Download presentation
Presentation is loading. Please wait.

1
Network Science: “Universal” Structure and Models of Formation Networked Life CIS 112 Spring 2008 Prof. Michael Kearns

2
“Natural” Networks and Universality Consider the many kinds of networks we have examined: –social, technological, business, economic, content,… These networks tend to share certain informal properties: –large scale; continual growth –distributed, organic growth: vertices “decide” who to link to –interaction (largely) restricted to links –mixture of local and long-distance connections –abstract notions of distance: geographical, content, social,… Do natural networks share more quantitative universals? What would these “universals” be? How can we make them precise and measure them? How can we explain their universality? This is the domain of network science Sometimes also referred to as link analysis, social network theory

3
Some Interesting Quantities Connected components: –how many, and how large? Network diameter: –the small-world phenomenon Clustering: –to what extent do links tend to cluster “locally”? –what is the balance between local and long-distance connections? –what roles do the two types of links play? Degree distribution: –what is the typical degree in the network? –what is the overall distribution? Etc. etc. etc.

4
A “Canonical” Natural Network has… Few connected components: –often only 1 or a small number independent of network size Small diameter: –often a constant independent of network size (like 6…) –or perhaps growing only logarithmically with network size –typically look at average; exclude infinite distances A high degree of edge clustering: –considerably more so than for a random network –in tension with small diameter A heavy-tailed degree distribution: –a small but reliable number of high-degree vertices –quantifies Gladwell’s connectors –often of power law form
 –or perhaps growing only logarithmically with network size –typically look at average; exclude infinite distances A high degree of edge clustering: –considerably more so than for a random network –in tension with small diameter A heavy-tailed degree distribution: –a small but reliable number of high-degree vertices –quantifies Gladwell’s connectors –often of power law form")
5
Some Models of Network Formation Random graphs (Erdos-Renyi model): –gives few components and small diameter –does not give high clustering and heavy-tailed degree distributions –is the mathematically most well-studied and understood model Watts-Strogatz and related models: –give few components, small diameter and high clustering –does not give heavy-tailed degree distributions Preferential attachment: –gives few components, small diameter and heavy-tailed distribution –does not give high clustering Hierarchical networks: –few components, small diameter, high clustering, heavy-tailed Affiliation networks: –models group-actor formation Nothing “magic” about any of the measures or models
: –gives few components and small diameter –does not give high clustering and heavy-tailed degree distributions –is the mathematically most well-studied and understood model Watts-Strogatz and related models: –give few components, small diameter and high clustering –does not give heavy-tailed degree distributions Preferential attachment: –gives few components, small diameter and heavy-tailed distribution –does not give high clustering Hierarchical networks: –few components, small diameter, high clustering, heavy-tailed Affiliation networks: –models group-actor formation Nothing magic about any of the measures or models")
6
Combining and Formalizing Familiar Ideas Explaining universal behavior through statistical models –our models will always generate many networks –almost all of them will share certain properties (universals) Explaining tipping through incremental growth –we gradually add edges, or gradually increase edge probability p –many properties will emerge very suddenly during this process size of police force crime rate number of edges prob. NW connected

7
Approximate Roadmap Examine a series of models of network formation –macroscopic properties they do and do not entail –tipping behavior during network formation –pros and cons of each model Examine some “real life” case studies Study some dynamics issues (e.g. seach/navigation) Move on to an in-depth study of the web as network
 Move on to an in-depth study of the web as network.")
8
Models of Network Formation and Their Properties

9
Probabilistic Models of Networks Network formation models we will study are probabilistic or statistical –later in the course: economic formation models They can generate networks of any size –we will typically ask what happens when N is very large or N infinity They often have various parameters that can be set: –size of network generated –probability of an edge being present or absent –average degree of a vertex –fraction of long-distance vs. local connections –etc. etc. etc. The models each generate a distribution over networks Statements are always statistical in nature: –with high probability, diameter is small –on average, degree distribution has heavy tail So along the way we’ll need some basic statistics and probability theory

10
Statistics and Probability Theory: The Absolute, Bare-Minimum Essentials [Really. Only two slides.]
![Statistics and Probability Theory: The Absolute, Bare-Minimum Essentials [Really. Only two slides.]](http://images.slideplayer.com/16/5039536/slides/slide_10.jpg "Statistics and Probability Theory: The Absolute, Bare-Minimum Essentials [Really. Only two slides.]")
11
Probability and Random Variables A random variable X is simply a variable that probabilistically assumes values in some set –set of possible values sometimes called the sample space S of X –sample space may be small and simple, or large and complex S = {Heads, Tails}; X is outcome of a coin flip S = {0,1,…,U.S. population size}; X is number voting democratic S = all networks of size N; X is generated by Erdos-Renyi Behavior of X determined by its distribution (or density) –for each specific value x in S, specify Pr[X = x] –these probabilities sum to exactly 1 (mutually exclusive outcomes) –complex sample spaces (such as large networks): distribution often defined implicitly by simpler components might specify the probability that each edge appears independently this induces a probability distribution over networks may be difficult to compute induced distribution
 –for each specific value x in S, specify Pr[X = x] –these probabilities sum to exactly 1 (mutually exclusive outcomes) –complex sample spaces (such as large networks): distribution often defined implicitly by simpler components might specify the probability that each edge appears independently this induces a probability distribution over networks may be difficult to compute induced distribution.")
12
Some Basic Notions and Laws Independence: –let X and Y be random variables –independence: for any x and y, Pr[X=x & Y=y] = Pr[X=x]Pr[Y=y] –intuition: value of X does not “influence” value of Y, and vice-versa –dependence: e.g. X, Y coin flips, but Y is always opposite of X Expected (mean) value of X: –only makes sense for numeric random variables –“average” value of X according to its distribution –formally, E[X] = (Pr[X = x] *x), sum is over all x in S –often denoted by –always true: E[X + Y] = E[X] + E[Y] –for independent random variables: E[XY] = E[X]E[Y] Variance of X: –Var(X) = E[(X – )^2]; often denoted by ^2 –standard deviation is sqrt(Var(X)) =
![Some Basic Notions and Laws Independence: –let X and Y be random variables –independence: for any x and y, Pr[X=x & Y=y] = Pr[X=x]Pr[Y=y] –intuition: value of X does not influence value of Y, and vice-versa –dependence: e.g.](http://images.slideplayer.com/16/5039536/slides/slide_12.jpg "X, Y coin flips, but Y is always opposite of X Expected (mean) value of X: –only makes sense for numeric random variables – average value of X according to its distribution –formally, E[X] = (Pr[X = x] *x), sum is over all x in S –often denoted by –always true: E[X + Y] = E[X] + E[Y] –for independent random variables: E[XY] = E[X]E[Y] Variance of X: –Var(X) = E[(X – )^2]; often denoted by ^2 –standard deviation is sqrt(Var(X)) = .")
13
Convergence to Expectations Let X1, X2,…, Xn be: –independent random variables –with the same distribution Pr[X=x] –expectation = E[X] and variance ^2 –independent and identically distributed (i.i.d.) –essentially n repeated “trials” of the same experiment –natural to examine r.v. Z = (1/n) Xi, where sum is over i=1,…,n –example: number of heads in a sequence of coin flips –example: degree of a vertex in the random graph model –E[Z] = E[X]; what can we say about the distribution of Z? Central Limit Theorem: –as n becomes large, Z becomes normally distributed with expectation and variance ^2/n –here’s a demodemo
![Convergence to Expectations Let X1, X2,…, Xn be: –independent random variables –with the same distribution Pr[X=x] –expectation = E[X] and variance ^2 –independent and identically distributed (i.i.d.) –essentially n repeated trials of the same experiment –natural to examine r.v.](http://images.slideplayer.com/16/5039536/slides/slide_13.jpg "Z = (1/n) Xi, where sum is over i=1,…,n –example: number of heads in a sequence of coin flips –example: degree of a vertex in the random graph model –E[Z] = E[X]; what can we say about the distribution of Z. Central Limit Theorem: –as n becomes large, Z becomes normally distributed with expectation and variance ^2/n –here’s a demodemo.")
14
The Erdos-Renyi Model

15
The Erdos-Renyi (ER) Model (Random Graphs) A model in which all edges: –are equally probable and appear independently Two parameters: NW size N > 1 and edge probability p: –each edge (u,v) appears with probability p, is absent with probability 1-p –N(N-1)/2 trials of a biased coin flip –results in a probability distribution D(N,p) over networks of size N –especially easy to generate networks from D(N,p) About the simplest imaginable formation model The usual regime of interest is when p ~ 1/N, N is large –e.g. p = 1/2N, p = 1/N, p = 2/N, p=150/N, p = log(N)/N, etc. –in expectation, each vertex will have a “small” number of neighbors (~ pN) Gladwell’s “Magic Number 150” and cognitive bounds on degree mathematical interest: just near the boundary of connectivity –will then examine what happens when N infinity –can thus study properties of large networks with bounded degree Degree distribution of a typical G drawn from D(N,p): –draw G according to D(N,p); look at a random vertex u in G –what is Pr[deg(u) = k] for any fixed k? –Poisson distribution with mean = p(N-1) ~ pN –Sharply concentrated; not heavy-tailed
/N, etc. –in expectation, each vertex will have a small number of neighbors (~ pN) Gladwell’s Magic Number 150 and cognitive bounds on degree mathematical interest: just near the boundary of connectivity –will then examine what happens when N infinity –can thus study properties of large networks with bounded degree Degree distribution of a typical G drawn from D(N,p): –draw G according to D(N,p); look at a random vertex u in G –what is Pr[deg(u) = k] for any fixed k. –Poisson distribution with mean = p(N-1) ~ pN –Sharply concentrated; not heavy-tailed.")
16
The Poisson Distribution The Poisson distribution: –applies to variables taken on integer values > 0 –often used to model counts of events number of phone calls placed in a given time period number of times a neuron fires in a given time period –single free parameter –probability of exactly x events: exp(- ) ^x/x! mean and variance are both here are some examplesexamples –similar to a normal (bell-shaped) distribution, but only takes on positive, integer values
 distribution, but only takes on positive, integer values.")
17
A Closely Related Model In Erdos-Renyi: –expected number of edges in the network = pN(N-1)/2 = m –actual number of edges will be ”extremely close” to m –so suppose we instead of fixing p, we fix the number of edges m Incremental Erdos-Renyi model: –start with N vertices and no edges –at each time step, add a new edge, up to m edges total –choose new edge randomly from among all missing edges Allows study of the evolution or emergence of properties: –as the number of edges m grows (in relation to N) –equivalently, as p is increased (in relation to N) For our purposes, these models are equivalent under pN(N-1)/2 = m For both models: –high probability “almost all” large graphs of a given edge density
/2 = m –actual number of edges will be extremely close to m –so suppose we instead of fixing p, we fix the number of edges m Incremental Erdos-Renyi model: –start with N vertices and no edges –at each time step, add a new edge, up to m edges total –choose new edge randomly from among all missing edges Allows study of the evolution or emergence of properties: –as the number of edges m grows (in relation to N) –equivalently, as p is increased (in relation to N) For our purposes, these models are equivalent under pN(N-1)/2 = m For both models: –high probability almost all large graphs of a given edge density")
18
The Evolution of a Random Network We have a large number N of vertices We start randomly adding edges one at a time At what point will the network: –have at least one “large” connected component? –have a single connected component? –have “small” diameter? –have a “large” clique? –have a “large” chromatic number? How gradually or suddenly do these properties appear?

19
Monotone Network Properties Often interested in monotone graph properties: –let G have the property –add edges to G to obtain G’ –then G’ must have the property also Examples: –G is connected –G has diameter <= d (not exactly d) –G has a clique of size >= k (not exactly k) –G has chromatic number >= c (not exactly c) –G has a matching of size >= m –d, k, c, m may depend on NW size N (How?) Difficult to study emergence of non-monotone properties as the number of edges is increased –what would it mean?
 –G has a clique of size >= k (not exactly k) –G has chromatic number >= c (not exactly c) –G has a matching of size >= m –d, k, c, m may depend on NW size N (How ) Difficult to study emergence of non-monotone properties as the number of edges is increased –what would it mean")
20
Formalizing Tipping: Thresholds for Monotone Properties [this slide optional] Consider Incremental Erdos-Renyi model –select m edges at random to include in G Let P be some monotone property of graphs –P(G) = 1 G has the property –P(G) = 0 G does not have the property Let m(N) be some function of NW size N –formalize idea that property P appears “suddenly” at m(N) edges Say that m(N) is a threshold or tipping function for P if: –let f(N) be any other function of N –look at ratio r(N) = f(N)/m(N) as N infinity –if r(N) 0: probability that P(G) = 1 in f(N) edges is 0 –if r(N) infinity: probability that P(G) = 1 in f(N) edges is 1 A purely structural definition of tipping –tipping results from incremental increase in connectivity
![Formalizing Tipping: Thresholds for Monotone Properties [this slide optional] Consider Incremental Erdos-Renyi model –select m edges at random to include in G Let P be some monotone property of graphs –P(G) = 1 G has the property –P(G) = 0 G does not have the property Let m(N) be some function of NW size N –formalize idea that property P appears suddenly at m(N) edges Say that m(N) is a threshold or tipping function for P if: –let f(N) be any other function of N –look at ratio r(N) = f(N)/m(N) as N infinity –if r(N) 0: probability that P(G) = 1 in f(N) edges is 0 –if r(N) infinity: probability that P(G) = 1 in f(N) edges is 1 A purely structural definition of tipping –tipping results from incremental increase in connectivity](http://images.slideplayer.com/16/5039536/slides/slide_20.jpg "Formalizing Tipping: Thresholds for Monotone Properties [this slide optional] Consider Incremental Erdos-Renyi model –select m edges at random to include in G Let P be some monotone property of graphs –P(G) = 1 G has the property –P(G) = 0 G does not have the property Let m(N) be some function of NW size N –formalize idea that property P appears suddenly at m(N) edges Say that m(N) is a threshold or tipping function for P if: –let f(N) be any other function of N –look at ratio r(N) = f(N)/m(N) as N infinity –if r(N) 0: probability that P(G) = 1 in f(N) edges is 0 –if r(N) infinity: probability that P(G) = 1 in f(N) edges is 1 A purely structural definition of tipping –tipping results from incremental increase in connectivity")
21
Recap Erdos-Renyi Model: –select each of the possible edges independently with prob. p –expected total number of edges is m = pN(N-1)/2 –expected degree of a vertex is p(N-1) –degree will obey a Poisson distribution (not heavy-tailed) Incremental Erdos-Renyi: –starting with no edges, just keep adding one edge at a time –always choose next edge randomly from among all missing edges –picking m edges total is like p = m/(2N(N-1)) Threshold or tipping m(N) for (say) connectivity: –fewer than m = m(N) edges graph almost certainly not connected –more than m = m(N) edges graph almost certainly is connected –made formal by examining limit as N infinity
/2 –expected degree of a vertex is p(N-1) –degree will obey a Poisson distribution (not heavy-tailed) Incremental Erdos-Renyi: –starting with no edges, just keep adding one edge at a time –always choose next edge randomly from among all missing edges –picking m edges total is like p = m/(2N(N-1)) Threshold or tipping m(N) for (say) connectivity: –fewer than m = m(N) edges graph almost certainly not connected –more than m = m(N) edges graph almost certainly is connected –made formal by examining limit as N infinity.")
22
So… Which Properties Tip? The following properties all have “tipping functions” m(N): –having a “giant component” –being connected –having “small” diameter –here is a nice demodemo 1996: All monotone graph properties! –So at least in one setting, tipping is the rule, not the exception Demo: look at the following progression –giant component connectivity small diameter –in Incremental Erdos-Renyi model (add one new edge at a time) –with remarkable consistency (N = 50): giant component ~ 40 edges, connected ~ 100, small diameter ~ 180 Number of possible edges = N(N-1)/2 = 1225 –[example 1] [example 2] [example 3] [example 4] [example 5][example 1][example 2][example 3][example 4][example 5]
: –having a giant component –being connected –having small diameter –here is a nice demodemo 1996: All monotone graph properties. –So at least in one setting, tipping is the rule, not the exception Demo: look at the following progression –giant component connectivity small diameter –in Incremental Erdos-Renyi model (add one new edge at a time) –with remarkable consistency (N = 50): giant component ~ 40 edges, connected ~ 100, small diameter ~ 180 Number of possible edges = N(N-1)/2 = 1225 –[example 1] [example 2] [example 3] [example 4] [example 5][example 1][example 2][example 3][example 4][example 5].")
23
More Precise… Connected component of size > N/2: –tipping function is m(N) = N (or p ~ 1/N) –note: full connectivity virtually impossible Fully connected: –tipping function is m(N) = (N/2)log(N) (or p ~ log(N)/N) –NW remains extremely sparse: only ~ log(N) edges per vertex Small diameter: –threshold is m(N) ~ N^(3/2) for diameter 2 (or p ~ 2/sqrt(N)) –fraction of possible edges still ~ 2/sqrt(N) 0 –generates very small worlds
 = N (or p ~ 1/N) –note: full connectivity virtually impossible Fully connected: –tipping function is m(N) = (N/2)log(N) (or p ~ log(N)/N) –NW remains extremely sparse: only ~ log(N) edges per vertex Small diameter: –threshold is m(N) ~ N^(3/2) for diameter 2 (or p ~ 2/sqrt(N)) –fraction of possible edges still ~ 2/sqrt(N) 0 –generates very small worlds")
24
Other Tipping Points Perfect matchings –consider only even N –tipping function is m(N) = (N/2)log(N) (or p ~ log(N)/N) –same as for connectivity! Cliques –k-clique tipping is m(N) = (1/2)N^(2 – 2/(k-1)) (p ~ 1/N^(2/k-1)) –edges appear immediately; triangles at N/2; etc. Coloring –k colors required just as k-cliques appear
 = (1/2)N^(2 – 2/(k-1)) (p ~ 1/N^(2/k-1)) –edges appear immediately; triangles at N/2; etc. Coloring –k colors required just as k-cliques appear.")
25
Erdos-Renyi Summary A model in which all connections are equally likely –each of the N(N-1)/2 edges chosen randomly & independently As we add edges, a precise sequence of events unfolds: –graph acquires a giant component –graph becomes connected –graph acquires small diameter –etc. etc. etc. Properties appear very suddenly (tipping, thresholds) –… and this is the rule, not the exception! All statements are mathematically precise But… is this how natural networks form? If not, which aspects are unrealistic? –maybe all edges are not equally likely…
 –… and this is the rule, not the exception. All statements are mathematically precise But… is this how natural networks form. If not, which aspects are unrealistic. –maybe all edges are not equally likely….")
26
The Clustering Coefficient of a Network Let nbr(u) denote the set of neighbors of u in a network –all vertices v such that the edge (u,v) is in the graph The clustering coefficient of u: –let k = |nbr(u)| (i.e., number of neighbors of u) –choose(k,2): max possible # of edges between vertices in nbr(u) –c(u) = (actual # of edges between vertices in nbr(u))/choose(k,2) –0 <= c(u) <= 1; measure of cliquishness of u’s neighborhood Clustering coefficient of a graph: –average of c(u) over all vertices u k = 4 choose(k,2) = 6 c(u) = 4/6 = 0.666…
 denote the set of neighbors of u in a network –all vertices v such that the edge (u,v) is in the graph The clustering coefficient of u: –let k = |nbr(u)| (i.e., number of neighbors of u) –choose(k,2): max possible # of edges between vertices in nbr(u) –c(u) = (actual # of edges between vertices in nbr(u))/choose(k,2) –0 <= c(u) <= 1; measure of cliquishness of u’s neighborhood Clustering coefficient of a graph: –average of c(u) over all vertices u k = 4 choose(k,2) = 6 c(u) = 4/6 = 0.666…")
27
Erdos-Renyi: Clustering Coefficient Generate a network G according to G(N,p) Examine a “typical” vertex u in G –choose u at random among all vertices in G –what do we expect c(u) to be? Answer: exactly p! In G(N,m), expect c(u) to be 2m/N(N-1) Both cases: c(u) entirely determined by overall density Baseline for comparison with “more clustered” models –Erdos-Renyi has no bias towards clustered or local edges Clustering coefficient meaningless in isolation Must compare to the “background rate” of connectivity
, expect c(u) to be 2m/N(N-1) Both cases: c(u) entirely determined by overall density Baseline for comparison with more clustered models –Erdos-Renyi has no bias towards clustered or local edges Clustering coefficient meaningless in isolation Must compare to the background rate of connectivity.")
28
Caveman and Solaria Erdos-Renyi: –sharing a common neighbor makes two vertices no more likely to be directly connected than two very “distant” vertices –every edge appears entirely independently of existing structure But in many settings, the opposite is true: –you tend to meet new friends through your old friends –two web pages pointing to a third might share a topic –two companies selling goods to a third are in related industries Watts’ Caveman world: –overall density of edges is low –but two vertices with a common neighbor are likely connected Watts’ Solaria world –overall density of edges low; no special bias towards local edges –“like” Erdos-Renyi

29
Making it More Precise: the -model –An incremental formation model –Pick network size N –Throw down a few random “seed” edges –Then for each pair of vertices u and v: compute probability of adding edge between u and v probability will depend on current network structure the more common neighbors u and v have, more likely to add edge provide knobs that let us adjust how weak/strong the effect is

30
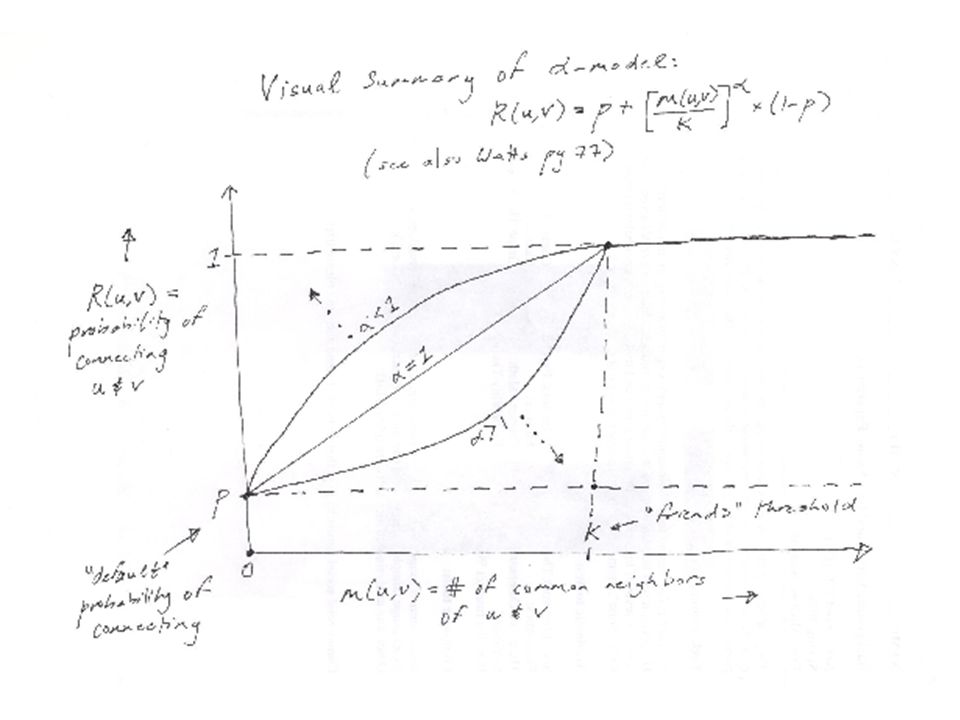
larger smaller = 1 y = probability of connecting u & v x = number of current common neighbors of u & v 1.0 “default” probability p network size N Making it More Precise: the -model = p + (1-p)*(x/N)^
*(x/N)^ ")
32
Small Worlds and Occam’s Razor For small , should generate large clustering coefficients –after all, we “programmed” the model to do so! But we do not want a new model for every little property –Erdos-Renyi small diameter – -model high clustering coefficient –etc. etc. etc. In the interests of Occam’s Razor, we would like to find –a single, simple model of network generation… –… that simultaneously captures many properties Watt’s small world: small diameter and high clustering –here is a figure showing that this can be captured in the -modelfigure

33
An Alternative Model The -model programmed high clustering into the formation process –and then we got small diamter “for free” (at certain ) A different model: –start with all vertices arranged on a ring or cycle –connect each vertex to all others that are within k steps –with probability p, rewire each local connection to a random vertex Initial cyclical structure models “local” or “geographic” connectivity Long-distance rewiring models “long-distance” connectivity p=0: high clustering, high diameter p=1: low clustering, low diameter (E-R) In between: look at this simulationsimulation
 A different model: –start with all vertices arranged on a ring or cycle –connect each vertex to all others that are within k steps –with probability p, rewire each local connection to a random vertex Initial cyclical structure models local or geographic connectivity Long-distance rewiring models long-distance connectivity p=0: high clustering, high diameter p=1: low clustering, low diameter (E-R) In between: look at this simulationsimulation")
34
Meanwhile, Back in the “Real” World… Watts examines three real networks as case studies: –the Kevin Bacon graph –the Western states power grid –the C. elegans nervous system For each of these networks, he: –computes its size, diameter, and clustering coefficient –compares diameter and clustering to best Erdos-Renyi approx. –shows that the best -model approximation is better –important to be “fair” to each model by finding best fit Overall moral: –if we care only about diameter and clustering, is better than E-R

36
Case 1: Kevin Bacon Graph Vertices: actors and actresses Edge between u and v if they appeared in a film together Here is the datadata

37
Case 2: Western States Power Grid Vertices: power stations in Western U.S. Edges: high-voltage power transmission lines Here is the network and datanetwork and data

38
Case 3: C. Elegans Nervous System Vertices: neurons in the C. elegans worm Edges: axons/synapses between neurons Here is the network and datanetwork and data

39
Two More Examples M. Newman on scientific collaboration networks –coauthorship networks in several distinct communities –differences in degrees (papers per author) –empirical verification of giant components small diameter (mean distance) high clustering coefficient Alberich et al. on the Marvel Universe –purely fictional social network –two characters linked if they appeared together in an issue –“empirical” verification of heavy-tailed distribution of degrees (issues and characters) giant component rather small clustering coefficient
 –empirical verification of giant components small diameter (mean distance) high clustering coefficient Alberich et al. on the Marvel Universe –purely fictional social network –two characters linked if they appeared together in an issue – empirical verification of heavy-tailed distribution of degrees (issues and characters) giant component rather small clustering coefficient.")
Similar presentations













 >")
 Networked Life CSE 112 Spring 2007 Michael.>")




, Room 110 –extra credit reports Turn in revisions of NW Construction.>")
