Download presentation
Presentation is loading. Please wait.

1
Exact and Approximation Algorithms for DNA Tag Set Design
Ion Mandoiu Computer Science & Engineering Department and Biomedical Engineering Program University of Connecticut

2
Overview Background on universal tag arrays Tag set design problem
c-h code formulation Integer program and LP-approximation Cycle packing formulation Experimental results Conclusions

3
DNA Structure Four nucleotide types: A,C,G,T Double helix shape
Watson-Crick Complementarity A’s paired with T’s (2 hydrogen bonds) C’s paired with G’s (3 hydrogen bonds)
 C’s paired with G’s (3 hydrogen bonds)")
4
DNA Microarrays Exploit Watson-Crick complementarity to simultaneously perform a large number of substring tests Used in a variety of genomic analyses Transcription (gene expression) analysis Single Nucleotide Polymorphism (SNP) genotyping Genomic-based microorganism identification Common microarray formats involve direct hybridization between labeled DNA/RNA sample and DNA probes attached to a glass slide
 analysis. Single Nucleotide Polymorphism (SNP) genotyping. Genomic-based microorganism identification. Common microarray formats involve direct hybridization between labeled DNA/RNA sample and DNA probes attached to a glass slide.")
5
Direct Hybridization Experiment
Labeled DNA/RNA sample hybridized to array of probes Laser activation of fluorescent labels Optical scanning used to identify probes with complements in the mixture Images courtesy of Affymetrix.

6
Limitations of Common Array Formats
Arrays of cDNAs Probes obtained by reverse transcription from Expressed Sequence Tags (ESTs) Inexpensive, but can only be used for transcription analysis Oligonucleotide arrays Short (20-60bp) synthetic DNA probes Flexible, but expensive unless produced in large quantities
 Inexpensive, but can only be used for transcription analysis. Oligonucleotide arrays. Short (20-60bp) synthetic DNA probes. Flexible, but expensive unless produced in large quantities.")
7
Universal Tag Arrays [Brenner 97, Morris et al. 98] “Programmable” oligonucleotide arrays Array consists of application independent oligonucleotides called tags Two-part “reporter” probes: aplication specific primers ligated to antitags Detection carried by a sequence of reactions separately involving the primer and the antitag part of reporter probes
![Universal Tag Arrays [Brenner 97, Morris et al. 98] Programmable oligonucleotide arrays.](http://slideplayer.com/slide/4805010/15/images/7/Universal+Tag+Arrays+%5BBrenner+97%2C+Morris+et+al.+98%5D+Programmable+oligonucleotide+arrays..jpg "Array consists of application independent oligonucleotides called tags. Two-part reporter probes: aplication specific primers ligated to antitags. Detection carried by a sequence of reactions separately involving the primer and the antitag part of reporter probes.")
8
Universal Tag Array Experiment
Solution phase hybridization + Mix reporter probes with genomic DNA Single-Base Extension Solid phase hybridization

9
Universal Tag Array Advantages
Cost effective Same array used in many analyses economies of scale Easy to customize Only need to synthesize new set of reporter probes Reliable Solution phase hybridization better understood than hybridization on solid support

10
Tag Hybridization Constraints
(H1) Stability: Antitags hybridize strongly to complementary tags (H2) Non-Interaction: No antitag hybridizes to a non-complementary tag (H3) Cross-Hybridization: Antitags do not hybridize to each other Tag Set Design Problem: Find a maximum cardinality set of tags satisfying (H1)-(H3)
 Stability: Antitags hybridize strongly to complementary tags. (H2) Non-Interaction: No antitag hybridizes to a non-complementary tag. (H3) Cross-Hybridization: Antitags do not hybridize to each other. Tag Set Design Problem: Find a maximum cardinality set of tags satisfying (H1)-(H3)")
11
More Hybridization Constraints…
Enforced during tag assignment by - Leaving some tags unassigned and distributing primers to multiple arrays [Ben-Dor et al. 03] - Exploiting availability of multiple primer candidates [MPT05]

12
Hybridization Models: Stability
Tag length = l [Affymetrix] Combined with additional constraints on GC-content, etc. Tag weight h [Ben-Dor et al. 00] wt(A)=wt(T)=1, wt(C)=wt(G)=2 Melting temperature TmT0 Tm can be computed using, e.g., nearest neighbor model of [SantaLucia 96]
=wt(T)=1, wt(C)=wt(G)=2. Melting temperature TmT0. Tm can be computed using, e.g., nearest neighbor model of [SantaLucia 96]")
13
Hybridization Models: Non-Interaction
Hamming distance model, e.g. [Marathe et al. 01] Models rigid DNA strands LCS/edit distance model, e.g., [Torney et al. 03] Models infinitely elastic DNA strands c-token model [Ben-Dor et al. 00]: Derived from nucleation complex theory: duplex formation requires formation of nucleation complex between perfectly complementary substrings Nucleation complex must have weight c

14
c-h Code Problem c-token: left-minimal DNA string of weight c, i.e.,
w(x) c w(x’) < c for every proper suffix x’ of x A set of tags is called c-h code if (C1) Every tag has weight h (C2) Every c-token is used at most once [Ben-Dor et al.00] c-h code problem: given c and h, find maximum cardinality c-h code
 c. w(x’) < c for every proper suffix x’ of x. A set of tags is called c-h code if. (C1) Every tag has weight h. (C2) Every c-token is used at most once. [Ben-Dor et al.00] c-h code problem: given c and h, find maximum cardinality c-h code.")
15
Previous Work [Ben-Dor et al.00] [MPT05]
Constructive upper-bound on c-h code size based on token tail-weight Approximation algorithm based on DeBruijn sequences [MPT05] Upper-bound for c-h codes including antitag-to-antitag hybridization constraints Simple alphabetic tree search heuristic
![Previous Work [Ben-Dor et al.00] [MPT05]](http://slideplayer.com/slide/4805010/15/images/15/Previous+Work+%5BBen-Dor+et+al.00%5D+%5BMPT05%5D.jpg "Constructive upper-bound on c-h code size based on token tail-weight. Approximation algorithm based on DeBruijn sequences. [MPT05] Upper-bound for c-h codes including antitag-to-antitag hybridization constraints. Simple alphabetic tree search heuristic.")
16
Token Content of a Tag Tag sequence of c-tokens
CCAGATT CC CCA CAG AGA GAT GATT Tag sequence of c-tokens End pos: c-token: CCCCACAGAGAGATGATT

17
Layered c-token graph l-1 l c/2 (c/2)+1 … c1 t s cN
+1 … c1 t s cN")
18
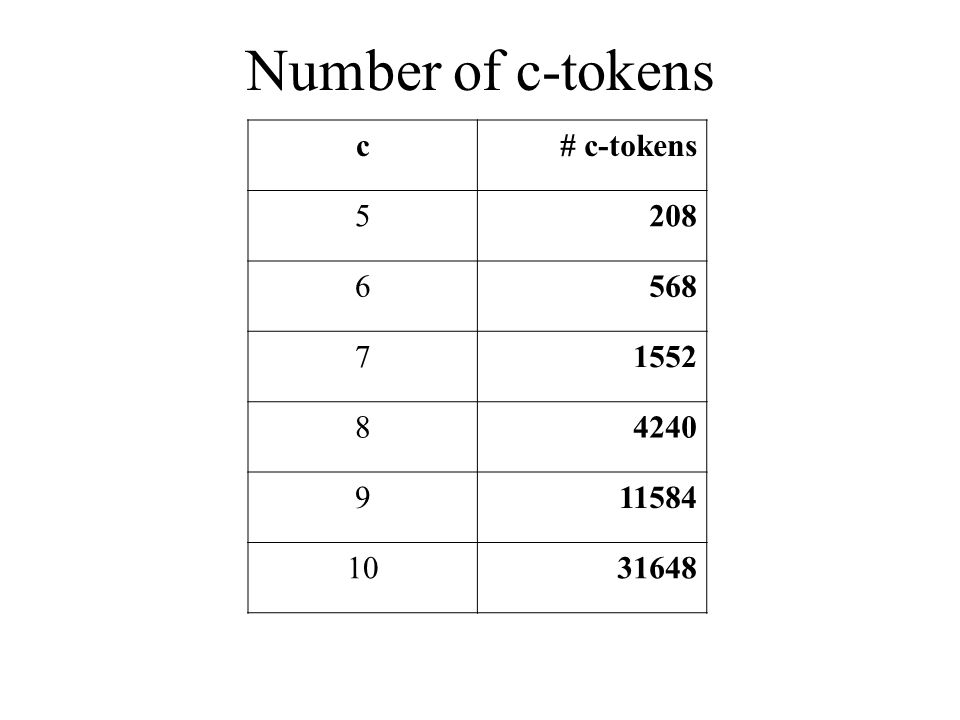
Integer Linear Program Formulation
Maximum integer flow problem w/ set capacity constraints O(lN)/O(hN) constraints & variables, where N = #c-tokens
/O(hN) constraints & variables, where N = #c-tokens.")
19
Number of c-tokens c # c-tokens 5 208 6 568 7 1552 8 4240 9 11584 10
31648
20
Packing ILP Formulation
To give an integer program formulation for the global buffered routing problem we will first define a graph G whose vertices correspond to pin and buffer-block locations. The graph has an edge between vertices u and v if the rectilinear distance between u and v, taking into account obstacles, is in the interval [L,U]. We then introduce a 0/1 variable f(T) for each valid routing tree T, i.e., for every tree in which the source-to-sink paths satisfy the imposed parity and length constraints. This variable will be set to 1 if the tree T is used in the final routing and to 0 otherwise. The objective is to maximize the total weight of the connected nets -- for simplicity we consider here only the un-weighted case, which corresponds to maximizing the number of connected nets. The integer program imposes two kinds of capacity constraints.The first type of constraint says that at most one tree can be routed for each net since pin capacities are set to 1. The second type of constraint says that the number of trees through a buffer block cannot exceed its capacity. Notice that in the special case in which all nets have 2 pins, the above formulation reduces to a regular (i.e., 2-terminal) vertex-capacitated integer multicommodity flow problem.
 for each valid routing tree T, i.e., for every tree in which the source-to-sink paths satisfy the imposed parity and length constraints. This variable will be set to 1 if the tree T is used in the final routing and to 0 otherwise. The objective is to maximize the total weight of the connected nets -- for simplicity we consider here only the un-weighted case, which corresponds to maximizing the number of connected nets. The integer program imposes two kinds of capacity constraints.The first type of constraint says that at most one tree can be routed for each net since pin capacities are set to 1. The second type of constraint says that the number of trees through a buffer block cannot exceed its capacity. Notice that in the special case in which all nets have 2 pins, the above formulation reduces to a regular (i.e., 2-terminal) vertex-capacitated integer multicommodity flow problem.")
21
Garg-Konemann Algorithm
x 0; y // yi are variables of the dual LP Find min weight s-t path p, where weight(v) = yi for every vVi While weight(p) < 1 do M maxi |p Vi| xp xp + 1/M For every i, yi yi( 1 + * |p Vi|/M ) Find min weight s-t path p, where weight(v) = yi for vVi 4. For every p, xp xp / (1 - log1+) The approximation algorithm finds simultaneously a fractional MTMCF and a solution to the dual program; the latter one is used for proving the approximation guarantee. The dual program asks for an assignment of non-negative weights w to the vertices such that the weight of every valid routing tree is at least 1. The algorithm starts with a fractional flow of zero and with the dual weight of each vertex set to a small value . As long as there exist feasible trees T with total weight less than 1, i.e., as long as the weights w are not dual feasible, the algorithm finds a tree T with minimum weight with respect to w. Then, tree T is added to the fractional flow, the weight of each vertex v in T is multiplied by a factor of (1+ /cap(v)), and previous two steps repeated. For increased efficiency, instead of finding the tree with minimum weight over all nets every time, the algorithm cycles through the nets, and uses the minimum weight tree only for the current net as long as its weight is remains close to the overall minimum. The previous update scheme ensures that vertex weights increase exponentially with the fractional flow routed through them. At the end of the algorithm, scaling the flow by the number of iterations gives a feasible fractional MTMCF which is within a small factor of the feasible dual solution given by the weights w. [GK98] The algorithm computes a factor (1- )2 approximation to the optimal LP solution with (N/)* log1+N shortest path computations
 = yi for every vVi. While weight(p) < 1 do. M maxi |p Vi| xp xp + 1/M. For every i, yi yi( 1 + * |p Vi|/M ) Find min weight s-t path p, where weight(v) = yi for vVi. 4. For every p, xp xp / (1 - log1+) The approximation algorithm finds simultaneously a fractional MTMCF and a solution to the dual program; the latter one is used for proving the approximation guarantee. The dual program asks for an assignment of non-negative weights w to the vertices such that the weight of every valid routing tree is at least 1. The algorithm starts with a fractional flow of zero and with the dual weight of each vertex set to a small value . As long as there exist feasible trees T with total weight less than 1, i.e., as long as the weights w are not dual feasible, the algorithm finds a tree T with minimum weight with respect to w. Then, tree T is added to the fractional flow, the weight of each vertex v in T is multiplied by a factor of (1+ /cap(v)), and previous two steps repeated. For increased efficiency, instead of finding the tree with minimum weight over all nets every time, the algorithm cycles through the nets, and uses the minimum weight tree only for the current net as long as its weight is remains close to the overall minimum. The previous update scheme ensures that vertex weights increase exponentially with the fractional flow routed through them. At the end of the algorithm, scaling the flow by the number of iterations gives a feasible fractional MTMCF which is within a small factor of the feasible dual solution given by the weights w. [GK98] The algorithm computes a factor (1- )2 approximation to the optimal LP solution with (N/)* log1+N shortest path computations.")
22
LP Based c-h Code Construction
Run Garg-Konemann and store the minimum weight paths in a list Traversing the list in reverse order, pick tags corresponding to paths if they are feasible and do not share c-tokens with already selected tags Mark used c-tokens and run the alphabetic tree search algorithm to select additional tags The approximation algorithm finds simultaneously a fractional MTMCF and a solution to the dual program; the latter one is used for proving the approximation guarantee. The dual program asks for an assignment of non-negative weights w to the vertices such that the weight of every valid routing tree is at least 1. The algorithm starts with a fractional flow of zero and with the dual weight of each vertex set to a small value . As long as there exist feasible trees T with total weight less than 1, i.e., as long as the weights w are not dual feasible, the algorithm finds a tree T with minimum weight with respect to w. Then, tree T is added to the fractional flow, the weight of each vertex v in T is multiplied by a factor of (1+ /cap(v)), and previous two steps repeated. For increased efficiency, instead of finding the tree with minimum weight over all nets every time, the algorithm cycles through the nets, and uses the minimum weight tree only for the current net as long as its weight is remains close to the overall minimum. The previous update scheme ensures that vertex weights increase exponentially with the fractional flow routed through them. At the end of the algorithm, scaling the flow by the number of iterations gives a feasible fractional MTMCF which is within a small factor of the feasible dual solution given by the weights w.
), and previous two steps repeated. For increased efficiency, instead of finding the tree with minimum weight over all nets every time, the algorithm cycles through the nets, and uses the minimum weight tree only for the current net as long as its weight is remains close to the overall minimum. The previous update scheme ensures that vertex weights increase exponentially with the fractional flow routed through them. At the end of the algorithm, scaling the flow by the number of iterations gives a feasible fractional MTMCF which is within a small factor of the feasible dual solution given by the weights w.")
23
Experimental Results (h=15)
")
24
Experimental Results (h=28)
")
25
Periodic Tags Key observation: c-token uniqueness constraint in c-h code formulation is too strong A c-token should not appear in two different tags, but can be repeated within a tag! A tag t is called periodic if it is the prefix of () for some Periodic strings with short period make best use of c-tokens (t uses at most || c-tokens)
 for some Periodic strings with short period make best use of c-tokens (t uses at most || c-tokens)")
26
c-token factor graph, c=4 (incomplete)
CC AAG AAC AAAA AAAT

27
Cycle Packing Problem Vertex-Disjoint Cycle Packing Problem: Given directed graph G, find maximum number of vertex disjoint directed cycles in G Theorem 1: APX-hard even for regular directed graphs with in-degree and out-degree 2 A maximization problem is APX-hard if there exists some constant >0 such that it is NP-hard to approximate the problem within a factor of 1/(1-) Proof: reduction from MAX-2-SAT-3 [Salavatipour and Verstraete 05] For general graphs: Quasi-NP-hard to approximate within (log1- n) O(n1/2) approximation algorithm
 Proof: reduction from MAX-2-SAT-3. [Salavatipour and Verstraete 05] For general graphs: Quasi-NP-hard to approximate within (log1- n) O(n1/2) approximation algorithm.")
28
Tag Set Design Algorithm
Construct c-token factor graph G T{} For all cycles C defining periodic tags, in increasing order of cycle length, do Add to T the tag defined by C Remove C from G Perform an alphabetic tree search and add to T tags with no c-tokens in common with T (alternatively: solve residual ILP) Return T
 Return T.")
29
Experimental Results h

30
Antitag-to-Antitag Hybridization
Formalization in c-token hybridization model: (C3) No two (anti)tags contain complementary substrings of weight c Cycle packing and tree search extend easily
 No two (anti)tags contain complementary substrings of weight c. Cycle packing and tree search extend easily.")
31
Results w/ Extended Constraints

32
Herpes B Gene Expression Assay
GenFlex Tags Tm # pools Pool size 500 tags 1000 tags 2000 tags # arrays % Util. 60 1446 1 4 82.26 3 65.35 2 57.05 5 88.26 70.95 63.55 67 1560 86.33 69.70 61.15 91.86 76.00 67.20 70 1522 88.46 73.65 65.40 92.26 91.10 70.30 Periodic Tags Tm # pools Pool size 500 tags 1000 tags 2000 tags # arrays % Util. 60 1446 1 4 94.06 2 97.20 72.30 5 96.13 100.00 67 1560 96.53 98.70 78.00 98.00 99.90 70 1522 96.73 98.90 76.10 97.80 99.80

33
Conclusions Use of periodic tags yields significant increase in tag set size and enables higher multiplexing rates in tag assignment Algorithms extend to more accurate hybridization models Monotonic melting temperature c-tokens factor graph Other applications of non-interacting DNA tag sets Lab-on-chip, DNA-mediated assembly, DNA computing [Brenneman&Condon 02] Open problems Settle approximation complexity of disjoint cycle packing

34
Acknowledgments Joint work with Dragos Trinca
UCONN Research Foundation

Similar presentations












 CSE Department,>")






