Download presentation
Presentation is loading. Please wait.

1
Search Engine Technology Slides are revised version of the ones taken from http://panda.cs.binghamton.edu/~meng/

2
Search Engine Technology Two general paradigms for finding information on Web: Browsing: From a starting point, navigate through hyperlinks to find desired documents. –Yahoo’s category hierarchy facilitates browsing. Searching: Submit a query to a search engine to find desired documents. –Many well-known search engines on the Web: AltaVista, Excite, HotBot, Infoseek, Lycos, Google, Northern Light, etc.

3
Browsing Versus Searching Category hierarchy is built mostly manually and search engine databases can be created automatically. Search engines can index much more documents than a category hierarchy. Browsing is good for finding some desired documents and searching is better for finding a lot of desired documents. Browsing is more accurate (less junk will be encountered) than searching.
 than searching..")
4
Search Engine A search engine is essentially a text retrieval system for web pages plus a Web interface. So what’s new???

5
Start on 2/19/01

6
Some Characteristics of the Web Web pages are –very voluminous and diversified –widely distributed on many servers. –extremely dynamic/volatile. Web pages have –more structures (extensively tagged). –are extensively linked. –may often have other associated metadata Web users are –ordinary folks (“dolts”?) without special training they tend to submit short queries. –There is a very large user community. Use the links and tags and Meta-data! Use the social structure of the web Standard content-based IR Methods may not work
. –are extensively linked. –may often have other associated metadata Web users are –ordinary folks ( dolts ) without special training they tend to submit short queries. –There is a very large user community. Use the links and tags and Meta-data. Use the social structure of the web Standard content-based IR Methods may not work.")
7
Overview Discuss how to take the special characteristics of the Web into consideration for building good search engines. Specific Subtopics: The use of tag information The use of link information Robot/Crawling Clustering/Collaborative Filtering

8
Use of TAG information

9
Use of Tag Information (1) Web pages are mostly HTML documents (for now). HTML tags allow the author of a web page to –Control the display of page contents on the Web. –Express their emphases on different parts of the page. HTML tags provide additional information about the contents of a web page. Can we make use of the tag information to improve the effectiveness of a search engine?

10
Use of Tag Information (2) Two main ideas of using tags: Associate different importance to term occurrences in different tags. Use anchor text to index referenced documents....... airplane ticket and hotel...... Page 1 Page 2: http://travelocity.com/

11
Use of Tag Information (3) Many search engines are using tags to improve retrieval effectiveness. Associating different importance to term occurrences is used in Altavista, HotBot, Yahoo, Lycos, LASER, SIBRIS. WWWW and Google use terms in anchor tags to index a referenced page. Shortcomings –very few tags are considered –relative importance of tags not studied –lacks rigorous performance study

12
Use of Tag Information (4) The Webor Method (Cutler 97, Cutler 99) Partition HTML tags into six ordered classes: –title, header, list, strong, anchor, plain Extend the term frequency value of a term in a document into a term frequency vector (TFV). Suppose term t appears in the i th class tf i times, i = 1..6. Then TFV = (tf 1, tf 2, tf 3, tf 4, tf 5, tf 6 ). Example: If for page p, term “binghamton” appears 1 time in the title, 2 times in the headers and 8 times in the anchors of hyperlinks pointing to p, then for this term in p: TFV = (1, 2, 0, 0, 8, 0).
. Example: If for page p, term binghamton appears 1 time in the title, 2 times in the headers and 8 times in the anchors of hyperlinks pointing to p, then for this term in p: TFV = (1, 2, 0, 0, 8, 0)..")
13
Use of Tag Information (5) The Webor Method (Continued) Assign different importance values to term occurrences in different classes. Let civ i be the importance value assigned to the ith class. We have CIV = (civ 1, civ 2, civ 3, civ 4, civ 5, civ 6 ) Extend the tf term weighting scheme –tfw = TFV CIV = tf 1 civ 1 + … + tf 6 civ 6 When CIV = (1, 1, 1, 1, 0, 1), the new tfw becomes the tfw in traditional text retrieval. How to find Optimal CIV?
 Extend the tf term weighting scheme –tfw = TFV CIV = tf 1 civ 1 + … + tf 6 civ 6 When CIV = (1, 1, 1, 1, 0, 1), the new tfw becomes the tfw in traditional text retrieval. How to find Optimal CIV .")
14
Use of Tag Information (6) The Webor Method (Continued) Challenge: How to find the (optimal) CIV = (civ 1, civ 2, civ 3, civ 4, civ 5, civ 6 ) such that the retrieval performance can be improved the most? One Solution: Find the optimal CIV experimentally using a hill-climbing search in the space of CIV Details Skipped

15
Use of Tag Information (7) The Webor Method (Continued) Creating a test bed: Web pages: A snap shot of the Binghamton University site in Dec. 1996 (about 4,600 pages; after removing duplicates, about 3,000 pages). Queries: 20 queries were created (see next page). For each query, (manually) identify the documents relevant to the query.
. Queries: 20 queries were created (see next page). For each query, (manually) identify the documents relevant to the query..")
16
Use of Tag Information (8) The Webor Method (Continued): 20 test bed queries: web-based retrieval concert and music neural network intramural sports master thesis in geology cognitive science prerequisite of algorithm campus dining handicap student help career development promotion guideline non-matriculated admissions grievance committee student associations laboratory in electrical engineering research centers anthropology chairman engineering program computer workshop papers in philosophy and computer and cognitive system
 The Webor Method (Continued): 20 test bed queries: web-based retrieval concert and music neural network intramural sports master thesis in geology cognitive science prerequisite of algorithm campus dining handicap student help career development promotion guideline non-matriculated admissions grievance committee student associations laboratory in electrical engineering research centers anthropology chairman engineering program computer workshop papers in philosophy and computer and cognitive system")
17
Use of Tag Information (9) The Webor Method (Continued) Use a Genetic Algorithm Use a Genetic Algorithm to find the optimal CIV. The initial population has 30 CIVs. –25 are randomly generated (range [1, 15]) –5 are “good” CIVs from manual screening. Each new generation of CIVs is produced by executing: crossover, mutation, and reproduction.
 –5 are good CIVs from manual screening. Each new generation of CIVs is produced by executing: crossover, mutation, and reproduction..")
18
Use of Tag Information (10) The Genetic Algorithm (continued) Crossover –done for each consecutive pair CIVs, with probability 0.75. –a single random cut for each selected pair Example: old pair new pair (1, 4, 2, 1, 2, 1) (2, 3, 2, 1, 2, 1) (2, 3, 1, 2, 5, 1) (1, 4, 1, 2, 5, 1) cut
 (2, 3, 2, 1, 2, 1) (2, 3, 1, 2, 5, 1) (1, 4, 1, 2, 5, 1) cut.")
19
Use of Tag Information (11) The Genetic Algorithm (continued) Mutation –performed on each CIV with probability 0.1. –When mutation is performed, each CIV component is either decreased or increased by one with equal probability, subject to range conditions of each component. Example: If a component is already 15, then it cannot be increased.

20
Use of Tag Information (12) The Genetic Algorithm (continued) The fitness functionThe fitness function –A CIV has an initial fitness of 0 when the 11-point average precision is less than 0.22. (11-point average precision - 0.22), otherwise. –The final fitness is its initial fitness divided by the sum of the initial fitnesses of all the CIVs in the current generation. each fitness is between 0 and 1 the sum of all fitnesses is 1
, otherwise. –The final fitness is its initial fitness divided by the sum of the initial fitnesses of all the CIVs in the current generation. each fitness is between 0 and 1 the sum of all fitnesses is 1.")
21
Use of Tag Information (13) The Genetic Algorithm (continued) Reproduction –Wheel of fortune scheme to select the parent population. –The scheme selects fit CIVs with high probability and unfit CIVs with low probability. –The same CIV may be selected more than once. The algorithm terminates after 25 generations and the best CIV obtained is reported as the optimal CIV. The 11-point average precision by the optimal CIV is reported as the performance of the CIV.

22
Use of Tag Information (14) The Webor Method (continued): Experimental Results Classes: title, header, list, strong, anchor, plain Queries Opt. CIV Normal New Improvement 1 st 10 281881 0.182 0.254 39.6% 2 nd 10 271881 0.172 0.255 48.3% all 251881 0.177 0.254 43.5% Conclusions: anchor and strong are most important header is also important title is only slightly more important than list and plain

23
Use of Tag Information (15) The Webor Method (continued): Summary The Webor method has the potential to substantially improve the retrieval effectiveness. But be cautious to draw any definitive conclusions as the results are too preliminary. Need to –Expand the set of queries in the test bed –Use other Web page collections

24
Use of LINK information

25
Use of Link Information (1) Hyperlinks among web pages provide new document retrieval opportunities. Selected Examples: Anchor texts can be used to index a referenced page (e.g., Webor, WWWW, Google). The ranking score (similarity) of a page with a query can be spread to its neighboring pages. Links can be used to compute the importance of web pages based on citation analysis. Links can be combined with a regular query to find authoritative pages on a given topic.
. The ranking score (similarity) of a page with a query can be spread to its neighboring pages. Links can be used to compute the importance of web pages based on citation analysis. Links can be combined with a regular query to find authoritative pages on a given topic..")
26
Connection to Citation Analysis Mirror mirror on the wall, who is the biggest Computer Scientist of them all? –The guy who wrote the most papers That are considered important by most people –By citing them in their own papers »“Science Citation Index” –Should I write survey papers or original papers? Infometrics; Bibliometrics

27
What Citation Index says About Rao’s papers

28
Desiderata for ranking A page that is referenced by lot of important pages (has more back links) is more important –A page referenced by a single important page may be more important than that referenced by five unimportant pages A page that references a lot of important pages is also important “Importance” can be propagated – Your importance is the weighted sum of the importance conferred on you by the pages that refer to you –The importance you confer on a page may be proportional to how many other pages you refer to (cite) (Also what you say about them when you cite them!) Different Notions of importance
 is more important –A page referenced by a single important page may be more important than that referenced by five unimportant pages A page that references a lot of important pages is also important Importance can be propagated – Your importance is the weighted sum of the importance conferred on you by the pages that refer to you –The importance you confer on a page may be proportional to how many other pages you refer to (cite) (Also what you say about them when you cite them!) Different Notions of importance")
29
Use of Link Information (2) Vector spread activation (Yuwono 97) The final ranking score of a page p is the sum of its regular similarity and a portion of the similarity of each page that points to p. Rationale: If a page is pointed to by many relevant pages, then the page is also likely to be relevant. Let sim(q, d i ) be the regular similarity between q and d i ; rs(q, d i ) be the ranking score of d i with respect to q; link(j, i) = 1 if d j points to d i, = 0 otherwise. rs(q, di) = sim(q, di) + link(j, i) sim(q, dj) = 0.2 is a constant parameter.
 be the regular similarity between q and d i ; rs(q, d i ) be the ranking score of d i with respect to q; link(j, i) = 1 if d j points to d i, = 0 otherwise. rs(q, di) = sim(q, di) + link(j, i) sim(q, dj) = 0.2 is a constant parameter..")
30
Authority and Hub Pages (1) The basic idea: A page is a good authoritative page with respect to a given query if it is referenced (i.e., pointed to) by many (good hub) pages that are related to the query. A page is a good hub page with respect to a given query if it points to many good authoritative pages with respect to the query. Good authoritative pages (authorities) and good hub pages (hubs) reinforce each other.
 and good hub pages (hubs) reinforce each other..")
31
Authority and Hub Pages (2) Authorities and hubs related to the same query tend to form a bipartite subgraph of the web graph. A web page can be a good authority and a good hub. hubsauthorities

32
Authority and Hub Pages (3) Main steps of the algorithm for finding good authorities and hubs related to a query q. 1.Submit q to a regular similarity-based search engine. Let S be the set of top n pages returned by the search engine. (S is called the root set and n is often in the low hundreds). 2.Expand S into a large set T (base set): Add pages that are pointed to by any page in S. Add pages that point to any page in S. If a page has too many parent pages, only the first k parent pages will be used for some k.
. 2.Expand S into a large set T (base set): Add pages that are pointed to by any page in S. Add pages that point to any page in S. If a page has too many parent pages, only the first k parent pages will be used for some k..")
33
Authority and Hub Pages (4) 3. Find the subgraph SG of the web graph that is induced by T. S T
 3. Find the subgraph SG of the web graph that is induced by T. S T")
35
Authority and Hub Pages (5) Steps 2 and 3 can be made easy by storing the link structure of the Web in advance. Link structure table parent_url child_url url1 url2 url1 url3

36
USER(41): aaa ;;an adjacency matrix #2A((0 0 1) (0 0 1) (1 0 0)) USER(42): x ;;an initial vector #2A((1) (2) (3)) USER(43): (apower-iteration aaa x 2) ;;authority computation—two iterations [1] USER(44): (apower-iterate aaa x 3) ;;after three iterations #2A((0.041630544) (0.0) (0.99913305)) [1] USER(45): (apower-iterate aaa x 15) ;;after 15 iterations #2A((1.0172524e-5) (0.0) (1.0)) [1] USER(46): (power-iterate aaa x 5) ;;hub computation 5 iterations #2A((0.70641726) (0.70641726) (0.04415108)) [1] USER(47): (power-iterate aaa x 15) ;;15 iterations #2A((0.7071068) (0.7071068) (4.3158376e-5)) [1] USER(48): Y ;; a new initial vector #2A((89) (25) (2)) [1] USER(49): (power-iterate aaa Y 15) ;;Magic… same answer after 15 iter #2A((0.7071068) (0.7071068) (7.571644e-7)) A B C
![USER(41): aaa ;;an adjacency matrix #2A((0 0 1) (0 0 1) (1 0 0)) USER(42): x ;;an initial vector #2A((1) (2) (3)) USER(43): (apower-iteration aaa x 2) ;;authority computation—two iterations [1] USER(44): (apower-iterate aaa x 3) ;;after three iterations #2A(( ) (0.0) ( )) [1] USER(45): (apower-iterate aaa x 15) ;;after 15 iterations #2A(( e-5) (0.0) (1.0)) [1] USER(46): (power-iterate aaa x 5) ;;hub computation 5 iterations #2A(( ) ( ) ( )) [1] USER(47): (power-iterate aaa x 15) ;;15 iterations #2A(( ) ( ) ( e-5)) [1] USER(48): Y ;; a new initial vector #2A((89) (25) (2)) [1] USER(49): (power-iterate aaa Y 15) ;;Magic… same answer after 15 iter #2A(( ) ( ) ( e-7)) A B C](http://images.slideplayer.com/16/4997275/slides/slide_36.jpg "USER(41): aaa ;;an adjacency matrix #2A((0 0 1) (0 0 1) (1 0 0)) USER(42): x ;;an initial vector #2A((1) (2) (3)) USER(43): (apower-iteration aaa x 2) ;;authority computation—two iterations [1] USER(44): (apower-iterate aaa x 3) ;;after three iterations #2A(( ) (0.0) ( )) [1] USER(45): (apower-iterate aaa x 15) ;;after 15 iterations #2A(( e-5) (0.0) (1.0)) [1] USER(46): (power-iterate aaa x 5) ;;hub computation 5 iterations #2A(( ) ( ) ( )) [1] USER(47): (power-iterate aaa x 15) ;;15 iterations #2A(( ) ( ) ( e-5)) [1] USER(48): Y ;; a new initial vector #2A((89) (25) (2)) [1] USER(49): (power-iterate aaa Y 15) ;;Magic… same answer after 15 iter #2A(( ) ( ) ( e-7)) A B C")
37
Start of 2/21 lecture

38
Authority and Hub Pages (6) 4.Compute the authority score and hub score of each web page in T based on the subgraph SG(V, E). Given a page p, let a(p) be the authority score of p h(p) be the hub score of p (p, q) be a directed edge in E from p to q. Two basic operations: Operation I: Update each a(p) as the sum of all the hub scores of web pages that point to p. Operation O: Update each h(p) as the sum of all the authority scores of web pages pointed to by p.
 be the authority score of p h(p) be the hub score of p (p, q) be a directed edge in E from p to q. Two basic operations: Operation I: Update each a(p) as the sum of all the hub scores of web pages that point to p. Operation O: Update each h(p) as the sum of all the authority scores of web pages pointed to by p..")
39
Authority and Hub Pages (7) Operation I: for each page p: a(p) = h(q) q: (q, p) E Operation O: for each page p: h(p) = a(q) q: (p, q) E q1q1 q2q2 q3q3 p q3q3 q2q2 q1q1 p
 Operation I: for each page p: a(p) = h(q) q: (q, p) E Operation O: for each page p: h(p) = a(q) q: (p, q) E q1q1 q2q2 q3q3 p q3q3 q2q2 q1q1 p")
40
Authority and Hub Pages (8) Matrix representation of operations I and O. Let A be the adjacency matrix of SG: entry (p, q) is 1 if p has a link to q, else the entry is 0. Let A T be the transpose of A. Let h i be vector of hub scores after i iterations. Let a i be the vector of authority scores after i iterations. Operation I: a i = A T h i-1 Operation O: h i = A a i
 is 1 if p has a link to q, else the entry is 0. Let A T be the transpose of A. Let h i be vector of hub scores after i iterations. Let a i be the vector of authority scores after i iterations. Operation I: a i = A T h i-1 Operation O: h i = A a i.")
41
Authority and Hub Pages (9) After each iteration of applying Operations I and O, normalize all authority and hub scores. Repeat until the scores for each page converge (the convergence is guaranteed). 5. Sort pages in descending authority scores. 6. Display the top authority pages.
. 5. Sort pages in descending authority scores. 6. Display the top authority pages..")
42
Authority and Hub Pages (10) Algorithm (summary) submit q to a search engine to obtain the root set S; expand S into the base set T; obtain the induced subgraph SG(V, E) using T; initialize a(p) = h(p) = 1 for all p in V; for each p in V until the scores converge { apply Operation I; apply Operation O; normalize a(p) and h(p); } return pages with top authority scores;
 Algorithm (summary) submit q to a search engine to obtain the root set S; expand S into the base set T; obtain the induced subgraph SG(V, E) using T; initialize a(p) = h(p) = 1 for all p in V; for each p in V until the scores converge { apply Operation I; apply Operation O; normalize a(p) and h(p); } return pages with top authority scores;")
43
Authority and Hub Pages (11) Example: Initialize all scores to 1. 1 st Iteration: I operation: a(q 1 ) = 1, a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 3, a(p 2 ) = 2 O operation: h(q 1 ) = 5, h(q 2 ) = 3, h(q 3 ) = 5, h(p 1 ) = 1, h(p 2 ) = 0 Normalization: a(q 1 ) = 0.267, a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 0.802, a(p 2 ) = 0.535, h(q 1 ) = 0.645, h(q 2 ) = 0.387, h(q 3 ) = 0.645, h(p 1 ) = 0.129, h(p 2 ) = 0 q1q1 q2q2 q3q3 p1p1 p2p2
 = 1, a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 3, a(p 2 ) = 2 O operation: h(q 1 ) = 5, h(q 2 ) = 3, h(q 3 ) = 5, h(p 1 ) = 1, h(p 2 ) = 0 Normalization: a(q 1 ) = 0.267, a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 0.802, a(p 2 ) = 0.535, h(q 1 ) = 0.645, h(q 2 ) = 0.387, h(q 3 ) = 0.645, h(p 1 ) = 0.129, h(p 2 ) = 0 q1q1 q2q2 q3q3 p1p1 p2p2.")
44
Authority and Hub Pages (12) After 2 Iterations: a(q 1 ) = 0.061, a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 0.791, a(p 2 ) = 0.609, h(q 1 ) = 0.656, h(q 2 ) = 0.371, h(q 3 ) = 0.656, h(p 1 ) = 0.029, h(p 2 ) = 0 After 5 Iterations: a(q 1 ) = a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 0.788, a(p 2 ) = 0.615 h(q 1 ) = 0.657, h(q 2 ) = 0.369, h(q 3 ) = 0.657, h(p 1 ) = h(p 2 ) = 0 q1q1 q2q2 q3q3 p1p1 p2p2
 After 2 Iterations: a(q 1 ) = 0.061, a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 0.791, a(p 2 ) = 0.609, h(q 1 ) = 0.656, h(q 2 ) = 0.371, h(q 3 ) = 0.656, h(p 1 ) = 0.029, h(p 2 ) = 0 After 5 Iterations: a(q 1 ) = a(q 2 ) = a(q 3 ) = 0, a(p 1 ) = 0.788, a(p 2 ) = h(q 1 ) = 0.657, h(q 2 ) = 0.369, h(q 3 ) = 0.657, h(p 1 ) = h(p 2 ) = 0 q1q1 q2q2 q3q3 p1p1 p2p2")
45
(why) Does the procedure converge? x x2x2 xkxk As we multiply repeatedly with M, the component of x in the direction of principal eigen vector gets stretched wrt to other directions.. So we converge finally to the direction of principal eigenvector

46
What about non-principal eigen vectors? Principal eigen vector gives the authorities (and hubs) What do the other ones do? –They may be able to show the clustering in the documents (see page 23 in Kleinberg paper) The clusters are found by looking at the positive and negative ends of the secondary eigen vectors (ppl vector has only +ve end…)
 What do the other ones do. –They may be able to show the clustering in the documents (see page 23 in Kleinberg paper) The clusters are found by looking at the positive and negative ends of the secondary eigen vectors (ppl vector has only +ve end…).")
47
Authority and Hub Pages (13) Should all links be equally treated? Two considerations: Some links may be more meaningful/important than other links. Web site creators may trick the system to make their pages more authoritative by adding dummy pages pointing to their cover pages (spamming). Domain name: the first level of the URL of a page. Example: domain name for “panda.cs.binghamton.edu/~meng/meng.html” is “panda.cs.binghamton.edu”.
. Domain name: the first level of the URL of a page. Example: domain name for panda.cs.binghamton.edu/~meng/meng.html is panda.cs.binghamton.edu ..")
48
Authority and Hub Pages (14) Transverse link: links between pages with different domain names. Intrinsic link: links between pages with the same domain name. Transverse links are more important than intrinsic links. Two ways to incorporate this: 1.Use only transverse links and discard intrinsic links. 2.Give lower weights to intrinsic links.

49
Authority and Hub Pages (15) How to give lower weights to intrinsic links? In adjacency matrix A, entry (p, q) should be assigned as follows: If p has a transverse link to q, the entry is 1. If p has an intrinsic link to q, the entry is c, where 0 < c < 1. If p has no link to q, the entry is 0.
 should be assigned as follows: If p has a transverse link to q, the entry is 1. If p has an intrinsic link to q, the entry is c, where 0 < c < 1. If p has no link to q, the entry is 0..")
50
Authority and Hub Pages (16) For a given link (p, q), let V(p, q) be the vicinity (e.g., 50 characters) of the link. If V(p, q) contains terms in the user query (topic), then the link should be more useful for identifying authoritative pages. To incorporate this: In adjacency matrix A, make the weight associated with link (p, q) to be 1+n(p, q), where n(p, q) is the number of terms in V(p, q) that appear in the query.
 contains terms in the user query (topic), then the link should be more useful for identifying authoritative pages. To incorporate this: In adjacency matrix A, make the weight associated with link (p, q) to be 1+n(p, q), where n(p, q) is the number of terms in V(p, q) that appear in the query..")
51
Authority and Hub Pages (17) Sample experiments: Rank based on large in-degree (or backlinks) query: game Rank in-degree URL 1 13 http://www.gotm.orghttp://www.gotm.org 2 12 http://www.gamezero.com/team-0/http://www.gamezero.com/team-0/ 3 12 http://ngp.ngpc.state.ne.us/gp.htmlhttp://ngp.ngpc.state.ne.us/gp.html 4 12 http://www.ben2.ucla.edu/~permadi/http://www.ben2.ucla.edu/~permadi/ gamelink/gamelink.html 5 11 http://igolfto.net/http://igolfto.net/ 6 11 http://www.eduplace.com/geo/indexhi.html http://www.eduplace.com/geo/indexhi.html Only pages 1, 2 and 4 are authoritative game pages.
 Sample experiments: Rank based on large in-degree (or backlinks) query: game Rank in-degree URL gamelink/gamelink.html Only pages 1, 2 and 4 are authoritative game pages.")
52
Authority and Hub Pages (18) Sample experiments (continued) Rank based on large authority score. query: game Rank Authority URL 1 0.613 http://www.gotm.orghttp://www.gotm.org 2 0.390 http://ad/doubleclick/net/jump/http://ad/doubleclick/net/jump/ gamefan-network.com/ 3 0.342 http://www.d2realm.com/http://www.d2realm.com/ 4 0.324 http://www.counter-strike.net 5 0.324 http://tech-base.com/ 6 0.306 http://www.e3zone.comhttp://www.e3zone.com All pages are authoritative game pages.

53
Authority and Hub Pages (19) Sample experiments (continued) Rank based on large authority score. query: free email Rank Authority URL 1 0.525 http://mail.chek.com/http://mail.chek.com/ 2 0.345 http://www.hotmail/com/http://www.hotmail/com/ 3 0.309 http://www.naplesnews.net/http://www.naplesnews.net 4 0.261 http://www.11mail.com/ 5 0.254 http://www.dwp.net/ 6 0.246 http://www.wptamail.com/http://www.wptamail.com/ All pages are authoritative free email pages.

54
Cora thinks Rao is Authoritative on Planning Citeseer has him down at 90 th position… How come??? --Planning has two clusters --Planning & reinforcement learning --Deterministic planning --The first is a bigger cluster --Rao is big in the second cluster

55
Start of 2/26

56
Announcements Project task 2 given Project task 1 progress report due on this Friday Questions??

58
Authority and Hub Pages (20) For a given query, the induced subgraph may have multiple dense bipartite communities due to: multiple meanings of query terms multiple web communities related to the query ad page obscure web page
 For a given query, the induced subgraph may have multiple dense bipartite communities due to: multiple meanings of query terms multiple web communities related to the query ad page obscure web page")
59
Authority and Hub Pages (21) Multiple Communities (continued) If a page is not in a community, then it is unlikely to have a high authority score even when it has many backlinks. Example: Suppose initially all hub and authority scores are 1. q’s p q’s p’s G1: G2: 1 st iteration for G1: a(q) = 0, a(p) = 5, h(q) = 5, h(p) = 0 1 st iteration for G2: a(q) = 0, a(p) = 3, h(q) = 9, h(p) = 0
 = 0, a(p) = 5, h(q) = 5, h(p) = 0 1 st iteration for G2: a(q) = 0, a(p) = 3, h(q) = 9, h(p) = 0.")
60
Authority and Hub Pages (22) Example (continued): 1 st normalization (suppose normalization factors H 1 for hubs and A 1 for authorities): for pages in G1: a(q) = 0, a(p) = 5/A 1, h(q) = 5/H 1, h(p) = 0 for pages in G2: a(q) = 0, a(p) = 3/A 1, h(q) = 9/H 1, a(p) = 0 After the nth iteration (suppose H n and A n are the normalization factors respectively): for pages in G1: a(p) = 5 n / (H 1 …H n-1 A n ) ---- a for pages in G2: a(p) = 3*9 n-1 /(H 1 …H n-1 A n ) ---- b Note that a/b approaches 0 when n is sufficiently large, that is, a is much much smaller than b.
 Example (continued): 1 st normalization (suppose normalization factors H 1 for hubs and A 1 for authorities): for pages in G1: a(q) = 0, a(p) = 5/A 1, h(q) = 5/H 1, h(p) = 0 for pages in G2: a(q) = 0, a(p) = 3/A 1, h(q) = 9/H 1, a(p) = 0 After the nth iteration (suppose H n and A n are the normalization factors respectively): for pages in G1: a(p) = 5 n / (H 1 …H n-1 A n ) ---- a for pages in G2: a(p) = 3*9 n-1 /(H 1 …H n-1 A n ) ---- b Note that a/b approaches 0 when n is sufficiently large, that is, a is much much smaller than b.")
61
Authority and Hub Pages (23) Multiple Communities (continued) If a page is not in the largest community, then it is unlikely to have a high authority score. –The reason is similar to that regarding pages not in a community. larger community smaller community

62
Authority and Hub Pages (24) Multiple Communities (continued) How to retrieve pages from smaller communities? A method for finding pages in nth largest community: –Identify the next largest community using the existing algorithm. –Destroy this community by removing links associated with pages having large authorities. –Reset all authority and hub values back to 1 and calculate all authority and hub values again. –Repeat the above n 1 times and the next largest community will be the nth largest community.

63
Authority and Hub Pages (25) Query: House (first community)
 Query: House (first community)")
64
Authority and Hub Pages (26) Query: House (second community)
 Query: House (second community)")
65
PageRank

66
Use of Link Information (3) PageRank citation ranking (Page 98). Web can be viewed as a huge directed graph G(V, E), where V is the set of web pages (vertices) and E is the set of hyperlinks (directed edges). Each page may have a number of outgoing edges (forward links) and a number of incoming links (backlinks). Each backlink of a page represents a citation to the page. PageRank is a measure of global web page importance based on the backlinks of web pages.
, where V is the set of web pages (vertices) and E is the set of hyperlinks (directed edges). Each page may have a number of outgoing edges (forward links) and a number of incoming links (backlinks). Each backlink of a page represents a citation to the page. PageRank is a measure of global web page importance based on the backlinks of web pages..")
67
Pagerank (Ranking the whole darned web) Basic Idea: Think of Web as a big graph. A random surfer keeps randomly clicking on the links. The importance of a page is the probability that the surfer finds herself on that page --Talk of transition matrix instead of adjacency matrix Transition matrix derived from adjacency matrix --If there are F(u) forward links from a page u, then the probability that the surfer clicks on any of those is 1/F(u) (Columns sum to 1. Stochastic matrix) --But even a dumb user may once in a while do something other than follow URLs on the current page.. --Idea: Put a small probability that the user goes off to a page not pointed to by the current page. Principal eigenvector Gives the stationary distribution!
 forward links from a page u, then the probability that the surfer clicks on any of those is 1/F(u) (Columns sum to 1. Stochastic matrix) --But even a dumb user may once in a while do something other than follow URLs on the current page.. --Idea: Put a small probability that the user goes off to a page not pointed to by the current page. Principal eigenvector Gives the stationary distribution!.")
68
Computing PageRank (1) PageRank is based on the following basic ideas: If a page is linked to by many pages, then the page is likely to be important. If a page is linked to by important pages, then the page is likely to be important even though there aren’t too many pages linking to it. The importance of a page is divided evenly and propagated to the pages pointed to by it. 10 5 5

69
Computing PageRank (2) PageRank Definition Let u be a web page, F u be the set of pages u points to, B u be the set of pages that point to u, N u = |F u | be the number pages in F u. The rank (importance) of a page u can be defined by: R(u) = ( R(v) / N v ) v B u
 of a page u can be defined by: R(u) = ( R(v) / N v ) v B u.")
70
Computing PageRank (3) PageRank is defined recursively and can be computed iteratively. Initiate all page ranks to be 1/N, N is the number of vertices in the Web graph. In i th iteration, the rank of a page is computed using the ranks of its parent pages in (i-1)th iteration. Repeat until all ranks converge. Let R i (u) be the rank of page u in ith iteration and R 0 (u) be the initial rank of u. R i (u) = ( R i-1 (v) / N v ) v B u
th iteration. Repeat until all ranks converge. Let R i (u) be the rank of page u in ith iteration and R 0 (u) be the initial rank of u. R i (u) = ( R i-1 (v) / N v ) v B u.")
71
Computing PageRank (4) Matrix representation Let M be an N N matrix and m uv be the entry at the u-th row and v-th column. m uv = 1/N v if page v has a link to page u m uv = 0 if there is no link from v to u Let R i be the N 1 rank vector for I-th iteration and R 0 be the initial rank vector. Then R i = M R i-1

72
Computing PageRank (5) If the ranks converge, i.e., there is a rank vector R such that R = M R, R is the eigenvector of matrix M with eigenvalue being 1. Convergence is guaranteed only if M is aperiodic (the Web graph is not a big cycle). This is practically guaranteed for Web. M is irreducible (the Web graph is strongly connected). This is usually not true. Principal eigen value for A stochastic matrix is 1
. This is practically guaranteed for Web. M is irreducible (the Web graph is strongly connected). This is usually not true. Principal eigen value for A stochastic matrix is 1.")
73
Computing PageRank (6) Rank sink: A page or a group of pages is a rank sink if they can receive rank propagation from its parents but cannot propagate rank to other pages. Rank sink causes the loss of total ranks. Example: A B CD (C, D) is a rank sink
 is a rank sink.")
74
Computing PageRank (7) A solution to the non-irreducibility and rank sink problem. Conceptually add a link from each page v to every page (include self). If v has no forward links originally, make all entries in the corresponding column in M be 1/N. If v has forward links originally, replace 1/N v in the corresponding column by c 1/N v and then add (1-c) 1/N to all entries, 0 < c < 1. Motivation comes also from random-surfer model
. If v has no forward links originally, make all entries in the corresponding column in M be 1/N. If v has forward links originally, replace 1/N v in the corresponding column by c 1/N v and then add (1-c) 1/N to all entries, 0 < c < 1. Motivation comes also from random-surfer model.")
75
Computing PageRank (8) M * = c (M + Z) + (1 – c) x K M* is irreducible. M* is stochastic, the sum of all entries of each column is 1 and there are no negative entries. Therefore, if M is replaced by M* as in R i = M* R i-1 then the convergence is guaranteed and there will be no loss of the total rank (which is 1). Z will have 1/N For sink pages And 0 otherwise K will have 1/N For all entries
. Z will have 1/N For sink pages And 0 otherwise K will have 1/N For all entries.")
76
Computing PageRank (9) Interpretation of M* based on the random walk model. If page v has no forward links originally, a web surfer at v can jump to any page in the Web with probability 1/N. If page v has forward links originally, a surfer at v can either follow a link to another page with probability c 1/N v, or jumps to any page with probability (1-c) 1/N.
 1/N..")
77
Start of 2/28 Task 1 submissions to cse494@godavari.eas.asu.edu cse494@godavari.eas.asu.edu (NO hardcopy submissions)
")
78
Computing PageRank (10) Example: Suppose the Web graph is: M = A B C D 0 0 0 ½ 11 0 0 0 0 1 0 ABCDABCD A B C D
 Example: Suppose the Web graph is: M = A B C D ½ ABCDABCD A B C D")
79
Computing PageRank (11) Example (continued): Suppose c = 0.8. All entries in Z are 0 and all entries in K are ¼. M* = 0.8 (M+Z) + 0.2 K = After 30 iterations: R(A) = R(B) = 0.176 R(C) = 0.332, R(D) = 0.316 0.05 0.05 0.05 0.45 0.85 0.85 0.05 0.05 0.05 0.05 0.85 0.05 Actually, my calculation says: A:.11; B=.11; C =.97 D=.18
 K = After 30 iterations: R(A) = R(B) = R(C) = 0.332, R(D) = Actually, my calculation says: A:.11; B=.11; C =.97 D=.18.")
80
Computing PageRank (12) Incorporate the ranks of pages into the ranking function of a search engine. The ranking score of a web page can be a weighted sum of its regular similarity with a query and its importance. ranking_score(q, d) = w sim(q, d) + (1-w) R(d), if sim(q, d) > 0 = 0, otherwise where 0 < w < 1. –Both sim(q, d) and R(d) need to be normalized to between [0, 1].
 = w sim(q, d) + (1-w) R(d), if sim(q, d) > 0 = 0, otherwise where 0 < w < 1. –Both sim(q, d) and R(d) need to be normalized to between [0, 1]..")
81
Use of Link Information (13) PageRank defines the global importance of web pages but the importance is domain/topic independent. We often need to find important/authoritative pages which are relevant to a given query. –What are important web browser pages? –Which pages are important game pages? Kleinberg (Kleinberg 98) proposed to use authority and hub scores to measure the importance of a web page with respect to a given query.
 proposed to use authority and hub scores to measure the importance of a web page with respect to a given query..")
82
Make sure to talk about Stability of page rank

84
Query complexity Complex queries (966 trials) –Average words 7.03 –Average operators ( +*–" ) 4.34 Typical Alta Vista queries are much simpler [Silverstein, Henzinger, Marais and Moricz] –Average query words 2.35 –Average operators ( +*–" ) 0.41 Forcibly adding a hub or authority node helped in 86% of the queries
![Query complexity Complex queries (966 trials) –Average words 7.03 –Average operators ( +*– ) 4.34 Typical Alta Vista queries are much simpler [Silverstein, Henzinger, Marais and Moricz] –Average query words 2.35 –Average operators ( +*– ) 0.41 Forcibly adding a hub or authority node helped in 86% of the queries](http://images.slideplayer.com/16/4997275/slides/slide_84.jpg "Query complexity Complex queries (966 trials) –Average words 7.03 –Average operators ( +*– ) 4.34 Typical Alta Vista queries are much simpler [Silverstein, Henzinger, Marais and Moricz] –Average query words 2.35 –Average operators ( +*– ) 0.41 Forcibly adding a hub or authority node helped in 86% of the queries")
85
Crawling

87
Main issues General-purpose crawling Context specific crawiling –Building topic-specific search engines…

88
Robot/Spider/Crawler (1) A robot (also known as spider, crawler, wanderer) is a program for fetching web pages from the Web. 243 registered spiders –Inktomi Slurp, Altavisa Scooter Standard search engine –Citeseer; Cora Just the CS papers… –Digimark Downloads just images; looking for watermarks –AdRelevance Just looking for those annoying banner ads (!!!) General purpose Vs. Topic Specific
 General purpose Vs. Topic Specific.")
89
Robot/Spider/Crawler (1) A robot (also known as spider, crawler, wanderer) is a program for fetching web pages from the Web. Main idea: 1.Place some initial URLs into a URL queue. 2.Repeat the steps below until the queue is empty –Take the next URL from the queue and fetch the web page using HTTP. –Extract new URLs from the downloaded web page and add them to the queue.

90
Web Crawling (Search) Strategy Starting location(s) Traversal order –Depth first –Breadth first –Or ??? Cycles? Coverage? Load? b c d e fg h i j

91
Storing Summaries Can’t store complete page text –Whole WWW doesn’t fit on any server Stop Words Stemming What (compact) summary should be stored? –Per URL Title, snippet –Per Word URL, word number

93
Robot (2) Some specific issues: 1.What initial URLs to use? Choice depends on type of search engines to be built. For general-purpose search engines, use URLs that are likely to reach a large portion of the Web such as the Yahoo home page. For local search engines covering one or several organizations, use URLs of the home pages of these organizations. In addition, use appropriate domain constraint.

94
Robot (3) Examples: To create a search engine for Binghamton University, use initial URL www.binghamton.edu and domain constraint “binghamton.edu”.www.binghamton.edu Only URLs having “binghamton.edu” will be used. To create a search engine for Watson School, use initial URL “watson.binghamton.edu” and domain constraints “watson.binghamton.edu”, “cs.binghamton.edu”, “ee.binghamton.edu”, “me.binghamton.edu” and “ssie.binghamton.edu”.

95
Robot (4) 2.How to extract URLs from a web page? Need to identify all possible tags and attributes that hold URLs. Anchor tag: … Option tag: … Map: Frame: Link to an image: Relative path vs. absolute path:

96
Robot (5) 3. How fast should we download web pages from the same server? Downloading web pages from a web server will consume local resources. Be considerate to used web servers (e.g.: one page per minute from the same server). 4.Other issues Handling bad links and down links Handling duplicate pages [Page Signatures..] Robot exclusion protocol
. 4.Other issues Handling bad links and down links Handling duplicate pages [Page Signatures..] Robot exclusion protocol.")
97
Robot (6) Robot Exclusion Standard: Use file /robots.txt to tell what can be accessed. Examples: User-agent: webcrawler Disallow: # no restriction for webcrawler User-agent: lycra Disallow: / # no access for robot lycra User-agent: * Disallow: /tmp # all other robots can index Disallow: /logs # docs not under /tmp, /logs Voluntary adherence No enforcement….

98
Robot (7) Several research issues about robots: Fetching more important pages first with limited resources. –Can use measures of page importance Fetching web pages in a specified subject area such as movies and sports for creating domain-specific search engines. –Focused crawling Efficient re-fetch of web pages to keep web page index up-to-date. –Keeping track of change rate of a page

99
Robot (8) Efficient Crawling through URL Ordering [Cho 98] Default ordering is based on breadth-first search. Efficient crawling fetches important pages first. Importance Definition Similarity of a page to a driving query Backlink count of a page Forward link of a page PageRank of a page Domain of a page (.edu is better than.com) Combination of the above. – w 1 *Apples+w 2 *Oranges+…..
![Robot (8) Efficient Crawling through URL Ordering [Cho 98] Default ordering is based on breadth-first search.](http://images.slideplayer.com/16/4997275/slides/slide_99.jpg "Efficient crawling fetches important pages first. Importance Definition Similarity of a page to a driving query Backlink count of a page Forward link of a page PageRank of a page Domain of a page (.edu is better than.com) Combination of the above. – w 1 *Apples+w 2 *Oranges+…...")
100
Robot (9) A method for fetching pages related to a driving query first [Cho 98]. Suppose the query is “computer”. A page is related (hot) if “computer” appears in the title or appears 10 times in the body of the page. Some heuristics for finding a hot page: –The anchor of its URL contains “computer”. –Its URL contains “computer”. –Its URL is within 3 links from a hot page. Call the above URL as a hot URL.
![Robot (9) A method for fetching pages related to a driving query first [Cho 98].](http://images.slideplayer.com/16/4997275/slides/slide_100.jpg "Suppose the query is computer . A page is related (hot) if computer appears in the title or appears 10 times in the body of the page. Some heuristics for finding a hot page: –The anchor of its URL contains computer . –Its URL contains computer . –Its URL is within 3 links from a hot page. Call the above URL as a hot URL..")
101
Robot (10) Crawling Algorithm hot_queue = url_queue = empty; /* initialization */ /* hot_queue stores hot URL and url_queue stores other URL */ enqueue(url_queue, starting_url); while (hot_queue or url_queue is not empty) { url = dequeue2(hot_queue, url_queue); /* dequeue hot_queue first if it is not empty */ page = fetch(url); if (page is hot) then hot[url] = true; enqueue(crawled_urls, url); url_list = extract_urls(page); for each u in url_list if (u not in url_queue and u not in hot_queue and u is not in crawled_urls) /* If u is a new URL */ if (u is a hot URL) enqueue(hot_queue, u); else enqueue(url_queue, u); }
![Robot (10) Crawling Algorithm hot_queue = url_queue = empty; /* initialization */ /* hot_queue stores hot URL and url_queue stores other URL */ enqueue(url_queue, starting_url); while (hot_queue or url_queue is not empty) { url = dequeue2(hot_queue, url_queue); /* dequeue hot_queue first if it is not empty */ page = fetch(url); if (page is hot) then hot[url] = true; enqueue(crawled_urls, url); url_list = extract_urls(page); for each u in url_list if (u not in url_queue and u not in hot_queue and u is not in crawled_urls) /* If u is a new URL */ if (u is a hot URL) enqueue(hot_queue, u); else enqueue(url_queue, u); }](http://images.slideplayer.com/16/4997275/slides/slide_101.jpg "Robot (10) Crawling Algorithm hot_queue = url_queue = empty; /* initialization */ /* hot_queue stores hot URL and url_queue stores other URL */ enqueue(url_queue, starting_url); while (hot_queue or url_queue is not empty) { url = dequeue2(hot_queue, url_queue); /* dequeue hot_queue first if it is not empty */ page = fetch(url); if (page is hot) then hot[url] = true; enqueue(crawled_urls, url); url_list = extract_urls(page); for each u in url_list if (u not in url_queue and u not in hot_queue and u is not in crawled_urls) /* If u is a new URL */ if (u is a hot URL) enqueue(hot_queue, u); else enqueue(url_queue, u); }")
102
Robot (11) url_list = extract_urls(page); for each u in url_list if (u not in url_queue and u not in hot_queue and u is not in crawled_urls) /* If u is a new URL */ if (u is a hot URL) enqueue(hot_queue, u); else enqueue(url_queue, u); } Reported experimental results indicate the method is effective.
 url_list = extract_urls(page); for each u in url_list if (u not in url_queue and u not in hot_queue and u is not in crawled_urls) /* If u is a new URL */ if (u is a hot URL) enqueue(hot_queue, u); else enqueue(url_queue, u); } Reported experimental results indicate the method is effective.")
103
Fish Search and ARACHNID Fish search (De Bra 94): Search by intelligently and automatically navigating through real online web pages from a starting point. Some key features: Use heuristics to select the next page to navigate. Client-based search and Favors depth-first search. ARACHNID (Adaptive Retrieval Agents Choosing Heuristic Neighborhoods for Information Discovery, Menczer 97) Key features: Start from multiple promising starting points. Each agent acts like a fish search engine but with more sophisticated navigation techniques.
 Key features: Start from multiple promising starting points. Each agent acts like a fish search engine but with more sophisticated navigation techniques..")
104
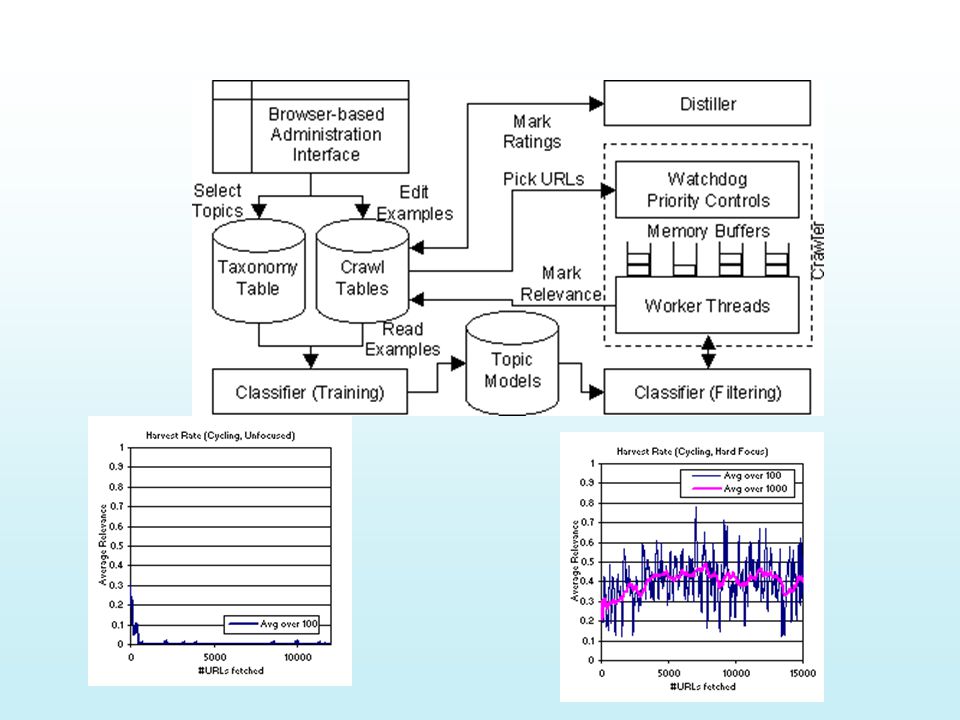
Focused Crawling Classifier: Is crawled page P relevant to the topic? –Algorithm that maps page to relevant/irrelevant Semi-automatic Based on page vicinity.. Distiller:is crawled page P likely to lead to relevant pages? –Algorithm that maps page to likely/unlikely Could be just A/H computation, and taking HUBS Distiller determines the priority of following links off of P

105
Measuring Crawler efficiency

107
Feedback & Prediction Traditional IR has a single user—probably working in single-shot modes –Relevance feedback… WEB search engines have: –Many users Propagate user preferences to other users… –Working continually Relevance feedback User profiling

108
Feedback opportunities When a user submits a query to a search engine, the user may have some of the following behaviors or reactions to the returned web pages: Click certain pages in certain order while ignore most pages. Read some clicked pages longer than some other clicked pages. Save/print certain clicked pages. Follow some links in clicked pages to reach more pages.

109
Feedback patterns The behavior of a user u to the result of a query q can be considered as a piece of knowledge associated with the user query pair (u, q). The same user may use the search engine many times with many queries. Each time, the user reacts to the retrieved results. Many users may submit different queries to the search engine. –Many users may have common information needs. –The same query or similar query may be submitted by different users.

110
Prediction opportunities The reactions of users to the retrieval results of many past queries can be collected and stored in a knowledge base. User reaction knowledge can be used in at least three different ways to improve retrieval: 1.Use the knowledge immediately to benefit the current search needs of the user (user feedback). 2.Use the knowledge in the future to benefit the future search needs of the user (user profile). 3.Use the knowledge in the future to benefit the future search needs of all users (collaborative filtering).
. 2.Use the knowledge in the future to benefit the future search needs of the user (user profile). 3.Use the knowledge in the future to benefit the future search needs of all users (collaborative filtering)..")
111
Relevance feedback Implicit User Feedback: 1.Derive likely relevant documents from the returned documents based on the user behavior. –Saved/printed documents can be considered to be relevant. –Documents that are viewed for a longer time can be considered to be more likely to be relevant. 2.Modify the query to a new query q* and submit q* to the search engine for another round of search. Relevance feedback

112
User profiling User Profile: A profile of a user is a collection of information that documents the user’s information needs and/or access patterns. Different types of user profiles exist: Static profile for describing user information needs. Dynamic profile that changes according to user’s recent access behaviors and patterns. Specialized profile (e.g., navigational pattern). Server side profile. Client side profile.
. Server side profile. Client side profile..")
113
User profiling User Profile: (continued) User profile is widely used for text filtering: Find documents that are similar to a user profile. Profile-based filtering is also known as content-based recommendation. User profile can be used in combination with query for better information retrieval and filtering.

114
Collaborative Filtering Collaborative Filtering: From (Miller 96): Collaborative filtering systems make use of the reactions and opinions of people who have already seen a piece of information to make predictions about the value of that piece of information for people who have not yet seen it. Collaborative filtering systems often recommend documents to a user (a query) that are liked (found useful) by similar users (e.g., users who have similar profiles) (for similar queries).
 that are liked (found useful) by similar users (e.g., users who have similar profiles) (for similar queries)..")
115
Collaborative Filtering (8) Main components: Recommendation gathering: e.g., record user behaviors to retrieved documents. Recommendation aggregation: Combine multiple recommendations into a useful measure. Recommendation usage: Apply recommendation measures to recommend documents. Some interesting issues: What recommendations are useful? How to do recommendation aggregation? How to combine recommendation with other usefulness measures?

116
Collaborative Filtering (9) Example Systems: PHOAKS (People Helping One Another Know Stuff) For recommending URLs. Use each mention of a URL in a news article as a recommendation. –Not counting URLs in headers and quoted sections. –Not using articles posted to too many newsgroups. –Not counting URLs in announcements or ads. Recommendation aggregation: compute the number of distinct recommenders of each URL. Recommendation based on the number of distinct recommenders.

117
Collaborative Filtering (10) Example Systems: Fab (http://fab.stanford.edu) Combines content-based recommendation and collaborative recommendation. –Retain the advantages of each approach while avoid the weaknesses of each approach. Users are required to rank each recommended document explicitly based on a 7-point scale. The ranking is used to update a user’s profile and highly ranked documents are also recommended to users with similar profiles.

118
Collaborative Filtering (11) Example Systems: DirectHit (http://www.directhit.com) Author-controlled search engines versus editor- controlled directories. DirectHit aims at achieving the breadth of a regular search engine with the accuracy of editor-controlled directories by adopting a user- controlled method. DirectHit uses user viewing time of documents and other behavior information to identify useful hits to documents and uses collaborative filtering to help find documents for new queries.

119
Indexing and Retrieval Issues

120
Harvest rate UnfocusedFocused

121
Relevance All Bus&EconRecreation CompaniesCycling Bike Shops Mt.Biking Clubs Arts... Path nodes Good nodes Subsumed nodes

Similar presentations




 Presentor: Lei Tang.>")






 (c) Wolfgang Hürst, Albert-Ludwigs-University.>")









>")

