (visualization) Hierarchical Agglomerative Clustering Step 1: Similarity score between all pairs of genes Pearson Correlation Euclidean distance Step 2: Find the two most similar genes, replace with a node that contains the average Builds a tree of genes Step 3: Repeat
 TreeView (visualization) Hierarchical Agglomerative Clustering. Step 1: Similarity score between all pairs of genes. Pearson Correlation. Euclidean distance. Step 2: Find the two most similar genes, replace with a node that contains the average. Builds a tree of genes. Step 3: Repeat.")
5
Agglomerative Hierarchical Clustering
Need to define the distance between the new cluster and the other clusters. Single Linkage: distance between closest pair. Complete Linkage: distance between farthest pair. Average Linkage: average distance between all pairs or distance between cluster centers Agglomerative Hierarchical Clustering Distance between joined clusters 5 2 4 3 1 4 2 5 1 3 The dendrogram induces a linear ordering of the data points Dendrogram

6
Results of Clustering Gene Expression
CLUSTER is simple and easy to use De facto standard for microarray analysis Limitations: Hierarchical clustering in general is not robust Genes may belong to more than one cluster

7
K-Means Clustering Algorithm
Randomly initialize k cluster means Iterate: Assign each genes to the nearest cluster mean Recompute cluster means Stop when clustering converges Notes: Really fast Genes are partitioned into clusters How do we select k?

8
K-Means Algorithm Randomly Initialize Clusters

9
K-Means Algorithm Assign data points to nearest clusters

10
K-Means Algorithm Recalculate Clusters

11
K-Means Algorithm Recalculate Clusters

12
K-Means Algorithm Repeat

13
K-Means Algorithm Repeat

14
K-Means Algorithm Repeat … until convergence

16
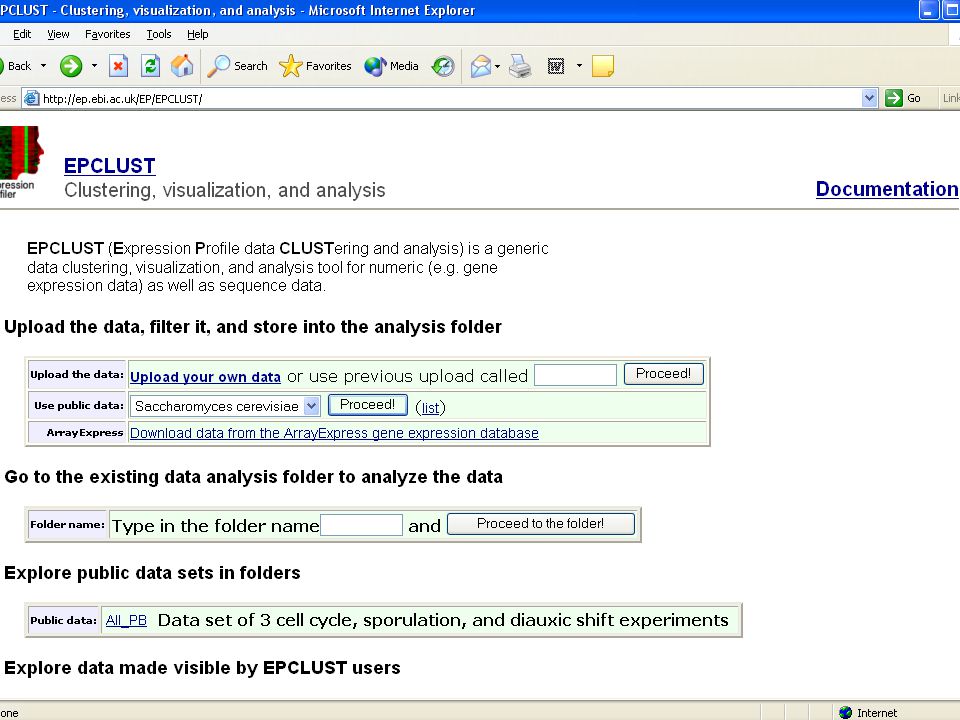
EPClust Input (1) Expression data matrix
Extra annotation for gene rows Method of tabulation Name for further analysis

17
EPClust Input (2) Method of measuring distance between gene rows
Cluster hierarchically Number k of means Cluster into k means

18
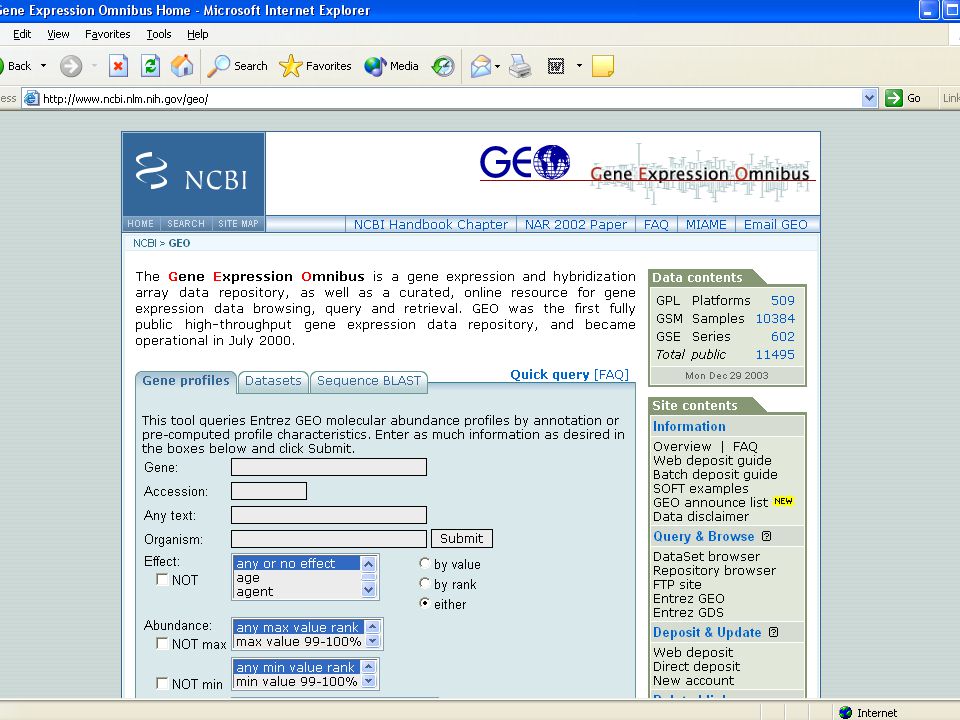
GEO: Gene Expression Omnibus
NCBI database for gene expression data Founded at end of 2000

20
Querying GEO Browse records Search for entries containing a gene
Search for experiments Search with Entrez

21
SGD – Expression database
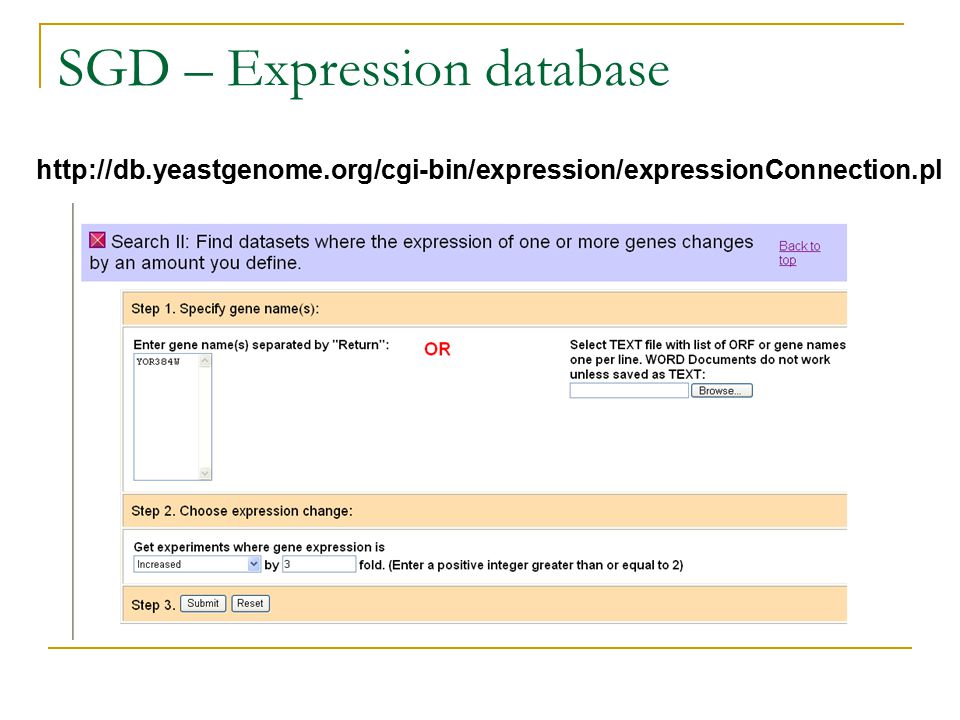
22
SGD – Expression database

23
SGD – Expression database

24
SGD – Expression database

25
Gene grouping Relative values
Two labs are running experiments on the APO1 gene. Suggest a method that would allow them to compare their results. Gene grouping Relative values

26
+ - Explain how microarrays can be used as a basis for diagnostic
Sample 1 Sample 2 Sample 3 sample4 Sample 5 Gen1 + - Gen2 Gen3 Gen4 Gen5

27
+ - Explain how microarrays can be used as a basis for diagnostic
Sample 1 Sample 2 sample4 Sample 3 Sample 5 Gen1 + - Gen2 Gen3 Gen4 Gen5

Similar presentations


 March 19, 2004 ChengXiang Zhai Department of Computer Science University.>")
>")



 IDENTIFY DIFFERENTIATING GENES Basic.>")




 Vipin Kumar Army High Performance.>")






