Download presentation
Presentation is loading. Please wait.

1
Data Mining Chapter 9 Moving on: Applications and Beyond
Kirk Scott

2
So-called machine learning is a broad topic with many ramifications
Data mining is just an applied subset of this overall field The book says the algorithms aren’t “abstruse or complicated” but they’re also not “completely obvious and trivial”

3
The book identifies the challenge of the future as lying in the realm of applications
In this sense, data mining has something in common with database management systems For some people the interesting part is figuring out how to apply the techniques to a given problem

4
The book notes that the source of these applications are people working in the problem domains
People specializing in data mining will continue to develop new algorithms But this doesn’t happen in a vacuum Much of the real, interesting work will come out of applications

5
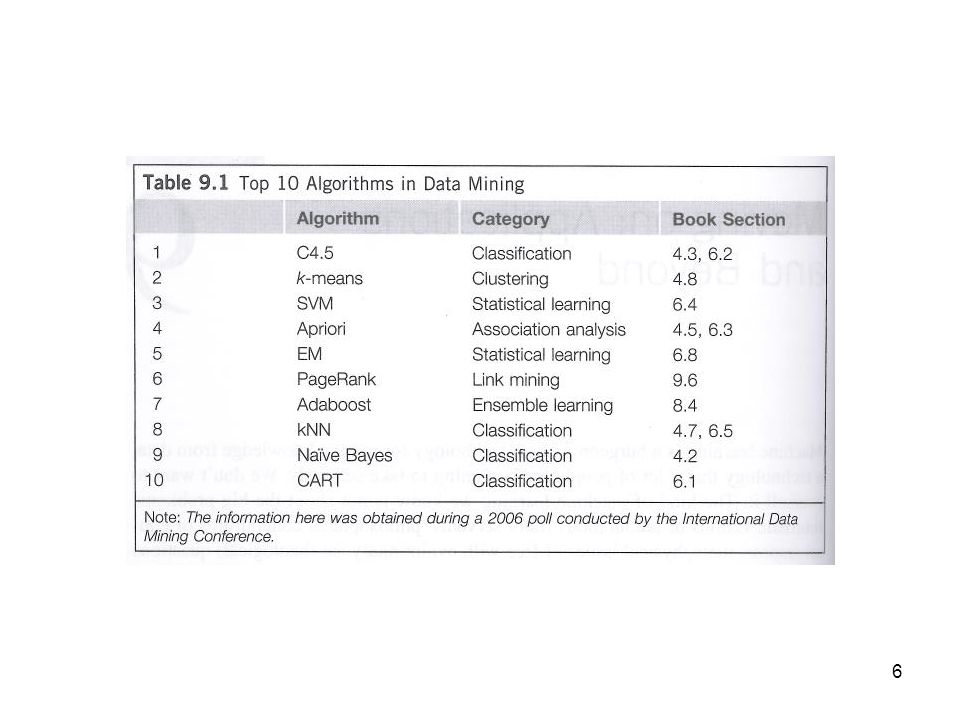
9.1 Applying Data Mining The book lists the “Top 10” data mining algorithms These are given in Table 9.1, shown on the following overhead Recall that number 1, C4.5, was for decision tree induction Notice also that the majority of these algorithms are for classification

7
Progress in Data Mining
There is a pitfall of applying algorithms to data sets, comparing results, and drawing broad conclusions about what is best in certain problem domains Reasoning from the specific to the general, without further information, is not necessarily correct

8
Even statistically significant differences in outcomes may not be important in practice
Quite often, simple methods get reasonably good results Complicated methods have their own shortcomings, including computational cost

9
Something to always keep in mind:
There may just be a lot of noise in the data Or, there may just be a lot of statistical variation There ARE limits on the ability to draw inferences from data

10
Also, training sets, by definition, are historical
They can’t perfectly reflect new data in a changing world

11
Another point to consider:
Recall that some classification schemes give probabilities that an instance falls into a class However, in reality, classification categories might not be mutually exclusive There may be data points in the training set which are partially one and partially another

12
However, the training set is considered to have instances that are rigidly classified as one or the other The training set doesn’t reflect probability Thus, the training set which you are basing your inferences on already contains inaccuracies You might think of this as conceptual noise resulting from forcing an instance into one class

13
The book admits that tweaking (picking parameters) can affect performance
As a result, small empirical differences in data mining results do not necessarily reflect actual differences in the quality of the algorithms In application, one might have been more successfully tweaked than another

14
Another interesting point on the Occam’s Razor/Epicurus divide:
Complicated methods may be harder to criticize than simple ones That fact alone doesn’t make them better The authors still favor “All else being equal, simpler is better”.

15
9.2 Learning from Massive Datasets
Basic constraints: Computational space and time Data stream methods are unaffected by this (more later) In other types of algorithms implementation techniques like hashing, caching, indexing and other data structures may be critical to practicality
 In other types of algorithms implementation techniques like hashing, caching, indexing and other data structures may be critical to practicality.")
16
Massive data sets typically imply large numbers of instances
Any algorithm with time complexity > linear will eventually be swamped by massive data Depending on the algorithm, too many attributes may also render it impractical because the computational complexity is in the dimension of the problem space

17
General ways to adapt to large data sets:
Train on a sample or subset of the data only Do a parallel implementation of the algorithm in a multi-processor environment Invent new algorithms…

18
Training on samples or subsets can give you as good a result as training on the whole set
The law of diminishing returns says that after a certain point, more instances don’t give significant increases in accuracy

19
Training on Samples There are two ways of looking at this:
If a problem is simple, a small data set may encapsulate all there is to know about it If the problem is complex but the data mining algorithm is simple, the algorithm may max out on its predictive power no matter how many training instances there are

20
Parallelization Algorithms like nearest neighbor, tree formation, etc. can be parallelized Not only do you have to figure out how to parallelize Parallelization is no defense against combinatorial explosion If the complexity is exponential but the growth in the number of processors is linear, you eventually lose

21
New Algorithms This is where research comes in
In general, the sky is the limit In some situations (tree building, for example) there is a provable floor on complexity Even here, new methods may be simpler and still have the characteristic of approximating the solutions given by deterministic methods
 there is a provable floor on complexity. Even here, new methods may be simpler and still have the characteristic of approximating the solutions given by deterministic methods.")
22
A side note on this: Virtually everything we’ve looked at has been a heuristic anyway—including greedy tree formation Exhaustive search would give genuinely optimal results Everything else is essentially an approximation approach

23
Another aspect to improving algorithm performance:
A lot of the data in a set, both instances and attributes, may be redundant Simply finding ways to throw out useless data may improve performance This idea will recur in the next section

24
9.3 Data Stream Learning For data streams, the overriding assumption for algorithms is that each instance will be examined at most one time The model of the data is updated incrementally based on the incoming instance Then the instance is discarded

25
An example of an application area is sensor readings
As long as the sensor is active, the readings just keep on coming It seems that things like Web transactions might be another example

26
Both time and space are issues
Discarding instances saves space The examination of each instance also has to be fixed in time, with an average rate of examination no less than the arrival rate of instances This constraint rules out major changes or reorganization of the model

27
Modifications to the model resulting from an instance either have to be counted in the examination time Or they have to occur infrequently enough that they are averaged out over the examination time of multiple instances

28
You may come up with ways of throwing out unneeded data
But the goal is not to throw out data simply because you couldn’t handle it fast enough (Although stay tuned for a later comment on throwing out data)
")
29
Algorithms That Are Directly Suited to Data Streams
Naïve Bayes Perceptrons Multi-layer neural networks Rules with exceptions (although you can’t simply accumulate unlimited exceptions)
")
30
The book notes that other kinds of algorithms can be adapted to data streams
It spends some time explaining how this might be done with trees The details are obscure and not important at this late stage in the semester

31
The key insight about throwing out instances is this:
Will you lose important data if you throw out instances? In an unending data stream, if information or a pattern is significant, it will recur So in the long run, throwing out an instance doesn’t hurt the model that results from the algorithm

32
9.4 Incorporating Domain Knowledge
The overall topic here is metadata—data about the data How to put this to use is an open area of research There can be various kinds of relationships between attributes They include semantic, causal, and functional

33
Semantic relationships can be summarized in this way:
If one attribute is included in a rule, another should also be included Informally, in the problem domain, this means that these two attributes aren’t (fully) meaningful without the other Somehow this could be included as a condition in a data mining scheme
 meaningful without the other. Somehow this could be included as a condition in a data mining scheme.")
34
The idea of causality also comes from the problem domain
The point is that if causality exists, the data mining scheme should be able to detect it This causality may go through multiple attributes ABC…

35
Functional dependency in data mining refers to the same concept as in db design
The point with respect to metadata is that if the functional dependency is already know, it’s not productive to have data mining “discover” it

36
On the one hand, there may be ways of applying data mining to normalization
On the other hand, if that’s not your purpose, functional dependencies that are mined will tend to have high confidence and most likely high support These associations will end up outweighing other, new associations that an algorithm might mine

37
How should metadata be represented?
A straightforward approach is to list what you already know about the data set using rules Logical deduction schemes can produce other rules resulting from the ones you already know

38
Data mining scheme works with instances to produce other new rules that you didn’t know before
The bodies of rules, merged together, give the sum total of knowledge gleaned about the problem

39
9.5 Text Mining Compare text mining to standard data mining
Data sets roughly parallel database tables There are identifiable instances and well-defined attributes Text is emphatically not structured in this way

40
An interesting comparison:
Data mining is supposed to find information about data where that information was not known By definition, text is different In text, the information is out in the open, in the form language It is simply not in a form suitable for easy computerized analysis

41
Data mining can be said to have as its goal the acquisition of “actionable” information
Based on a training set you can classify or cluster future instances, for example In a derivative way, you can make decisions that earn make money, etc. Another goal of data mining is to develop a data model Again, this is out in the open with text

42
There are several applications of text mining:
Text summarization, document classification, and clustering Language identification and authorship ascription Assigning key descriptive phrases to documents Metadata, entity, and information extraction

43
Document classification can be done based on the (count of) occurrences of words in the document
There is a feature extraction aspect to this problem Frequent words don’t help classify Infrequent words don’t help classify There is still an overwhelming number of words in the middle that have value

44
More complex methods step up from counting words alone
Context, word order, grammatical constructs, etc. all affect meaning At the very least phrases might be mined instead of words Natural language processing, syntax, and semantics may come into play

45
Document classification may be done with predefined classes
Document clustering doesn’t have predefined classes Mining techniques can be used to identify the language of a document n-grams, n-letter sequences correlate highly with different languages n = 3 is usually sufficient for this

46
Authorship ascription is done by counting common (stylistic) words, not the content words which define classifications A more complex approach would again do more than just count words

47
Assignment of key phrases to a document corresponds to the problem of assigning subject headings in the library catalog You start with established sets of phrases with defined meanings The goal is to assign one or more of these phrases to the document

48
Metadata extraction is a related idea with further ramifications
Is it possible to find specific information like author and title, automatically? Can you extract useful identifying key words and phrases? Note that the ability to do this may result in “actionable” information

49
The next step is entity extraction
Not only do you want to extract more obvious things like the author and title: You want to identify any things that are mentioned in the document

50
How do you identify entities?
You can look them up in reference resources like dictionaries, lists of names, etc. You may rely on simply things like capitalization or titles of address, etc. You may search for regular expressions or use simple grammars for expressions

51
Information extraction refers to a situation similar to reading information from a form
Certain documents may be limited in their scope and expected to contain a given set of data items If the informational items can be extracted, it may then be possible to infer rules or relationships involving them

52
Text mining is complex There are many potential applications Ultimately, the algorithms fall into the realm of natural language processing The current state of the art of computerized text processing is at the level where it is hard to match human abilities and understanding

53
9.6 Web Mining This is like a specialized area of text mining
The basic content of pages is predominantly text There are two key differences: Pages have internal markup, which defines structure Pages have links in and out, which help classify by content and value

54
In fact, large amounts of Web content are tabular, and presumably suited to standard data mining
However, the tabular nature is only reflected in the html presentation A data mining technique called wrapper induction can be used to try and infer the tabular relationships based on formatting

55
Wrapper induction can be extended:
To accommodate changes in formatting To recognized when formats that differ superficially really indicate the same structure

56
Page rank is an important concept in Web mining
It is only tangentially related to standard data mining Page rank is a measure of how “good” a match a page is to a certain search request based on links in and out of pages

57
These are the general principles for page ranking:
Many links to page x suggest that x is good A link from y to x is a good indicator if there are few links out of y A link from y to x is a good indicator if y itself is rated highly

58
Having the ranks of pages depend on the ranks of other pages is somewhat circular
However, iterative algorithms can run through networks of links converging on solutions The stopping condition is when the change of ranking values between iterations falls below a certain threshold

59
Some relevant factoids:
The authors guess that for ranks normalized between 0 and 1, the threshold for the stopping conditions is in the range An early experiment when the Web was simpler converged after ~50 iterations

60
Rumor has it that Google’s page ranking program(s) cycle through the entire Web in a matter of days
This process is repeated every few weeks

61
There is a practical problem with this approach
There may be Web pages with no in links or no out links These are known as page rank sinks If the algorithm is caught in a sink it won’t terminate or converge

62
The algorithms are given probabilistic parameters
In searching the web there is a small probability of “teleporting”, jumping, to another random page The parameter is tunable Its size affects the speed and accuracy of convergence

63
9.7 Adversarial Situations
Spam filtering is a classic example of this You can write algorithms to identify spam The point is that spam senders will track the algorithms and try to outwit them This is a see-saw problem

64
Similar kinds of problems:
Trying to trick page ranking algorithms Trying to confound computer security programs that detect intrusions and breaches based on transaction patterns There are many applications of data mining which, while not necessarily adversarial exactly, are “security” rather than money based

65
Data mining may be used to detect fraud, money laundering, other criminal activity
It is used to flag airline passengers for additional screening The government uses it to detect terrorists or terror-related activity This can be based on any obtainable record, whether computer, cell phone or other, which can be mined

66
There are serious ethical, legal, privacy, constitutional, and civil liberties questions about these practices Data mining can also be applied in a collaborative/adversarial way

67
The authors cite robo-soccer
Independent agents “learn” to act independently and in concert with other agents to win a game or achieve some goal against other collections of agents The book also cites a project that was designed to determine the author of a document where the styled had presumably been intentionally altered

68
9.8 Ubiquitous Data Mining
Ubiquitous data mining stems from the concept of ubiquitous computing More factoids: The Web contains billion documents This is ~50 Terabytes Suppose you combined the content of the Web with the contents or actions of every device with an electronic brain, cell phone, iPOD, etc., and data mined across it all

69
In a more limited sphere the authors cite a specific example:
There are programs which follow a user’s actions with the goal of “learning” what tasks a user performs when using an operating system, in essence learning how to customize the O/S’s actions to the user’s desires

70
The authors state that data mining will be ubiquitous in the future
Doubtless this is true The questions remaining: Who wins, who makes money: Will this make us more masters or (willing) slaves of technology? Do you want to play the game? Will you have a choice?
 slaves of technology Do you want to play the game Will you have a choice")
71
The End

Similar presentations













 Sequence Comparisons –Problems in molecular biology involve finding the minimum number of edit.>")





