Download presentation
Presentation is loading. Please wait.

1
Strategic Decisions Using Dynamic Programming
Nikolaos E. Pratikakis, Matthew Realff and Jay H. Lee The main objective of this talk is to introduce the intuition behind the dynamic programming methodology. By characterizing a decision ``strategic’’ , we denote a decision that considers the future uncertainty… And tries to maximize the position of the system in the long run… The goal of DP is to maximize the expected reward or

2
Agenda Motivation Exemplary Manufacturing Job Shop Under Uncertain Demand and Product Yield Understanding Dynamic Programming (DP) via Chess Curse of Dimensionality (COD) A new proposed Approach based on Real Time DP (RTDP) Results Conclusions and Future Work First I will highlight the problems that DP methods can be bring significant performance improvements Then I will introduce to you an exemplary… product yield…
 A new proposed Approach based on Real Time DP (RTDP) Results. Conclusions and Future Work. First I will highlight the problems that DP methods can be bring significant performance improvements. Then I will introduce to you an exemplary… product yield…")
3
Plant Operation Control
[year] [month] Management [week] complexity Hierarchy in process system industries [day] [min] Plant Operation Control [sec] Decision Hierarchy in Process Industries

4
Manufacturing Job Shop Scheduling
(Recirculation Rate) Completed Jobs Station 2 Queue Testing Area Station 1 Queue Assume that our manufacturing problem at this time period runs with a given configuration Our decisions will be effective from the next time period. So at firtst we should decide how much raw materials should we order for the next time period, how many machines we should have available at station 1 at the next time period and the percentage of those that will be used. The raw materials are queued at station 1 and when processed from the main processing area are going to be queued at station 2, then they are going to extensively tested, at the testing area, to see if they meet the market requirements or not. The portion that doesn’t meet the market requirements is going to be reconstructed and be forward to station 2, while the portion that does meet the market requirements is going to be stocked and satisfy the demand Likewise at station 2 and 3, the decision maker has the same decisions as in station 1. The uncertainty lies at the recirculation rate as well as at the demand rate. We studied this example by considering two modes for the recirculation rate : the high recirculation mode (low thoughput) corresponds to the bad operational status of the system and the low recirculation mode (high thoughput) that corresponds to the good operational status of the system. We will formulate this problem as an MDP but first we will show you what are the elements of an MDP formulation… Main Processing Station 3 Queue D (Demand) Reconstruction Area
 Completed Jobs. Station 2. Queue. Testing Area. Station 1. Queue. Assume that our manufacturing problem at this time period runs with a given configuration. Our decisions will be effective from the next time period. So at firtst we should decide how much raw materials. should we order for the next time period, how many machines we should have available at station 1 at the. next time period and the percentage of those that will be used. The raw materials are queued at station 1 and when processed from the main processing area are going to. be queued at station 2, then they are going to extensively tested, at the testing area, to see if they meet the market requirements or not. The portion that doesn’t meet the market requirements is going to be reconstructed and be forward to station 2, while the portion that does meet the market requirements is going to be stocked and satisfy the demand. Likewise at station 2 and 3, the decision maker has the same decisions as in station 1. The uncertainty lies at the recirculation rate as well as at the demand rate. We studied this example by considering two modes for the recirculation rate : the high recirculation mode (low thoughput) corresponds to the bad operational status of the system and the low recirculation mode (high thoughput) that corresponds to the good operational status of the system. We will formulate this problem as an MDP but first we will show you what are the elements of an MDP formulation… Main Processing. Station 3. Queue. D (Demand) Reconstruction Area.")
5
An Analogy…

6
System State for Chess …
A state is a configuration of the pieces at the board System State … System State System State

7
System State for Job Shop
(Recirculation Rate) Completed Jobs Station 2 Queue Testing Area Station 1 Queue Main Processing Station 3 Queue D (Demand) Reconstruction Area
 Completed Jobs. Station 2. Queue. Testing Area. Station 1. Queue. Main Processing. Station 3. Queue. D (Demand) Reconstruction Area.")
8
Control in DP Terms (2) Which Control or Action will maximize
my future position? Action 1 ? Action 2 ? Expert to help you decide! System State How ???By scoring the successor configurations of the table

9
“Curse of Dimensionality”
Curse of Dimensionality (COD) Size of S (storage issue) For complex applications the S is countable infinite Large number of controls per system state The research branch that focuses on alleviating the COD is termed as Approximate DP The obstacles if we apply DP in its pure form is size of the state space and the large number of controls. The computations for a single value iteration is denoted as such: If we don’t have a finite state or action space then its virtually impossible perform do even one value iteration.The stream of literature that tries to minimize the effect of all these elements is called ADP While heuristic policies have been used in most practical cases, {\em{dynamic programming}} (DP) \cite{Put94} \cite{BeI} \cite{BeII} stands as the basic paradigm for constructing optimal policies for multi-stage optimization problems under uncertainty. The main difficulty in applying the DP approach in its pure form is the ``curse of dimensionality'', referring to the exponential increase in the size of the state space with the number of state variables, and that of the action space with the number of decision variables. The ``curse of dimensionality" has two direct implications for the applicability of the DP approach. First is the space complexity of storing the value function (e.g., the {\it profit-to-go} function) defined over the state space: It may be very difficult or even impossible to store the values for all states even with today's technology. Second and more important is the time needed to converge to an optimal solution. The computation for a single iteration pass increases with the size of both the state space and the action space. In general, we have an exponential growth of computational time with respect to dimensions of the state space and the action space, and solving the problem using a textbook approach like {\it value iteration} or {\it policy iteration} is largely impractical \cite{BeII} \cite{Chang}. At Chapter 3 of this proposal, we propose an alternative way to address MDP formulations using a real-time dynamic programming approach, for solving large scale multi-stage decision problems under uncertainty. This approach can be used to find optimal solutions, but in many cases doing so will be prohibitively expensive. Instead we will use it to find suboptimal policies that improve significantly upon existing heuristics.
 Size of S (storage issue) For complex applications the S is countable infinite. Large number of controls per system state. The research branch that focuses on alleviating the COD is termed as Approximate DP. The obstacles if we apply DP in its pure form is size of the state space and the large number of controls. The computations for a single value iteration is denoted as such: If we don’t have a finite state or action space then its virtually impossible perform do even one value iteration.The stream of literature that tries to minimize the effect of all these elements is called ADP. While heuristic policies have been used in most practical cases, {\em{dynamic. programming}} (DP) \cite{Put94} \cite{BeI} \cite{BeII} stands as the basic paradigm for. constructing optimal policies for multi-stage optimization problems under uncertainty. The main difficulty in applying the DP approach in its pure form is the ``curse of. dimensionality , referring to the exponential increase in the size of the state space. with the number of state variables, and that of the action space with the number of. decision variables. The ``curse of dimensionality has two direct implications for the. applicability of the DP approach. First is the space complexity of storing the value. function (e.g., the {\it profit-to-go} function) defined over the state space: It may be. very difficult or even impossible to store the values for all states even with today s. technology. Second and more important is the time needed to converge to an optimal. solution. The computation for a single iteration pass increases with the size of both the. state space and the action space. In general, we have an exponential growth of. computational time with respect to dimensions of the state space and the action space, and solving the problem using a textbook approach like {\it value iteration} or {\it. policy iteration} is largely impractical \cite{BeII} \cite{Chang}. At Chapter 3 of this. proposal, we propose an alternative way to address MDP formulations using a real-time. dynamic programming approach, for solving large scale multi-stage decision problems under. uncertainty. This approach can be used to find optimal solutions, but in many cases doing. so will be prohibitively expensive. Instead we will use it to find suboptimal policies. that improve significantly upon existing heuristics.")
10
Formal Definition of Value Function
Given a policy the value function for state is the expected reward Optimal value function corresponds to Value Functions are the solution of the optimality equations. This is a very important slide and defines the key concept of DP which is the value function. Simply put Value function of a policy π is its expected reward. Every policy π (Markovian deterministic or randomized) for the same state corresponds to a different value function The optimal or converged value function is the policy π* that attains the maximum expected reward. How can this policy π* be retrieved? If we simultaneously solve these optimality equations , that were first proposed by R. Bellman in 1957, we will end up with the optimal value functions for each of the sates Then we can find the optimal control using the optimal-converged value function information. This is exactly what the a*(s) equation denotes/ We can accomplish converged value function by following well known methodologies as value iteration, policy iteration, linear programming… We will stress the obstacles of DP by analyzing theValue Iteration approach Optimal action can easily be computed from optimal value function
 for the same state corresponds to a different value function. The optimal or converged value function is the policy π* that attains the maximum expected reward. How can this policy π* be retrieved If we simultaneously solve these optimality equations , that were first proposed by R. Bellman in 1957, we will end up with the optimal value functions for each of the sates. Then we can find the optimal control using the optimal-converged value function information. This is exactly what the a*(s) equation denotes/ We can accomplish converged value function by following well known methodologies as value iteration, policy iteration, linear programming… We will stress the obstacles of DP by analyzing theValue Iteration approach. Optimal action can easily be computed from optimal value function.")
11
Real Time Approximate Dynamic Programming
Adaptive Action Set (AAS) Candidate optimal action for Initial state Possible successive next state 2 1 4 Check every action in AAS α* 3 6 Sample from possible transitions 5 We first start with a random state xi, we construct our AAS and we check every action using the bellman equations and our stored value table… We pick a greedy action a* update the value table, store this a* as the best known action for state xi and the sample from all the possible successive states the correspond to the transition from xi using a* We set xj=xi and continue with the loop Uncertainty Pratikakis, N.E, Realff M.J and Lee, J.H “Strategic Capacity Decisions In Manufacturing Using Real-Time Adaptive Dynamic Programming”, Submitted to Naval Research Logistics.
 Candidate optimal action for Initial state. Possible successive next state Check every. action in AAS. α* Sample from. possible transitions. 5. We first start with a random state xi, we construct our AAS and we check every action using the bellman equations and our stored value table… We pick a greedy action a* update the value table, store this a* as the best known action for state xi and the sample from all the possible successive states the correspond to the transition from xi using a* We set xj=xi and continue with the loop. Uncertainty. Pratikakis, N.E, Realff M.J and Lee, J.H Strategic Capacity Decisions In Manufacturing Using. Real-Time Adaptive Dynamic Programming , Submitted to Naval Research Logistics.")
12
Results :Saturation of System States

13
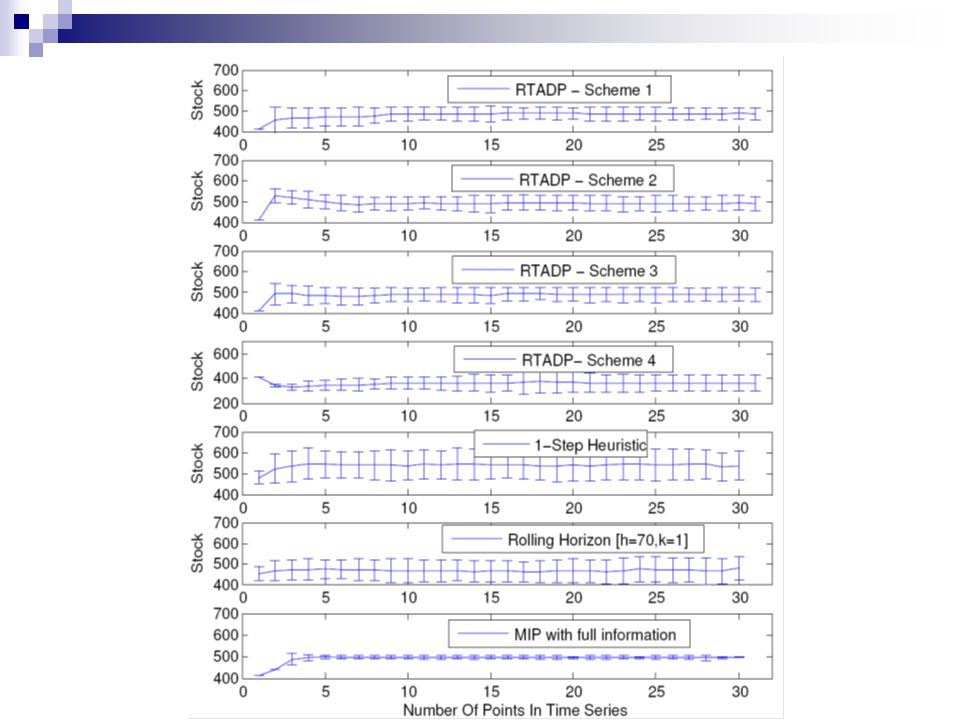
Results : Performance .

14
Conclusions & Future Directions
RTADP computationally amenable way to create a high quality policy for any given system. Quality of solution exceeds traditional deterministic approaches Extend current framework and incorporate risk issues (Risk Measure - CVaR). Risk RTADP framework promises to generate multiple strategies accounting risk. We conclude that the RTDP approach is RTDP approach is a computationally amenable way to create a high quality policy for any given system Adaptive action set with the random actions ensures convergence in the long run and does not satisfy performance This generic algorithmic framework can be used for multistage optimization problems under uncertainty
. Risk RTADP framework promises to generate multiple strategies accounting risk. We conclude that the RTDP approach is RTDP approach is a computationally amenable way to create a high quality policy for any given system. Adaptive action set with the random actions ensures convergence in the long run and does not satisfy performance. This generic algorithmic framework can be used for multistage optimization problems under uncertainty.")
15
Questions …?

17
Approximate Dynamic Programming
Sampling of the “relevant” state space through simulation (with known suboptimal policies) Fit a function approximator to the value function data for interpolation Global1,2 vs local approximators3 Barto et al4 introduced the real time DP To minimize the COD concerning the state space people have sampled the state space using suboptimal policies and then did the value iteration in the constructed state space, hoping that this state space overlaps with the relevant state space. Relevant state space is the state space that can be created if we know the optimal policy π* and via simulation we sample the states. But this approach can find very high Policies that exhibit performance very close to the one even if one did full DP. An other approach is to fit a global approximator to the value function data, but one needs huge amount of data to accomplish that. Recently Lee and Lee compare d the usage of global approximators (neural networks) vs local approximators(k-NN) in terms of stability and monotonicity during the value iteration and suggested the usage of local approximators. A different approach that mainly is applied for robotic path planning is the RTDP approach proposed by Barto. He has shown the convergence of this approach for stochastic shortest path problems even if on uses the relevant state space. Barto’s approach is a parent for our suggested approach and nect we will show an overview of the RTDP algorithm Several approaches have been proposed to reduce the computational burden of DP. A recent approach is Neuro-dynamic programming (NDP). The typical approach in the (NDP) and (RL) literature is to ¯t a global approximator (e.g., neural network) to the value function data. There have been many examples in the literature of failure of such an approximator in the current literature. The failure is attributed to \over-extending" the value function approximation, which was ¯rst explained by Thrun and Schwartz k-NN based approach in these examples exhibited stability, monotonicity, and fast rate of convergence. On the other hand, the neural network based approach did not exhibit such nice convergence behavior during the value iteration. 1. Bertsekas, D. P.. Encyclopedia of Optimization, Kluwer, 2001. Thrun, S. and Schwartz, A. Proceedings of the Fourth Connectionist Models Summer School (Hillsdale, NJ) Lawrence Erlbaum,1993. Lee, J. M. and Lee, J. H.,, International Journal of Control Automation and Systems, vol. 2, no. 3, pp , 2004. Barto, A., Bradtke, S., and Singh, S. Artificial Intelligence, vol. 72, pp , 1995.
 Fit a function approximator to the value function data for interpolation. Global1,2 vs local approximators3. Barto et al4 introduced the real time DP. To minimize the COD concerning the state space people have sampled the state space using suboptimal policies and then did the value iteration in the constructed state space, hoping that this state space overlaps with the relevant state space. Relevant state space is the state space that can be created if we know the optimal policy π* and via simulation we sample the states. But this approach can find very high Policies that exhibit performance very close to the one even if one did full DP. An other approach is to fit a global approximator to the value function data, but one needs huge amount of data to accomplish that. Recently Lee and Lee compare d the usage of global approximators (neural networks) vs local approximators(k-NN) in terms of stability and monotonicity during the value iteration and suggested the usage of local approximators. A different approach that mainly is applied for robotic path planning is the RTDP approach proposed by Barto. He has shown the convergence of this approach for stochastic shortest path problems even if on uses the relevant state space. Barto’s approach is a parent for our suggested approach and nect we will show an overview of the RTDP algorithm. Several approaches have been proposed to reduce the computational burden of DP. A recent approach is. Neuro-dynamic programming (NDP). The typical. approach in the (NDP) and (RL) literature is to ¯t a global approximator (e.g., neural network) to the. value function data. There have been many examples in the literature of failure of such an approximator. in the current literature. The failure is attributed to \over-extending the value function approximation, which was ¯rst explained by Thrun and Schwartz. k-NN based approach in these examples exhibited stability, monotonicity, and fast rate of convergence. On. the other hand, the neural network based approach did not exhibit such nice convergence behavior during. the value iteration. 1. Bertsekas, D. P.. Encyclopedia of Optimization, Kluwer, Thrun, S. and Schwartz, A. Proceedings of the Fourth Connectionist Models Summer School (Hillsdale, NJ) Lawrence Erlbaum,1993. Lee, J. M. and Lee, J. H.,, International Journal of Control Automation and Systems, vol. 2, no. 3, pp , Barto, A., Bradtke, S., and Singh, S. Artificial Intelligence, vol. 72, pp ,")
18
Overview of RTDP Algorithm
The controller always follows a policy that is greedy with respect to the most recent estimate of J. Simulate the dynamics of the system Update J according to : In RTDP, the The controller always follows a policy that is greedy with respect to the most recent estimate of J. Then we Simulate the dynamics of the system and we update only for this state and preserve the rest of the value table. Before I present our propose approach we will emphasize its main differences from the previous mentioned schemes.

20
Future Directions The future directions are to evolve this approach by considering Localized function approximations (k-Nearest Neighbors) Use Mathematical programming (e.g., MILP or chance CP) for generating candidate optimal controls The preliminary results of this architecture are quite promising We also pursuing a systematic study of the effect of initialization in convergence rate and the exploration Of the state space, I also have some preliminary results for that as well if you interested offline. With that I will conclude my talk Thank you for attending this talk…
 for generating candidate optimal controls. The preliminary results of this architecture are quite promising. We also pursuing a systematic study of the effect of initialization in convergence rate and the exploration. Of the state space, I also have some preliminary results for that as well if you interested offline. With that I will conclude my talk Thank you for attending this talk…")
Similar presentations

>")
>")

 Authors: Yash Patel, Andrew.>")



>")


 Jeremy Wyatt Intelligent Robotics Lab School of Computer Science University of Birmingham>")
>")
>")
 Mausam Joint work with Daniel S. Weld University of Washington Seattle.>")
 Li, Hailin.>")




