Download presentation
Presentation is loading. Please wait.

1
Energy Efficient Instruction Cache for Wide-issue Processors Alex Veidenbaum Information and Computer Science University of California, Irvine

2
Motivation Power dissipation is a serious problem It is important for both high performance, –e.g. COMPAQ Alpha, MIPS R10K, Intel x86, As well as embedded processors –E.g. ARM, Strongarm, etc… Our current research is focused on reducing the average energy consumption of high-performance embedded processors MIPS R20K, IBM/Motorola PowerPC, Mobile Pentium,..

3
We want to address the energy consumption via –architecture –compiler Technology is, to the first order, an orthogonal parameter and is NOT considered So the first question is –What are the major sources of energy dissipation? –Hard to find this info

4
Experimental Setup We started with Wattch (Princeton) –architectural-level power simulator –based on SimpleScalar (sim-outorder) simulator –can specify technology, clock and voltage –computes power for major internal units of processor parameterizable models for most of the components mostly memory-based units… ALU power is a constant (based on input from industry) Modified it to match our needs
 –architectural-level power simulator –based on SimpleScalar (sim-outorder) simulator –can specify technology, clock and voltage –computes power for major internal units of processor parameterizable models for most of the components mostly memory-based units… ALU power is a constant (based on input from industry) Modified it to match our needs")
5
Need to account for energy correctly: –“Worst case”, F(V,C,f) =~C*V^2*f Every unit on every cycle… –No good –Depending on program behavior –the right way Basic organization:
 =~C*V^2*f Every unit on every cycle… –No good –Depending on program behavior –the right way Basic organization:")
6
Used a typical wide-issue processor, assuming 600 MHz, 32-bit 32K L1 instruction cache, 32K L1 data cache 512K L2 unified cache 2 int ALUs, 1 FP adder, 1 FP multiplier 3.3V MIPS R10K like, mods from default SS Major units to look at: –Instruction,data cache, ALU, branch predictor, RF,…

7
Some typical results Power distribution among major internal units

8
Motivation cont’d Now we can attack specific important sources Instruction cache is one such unit Reason: –Every cycle 4 32b instruction words need to be fetched Next we discuss a hardware mechanism for reducing instruction cache energy consumption

9
Previous Work Hasegawa 1995 - phased cache Examine the tag and data fields in two separate phases Reduce power consumption by 70% Increase the average cache-access time by 100% Inoue 1999 - set-associative, way-prediction cache Speculatively selects one way before starting a normal access On a way prediction hit, power is reduced by a factor of 4 Increase the cache-access time on mispredictions Lee 1999 - loop cache Shut down main cache completely while executing tight program loops from the loop cache Power savings vary with the application No performance degradation

10
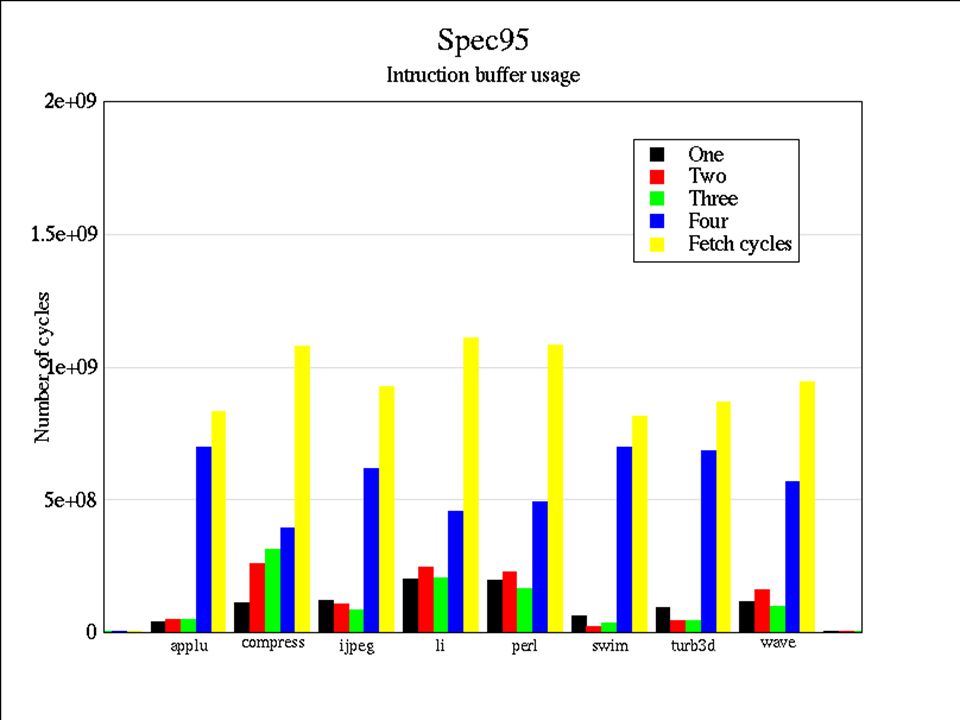
Our approach Not all of the fetched instructions in a line are used –When a branch is taken – the words after the branch till line end –When there is a target in a line from the beginning of a line till the target Save energy by fetching only useful instructions –Design a hardware mechanism (fetch predictor) that predicts which instructions are going to be used out of a cache line before that line is fetched –Selectively fetch only predicted useful instructions in each fetch cycle
 that predicts which instructions are going to be used out of a cache line before that line is fetched –Selectively fetch only predicted useful instructions in each fetch cycle")
11
Organization Need a cache with an ability to fetch any consecutive sequence of instructions from a line This has been implemented before Su 1995 - divide the cache into subbanks, activated individually by a control vector RS/6000 - cache organized as 4 separate arrays, each of which could use a different row address Generate a control vector w/ a bit for each “bank”

12
Fetch Predictor General idea: –Rely on branch predictor to get PC of next instruction –Build a fetch predictor on top of branch predictor to decide which instructions to fetch –Use branch misprediction detection mechanism and branch predictor update phase to update the fetch predictor

13
Some specifics Predict for the next line to fetched For a target in the next line - use address in BTB –Fetch from target on For a branch in next line need a separate predictor –Before the line is fetched –Add update when branch predictor is updated –Initialize to fetch all words Need to take care of a case when both branch and target are in the same line –AND control bit vectors

14
Experimental Setup SimpleScalar extended with a fetch predictor A simple power model: –Energy per cycle is proportional to the number of fetched instructions Simulated a subset of Spec95 3 billion instructions executed in each Direct mapped cache, with 4 and 8 instructions per line Bimodal branch predictor

15
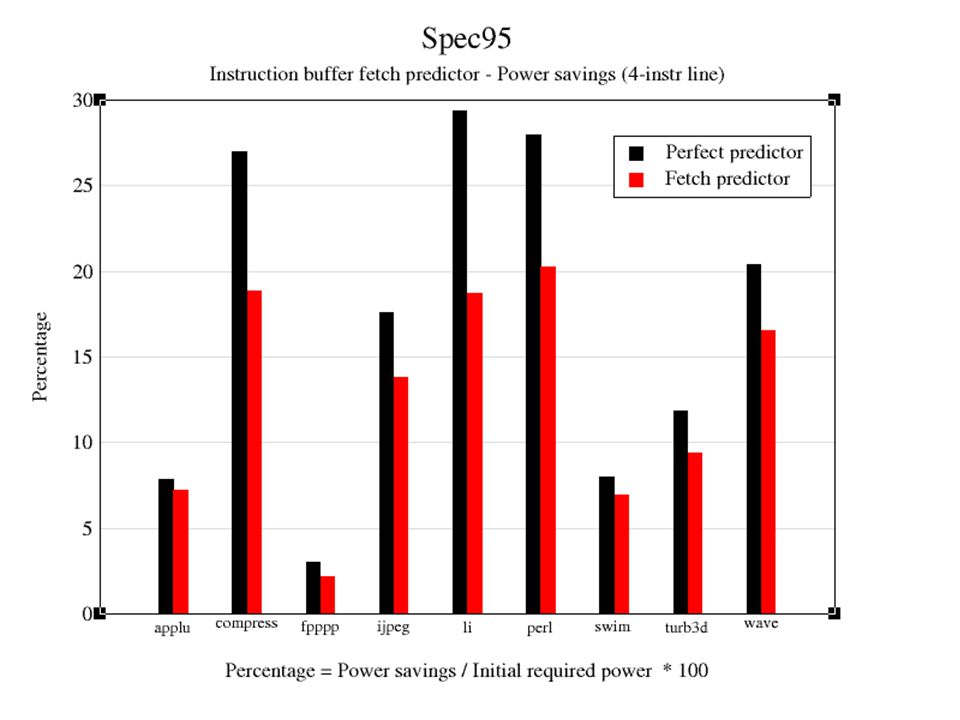
Summary of Results Average power savings –Perfect predictor 33%, between 8% and 55% for a 8-instr cache line –Fetch predictor 25%, between 5% and 41% for a 8-instr cache line Larger power savings for integer benchmarks than for the floating point ones

19
Conclusions Contribution to power-aware hardware –a fetch predictor for fetching only useful instructions Preliminary results –5% of the total power, for an 8-instruction cache line (assumes I-cache consumes 20% of the total) Advantage: No performance penalty!
 Advantage: No performance penalty!")
Similar presentations



 Hyesoon Kim, Jose A. Joao, Onur Mutlu ++, Chang Joo Lee, Yale N. Patt, Robert Cohn* ++ *>")









>")

 Stalls with Dynamic Branch Prediction So far we have dealt with.>")



It is less expensive 2)It is usually faster 3)Its average CPI is smaller 4)It allows a faster clock rate 5)It has a simpler.>")
 Stalls with Dynamic Branch Prediction So far we have dealt with.>")