Download presentation
Presentation is loading. Please wait.

1
Minimum Error Rate Training in Statistical Machine Translation By: Franz Och, 2003 Presented By: Anna Tinnemore, 2006

2
GOAL To directly optimize translation quality WHY?? No direct correlation in popular evaluation criteria F-Measure (parsing) Mean Average Precision (ranked retrieval) BLEU—multi-reference word error rate (statistical machine translation)
 Mean Average Precision (ranked retrieval) BLEU—multi-reference word error rate (statistical machine translation).")
3
Problem: The difference in classification of error between the statistical approach and the automatic evaluation methods. Solution (maybe): optimize model parameters according to individual evaluation methods
: optimize model parameters according to individual evaluation methods.")
4
Background Optimal under “zero-one loss function” A different metric would have a different optimal decision rule

5
Background, continued Problems: finding suitable feature functions (M) and parameter values(λ) MMI (max mutual info) One unique global optimum Algorithms guaranteed to find it Optimal translation quality?
 and parameter values(λ) MMI (max mutual info) One unique global optimum Algorithms guaranteed to find it Optimal translation quality")
6
So what? Review automatic evaluation criteria Two training criteria that might help New training algorithm for optimizing an unsmoothed error count Och’s approach Evaluation of training criteria

7
Translation quality metrics mWER –(multi-reference word error rate) Compute edit distance to closest ref. transl. mPER – (multi-reference position independent error rate) bag of words, edit distance BLEU The mean of the precision of n-grams NIST Weighted precision of n-grams
 bag of words, edit distance BLEU The mean of the precision of n-grams NIST Weighted precision of n-grams.")
8
Training Minimize error rate Problems: argmax operation (6)- no global optimum Many local optima
- no global optimum Many local optima")
9
Smoothed Error Count This is easier to deal with than last function, but still tricky Performance doesn’t change much with smoothing

11
Unsmoothed Error Count Standard: Powell’s algorithm – grid-based line optimization Fine-grained grid: slow Large grid: miss optimal solution NEW: Log-linear model Guaranteed to find the optimal solution Much faster and more stable

12
New Algorithm Each candidate translation in C corresponds to a line (t and m are constants) Piecewise linear
 Piecewise linear")
13
Algorithm: the nitty-gritty For every f : Compute ordered sequence of linear intervals that make up f (γ;f) Compute each change in error count between intervals Merge all sequences γ f and ΔE f Traverse the sequence of boundaries while keeping track of error count to find the optimal γ
 Compute each change in error count between intervals Merge all sequences γ f and ΔE f Traverse the sequence of boundaries while keeping track of error count to find the optimal γ")
14
Baseline Same as alignment template approach This model, log-linear, had M = 8 features Extract n-best candidate translations from all possible translations Wait a minute...

15
N-best??? Overfitting? Unseen data? First, compute n-best list using “made-up” parameter values. Use this list to train model for new parameters. Second, use new parameters, do new search, make new n-best list, append to old n-best list Third, use new list to train model for even better parameters

16
Keep going until the n-best list doesn’t change – all possible translations are in list Each iteration generates approx. 200 additional translations The algorithm only takes 5-7 iterations to converge

17
Additional Sneaky Stuff Problems with MMI (maximum mutual info) Reference sentences have to be part of n-best list Solution: Fake reference sentences, of course Select from the n-best list, those sentences with the fewest word errors with respect to the REAL references, and call these: “pseudo-references”
 Reference sentences have to be part of n-best list Solution: Fake reference sentences, of course Select from the n-best list, those sentences with the fewest word errors with respect to the REAL references, and call these: pseudo-references")
18
Experiment 2002 TIDES Chinese- English small data track task News text from Chinese to English Note: no rule-based components used to translate numbers, dates, or names

19
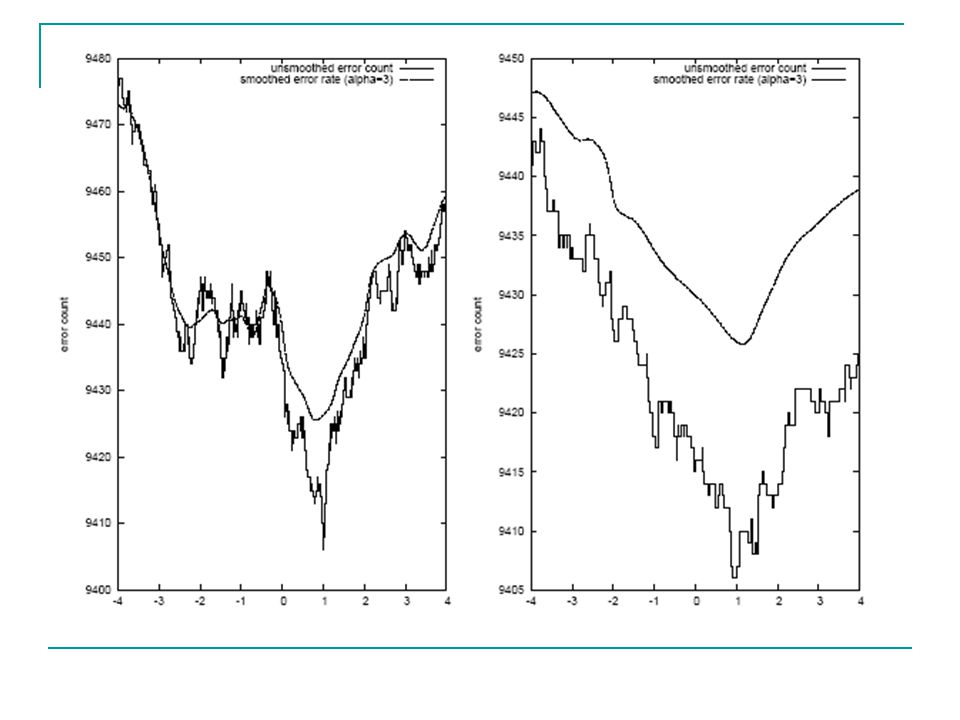
Development Corpus Results

20
Test Corpus Results

21
Conclusions Alternative training criteria which directly relate to quality of translation Unsmoothed and smoothed error count on development corpus Optimizing error rate in training yields better results on unseen test data Maybe ‘true’ translation quality is also increased We don’t know because the evaluation metrics need help

22
Future Questions How many parameters can be reliably estimated using differing criteria on development corpuses (corpi) of various sizes? Does the criteria used make a difference? Which error rate criteria (smooth/unsmooth) should be optimized in training?
 should be optimized in training .")
23
Boasting This approach applies to any evaluation technique If the evaluation methods ever get better, this algorithm will yield correspondingly better results

24
Side-stepping It’s possible that this algorithm could be used to “overfit” the evaluation method, giving falsely inflated scores It’s not our problem. The developers of the evaluation methods should develop so this can’t happen

25
... And Around The World This algorithm has a place wherever evaluation methods are used It could yield improvements in these other areas as well

26
Questions, observations, accolades...

27
My Observations Improvements do not seem significant This exposes a problem in the evaluation metrics, but does nothing to solve it Seems like a good idea, but has many unanswered questions regarding optimal implementation

28
THANK YOU and Good Night!

Similar presentations




>")
, take home, turn in at noon time of 03/02 (Friday)>")





 or Orange: a.>")







