Download presentation
Presentation is loading. Please wait.

1
Filterfresh Fault-tolerant Java Servers Through Active Replication Arash Baratloo www.cs.nyu.edu/phd_students/baratloo

2
Investigation of failure models in distributed Java applications Provide transparent fault-masking (to users and to programmers) Support highly available services in presence of failures Remove single-points of failure Filterfresh
 Support highly available services in presence of failures Remove single-points of failure Filterfresh")
3
Remote Method Invocation (RMI) 100% Java, hot, new, easy-to-use and Reliable Object Services (ROS) Interest in Providing: –support active-active replication –support Java objects Motivating Factors
 100% Java, hot, new, easy-to-use and Reliable Object Services (ROS) Interest in Providing: –support active-active replication –support Java objects Motivating Factors")
4
Roadmap Motivation –RMI Registry & crash failures –RMI Server Architecture & crash failures –A Unified Solution -- process group approach –Fault-tolerant Registry –Fault-tolerant RMI –Conclusion

5
RMI in a Nutshell Servers register with the local registry Clients looks up a server at a well known registry Given a remote reference, client performs a remote method invocation

6
Limitations of RMI Registry The “well known registry” requirement too restrictive for failure recovery Single point of failure Can not support replicated servers, thus, highly available servers

7
FT Registry requires... Distribute and replicate registry servers Replication strategy to maintain a consistent state Failure detection and removal of failed registry servers Failed objects must be restarted automatically Dynamic addition of registry servers

8
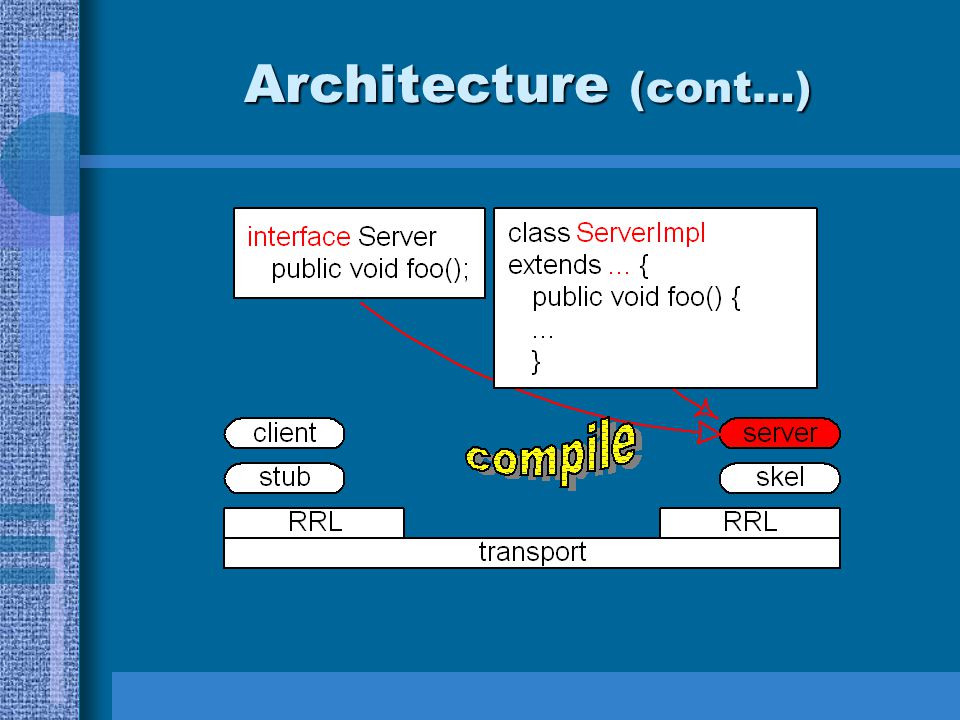
RMI Architecture RRL assumes a stream-oriented transport Transport layer implemented on TCP/IP

9
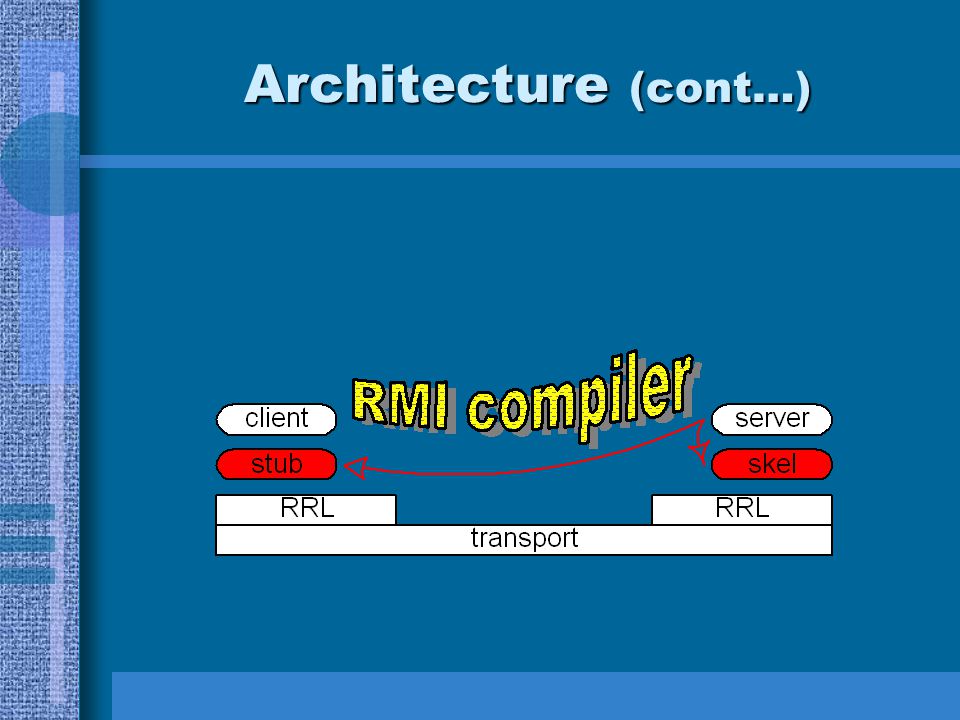
Architecture (cont…)
")
12
Transparent FT system implies RRL or below

13
FT Servers Require... Distribute and replicate servers Replication strategy to maintain a consistent state Failure detection and removal of failed registry servers Dynamic addition of registry servers Object reference must remain valid after the associated object has failed

14
A Unified Solution... Process Group Approach where all non-faulty objects –form a group –consistent view of the group –interact through reliable group primitives -- all or nothing –total order on group primitives

15
Fortunately Process Group Membership is –well understood problem and protocols –well tested (ISIS, Transis, Amoeba, etc.) –basis for virtual synchrony Equivalent Problems* (implement one, get all) –Group Membership –Reliable Failure Detectors –Reliable and ordered multicast * Chandra and Toueg. Unreliable failure detectors for Reliable Distributed Systems. JACM, March 96.

16
Unfortunately Process Group Membership is –as hard as distributed consensus –impossible in purely asynchronous systems with crash failures* Our solution –the standard “timeout” assumption –variation of protocol used in Amoeba OS** * Chandra, Toueg, Hadzilacos and Charron-Bost. Impossibility of Group Membership in Asynchronous Systems. ** Oey, Langendoen and Bal. Comparing Kernel-level and User-level Communication protocols on Amoeba. ICDCS 95.

17
What We Provide... A Group Manager Class –100% Java –build on top of UDP/IP Implements –group creation –join operation (with state transfer) –leave operation –failure detection and recovery –reliable multicast All events are atomic and totally ordered
 –leave operation –failure detection and recovery –reliable multicast All events are atomic and totally ordered.")
18
Multicast Performance Pentium Pro 200, Linux RedHat 4.0, Fast Ethernet hub

19
FT Registry Architecture registry on each host/domain group managers ensure reliable ordered events support dynamic joins w/state transfer

20
FT Registry Architecture (cont…) lookup becomes a local operation detect and remove failed objects consistent global state
 lookup becomes a local operation detect and remove failed objects consistent global state")
21
FT Registry Performance Pentium Pro 200, Linux RedHat 4.0, Fast Ethernet, Ethernet hub

22
RMI & FT Registry support multiple servers register with a same name can now support recovery from server failure

23
What if... In the event of server failure...

24
Failure Recovery The old connection is patched with a connection to a non-faulty server Illusion of a valid object reference Transparent! A “reverse” lookup returns a name given a wire connection

25
Failure Recovery Performance ? Working but measurements have not been made

26
FT Server Architecture Client has the illusion of a single server In reality, we have active replicated servers Highly available?

27
Highly Available Servers Group managers ensure reliable ordering of events across all servers Guarantees servers have a consistent state Failure detection and removal of failed servers Dynamic addition of servers w/state transfer Illusion of a valid server reference even after the associated object has failed

28
Conclusions

Similar presentations

>")





 and Justin (cs614 2005)>")






>")

 Joint work with: Marcos K. Aguilera (MSR), Idit Keidar (Technion), Dahlia Malkhi (MSR.>")

 Introduction Networked devices make their capabilities known.>")
