Download presentation
Presentation is loading. Please wait.

1
PPA 415 – Research Methods in Public Administration Lecture 9 – Bivariate Association

2
Statistical Significance and Theoretical Significance Tests of significance detect nonrandom relationships. Measures of association go one step farther and provide information on the strength and direction of relationships.

3
Statistical Significance and Theoretical Significance Measures of association allow us to achieve two goals: Trace causal relationships among variables. But, they cannot prove causality. Predict scores on the dependent variable based on information from the independent variable.

4
Bivariate Association and Bivariate Tables Two variables are said to be associated if the distribution of one of them changes under the various categories or scores of the other. Liberals are more likely to vote for Democratic candidates than for Republican Candidates. Presidents are more likely to grant disaster assistance when deaths are involved than when there are no deaths.

5
Bivariate Association and Bivariate Tables Bivariate tables are devices for displaying the scores of cases on two different variables. Independent or X variable in the columns. Dependent variable or Y variable in the rows. Each column represents a category on the independent variable. Each row represents a category on the dependent variable. Each cell represents those cases that fall into each combination of categories.

6
Bivariate Association and Bivariate Tables Each column’s frequency distribution is called a conditional distribu- tion of Y.

7
Bivariate Association and Bivariate Tables Often you will calculate a chi-square when you generate table. If chi-square is zero, then there is no association. Usually, however, chi-square is positive to some degree. Statistical significance is not the same as association. It is, however, usually the case that significance is the first step in determining the strength of association.

8
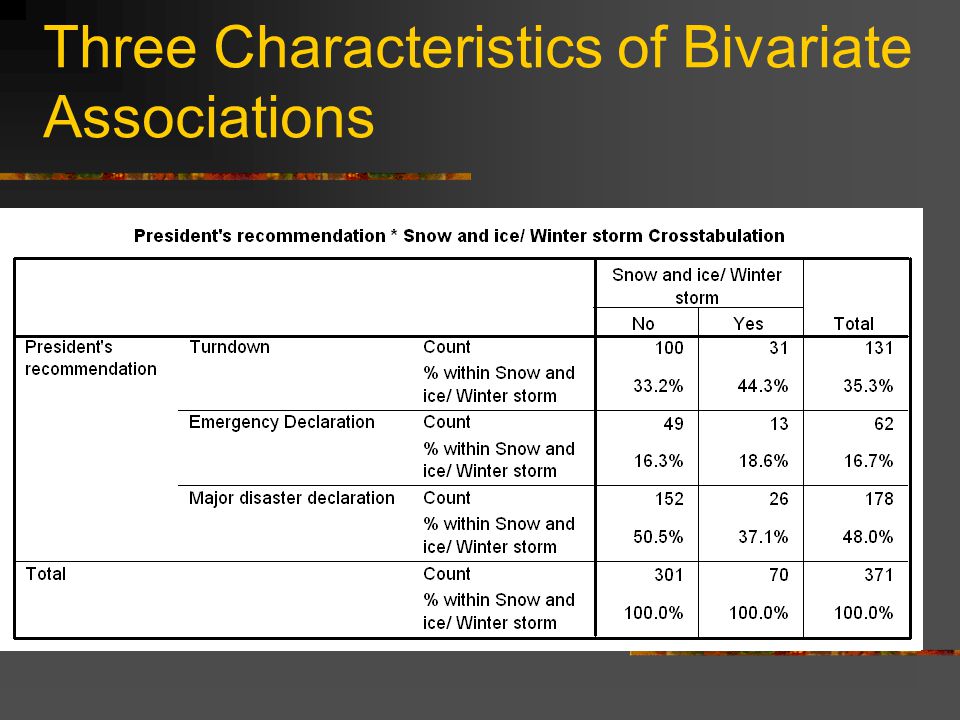
Three Characteristics of Bivariate Associations Does an association exist? Statistical significance the first step. Calculate column percentages and compare across conditional distributions. If there is an association, the largest cell will change from column to column. If there is no association, the conditional percentages will not change.

9
Three Characteristics of Bivariate Associations How strong is the association? Once we establish the existence of an association, we need to determine how strong it is? A matter of measuring the changes across conditional distributions. No association – no change in column percentages. Perfect association – each value of the independent variable is associated with one and only one value of the dependent variable. The huge majority of relationships fall in between.

10
Three Characteristics of Bivariate Associations How strong is the association (contd.)? Virtually all statistics of association are designed to vary between 0 for no association and +1 for perfect association (±1 for ordinal and interval data). The meaning of the statistics varies a little from statistic to statistics, but 0 signifies no association and 1 signifies perfect association in all cases.
. The meaning of the statistics varies a little from statistic to statistics, but 0 signifies no association and 1 signifies perfect association in all cases..")
11
Three Characteristics of Bivariate Associations What is the pattern and/or direction of the association? Pattern is determined by examining which categories of X are associated with which categories of Y. Direction only matters for ordinal and interval-ratio data. In positive association, low values on one variable are associated with low values on the other and high with high. On negative association, low values on variable are associated with high values on the other and vice versa.

12
Three Characteristics of Bivariate Associations

14
Nominal Association – Chi- Square Based The five-step model is calculated using chi-square.

15
Nominal Association – Chi- Square Based

16
Nominal Association – Chi- Square-Based

17
Nominal Association – Proportional Reduction in Error The logic of proportional reduction in error (PRE) involves first attempting to guess or predict the category into which each case will fall on the dependent variable without using information from the independent variable. The second step involves using the information on the conditional distribution of the dependent variable within categories of the independent variable to reduce errors in prediction.

18
Nominal Association – Proportional Reduction in Error If there is a strong association, there will be a substantial reduction in error from knowing the joint distribution of X and Y. If there is no association, there will be no reduction in error.

19
Nominal Association – PRE - Lambda Prediction rule: Predict that all cases fall the largest category. Where E 1 is the number of prediction errors without knowing X. And E 2 is the number of prediction errors knowing the distribution On X.

20
Nominal Association – PRE - Lambda E 1 is calculated by subtracting the cases in the largest category of the row marginals from the total number of cases. E 2 is calculated by subtracting the largest category in each column from the column total and summing across columns of the independent variable.

21
Nominal Association – PRE - Lambda

23
The key problem with lambda occurs when the distribution on one of the variables is lopsided (many cases in one category and few cases in the others). Under those circumstances, lambda can equal zero, even when there is a relationship.

24
Nominal Association – PRE – Goodman and Kruskal’s Tau b A better coefficient of association is Goodman and Kruskal’s tau b, which is also PRE. Instead of assuming that the person making the prediction will always select the largest category in each column, tau b assumes that the researcher will select cases based on their actual distribution in the column. For example, on a three-category variable with 40% of the cases in category 1, 30% in category 2, and 30% in category 3, E 1 would be 60%N 1 +70%N 2 +70%N 3.

25
Nominal Association – PRE – Goodman and Kruskal’s Tau b

28
Nominal Association The five-step test of significance for both the chi-square-based statistics and the PRE statistics is chi-square.

29
Ordinal Association Some ordinal variables have many categories and look like interval variables. These can be called continuous ordinal variables. The appropriate ordinal association statistic is Spearman’s rho. Some ordinal variables have only a few categories and can be called collapsed ordinal variables. The appropriate ordinal association statistic is gamma and the other tau-class statistics.

30
The Computation of Gamma and Other Tau-class Statistics These measures of association compare each case to every other case. The total number of pairs of cases is equal to N(N- 1)/2.
/2..")
31
The Computation of Gamma and Other Tau-class Statistics There are five classes of pairs: C or N s : Pairs where one case is higher than the other on both variables. D or N d : Pairs where one case is higher on one variable and lower on the other. T y : Pairs tied on the dependent variable but not the independent variable. T x : Pairs tied on the independent variable but not the dependent variable. T xy :Pairs tied on both variables.

32
The Computation of Gamma and Other Tau-class Statistics To calculate C, start in the upper left cell and multiply the frequency in each cell by the total of all frequencies to right and below the cell in the table. To calculate D, start in the upper right cell and multiply the frequency in each cell by the total of all frequencies to the left and below the cell in the table.

33
The Computation of Gamma and Other Tau-class Statistics To calculate Tx, start in the upper left cell and multiply the frequency in each cell by the total of all frequencies directly below the cell. To calculate Ty, start in the upper left cell and multiple the frequency in each cell by the total of all frequencies directly to the right of the cell.

34
The Computation of Gamma and Other Tau-class Statistics To calculate Txy, start in the upper left cell and multiply N(N-1)/2 for each cell.
/2 for each cell.")
35
Gamma Example – JCHA 2000

36
Gamma and its associated statistics can have a PRE interpretation.

37
Gamma Example – JCHA 2000

38
The Computation of Spearman’s Rho Suppose we wished to test whether Democratic and Republican thermometer ratings from the NES are inversely related. Because these scores are measured on a 100-point scale, we can use Spearman’s rho test the strength of the relationship. Fewer categorical ties.

39
The Computation of Spearman’s Rho

41
The Five-Step Test for Gamma Step 1. Making assumptions. Random sampling. Ordinal measurement. Normal sampling distribution. Step 2 – Stating the null hypothesis. H 0 : γ=0.0 H 1 : γ 0.0

42
The Five-Step Test for Gamma Step 3. Selecting the sampling distribution and establishing the critical region. Sampling distribution = Z distribution. Alpha =.05. Z (critical) = ±1.96.
 = ±")
43
The Five-Step Test for Gamma Step 4. Computing the test statistic. Step 5. Making a decision. Z(obtained) is less than Z(critical). Fail to reject the null hypothesis that gamma is zero in the population. There is no relationship between race and the feeling of safety at home based on the JCHA 2000 sample.
 is less than Z(critical). Fail to reject the null hypothesis that gamma is zero in the population. There is no relationship between race and the feeling of safety at home based on the JCHA 2000 sample..")
44
The Five-Step Test for Spearman’s Rho. Step 1. Making assumptions. Random sampling. Ordinal measurement. Normal sampling distribution. Step 2 – Stating the null hypothesis. H 0 : ρ s =0.0 H 1 : ρ s 0.0

45
The Five-Step Test for Spearman’s Rho. Step 3. Selecting the sampling distribution and establishing the critical region. Sampling distribution = t distribution. Alpha =.05. Degrees of freedom = N – 2 = 15 – 2 = 13 t (critical) = ±2.160.
 = ±")
46
The Five-Step Test for Spearman’s Rho. Step 4. Computing the test statistic. Step 5. Making a decision. T(obtained) < t(critical). Fail to reject the null hypothesis. There is no relationship between the Democratic and Republican thermometers.
 < t(critical). Fail to reject the null hypothesis. There is no relationship between the Democratic and Republican thermometers..")
Similar presentations





 There are two types of hypothesis : 1) Simple hypothesis :A statistical.>")


 and dependant (Y) variables.>")




 Tests Chi-Square.>")









