Download presentation
Presentation is loading. Please wait.

1
Graph Analysis with High Performance Computing by Bruce Hendrickson and Jonathan W. Berry Sandria National Laboratories Published in the March/April 2008 issue of Computing in Science and Engineering 2/9/11 Presented by Darlene Barker

2
Overview Explored the use of high-performance computing to study large, complex graphing algorithms Presented the challenges running graphing algorithms using explicit message passing using a MPI in distributed-memory computers Proposed solution—developing graph algorithms on a nontraditional, multithreaded supercomputers

3
Distributed-memory computers Most popular class of parallel machines which uses programming with explicit message passing (MPI) –The user divides the data among processors and determines which processor performs which task. The processors exchange data via user-controlled messages.

4
Alternatives to using explicit message passing (MPI) to program distributed-memory parallel computers: Partitioned global address-space computing - Unified Parallel C (UPC) Shared-Memory computing: Cache-coherent parallel computers Massively multithreaded architectures Software—OpenMP – restricted to shared-memory machines but has some portability
 to program distributed-memory parallel computers: Partitioned global address-space computing - Unified Parallel C (UPC) Shared-Memory computing: Cache-coherent parallel computers Massively multithreaded architectures Software—OpenMP – restricted to shared-memory machines but has some portability")
5
UPC The number of control threads is constant in a UPC and is generally equal to the number of processors or cores.

6
Cache-coherent parallel computers -Global memory is universally accessible to each computer and presents some challenges, such as latency: -while using faster hardware to access memory but still with limitations in that it adds overhead degrading performance. -Requires a protocol for thread synchronization and scheduling

7
Massively multithreaded architecture Examples: Cray MTA-2, XMT Addresses latency challenge seen with ensuring that the processor has other work to do while waiting for a memory request to be satisfied. When a memory request is issued, the processor immediately switches its attention to another thread that’s ready to execute.

8
Drawbacks Custom vs. commodity processors which are expensive and have a much slower clock rate than mainstream processors. MTA-2’s programming model although simple and elegant it is not portable to other architectures.

9
To fix the cross-architectural problem with the MTA-2 programming model Use generic programming libraries that hide machine E.g. Generic programming underlies: »C++ Standard Template Library »Boost C++ Libraries »Boost Graph Library (BGL) Use the massively multithreaded architecture with an extended subset of the Boost Graph Library
 Use the massively multithreaded architecture with an extended subset of the Boost Graph Library.")
10
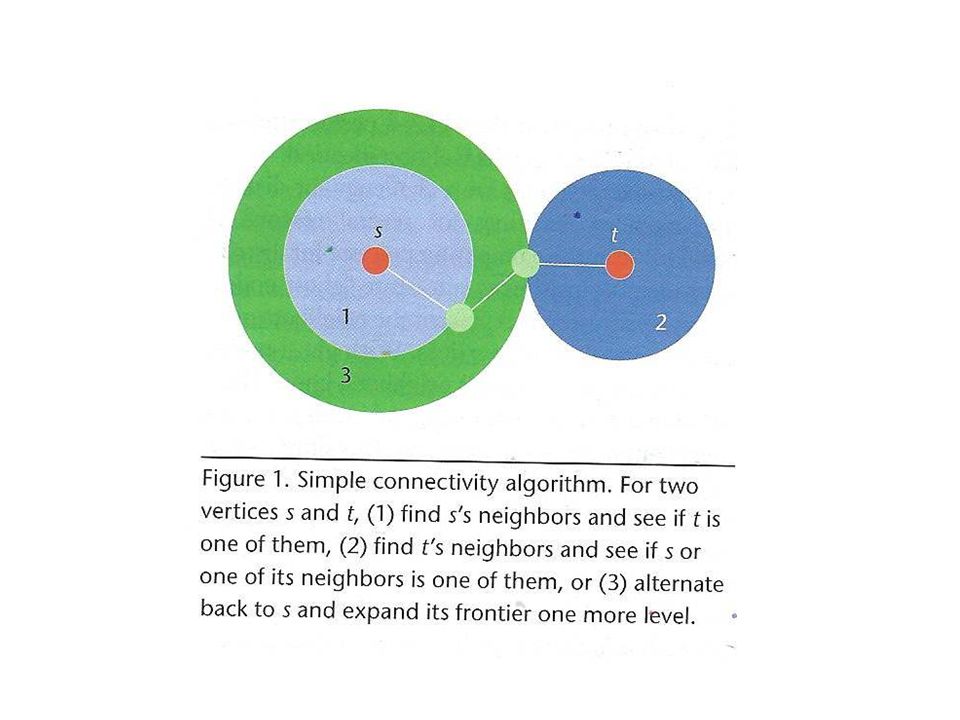
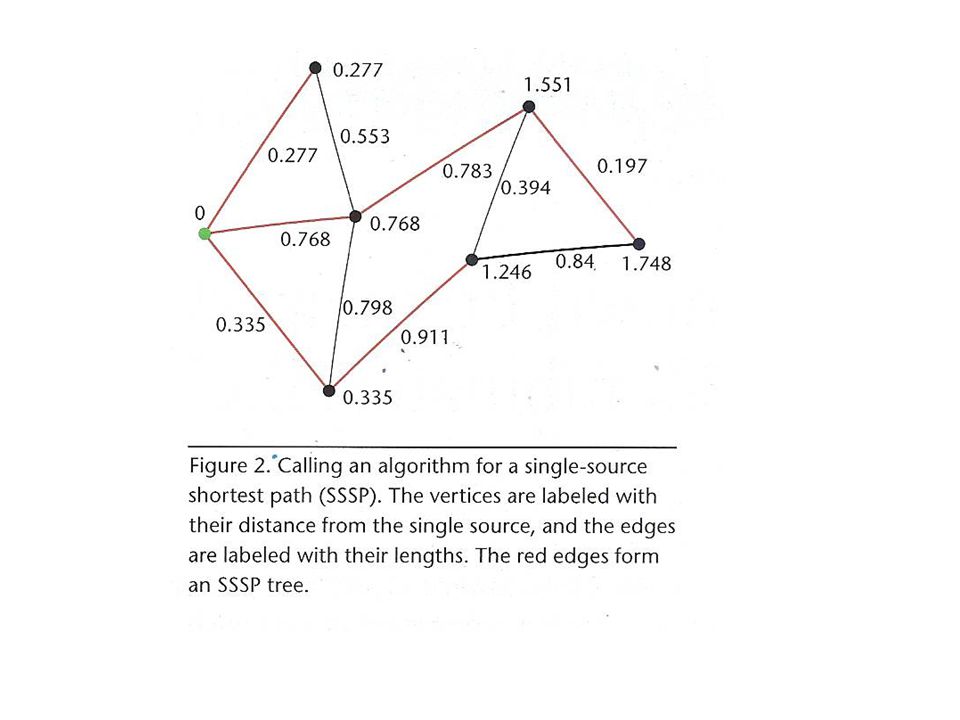
Studied two fundamental graph algorithms on different platforms s-t connectivity To find a path from vertex s to vertex t that traverses the fewest possible edges. Single-Source Shortest Paths (SSSPs) Find the shortest-length path from a specific vertex to all other vertices in the graph.
 Find the shortest-length path from a specific vertex to all other vertices in the graph..")
11
Focused on two different classes of graphs Erdos-Renyi random graphs – constructed by assigning a uniform edge probability to each possible edge and then using a random number generator to determine which edges exists. Inverse power law graphs (RMAT) – constructed by recursively adding adjacencies to a matrix in an intentionally uneven way.
 – constructed by recursively adding adjacencies to a matrix in an intentionally uneven way..")
12
Example of a Erdos-Renyi random graph – not relating to the paper http://upload.wikimedia.org/wikipedia/commons/1/13/Erdos_generated_network-p0.01.jpg

13
Results Only the MTA-2 has a programming model and architecture sufficiently robust to easily test instances of inverse power law graphs with close to a billion edges.

14
Challenges for distributed-memory machines High degree nodes using standard scientific computing practice—storing ghost nodes. High-degree vertices requiring very large message buffers. Ghost nodes limit memory scalability and help runtime scalability.

16
R-t connectivity Type of graphNo. of nodesResults on # of processors Note Erdos-Renyi3.2 billion32768Using world’s largest machine, BlueGene/L. Erdos-RenyiFixed sizeSpeedup of roughly 36 on 450 processors Erdos-Renyi32768# of vertices visited should be roughly 177 times larger for a graph of 32768 nodes than for a graph on a single node.

18
Conclusion - 1 Unlike most scientific computing kernels, graph algorithms exhibit complex memory access patterns and limited amounts of actual processing. Performance is determined by the computer’s ability to access memory, not by actual processor speed. They believe a broad trend exists in the scientific computing community towards increasingly complex and memory limited simulations.

19
Conclusion - 2 With current microprocessor sizes going from silicon to spare, the author’s believe that this space should be used to support massive multithreading, resulting in processors and parallel machines that can apply to a broader range than current offerings.

Similar presentations