Download presentation
Presentation is loading. Please wait.

1
Data Mining Cardiovascular Bayesian Networks Charles Twardy †, Ann Nicholson †, Kevin Korb †, John McNeil ‡ (Danny Liew ‡, Sophie Rogers ‡, Lucas Hope † ) † School of Computer Science & Software Engineering ‡ Dept. of Epidemilogy & Preventive Medicine Monash University www.datamining.monash.edu.au/bwww.datamining.monash.edu.au/bnepi

2
Overview Medical Experts 2 epidemiological models 1. Knowledge Engineering Causal discovery (CaMML) + Other learners 3. Evaluation 2. Data Mining Busselton Study data Problem: assessment of risk for coronary heart disease (CHD) Bayesian network software (Netica)
 + Other learners 3. Evaluation 2. Data Mining Busselton Study data Problem: assessment of risk for coronary heart disease (CHD) Bayesian network software (Netica).")
3
Knowledge Engineering BNs from the medical literature l The Australian Busselton Study »every 3 years, 1966-1981, > 8,000 participants »mortality followup via WA death register + manually »Cox proportional-hazards model, 2,258 from 1978 cohort »CHD event base rates: 23% for men, 14% for women l The German PROCAM Study »1979-1985, followup every 2 years, > 25,000 participants »Scoring model (based on Cox), ~5,000 men »CHD event base rates: ~6% General question: are models transferable across populations?
, ~5,000 men »CHD event base rates: ~6% General question: are models transferable across populations")
4
Bayesian networks (BNs) l Use probability theory for representing uncertainty l Represents a probability distribution graphically (directed acyclic graphs) l Nodes: random variables (discrete, continuous) l Arcs indicate conditional dependencies between variables »P(X,Y,Z) can be decomposed to P(X)P(Y|X)P(Z|X) l Conditional Probability Distribution (CPD) »Associated with each variable, probability of each state given parent states l BN inference »Evidence: observation of specific state »Task: compute the posterior probabilities for query node(s) given evidence.
 l Use probability theory for representing uncertainty l Represents a probability distribution graphically (directed acyclic graphs) l Nodes: random variables (discrete, continuous) l Arcs indicate conditional dependencies between variables »P(X,Y,Z) can be decomposed to P(X)P(Y|X)P(Z|X) l Conditional Probability Distribution (CPD) »Associated with each variable, probability of each state given parent states l BN inference »Evidence: observation of specific state »Task: compute the posterior probabilities for query node(s) given evidence.")
5
The Busselton BN: nodes

6
The Busselton BN: arcs predictor variables uninformative 10-year risk of CHD event P(S,B,Al,At) =P(S)P(B|S)P(Al|S)P(At|S) BNs summarize the joint distribution All nodes have an associated conditional prob. distribution

7
The Busselton BN: discretization discretization choices binary nodes

8
The Busselton BN: reasoning

10
Bad cholesterol Heavy smoking Normal

11
The Busselton BN: reasoning More risk factors !

12
A risk assessment tool for clinicians l Previous tool: TAKEHEART l Combine risk assessment (probability) with costs.
 with costs.")
13
Risk Assessment Tool: example Young, predictor not observed – don’t treat old, predictor not observed – treatNot so old, predictor not observed – treat Young, predictor observed – don’t treat

14
PROCAM BN

15
CaMML: a causal learner l Developed at Monash University l Data mines BNs from epidemiological data l Minimum message length (MML) metric: Trades-off complexity vs goodness of fit l MCMC search over model space
 metric: Trades-off complexity vs goodness of fit l MCMC search over model space")
16
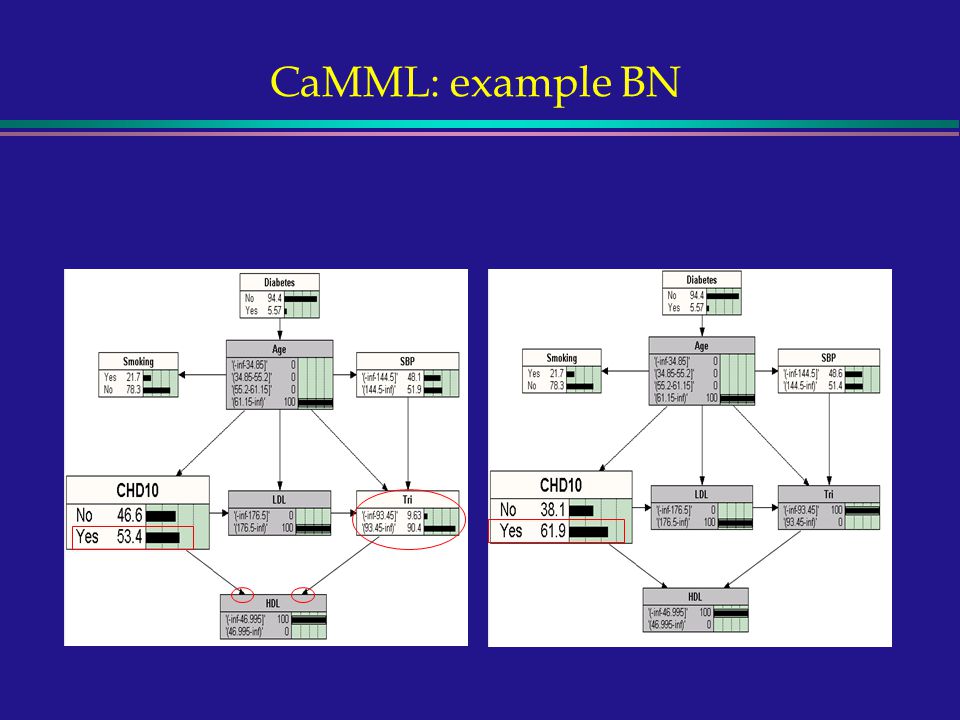
CaMML: example BN

18
Evaluation l Predicting 10 year risk of CHD using Busselton data l Split data 90-10 training/testing l 10 fold cross validation l Metrics: »Predictive Accuracy »ROC Curves (area under curve): correct classification vs false positives »Bayesian Information Reward (BIR) l Using Weka: Java environment for machine learning tools and techniques
: correct classification vs false positives »Bayesian Information Reward (BIR) l Using Weka: Java environment for machine learning tools and techniques")
19
Predictive accuracy l Examining each joint observation in the sample l Adding any available evidence for the other nodes l Updating the network l Use value with highest probability as predicted value l Compare predicted value with the actual value

20
Information Reward l Rewards calibration of probabilities l Zero reward for just reporting priors l Unbounded below for a bad prediction l Bounded above by a maximum that depends on priors Reward = 0 Repeat If I == correct state IR += log ( 1 / p[i] ) else IR += log ( 1 / 1 - p[i] )
![Information Reward l Rewards calibration of probabilities l Zero reward for just reporting priors l Unbounded below for a bad prediction l Bounded above by a maximum that depends on priors Reward = 0 Repeat If I == correct state IR += log ( 1 / p[i] ) else IR += log ( 1 / 1 - p[i] )](http://images.slideplayer.com/15/4800275/slides/slide_20.jpg "Information Reward l Rewards calibration of probabilities l Zero reward for just reporting priors l Unbounded below for a bad prediction l Bounded above by a maximum that depends on priors Reward = 0 Repeat If I == correct state IR += log ( 1 / p[i] ) else IR += log ( 1 / 1 - p[i] )")
21
Experimental Evaluation l Experiment 1: »Compare Busselton, PROCAM and CaMML BNs l Experiment 2 »Compare CaMML and other standard machine learners (from Weka)
")
22
Evaluation: Weka learners l Naïve Bayes l J48 (version of C4.5) l CaMML –Causal BN learner, using MML metric l AODE l TAN l Logistic Pr=1/3
 l CaMML –Causal BN learner, using MML metric l AODE l TAN l Logistic Pr=1/3")
23
Experiment 1: ROC Results Area under curve (AUC) priors No-one at risk! Everyone at risk! Extremes:
 priors No-one at risk! Everyone at risk! Extremes:")
24
Experiment 1: Bayesian Info Reward

25
Experiment 2: ROC Results

26
Experiment 2: Bayesian Info Reward

27
Summary of Results Experiment I (Models of whole data) l PROCAM model does at least as well as Busselton » On Busselton data » For both "relative" (ROC) and "absolute" (BIR) risk l CaMML Models do as well »But much simpler: only 4 nodes matter to CHD10! Experiment II (Cross-validation of learners) l Logistic regression does best on both metrics »Statistically powerful: only 1 parameter per arc »No search required: structure is given »No discretization necessary
 l Logistic regression does best on both metrics »Statistically powerful: only 1 parameter per arc »No search required: structure is given »No discretization necessary.")
28
Conclusions l Busselton & PROCAM models appear to perform equally well on Busselton data, using an absolute risk measure (BIR) from the literature l CaMML results suggest the data have high variance and are too weak to support inference to complex models. Combining data would help.

29
Future directions l Improve data mining by »Adding prior knowledge to search »Assessing whether data sources can be combined; if so, do so l Investigate combination of continuous and discrete variables in data mining and modeling l Develop new TAKEHEART model using BNs (taking the best from experts, literature, data mining) »with intervention modeling (Causal Reckoner) »with decision support »with GUI, usable by clinicians
 »with intervention modeling (Causal Reckoner) »with decision support »with GUI, usable by clinicians")
30
References l G. Assmann, P. Cullen and H. Schulte. Simple scoring scheme for calculating the risk of acute coronary events based on the 10-year follow-up of the Prospective Cardiovascular Munster (PROCAM) study. Circulation, 105(3):310-315, 2002. l M.W. Knuiman, H.T. Vu and H. C. Bartholomew. Multivariate risk estimation for coronary heart disease: the Busselton Health Study, Australian & New Zealand Journal of Public Health, 22:747-753, 1998. l C.S. Wallace and K.B. Korb. Learning Linear Causal Models by MML Sampling, In A. Gammerman, editor, Causal Models and Intelligent Data Management, pages 89-111. Springer-Verlag, 1999. www.datamining.monash.edu.au/software/camml l C.R. Twardy, A.E. Nicholson, K.B. Korb and J. McNeil. Data Mining Cardiovascular Bayesian Networks. Technical report 2004/165. School of Computer Science and Software Engineering, Monash University, 2004. l C.R. Twardy, A.E. Nicholson and K.B. Korb. Knowledge engineering cardiovascular Bayesian networks from the literature, Technical Report 2005/170, School of CSSE, Monash University, 2005.
 study. Circulation, 105(3): , l M.W. Knuiman, H.T. Vu and H. C. Bartholomew. Multivariate risk estimation for coronary heart disease: the Busselton Health Study, Australian & New Zealand Journal of Public Health, 22: , l C.S. Wallace and K.B. Korb. Learning Linear Causal Models by MML Sampling, In A. Gammerman, editor, Causal Models and Intelligent Data Management, pages Springer-Verlag, l C.R. Twardy, A.E. Nicholson, K.B. Korb and J. McNeil. Data Mining Cardiovascular Bayesian Networks. Technical report 2004/165. School of Computer Science and Software Engineering, Monash University, l C.R. Twardy, A.E. Nicholson and K.B. Korb. Knowledge engineering cardiovascular Bayesian networks from the literature, Technical Report 2005/170, School of CSSE, Monash University,")
Similar presentations




2005.>")
 Computer Science cpsc502, Lecture 15 Nov, 1, 2011 Slide credit: C. Conati, S.>")











>")

 Owen Woodberry Supervisors: Ann Nicholson Kevin Korb Carmel Pollino.>")
