Download presentation
Presentation is loading. Please wait.

1
Features and Unification
Grammatical Categories (e.g. Non3sgAux, 3sgNP) and grammar rules (S-> NP VP) can be thought of as objects that have complex set of properties associated with them. These properties are represented as constraints (constraint-based formalisms) Such formalisms are efficient for representing language phenomena such as agreement and subcategorizations that cannot be handled by CFGs in an efficient way.
 and grammar rules (S-> NP VP) can be thought of as objects that have complex set of properties associated with them. These properties are represented as constraints (constraint-based formalisms) Such formalisms are efficient for representing language phenomena such as agreement and subcategorizations that cannot be handled by CFGs in an efficient way.")
2
Features and Unification
e.g. a NP may have a property NUMBER and a VP may have a similar property, and agreement is then implemented by comparing these two properties. In that case the grammar rule S-> NP VP is extended with the constraint Only if the NUMBER of NP is equal to the number of VP The formalization of such constraints and of properties such as NUMBER are unification and feature structures.

3
Feature Structures Feature Structures (FS) is a method for encoding the grammatical properties. They are simply sets of feature-value pairs, where features are unanalyzable atomic symbols and values are either atomic symbols or are feature structures. FSs are usually represented with an attribute-value matrix (AVM) FEATURE_1 VALUE_1 FEATURE_2 VALUE_2 ... FEATURE_N VALUE_N
 is a method for encoding the grammatical properties. They are simply sets of feature-value pairs, where features are unanalyzable atomic symbols and values are either atomic symbols or are feature structures. FSs are usually represented with an attribute-value matrix (AVM) FEATURE_1 VALUE_1. FEATURE_2 VALUE_ FEATURE_N VALUE_N.")
4
Feature Structures Feature Structures for categories NP3Sg and NP3Pl
CAT NP NUMBER SG PERSON 3 CAT NP NUMBER PL PERSON 3 Some grammatical categories can remain common (e.g CAT and PERSON) and distinctions can be made by changing others (e.g. NUMBER)
 and distinctions can be made by changing others (e.g. NUMBER)")
5
Feature Structures The values of feature structures may be other feature structures. CAT NP AGREEMENT NUMBER SG PERSON 3 With such a grouping we can test for the equality of the values NUMBER and PERSON together by testing the equality of the agreement feature.

6
Feature Structures FSs can also be represented as graphs. A feature path is a list of features through an FS leading to a particular value. E.g. the path <AGREEMENT PERSON> leads to the value 3.

7
Reentrant Feature Structures
It is also possible that two features share the same FS as a value. Such FSs are called reentrant structures. The features actually share the same FS as value (not just equal values) CAT S HEAD AGREEMENT (1) SUBJECT NUMBER SG PERSON 3 [ AGREEMENT (1)]
 CAT S. HEAD. AGREEMENT (1) SUBJECT. NUMBER SG. PERSON 3. [ AGREEMENT (1)]")
8
Reentrant Feature Structures

9
Unification of Feature Structures
Unification is an operation that Merges the information of two structures Rejects the merging of incompatible structures Simple Unification [NUMBER SG] |_| [NUMBER SG] = [NUMBER SG] [NUMBER SG] |_| [NUMBER PL] Fails! [NUMBER SG] |_| [NUMBER [ ] ] = [NUMBER SG] where [ ] means unspecified value. [NUMBER SG] |_| [PERSON 3 ] = NUMBER SG PERSON 3

10
Unification of Feature Structures
AGREEMENT (1) SUBJECT NUMBER SG PERSON 3 [ AGREEMENT (1)] NUMBER SG PERSON 3 SUBJECT AGREEMENT AGREEMENT (1) SUBJECT NUMBER SG PERSON 3 [ AGREEMENT (1)]
 SUBJECT. NUMBER SG. PERSON 3. [ AGREEMENT (1)] NUMBER SG. PERSON 3. SUBJECT. AGREEMENT. AGREEMENT (1) SUBJECT. NUMBER SG. PERSON 3. [ AGREEMENT (1)]")
11
Unification of Feature Structures
AGREEMENT (1) SUBJECT [ AGREEMENT (1)] NUMBER SG PERSON 3 SUBJECT AGREEMENT AGREEMENT (1) NUMBER SG PERSON 3 AGREEMENT (1) SUBJECT
 SUBJECT. [ AGREEMENT (1)] NUMBER SG. PERSON 3. SUBJECT. AGREEMENT. AGREEMENT (1) NUMBER SG. PERSON 3. AGREEMENT (1) SUBJECT.")
12
Unification of Feature Structures
AGREEMENT NUMBER SG SUBJECT AGREEMENT NUMBER SG NUMBER SG PERSON 3 SUBJECT AGREEMENT AGREEMENT NUMBER SG NUMBER SG PERSON 3 SUBJECT AGREEMENT

13
Unification of Feature Structures
AGREEMENT (1) SUBJECT NUMBER SG PERSON 3 [ AGREEMENT (1)] AGREEMENT NUMBER SG PERSON 3 NUMBER PL PERSON 3 SUBJECT AGREEMENT Failure!
 SUBJECT. NUMBER SG. PERSON 3. [ AGREEMENT (1)] AGREEMENT. NUMBER SG. PERSON 3. NUMBER PL. PERSON 3. SUBJECT. AGREEMENT. Failure!")
14
Subsuming Unification is a way of merging the information of two FSs. The unified structure is equally or more specific (has more information) to any of the input FSs. We say that a less specific feature subsumes an equally or more specific one (operator ⊑). Formally: A feature structure F subsumes a feature structure G (F ⊑ G) if and only if: For every feature x in F, F(x) ⊑ G(x) For all paths p and q in F such that F(p)=F(q), it is also the case that G(p)=G(q)
 to any of the input FSs. We say that a less specific feature subsumes an equally or more specific one (operator ⊑). Formally: A feature structure F subsumes a feature structure G (F ⊑ G) if and only if: For every feature x in F, F(x) ⊑ G(x) For all paths p and q in F such that F(p)=F(q), it is also the case that G(p)=G(q)")
15
Subsuming ⊑ ⊑ ⊑ CAT VP AGREEMENT (1) AGREEMENT (1) SUBJECT CAT VP
NUMBER SG PERSON 3 AGREEMENT SUBJECT CAT VP AGREEMENT (1) ⊑ NUMBER SG PERSON 3 AGREEMENT (1) SUBJECT
 ⊑ NUMBER SG. PERSON 3. AGREEMENT (1) SUBJECT.")
16
Unification Formally unification is defined as the most general feature structure H such that F ⊑ H, G ⊑ H. The unification operation is monotonic. This means that if a feature structure satisfies some description, unifying with another FS results in a new FS that still satisfies the original description (i.e. all of the original information is retained). A direct consequence of the above is that unification is order-independent. Regardless of the order in which we unify a number of FSs the final result will be the same.
. A direct consequence of the above is that unification is order-independent. Regardless of the order in which we unify a number of FSs the final result will be the same.")
17
Feature Structures in the Grammar
FSs and Unification provide an elegant way for expressing syntactic constraints. This is done by augmenting CFG rules with FS for the constituents of the rules and unification operations that impose constraints on those constituents. Rules: β0 -> β1 β βΝ Constraints: < βi feature path > = Atomic Value < βi feature path > = < βj feature path > e.g. S -> NP VP < NP NUMBER > = < VP NUMBER >

18
Agreement Subject-Verb Agreement This flight serves breakfast.
S -> NP VP <NP AGREEMENT> = <VP AGREEMENT> Does this flight serve breakfast. Do these flights serve breakfast. S -> Aux NP VP <Aux AGREEMENT> = <NP AGREEMENT> Determiner-Noun Agreement This flight, these flights NP -> Det Nominal <Det AGREEMENT> = <Nominal AGREEMENT> <NP AGREEMENT> = <Nominal AGREEMENT>

19
Agreement Aux –> do <Aux AGREEMENT NUMBER>=PL
<Aux AGREEMENT PERSON>=3 Aux -> does <Aux AGREEMENT NUMBER>=SG Verb -> serve <Verb AGREEMENT NUMBER>=PL Verb -> serves <Verb AGREEMENT NUMBER>=SG < Verb AGREEMENT PERSON>=3

20
Head Features Compositional Grammatical Constituents (NP, VP …) have features which are copied from their children. The child that provides the features is called the head of the phrase and the copied features are called head features. VP -> Verb NP <VP AGREEMENT> = <Verb AGREEMENT> NP -> Det Nominal <Det AGREEMENT> = <Nominal AGREEMENT> <NP AGREEMENT> = <Nominal AGREEMENT> Or a this can be generalized by adding a HEAD feature: <VP HEAD> = <Verb HEAD> <Det HEAD> = <Nominal HEAD> <NP HEAD> = <Nominal HEAD>
 have features which are copied from their children. The child that provides the features is called the head of the phrase and the copied features are called head features. VP -> Verb NP. <VP AGREEMENT> = <Verb AGREEMENT> NP -> Det Nominal. <Det AGREEMENT> = <Nominal AGREEMENT> <NP AGREEMENT> = <Nominal AGREEMENT> Or a this can be generalized by adding a HEAD feature: <VP HEAD> = <Verb HEAD> <Det HEAD> = <Nominal HEAD> <NP HEAD> = <Nominal HEAD>")
21
Subcategorization Subcategorization is the notion that different verbs take different patterns of arguments. By associating each verb with a SUBCAT feature we can model this behaviour. Verb -> serves <Verb HEAD ARGUMENT NUMBER> = SG <Verb HEAD SUBCAT> = TRANS VP -> Verb <VP HEAD>= < Verb HEAD>, <VP HEAD SUBCAT>=INTRANS VP -> Verb NP <VP HEAD>= < Verb HEAD>, <VP HEAD SUBCAT>=TRANS VP -> Verb NP NP <VP HEAD>= < Verb HEAD>, <VP HEAD SUBCAT>=DITRANS

22
Subcategorization Another approach is to allow each verb to explicitly specify its arguments as a list. Verb -> serves <Verb HEAD AGREEMENT NUMBER>=SG <Verb HEAD SUBCAT FIRST CAT>=NP <Verb HEAD SUBCAT SECOND>=END Verb -> want <Verb HEAD SUBCAT FIRST CAT>=VP <Verb HEAD SUBCAT FIRST FORM>=INFINITIVE VP -> Verb NP <VP HEAD>=<Verb HEAD> <VP HEAD SUBCAT FIRST CAT>=<NP CAT>

23
Implementing Unification
The FS of the input can be represented as directed acyclic graphs (DAG), where features are labels or directed arcs and feature values are atomic symbols or DAGs). The implementation of unification is then a recursive graph matching algorithm, that loops through the features in one input and tries to find a corresponding feature in the other. If a single feature causes a mismatch then the algorithm fails. The algorithm proceeds recursively, so as to deal with with features that have other FSs as values.
, where features are labels or directed arcs and feature values are atomic symbols or DAGs). The implementation of unification is then a recursive graph matching algorithm, that loops through the features in one input and tries to find a corresponding feature in the other. If a single feature causes a mismatch then the algorithm fails. The algorithm proceeds recursively, so as to deal with with features that have other FSs as values.")
24
Parsing with Unification
Since Unification is order independent it is possible to ignore the search strategy used in the parser. Therefore unification can be added to any of the parsers we have studied (Top-down, bottom-up, Early). A simple approach is to parse using the CFG and at the end filter out the parses that contain unification failures. A better approach is to incorporate unification constraints in the parsing process and therefore eliminated structures that don’t satisfy unification constraints as soon as they are found.
. A simple approach is to parse using the CFG and at the end filter out the parses that contain unification failures. A better approach is to incorporate unification constraints in the parsing process and therefore eliminated structures that don’t satisfy unification constraints as soon as they are found.")
25
Unification Parsing A different approach to parsing using unification is to consider the grammatical category as a feature and implement the context-free rule as a unification between CAT features. E.g. X0->X1X2 < X0 CAT>=S, < X1 CAT>=NP, < X2 CAT>=VP < X1 HEAD AGREEMENT>=< X2 HEAD AGREEMENT> < X2 HEAD >= < X0 HEAD > This approach models in an elegant way rules that can be generalized across many different grammatical categories. X0->X1 and X 2 < X1 CAT> = < X2 CAT> < X0 CAT> = < X1 CAT>

26
Probabilistic Grammars
Probabilistic Context-Free Grammars (PCFGs) (or Stochastic Context-Free Grammars are Context-Free Grammars where each rule is augmented with a conditional probability. A -> B [p] PCFGs can be used to estimate a number of useful probabilities concerning the parse trees of a sentence. Such probabilities can be useful for disambiguating different parses of a sentence.
 (or Stochastic Context-Free Grammars are Context-Free Grammars where each rule is augmented with a conditional probability. A -> B [p] PCFGs can be used to estimate a number of useful probabilities concerning the parse trees of a sentence. Such probabilities can be useful for disambiguating different parses of a sentence.")
27
Probabilistic Grammars

28
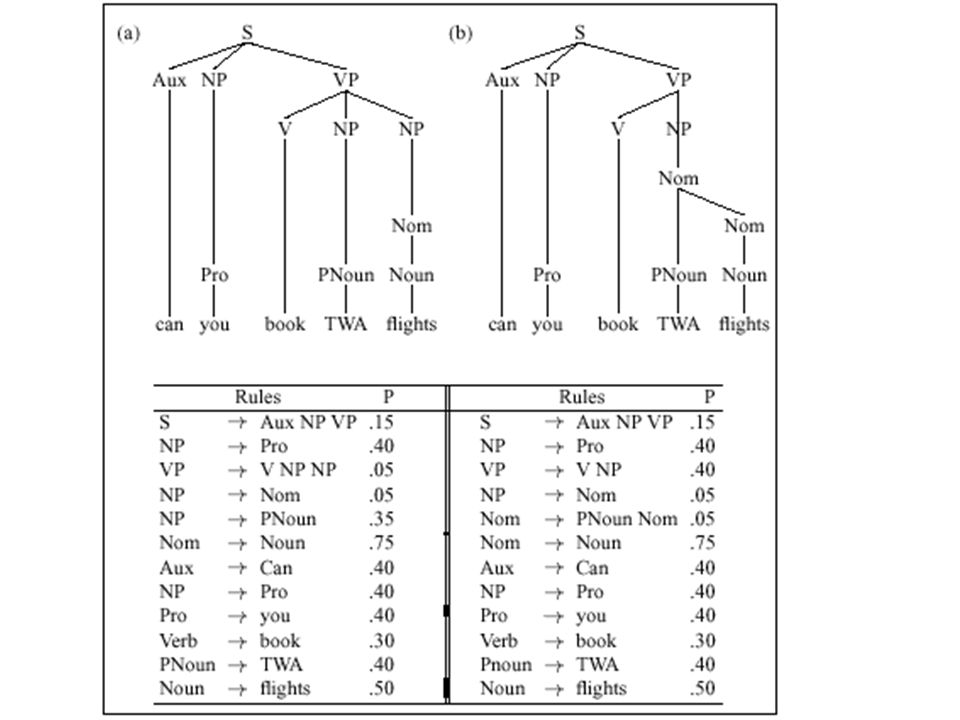
Probabilistic Grammars
The probability of a parse of a sentence is calculated as the product of all the probabilities of all the rules used to expand each node in the sentence parse. P(Ta)=.15 * .40 * .05 * .35 * .75 * .40 * .40 * .40 * .30 *.40 * .50 = 1.5 * 10-6 P(Tb)=.15 * .40 * .40 * .05 * .05 * .75 * .40 * .40 * .40 * .30 *.40 * .50 = 1.7 * 10-7 Similarly in this way it is also possible to assign probability to a substring of a sentence (probability of a subtree of the parse tree)
=.15 * .40 * .05 * .35 * .75 * .40 * .40 * .40 * .30 *.40 * .50 = 1.5 * P(Tb)=.15 * .40 * .40 * .05 * .05 * .75 * .40 * .40 * .40 * .30 *.40 * .50 = 1.7 * Similarly in this way it is also possible to assign probability to a substring of a sentence (probability of a subtree of the parse tree)")
30
Learning PCFG Probabilities
PCFG Probabilities can be learned by using a corpus of already-parsed sentences. Such a corpus is called a treebank. An example of such a treebank is the Penn Treebank, that contains parsed sentences of 1 million words from the Brown corpus. Then the probability of a rule is computed by counting the number of times this rule is expanded. P(a->b|a)=Count(a->b) / Count (a) There are also algorithms that calculate such probabilities without using a treebank, such as the Inside-Outside algorithm.
=Count(a->b) / Count (a) There are also algorithms that calculate such probabilities without using a treebank, such as the Inside-Outside algorithm.")
31
Dependency Grammars Dependency Grammars is a different lexical formalism that is not based on the notion of constituents, but on the lexical dependencies between words. The syntactic structure of a sentence is described purely in terms of words and on binary semantic or syntactic relations between these words. Dependency Grammars are very useful for dealing with languages with free word order, where the word order is far more flexible than in English (e.g. Greek, Czech). In such languages CFGs would require a different set of rules for dealing with each different word order.
. In such languages CFGs would require a different set of rules for dealing with each different word order.")
32
Dependency Description
subj syntactic subject obj direct object dat indirect object pcomp complement of a preposition comp predicate nominals tmp temporal adverbial loc location adverbial attr premodifying (attributive) nominals mod nominal postmodifiers (prepositional phrases)
 nominals. mod nominal postmodifiers (prepositional. phrases)")
Similar presentations




 NLP- WEEK 4.>")

 Muhammed Al-Mulhem March 1,>")





 Computer Science cpsc422, Lecture 27>")

 Features.>")




