Download presentation
Presentation is loading. Please wait.

1
Circular analysis in systems neuroscience – with particular attention to cross-subject correlation mapping Nikolaus Kriegeskorte Laboratory of Brain and Cognition, National Institute of Mental Health

2
Chris I Baker W Kyle Simmons Patrick SF Bellgowan Peter Bandettini Collaborators

3
Part 1 General introduction to circular analysis in systems neuroscience (synopsis of Kriegeskorte et al. 2009) Part 2 Specific issue: selection bias in cross-subject correlation mapping (following up on Vul et al. 2009) Overview
 Part 2 Specific issue: selection bias in cross-subject correlation mapping (following up on Vul et al. 2009) Overview.")
5
dataresults

6
analysis dataresults

7
dataresults analysis

8
dataresults analysis assumptions

9
dataresults analysis assumptions

10
Circular inference dataresults analysis assumptions

11
Circular inference dataresults analysis assumptions

12
How do assumptions tinge results? Elimination (binary selection) Weighting (continuous selection) Sorting (multiclass selection) – Through variants of selection!
 Weighting (continuous selection) Sorting (multiclass selection) – Through variants of selection!.")
13
dataresults analysis assumptions: selection criteria Elimination (binary selection)
")
14
Example 1 Pattern-information analysis

15
Experimental design “Animate?”“Pleasant?” STIMULUS (object category) TASK (property judgment) Simmons et al. 2006

16
define ROI by selecting ventral-temporal voxels for which any pairwise condition contrast is significant at p<.001 (uncorr.) perform nearest-neighbor classification based on activity-pattern correlation use odd runs for training and even runs for testing Pattern-information analysis
 perform nearest-neighbor classification based on activity-pattern correlation use odd runs for training and even runs for testing Pattern-information analysis")
17
0 0.5 1 decoding accuracy task (judged property) stimulus (object category) Results chance level
 stimulus (object category) Results chance level")
18
fMRI data using all data to select ROI voxels using only training data to select ROI voxels data from Gaussian random generator 0 0.5 1 0 1 0 1 0 1 decoding accuracy chance level task stimulus...but we used cleanly independent training and test data! ? !

19
Conclusion for pattern-information analysis The test data must not be used in either... training a classifier or defining the ROI continuous weighting binary weighting

20
Data selection is key to many conventional analyses. Can it entail similar biases in other contexts?

21
Example 2 Regional activation analysis

22
ROI definition is affected by noise true region overfitted ROI ROI-average activation overestimated effect independent ROI

23
Data sorting dataresults analysis assumptions: sorting criteria

24
Set-average tuning curves stimulus parameter (e.g. orientation) response...for data sorted by tuning noise data
 response...for data sorted by tuning noise data.")
25
ROI-average fMRI response ABCD condition Set-average activation profiles...for data sorted by activation noise data

26
To avoid selection bias, we can......perform a nonselective analysis OR...make sure that selection and results statistics are independent under the null hypothesis, because they are either: inherently independent or computed on independent data e.g. independent contrasts e.g. whole-brain mapping (no ROI analysis)
.")
27
Does selection by an orthogonal contrast vector ensure unbiased analysis? ROI-definition contrast: A+B ROI-average analysis contrast: A-B c selection =[1 1] T c test =[1 -1] T orthogonal contrast vectors

28
Does selection by an orthogonal contrast vector ensure unbiased analysis? not sufficient contrast vector The design and noise dependencies matter.designnoise dependencies – No, there can still be bias. still not sufficient

29
Circular analysis Pros highly sensitive widely accepted (examples in all high-impact journals) doesn't require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons
 doesn t require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons")
30
Circular analysis Pros highly sensitive widely accepted (examples in all high-impact journals) doesn't require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons
 doesn t require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons")
31
Circular analysis Pros highly sensitive widely accepted (examples in all high-impact journals) doesn't require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons [can’t think of any right now] Pros the error that beautifies results confirms even incorrect hypotheses improves chances of high-impact publication
![Circular analysis Pros highly sensitive widely accepted (examples in all high-impact journals) doesn t require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons [can’t think of any right now] Pros the error that beautifies results confirms even incorrect hypotheses improves chances of high-impact publication](http://images.slideplayer.com/16/4964162/slides/slide_31.jpg "Circular analysis Pros highly sensitive widely accepted (examples in all high-impact journals) doesn t require independent data sets grants scientists independence from the data allows smooth blending of blind faith and empiricism Cons [can’t think of any right now] Pros the error that beautifies results confirms even incorrect hypotheses improves chances of high-impact publication")
32
Part 2 Specific issue: selection bias in cross-subject correlation mapping (following up on Vul et al. 2009)
.")
33
Motivation Vul et al. (2009) posed a puzzle: Why are the cross-subject correlations found in brain mapping so high? Selection bias is one piece of the puzzle. But there are more pieces and we have yet to put them all together.
 posed a puzzle: Why are the cross-subject correlations found in brain mapping so high. Selection bias is one piece of the puzzle. But there are more pieces and we have yet to put them all together..")
34
Overview List and discuss six pieces of the puzzle. (They don't all point in the same direction!) Suggest some guidelines for good practice.
 Suggest some guidelines for good practice..")
35
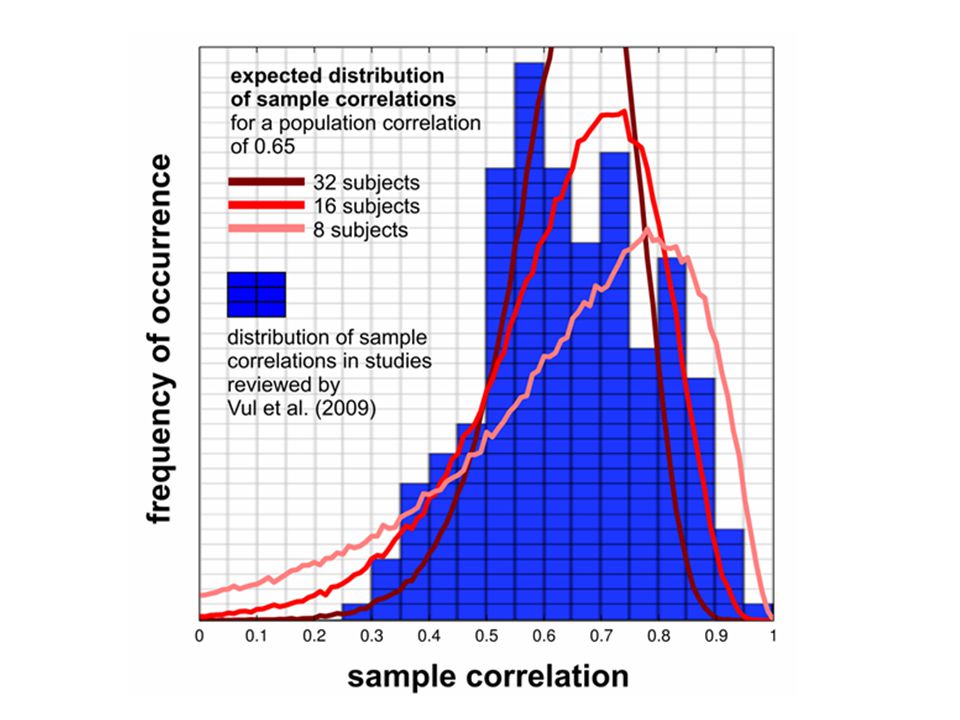
Six pieces synopsis 1.Cross-subject correlation estimates are very noisy. 2.Bin or within-subject averaging legitimately increases correlations. 3.Selecting among noisy estimates yields large biases. 4.False-positive regions are highly likely for a whole- brain mapping thresholded at p<.001, uncorrected. 5.Reported correlations are high, but not highly significant. 6.Studies have low power for finding realistic correlations in the brain if multiple testing is appropriately accounted for.

36
Vul et al. 2009,, population The geometric mean of the reliability is an upper bound on the population correlation. The reliabilities provide no bound on the sample correlation. noise-free correlation

37
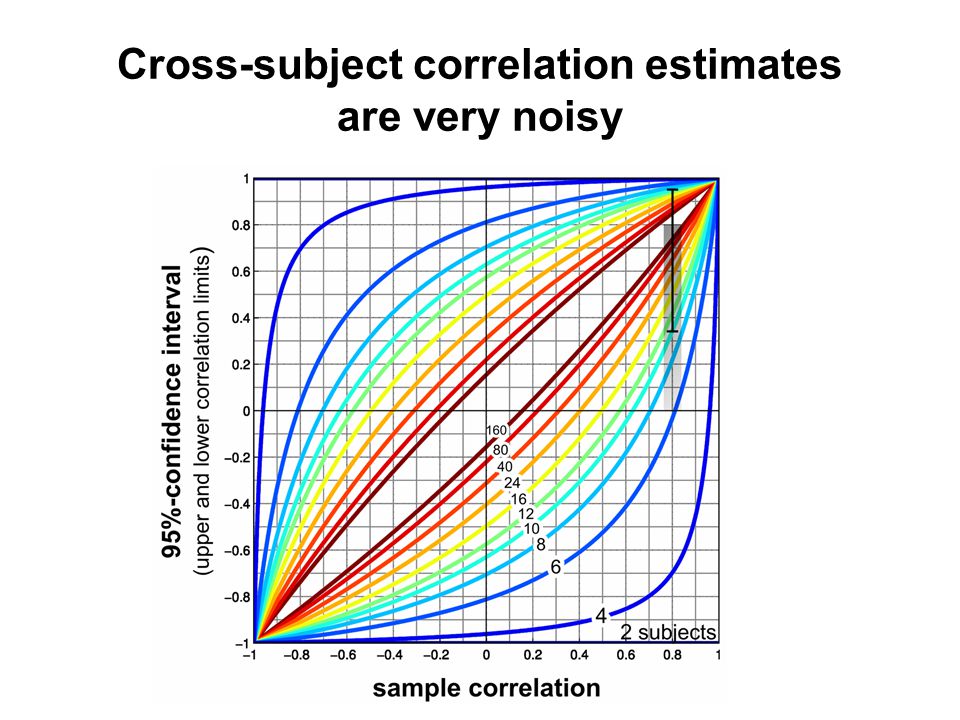
Sample correlations across small numbers of subjects are very noisy estimates of population correlations. Piece 1

38
0.65

40
correlation 10 subjects 95%-confidence interval Cross-subject correlation estimates are very noisy

42
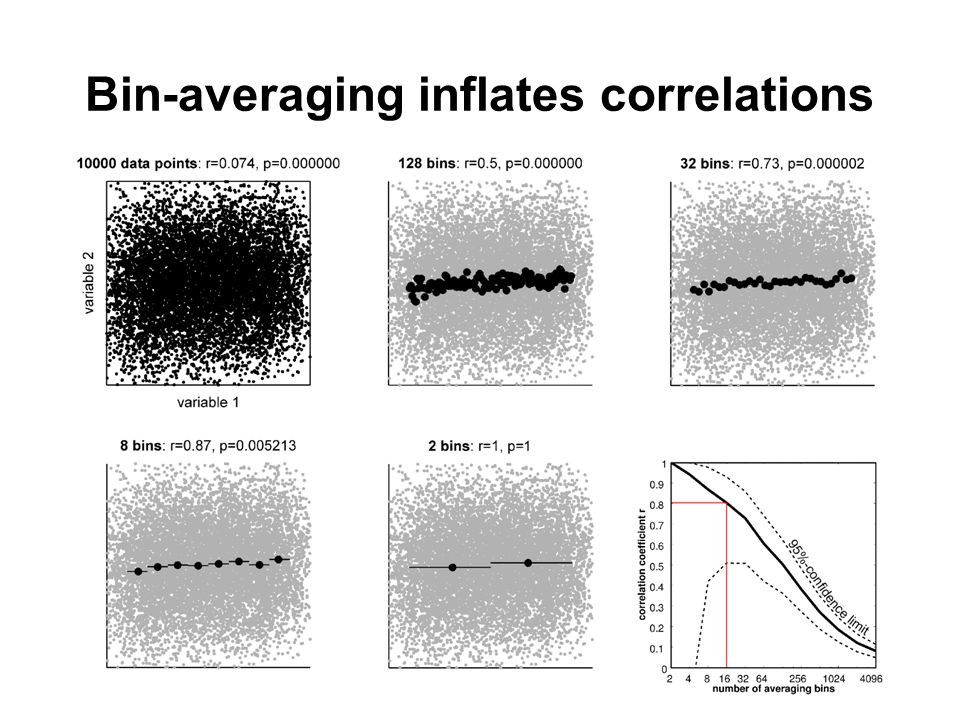
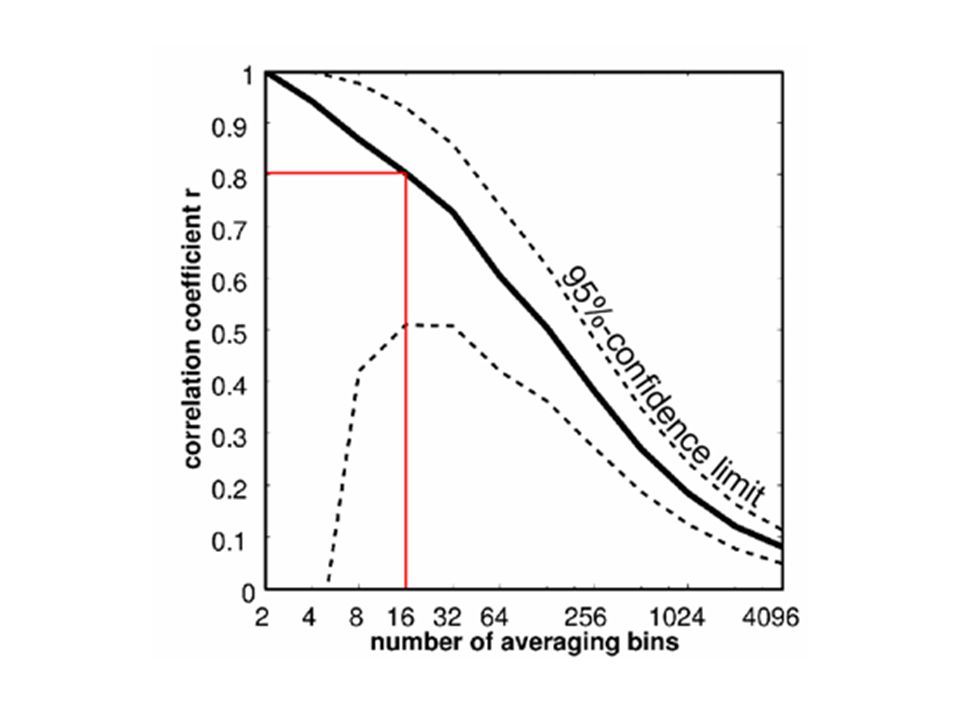
The more we average (reducing noise but not signal), the higher correlations become. Piece 2
, the higher correlations become. Piece 2")
43
Bin-averaging inflates correlations

46
Subjects are like bins... For each subject, all data is averaged to give one number. Take-home message Cross-subject correlation estimates are expected to be... high (averaging all data for each subject) noisy (low number of subjects) So what's Ed fussing about? We don't need selection bias to explain the high correlations, right?
 noisy (low number of subjects) So what s Ed fussing about. We don t need selection bias to explain the high correlations, right .")
47
Selecting the maximum among noisy estimates yields large selection biases. Piece 3

48
Expected maximum correlation selected among null regions expected maximum correlation 16 subjects bias

49
False-positive regions are likely to be found in whole-brain mapping using p<.001, uncorrected. Piece 4

50
Mapping with p<.001, uncorrected Global null hypothesis is true (population correlation = 0 in all brain locations)
")
51
Reported correlations are high, but not highly significant. Piece 5

52
Reported correlations are high, but not highly significant p<0.00001 p<0.001 p<0.01 p<0.05 one-sided two-sided correlation thresholds as a function of the number of subjects

53
Reported correlations are high, but not highly significant p<0.00001 p<0.001 p<0.01 p<0.05 one-sided two-sided correlation thresholds as a function of the number of subjects

54
Reported correlations are high, but not highly significant p<0.00001 p<0.001 p<0.01 p<0.05 one-sided two-sided correlation thresholds as a function of the number of subjects (assuming each study reports the maximum of 500 independent brain locations) What correlations would we expect under the global null hypothesis?
 What correlations would we expect under the global null hypothesis")
55
Reported correlations are high, but not highly significant p<0.00001 p<0.001 p<0.01 p<0.05 one-sided two-sided (assuming each study reports the max. of 500 independent brain locations) What correlations would we expect under the global null hypothesis?
 What correlations would we expect under the global null hypothesis .")
56
Most of the studies have low power for finding realistic correlations with whole-brain mapping if multiple testing is appropriately accounted for. Piece 6 see also: Yarkoni 2009

57
Numbers of subjects in studies reviewed by Vul et al. (2009) number of correlations estimates number of subjects 48163660100
 number of correlations estimates number of subjects")
58
power In order to find a single region with a cross-subject correlation of 0.7 in the brain......we would need about 36 subjects 16 subjects

59
power In order to find a single region with a cross-subject correlation of 0.7 in the brain......we would need about 36 subjects 16 subjects

60
Take-home message Whole-brain cross-subject correlation mapping with 16 subjects doesnotwork. Need at least twice as many subjects.

61
Conclusions Unless much larger numbers of subjects are used, whole-brain cross-subject correlation mapping suffers from either: –very low power to detect true regions (if we carefully to correct for multiple comparisons) –very high rates of false-positive regions (otherwise) If analysis is circular, selection bias is expected to be high here (because selection occurs among noisy estimates)....in other words, it doesn't work.
 –very high rates of false-positive regions (otherwise) If analysis is circular, selection bias is expected to be high here (because selection occurs among noisy estimates)....in other words, it doesn t work.")
62
Suggestions Design study to have enough power to detect realistic correlations. (Need either anatomical restrictions or large numbers of subjects.) Consider studying trial-to-trial rather than subject-to- subject effects. Correct for multiple testing to avoid false positives. Avoid circularity: Use leave-one-subject out procedure to estimate regional cross-subject correlations. Report correlation estimates with error bars.
 Consider studying trial-to-trial rather than subject-to- subject effects. Correct for multiple testing to avoid false positives. Avoid circularity: Use leave-one-subject out procedure to estimate regional cross-subject correlations. Report correlation estimates with error bars..")
Similar presentations





 brief introduction to multivoxel analysis “stuff” Jo Etzel, Social Brain Lab>")






 Institute for Empirical.>")







