Download presentation
Presentation is loading. Please wait.

1
Mutual Information Mathematical Biology Seminar 23.5.2005

2
1. Information Theory and, are terms which describe any process that selects one or more objects from a set of objects. Mathematical Biology Seminar

3
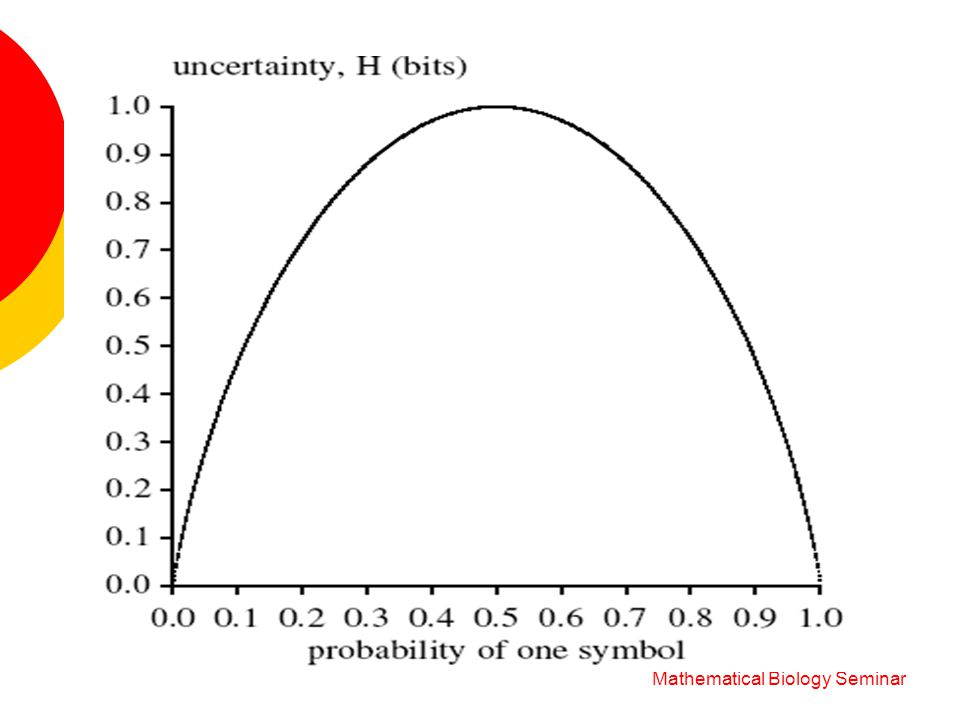
Information Theory Mathematical Biology Seminar Uncertainty = 3 Symbol ABC 12 Uncertainty = 2 Symbol A1A2B1B2C1C2 Uncertainty = 6 Symbol Uncertainty = Log (M) M = The Number of Symbols
 M = The Number of Symbols")
4
Information Theory Very Surprised Not Surprised Mathematical Biology Seminar

5
Entropy (self information) – a discrete random variable - probability distribution measure of the uncertainty information of a discrete random variable. How certain we are of the outcome. Mathematical Biology Seminar

6
Entropy – properties: maximum entropy – a uniform distribution Mathematical Biology Seminar

8
Joint Entropy measure of the uncertainty between X and Y. Mathematical Biology Seminar

9
Conditional Entropy measure the remaining uncertainty when X is known. Mathematical Biology Seminar

10
Mutual Information It is the reduction of uncertainty of one variable due to knowing about the other, or the amount of information one variable contains about the other. Mathematical Biology Seminar MI(X,Y) 0 MI(X,Y) = 0 only when X,Y are independent: H(X|Y) = H(X). MI(X,X) = H(X)-H(X|X) = H(X) Entropy is the self-information. Mutual Information – properties:
 0 MI(X,Y) = 0 only when X,Y are independent: H(X|Y) = H(X). MI(X,X) = H(X)-H(X|X) = H(X) Entropy is the self-information. Mutual Information – properties:.")
11
2. Applications: Clustering algorithms Clustering quality Mathematical Biology Seminar

12
Clustering algorithms Motivation: MI ’ s capability to measure a general dependence among random variables. Use MI as a similarity measure. Minimize the statistical correlation among clusters in contrast to distance-based algorithms which minimize the total variance within different clusters. Mathematical Biology Seminar

13
Clustering algorithms Mathematical Biology Seminar Two methods: 1. Mutual-information – MI, PMI 2. Combined mutual-information and distance-based – MIK, MIF

14
MI – mutual information minimization Grouping property: 1. Compute a proximity matrix based on pairwise mutual informations; assign n clusters such that each cluster contains exactly one object; 2. find the two closest clusters i and j; 3. create a new cluster (ij) by combining i and j; 4. delete the lines/columns with indices i and j from the proximity matrix, and add one line/column containing the proximities between cluster (ij) and all other clusters; 5. if the number of clusters is still > 2, goto (2); else join the two clusters and stop. Mathematical Biology Seminar
 by combining i and j; 4. delete the lines/columns with indices i and j from the proximity matrix, and add one line/column containing the proximities between cluster (ij) and all other clusters; 5. if the number of clusters is still > 2, goto (2); else join the two clusters and stop. Mathematical Biology Seminar.")
15
PMI – threshold based on pairwise mutual information 1. Start with the first gene and grouping genes that has smallest mutual-information-based distance with it. Repeat, until no gene can be added without surpassing the threshold. Then start with the second gene and repeat the same procedure (all genes are available). Repeat for all genes. 2. The largest candidate cluster is selected. 3. Repeat 1 and 2 until the K clusters. Mathematical Biology Seminar
. Repeat for all genes. 2. The largest candidate cluster is selected. 3. Repeat 1 and 2 until the K clusters. Mathematical Biology Seminar.")
16
PMI Threshold – 1. Mean of the distances of all gene pairs 2. Choose empirically Optimal solution – simulated annealing algorithm (optimization). cost function: Mathematical Biology Seminar
. cost function: Mathematical Biology Seminar.")
17
Combined methods Euclidean distance – positive correlation. Mutual information – nonlinear correlation. A small data sample size combined algorithms Mathematical Biology Seminar

18
MIF - combined metric of MI and fuzzy membership distance The objective function: - a weight factor, - normalization constants Mathematical Biology Seminar

20
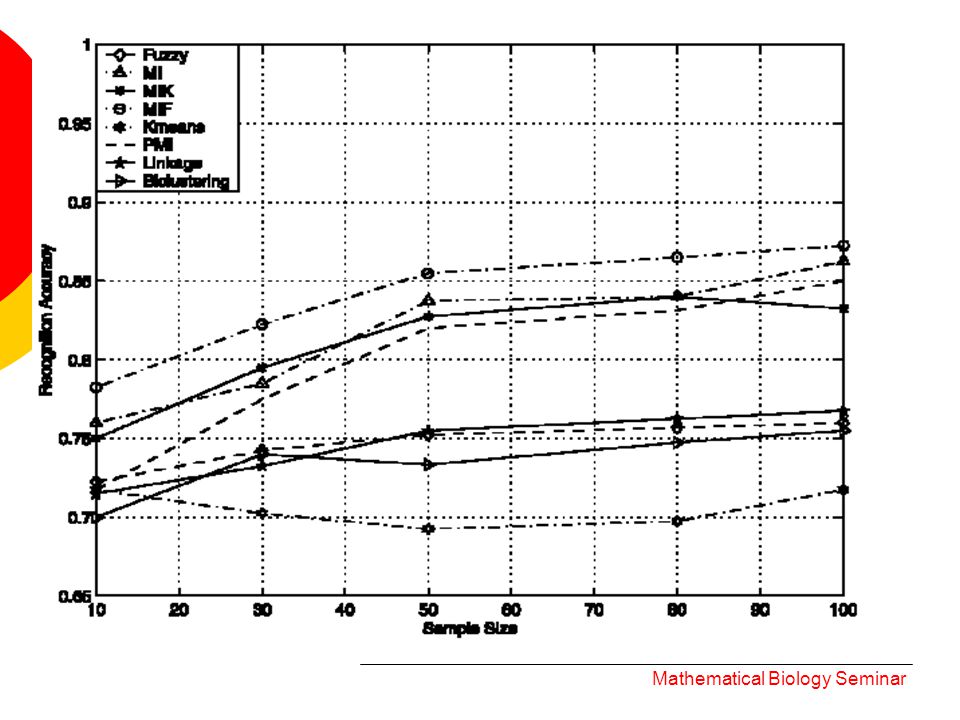
Performance on simulated data 8 clustering algorithms. measure of performance: percentage of points placed into correct clusters. 1. 4 variables: The sample size (M) is changed. Mathematical Biology Seminar
 is changed. Mathematical Biology Seminar.")
22
Performance on simulated data Result (1): 1. MI method outperforms the Fuzzy, K- means, linkage, biclustering, PMI. 2. MIF – best clustering accuracy. 3. MIK has similar performance as the MI. 4. MI based clustering methods – more accurate as the sample size increases. Mathematical Biology Seminar

23
Performance on simulated data 2. different number of genes (N) M=30 The data are generated according to: Results (2): In addition to the previous results … 1. Performances degrade as the number of gene increase. 2. Degree of degradation depends on the distributions governing the data. Mathematical Biology Seminar
 M=30 The data are generated according to: Results (2): In addition to the previous results … 1. Performances degrade as the number of gene increase. 2. Degree of degradation depends on the distributions governing the data. Mathematical Biology Seminar.")
24
Experimental Analysis Clustering genes based on similarity of their expression patterns in a limited set of experiments. Gene with similar expression patterns are more likely to have similar biological function (it is not provide the best possible grouping). Higher entropy for a gene means that its expression data are more randomly distributed. Higher MI between genes, it is more likely that they have a biological relationship. Mathematical Biology Seminar
. Higher entropy for a gene means that its expression data are more randomly distributed. Higher MI between genes, it is more likely that they have a biological relationship. Mathematical Biology Seminar.")
25
Experimental Analysis Mathematical Biology Seminar 579 genes from 26 human glioma surgical tissue samples. 526 genes after filtering out genes with insufficient variability.

26
Glioma Gliomas are tumors that can be found in various parts of the brain. They arise from the support cells of the brain, the glial cells. Mathematical Biology Seminar

27
Fuzzy K-meansMIF binary profiles

28
Experimental Analysis Results (Fuzzy vs. MIF): Two small clusters were broken out from the Fuzzy clusters. While the number of genes changed is small, the error decrease is significant (2.013 decrease to 1.084). Mathematical Biology Seminar
: Two small clusters were broken out from the Fuzzy clusters. While the number of genes changed is small, the error decrease is significant (2.013 decrease to 1.084). Mathematical Biology Seminar.")
29
Experimental Analysis Results: The results are the same for MIK and Fuzzy. Compared with MIF and MIK, MI and PMI gives different results. Mathematical Biology Seminar

30
Applications: Clustering algorithms Clustering quality Mathematical Biology Seminar

31
Clustering quality What choice of number of clusters generally yields the most information about gene function (where function is known)? 9 different algorithms, 2 databases, 4 data sets. a table of 6300 genes * 2000 attributes. a cogency table for each cluster-attribute pairs. Mathematical Biology Seminar

32
Clustering quality Calculate entropies: and the total MI between the cluster result C and all the attributes as: Mathematical Biology Seminar

33
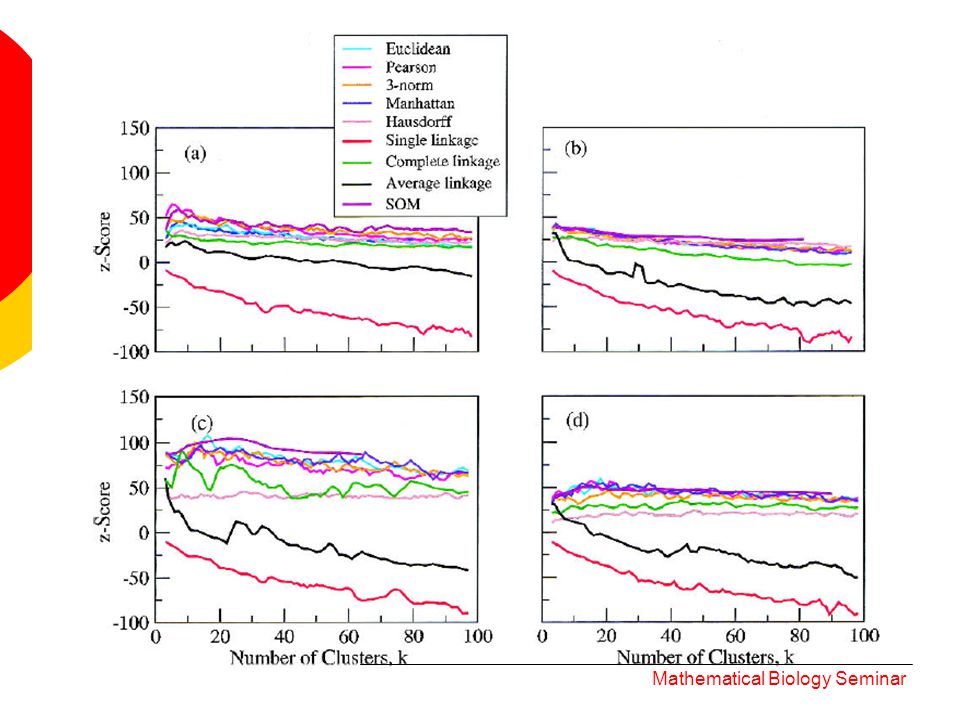
1. How does MI change? given: 3000 genes 30 clusters Perform random swaps – the cluster sizes were held but the degree of correlation within the clusters, slowly destroy. Mathematical Biology Seminar

34
Results: 1. MI decreases 2. MI converges to a non-zero value Mathematical Biology Seminar

35
2. Score the partition 1. Compute MI for the clustered data –. 2. Compute MI for clustering obtained by random swaps, Repeating until a distribution of values is obtained. 3. Compute z-score : Mathematical Biology Seminar

37
large z-score greater distance clustering results more significantly related to gene function. Results: 1. low cluster numbers 2. clustering algorithm which produce nonuniform cluster size distribution, perform better. Mathematical Biology Seminar

38
Conclusion – Advantages(1): Very simple and natural hierarchical clustering algorithm (As MI estimates are becoming better, also the results should improve). Optimal results when the sample size is large. MI is a proximity measure, which also recognizes negatively and nonlinearly correlated data set. So it is more general to use it modeling relationship between genes. MI is not biased by outliers. Euclidian distance is more easily distorted when variables are not uniformly distributed. Mathematical Biology Seminar

39
Conclusion – Advantages(2): Expression levels can be modeled to include measurement noise. Mathematical Biology Seminar

40
Conclusion - Disadvantages: In general, It is not easy to estimate MI (as an example, continuous random variables). The performances degrade substantially as the number of genes increases. Mathematical Biology Seminar

41
Conclusion It is not so accurate to look at each condition as a independent observation. Each point is significant. There are analyses on datasets which do not miss any non-linear correlations. Its more accurate as a validation method. Mathematical Biology Seminar

Similar presentations











 for Clustering Gene Expression Data K. Y. Yeung and W. L. Ruzzo.>")






 Vipin Kumar Army High Performance.>")




