Download presentation
Presentation is loading. Please wait.

1
Characterizing and Recognizing Spoken Corrections in Human-Computer Dialog Gina-Anne Levow August 25, 1998

2
Error Correction Spiral U: Give me the price for AT&T. S: Hewlett-Packard was 83 ¾, up 2 ½ since yesterday. U: Give me the price for AT&T. S: Data General was at 10 ½ up a quarter. U: Give me the price for AT&T. S: Hewlett-Packard was 83 ¾, up 2 ½. U: Give me the price for American Telephone and Telegraph. S: Excuse me?

3
Identifying Corrections Most "Reasoning" Approaches Correction => Violates Task, Belief Constraint Requires Tight Task, Belief Model Often Requires Accurate Recognition This Approach Uses Acoustic or Lexical Information Content, Context Independent

4
Accomplishments Corrections vs Original Inputs Significant Differences: Duration, Pause, Pitch Corrections vs Recognizer Models Contrasts: Phonology and Duration Correction Recognition Decision Tree Classifier: 65-77% accuracy Human Baseline ~80%

5
Why Corrections? Recognizer Error Rates ~25% REAL meaning of utterance user intent Corrections misrecognized 2.5X as often Hard to Correct => Poor Quality System

6
Why it's Necessary Error Repair Requires Detection Errors can be very difficult to detect E.g. Misrecognitions Focus Repair Efforts Corrections Decrease Recognition Accuracy Adaptation Requires Identification

7
Why is it Hard? Recognition Failures and Errors Repetition <> Correction 500 Strings => 6700 Instances (80%) Speech Recognition Technology Variation - Undesirable, Suppressed
 Speech Recognition Technology Variation - Undesirable, Suppressed.")
9
Corrections Within

11
Roadmap Data Collection and Description SpeechActs System & Field Trial Characterizing Corrections Original-Repeat Pair Data Analysis Acoustic and Phonological Measures & Results Recognizing Corrections Conclusions and Future Work

12
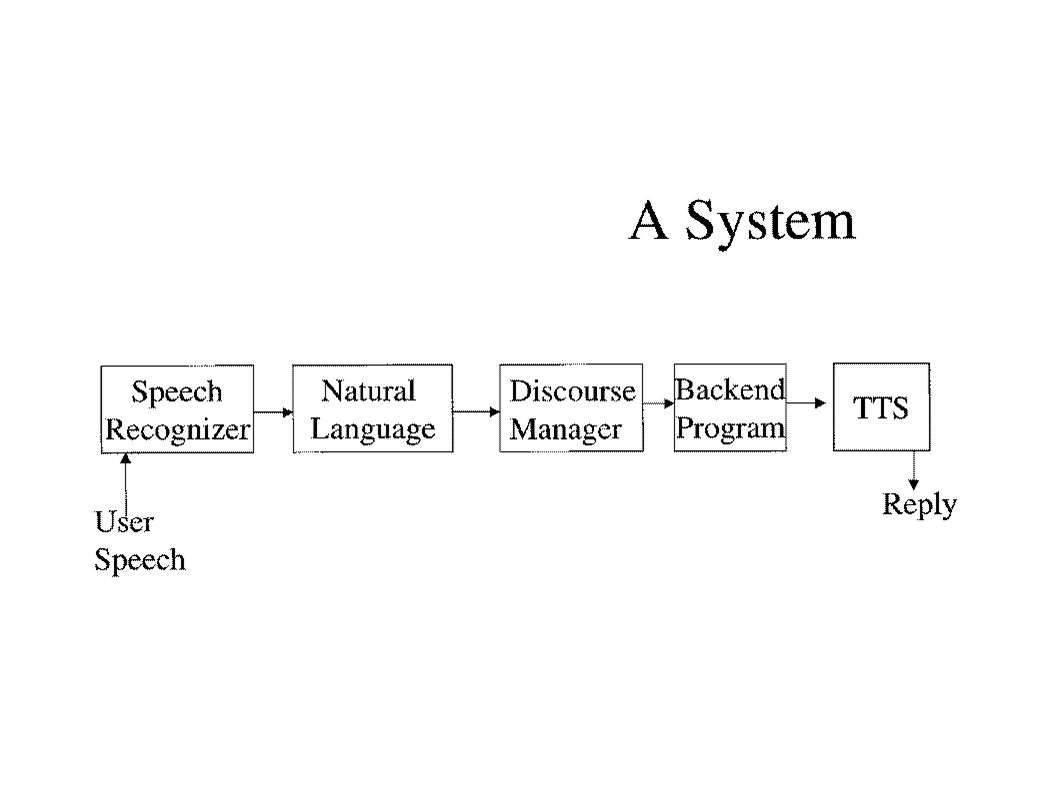
SpeechActs System Speech-Only System over the Telephone Access to Common Desktop Applications Email, Calendar, Weather, Stock Quotes BBN's Hark Speech Recognition, Centigram TruVoice Speech Synthesis In-house: Natural Language Analysis Back-end Applications, Dialog Manager

13
Example Interaction SpeechActs: You have 14 new messages and 47 old messages. The first new message is from Eric Baatz regarding "report completed". User: Let me hear it. SpeechActs: "The first draft is ready for your comments." User: Reply and Include the current message. SpeechActs: Preparing message to Eric Baatz. Begin recording after the tone. When finished, pause for several seconds. User: Eric, I'll get those to you this afternoon. SpeechActs: Say cancel, send or review.

14
Example Interaction: Con't User: Send. SpeechActs: Message Sent. What now? User: Next message. SpeechActs: New Message two from Stuart Adams, subject "Can we meet at 3:00 today?" User: Switch to Calendar.

15
System Data Overview Approximately 60 hours of interactions Digitized at 8kHz, 8-bit mu-law encoding 18 subjects: 14 novices, 4 experts, single shots 7529 user utterances, 1961 errors ~25% error P(error | correct) = 18%; P(error | error) = 44%
 = 18%; P(error | error) = 44%")
16
System: Recognition Error Types Rejection Errors - Below Recognition Level U: Switch to Weather S (Heard): S (said): Huh? Misrecognition Errors - Substitution in Text U: Switch to Weather S (Heard): Switch to Calendar S (Said): On Tuesday August 25, you have defense 1250 Rejections ~2/3 706 Misrecognitions ~1/3
: Switch to Calendar S (Said): On Tuesday August 25, you have defense 1250 Rejections ~2/3 706 Misrecognitions ~1/3.")
17
Roadmap Data Collection and Description SpeechActs System & Field Trial Characterizing Corrections Original-Repeat Pair Data Analysis Acoustic and Phonological Measures & Results Divergence from Recognizer Models Recognizing Corrections Conclusions and Future Work

18
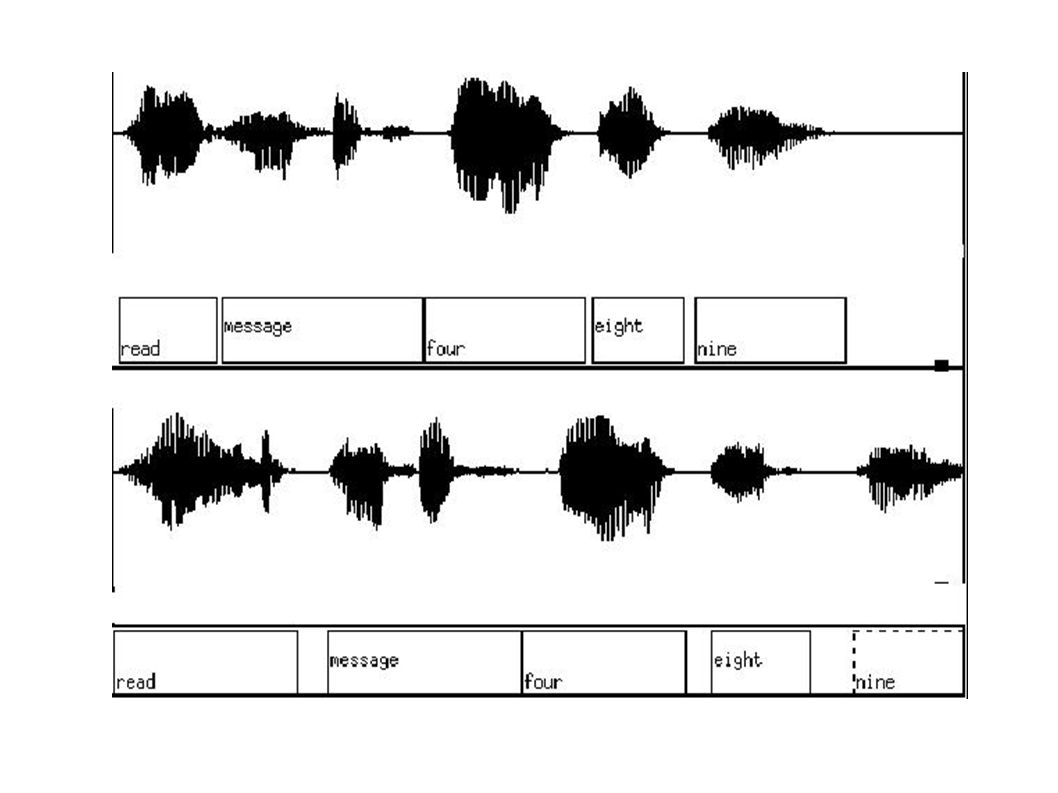
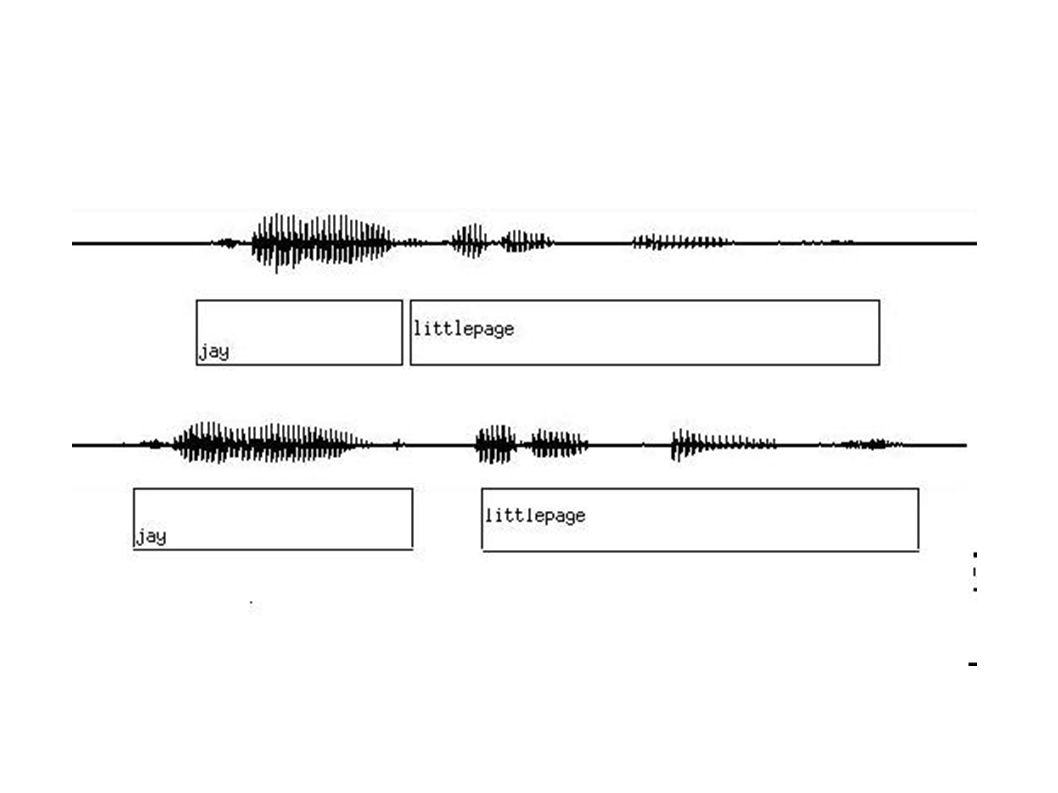
Analysis: Data 300 Original Input-Repeat Correction Pairs Lexically Matched, Same Speaker Example: S: (Said): Please say mail, calendar, weather. U: Switch to Weather. Original S (Said): Huh? U: Switch to Weather. Repeat.
: Huh. U: Switch to Weather. Repeat..")
19
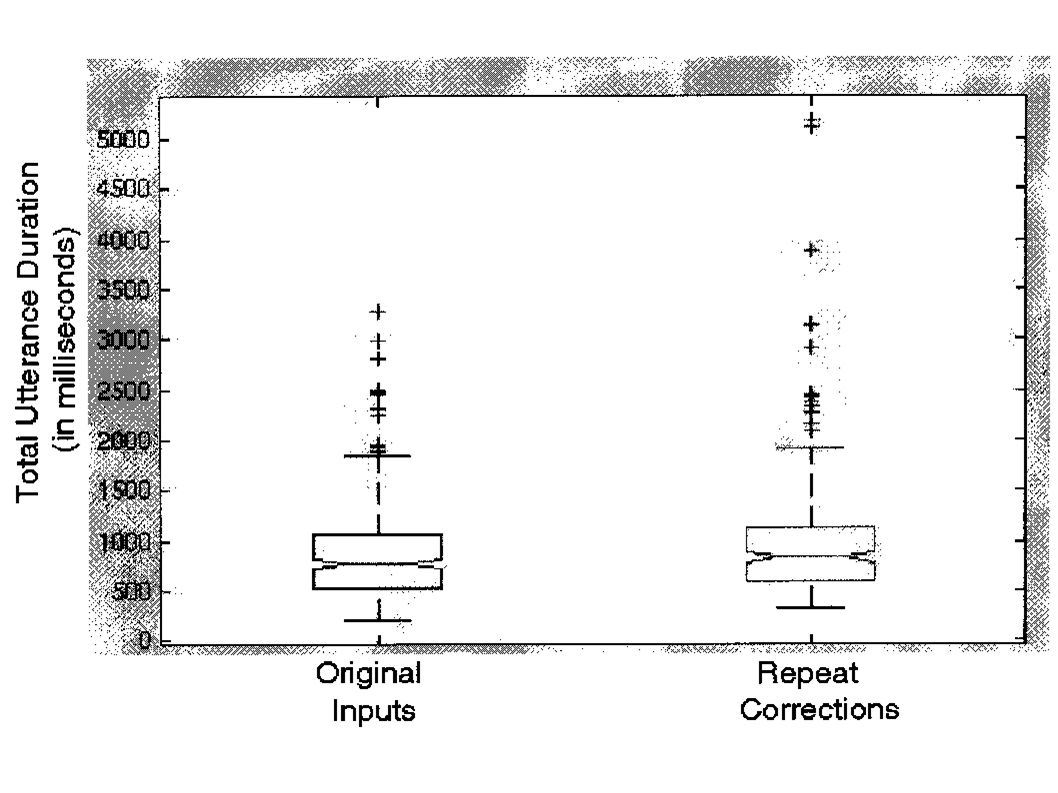
Analysis: Duration Automatic Forced Alignment, Hand-Edited Total: Speech Onset to End of Utterance Speech: Total - Internal Silence Contrasts: Original Input/Repeat Correction Total: Increases 12.5% on average Speech: Increases 9% on average

21
Analysis: Pause Utterance Internal Silence > 10ms Not Preceding Unvoiced Stops(t), Affricates(ch) Contrasts: Original Input/Repeat Correction Absolute: 46% Increase Ratio of Silence to Total Duration: 58% Increase
, Affricates(ch) Contrasts: Original Input/Repeat Correction Absolute: 46% Increase Ratio of Silence to Total Duration: 58% Increase")
23
Pitch Tracks

24
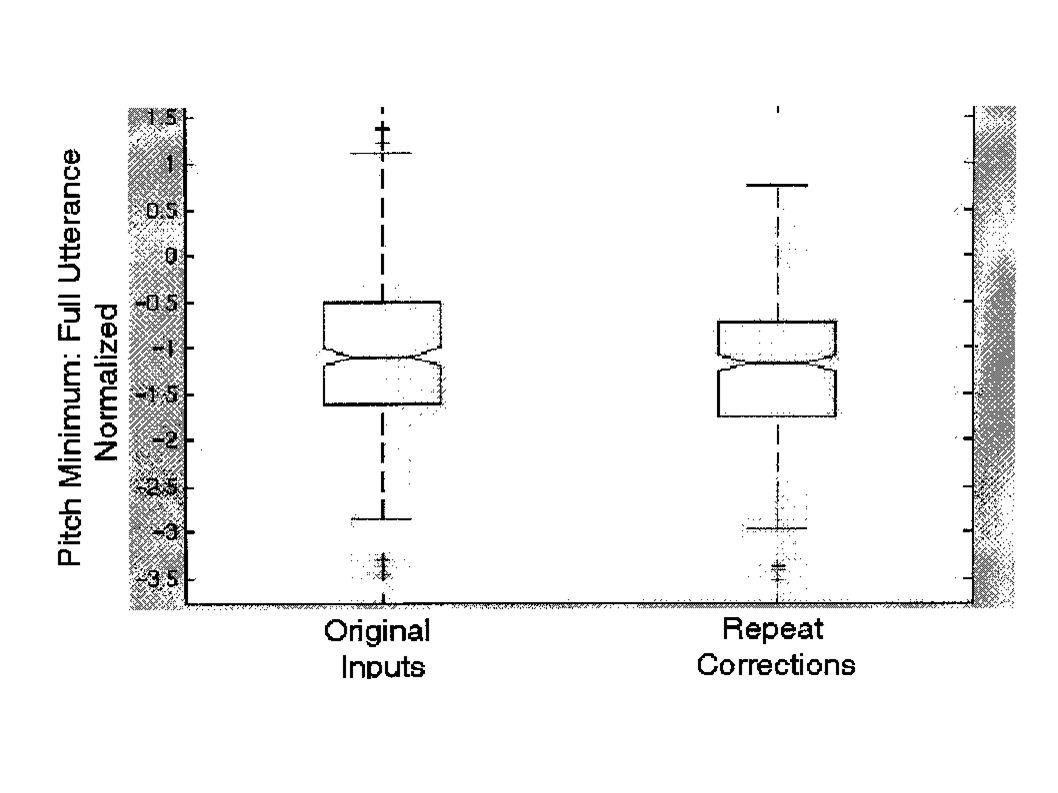
Analysis: Pitch I ESPS/Waves+ Pitch Tracker, Hand-Edited Normalized Per-Subject: (Value-Subject Mean) / (Subject Std Dev) Pitch Maximum, Minimum, Range Whole Utterance & Last Word Contrasts: Original Input/Repeat Correction Significant Decrease in Pitch Minimum Whole Utterance & Last Word
 / (Subject Std Dev) Pitch Maximum, Minimum, Range Whole Utterance & Last Word Contrasts: Original Input/Repeat Correction Significant Decrease in Pitch Minimum Whole Utterance & Last Word")
25
Analysis: Pitch II

26
Analysis: Pitch III Internal Pitch Contours: Pitch Accent Steepest Rise, Steepest Fall, Slope Sum Overall => Not Significant Misrecognitions Only: Original vs Repeat Significant Increases: Steepest Rise, Slope Sum

28
Pitch Contour Detail Exclude Boundary Tone Region 5-Point median smoothing (Taylor 1996) Piecewise linear contour between max and min
 Piecewise linear contour between max and min")
29
Analysis: Overview Significant Differences: Original/Correction Duration & Pause Significant Increases: Original vs Correction Pitch Significant Decrease in Pitch Minimum Increase in Final Falling Contours Misrecognitions: Increase in Pitch Variability Conversational-to-Clear Speech Shift Contrastive Use of Pitch Accent

30
Roadmap Data Collection and Description SpeechActs System & Field Trial Characterizing Corrections Original-Repeat Pair Data Analysis Acoustic and Phonological Measures & Results Divergence from Recognizer Models Recognizing Corrections Conclusions and Future Work

31
Analysis: Phonology Reduced Form => Citation Form Schwa to unreduced vowel (~20) E.g. Switch t' mail => Switch to mail. Unreleased or Flapped 't' => Released 't' (~50) E.g. Read message tweny => Read message twenty Citation Form => Hyperclear Form Vowel or Syllabic Insertion (~20) E.g. Goodbye => Goodba-aye
 E.g. Read message tweny => Read message twenty Citation Form => Hyperclear Form Vowel or Syllabic Insertion (~20) E.g. Goodbye => Goodba-aye.")
34
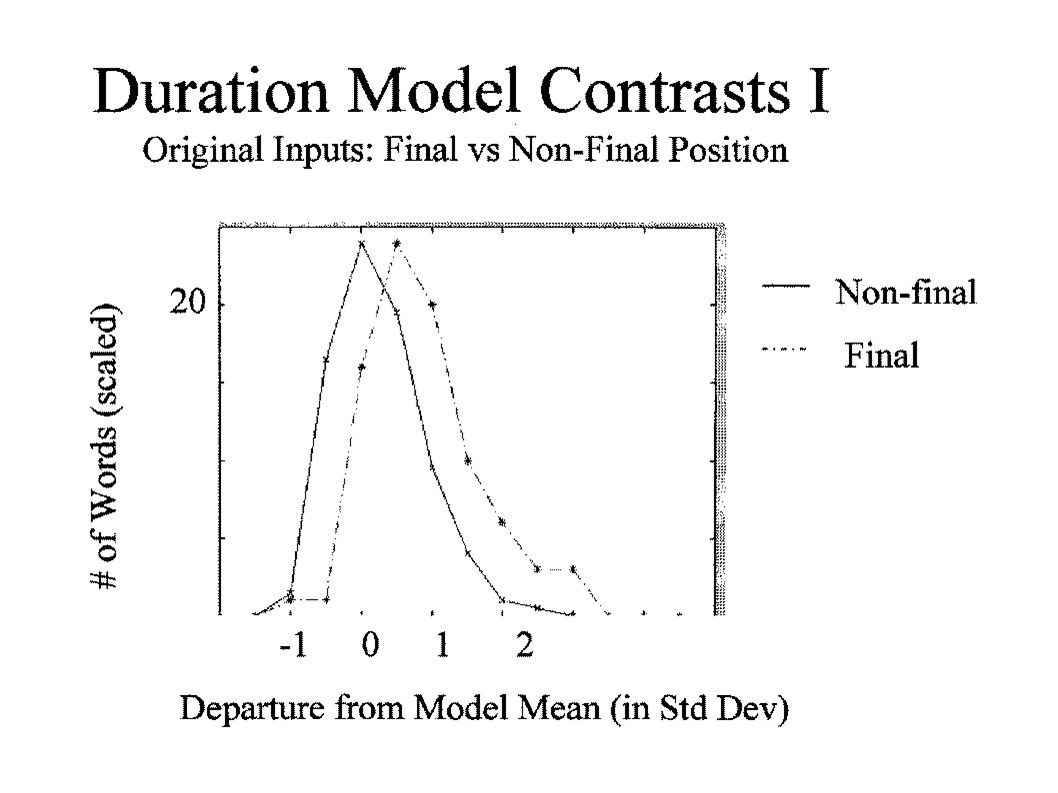
Analysis: Overview II Original vs Correction & Recognizer Model Phonology Reduced Form => Citation Form => Hyperclear Form Conversational to (Hyper) Clear Shift Duration Contrast between Final and Non-final Words Departure from ASR Model Increase for Corrections, especially Final Words
 Clear Shift Duration Contrast between Final and Non-final Words Departure from ASR Model Increase for Corrections, especially Final Words")
35
Roadmap Data Collection and Description SpeechActs System & Field Trial Characterizing Corrections Original-Repeat Pair Data Analysis Acoustic and Phonological Measures & Results Divergence from Recognizer Models Recognizing Corrections Conclusions and Future Work

36
Learning Method Options (K)-Nearest Neighbor Need Commensurable Attribute Values Sensitive to Irrelevant Attributes Labeling Speed - Training Set Size Neural Nets Hard to Interpret Can Require More Computation & Training Data +Fast, Accurate when Trained Decision Trees Intelligible, Robust to Irrelevant Attributes +Fast, Compact when Trained ?Rectangular Decision Boundaries, Don't Test Feature Combinations Alternative: Mixture of Experts
-Nearest Neighbor Need Commensurable Attribute Values Sensitive to Irrelevant Attributes Labeling Speed - Training Set Size Neural Nets Hard to Interpret Can Require More Computation & Training Data +Fast, Accurate when Trained Decision Trees Intelligible, Robust to Irrelevant Attributes +Fast, Compact when Trained Rectangular Decision Boundaries, Don t Test Feature Combinations Alternative: Mixture of Experts")
37
Learning Method Options (K)-Nearest Neighbor Need Commensurable Attribute Values Sensitive to Irrelevant Attributes Labeling Speed - Training Set Size Neural Nets Hard to Interpret Can Require More Computation & Training Data +Fast, Accurate when Trained Decision Trees <= Intelligible, Robust to Irrelevant Attributes +Fast, Compact when Trained ?Rectangular Decision Boundaries, Don't Test Feature Combinations
-Nearest Neighbor Need Commensurable Attribute Values Sensitive to Irrelevant Attributes Labeling Speed - Training Set Size Neural Nets Hard to Interpret Can Require More Computation & Training Data +Fast, Accurate when Trained Decision Trees <= Intelligible, Robust to Irrelevant Attributes +Fast, Compact when Trained Rectangular Decision Boundaries, Don t Test Feature Combinations")
38
Decision Tree Features 38 Features Total, E.g. 15 for best trees Pause Total Pause Duration Pause / Total Duration Duration Total Duration (uttdur) Speaking Rate (sps) Normalized Duration Amplitude Max, Mean, Last Max-Last (ampdiff) Mean-Last (ampdelta) Pitch Max, Min, Range Global, Last Word Range/Total Contour Max, min, sum slope
 Speaking Rate (sps) Normalized Duration Amplitude Max, Mean, Last Max-Last (ampdiff) Mean-Last (ampdelta) Pitch Max, Min, Range Global, Last Word Range/Total Contour Max, min, sum slope.")
39
Decision Tree Training & Testing Data: 50% Original Inputs, 50% Repeat Corrections Classifier Labels: Original, Correction 7-Way Cross-Validation Train on 6/7 of data, Test on remaining 1/7 Subsets drawn at random according to distribution Cycle through all subsets, training & testing Report average results on unseen test data

40
Recognizer: Results (Overall) Tree Size: 57 (unpruned), 37 (pruned) Minimum of 10 nodes per branch required First Split: Normalized Duration (All Trees) Most Important Features: Normalized & Absolute Duration, Speaking Rate 65% Accuracy - Null Baseline-50%
 Tree Size: 57 (unpruned), 37 (pruned) Minimum of 10 nodes per branch required First Split: Normalized Duration (All Trees) Most Important Features: Normalized & Absolute Duration, Speaking Rate 65% Accuracy - Null Baseline-50%")
41
Example Tree

42
Classifier Results: Misrecognitions Most important features: Absolute and Normalized Duration Pitch Minimum and Pitch Slope 77% accuracy (with text) 65% (acoustic features only) Null baseline - 50% Human baseline - 79.4% (Hauptman & Rudnicky 1990)
 65% (acoustic features only) Null baseline - 50% Human baseline % (Hauptman & Rudnicky 1990)")
43
Classifier Results: Misrecognitions Most important features: Absolute and Normalized Duration Pitch Minimum and Pitch Slope 77% accuracy (with text) 65% (acoustic features only) Errors, most trees: ½ false positive, ½ false negative Null baseline - 50% Human baseline - 79.4% (Hauptman & Rudnicky 1990)
 65% (acoustic features only) Errors, most trees: ½ false positive, ½ false negative Null baseline - 50% Human baseline % (Hauptman & Rudnicky 1990)")
44
Misrecognition Classifier

45
Roadmap Data Collection and Description Characterizing Corrections Recognizing Corrections Conclusions and Future Work

46
Accomplishments Contrasts between Originals vs Corrections Significant Differences in Duration, Pause, Pitch Conversational-to-Clear Speech Shifts Shifts away from Recognizer Models Corrections Recognized at 65-77% Near-human Levels

47
The Recipe Original/Correction Training Set (300+ sets) Labeled, Transcribed, Digitized, Corpus or Wizard Acoustic Analyses Pitch Tracking, Silence Detection, Speaking Rate,... Classifier Training & Tuning Confidence Measure (Weighted Pessimistic Error) Phonological Rule Extraction Durational Contrast Modeling Repair Dialog Management
 Phonological Rule Extraction Durational Contrast Modeling Repair Dialog Management.")
48
Future Work Modify ASR Duration Model for Correction Reflect Phonological and Duration Change Identify Locus of Correction for Misrecognitions Preliminary tests: 26/28 Corrected Words Detected, 2 False Alarms

Similar presentations






 Chilin Shih (University of Illinois) Tan Lee (CUHK) with Hongyan.>")




? – Physical Realization.>")











