Download presentation
Presentation is loading. Please wait.

1
Hidden Markov Models BIOL337/STAT337/437 Spring Semester 2014

2
1 2 K … 1 2 K … 1 2 K … … … … 1 2 K … x1x1 x2x2 x3x3 xnxn 2 1 K 2 Theory of hidden Markov models (HMMs) Probabilistic interpretation of sequence alignments using HMMs Applications of HMMs to biological sequence modeling and discovery of features such as genes, etc. An HHM π1π1 … …π2π2 π3π3 πnπn

3
Example of an HHM Do you want to play? The Dishonest Casino

4
The situation... Casino has two dice, one fair (F) and one loaded (L) Probabilities for the fair die: P(1) = P(2) = P(3) = P(4) = P(5) = P(6) = 1/6 Probabilities for the loaded die: P(1) = P(2) = P(3) = P(4) = P(5) = 1/10; P(6) = ½ Before each roll, the casino player switches from the fair die to the loaded die (or vice versa) with probability 1/20 The game... You bet $1 You roll (always with the fair die) Casino player rolls (maybe with the fair die, maybe with the loaded die) Player who rolls the highest number wins $2
 and one loaded (L) Probabilities for the fair die: P(1) = P(2) = P(3) = P(4) = P(5) = P(6) = 1/6 Probabilities for the loaded die: P(1) = P(2) = P(3) = P(4) = P(5) = 1/10; P(6) = ½ Before each roll, the casino player switches from the fair die to the loaded die (or vice versa) with probability 1/20 The game... You bet $1 You roll (always with the fair die) Casino player rolls (maybe with the fair die, maybe with the loaded die) Player who rolls the highest number wins $2.")
5
Dishonest Casino HMM FAIRLOADED 0.05 0.95 P(1 | F) = 1/6 P(2 | F) = 1/6 P(3 | F) = 1/6 P(4 | F) = 1/6 P(5 | F) = 1/6 P(6 | F) = 1/6 P(1 | L) = 1/10 P(2 | L) = 1/10 P(3 | L) = 1/10 P(4 | L) = 1/10 P(5 | L) = 1/10 P(6 | L) = 1/2
 = 1/6 P(2 | F) = 1/6 P(3 | F) = 1/6 P(4 | F) = 1/6 P(5 | F) = 1/6 P(6 | F) = 1/6 P(1 | L) = 1/10 P(2 | L) = 1/10 P(3 | L) = 1/10 P(4 | L) = 1/10 P(5 | L) = 1/10 P(6 | L) = 1/2")
6
Three Fundamental Questions About Any HMM Evaluation: What is the probability of a sequence of outputs of an HMM? Decoding: Given a sequence of outputs of an HMM, what is the most probable sequence of states that the HMM went through to produce the output? Learning: Given a sequence of outputs of an HMM, how do we estimate the parameters of the model?

7
1666316316416412646255421 6515616361663616636166466 26532164151151 Evaluation Question Suppose the casino player rolls the following sequence... How likely is this sequence given our model of how the casino operates? 443 Probability = 1.3 x 10 -35 (Note (1/6) 67 = 7.309139054 x 10 -53.)
 67 = x ).")
8
Decoding Question 1666316316416412646255421 6515616361663616636166466 26532164151151 What portion of the sequence was generated with the fair die, and what portion with the loaded die? 443 FAIR LOADED

9
Learning Question 1666316316416412646255421 6515616361663616636166466 26532164151151 How “loaded” is the loaded die? How “fair” is the fair die? How often does the casino player change from fair to loaded, and back? That is, what are the parameters of the model? 443 FAIR LOADED P(6) = 0.64
 =")
10
Ingredients of a HMM An HMM M has the following parts... Alphabet Σ = {b 1, b 2,..., b m } //these symbols are output by the model, for example, Σ = {1,2,3,4,5,6} in the dishonest casino model Set of states Q = {1, 2,..., K} //for example, ‘FAIR’ and ‘LOADED’ Transition probabilities between states a i,j = probability of making a transition from state i to state j Starting probabilities a 0j = probability of the model starting in state j Σ a ij = 1 j=1 K Σ a 0j = 1 j=1 K

11
Emission probabilities within state k, e k (b) = probability of seeing (emitting) the symbol b output while in state k, that is, e k (b) = P(x i = b | π i = k) k 1 2 K e k (b 1 ) = P(x i = b 1 | π i = k) e k (b 2 ) = P(x i = b 2 | π i = k) e k (b m ) = P(x i = b m | π i = k) ak1ak1 ak2ak2 a k,K a k,k.…
 = probability of seeing (emitting) the symbol b output while in state k, that is, e k (b) = P(x i = b | π i = k) k 1 2 K e k (b 1 ) = P(x i = b 1 | π i = k) e k (b 2 ) = P(x i = b 2 | π i = k) e k (b m ) = P(x i = b m | π i = k) ak1ak1 ak2ak2 a k,K a k,k.…")
12
Some Notation π = ( π 1, π 2,..., π t ) x 1,x 2,...,x t, π 1, π 2,..., π t π i = state occupied after i steps π i = state occupied after i steps, x i emitted in state i
 x 1,x 2,...,x t, π 1, π 2,..., π t π i = state occupied after i steps π i = state occupied after i steps, x i emitted in state i")
13
1 2 K 1 2 K 1 2 K x1x1 x2x2 x3x3 1 2 K xnxn ……… … … … … x 1,x 2,...,x n, π 1, π 2,..., π n

14
‘Forgetfulness’ property: if the current state is π t, the next state π t+1 depends only on π t and nothing else P( t+1 = k | ‘whatever happened so far’) = P( t+1 = k | x 1,x 2,…,x t, 1, 2,…, t ) = P( t+1 = k | t ) The ‘forgetfulness’ property is part of the definition of an HMM!
 = P( t+1 = k | x 1,x 2,…,x t, 1, 2,…, t ) = P( t+1 = k | t ) The ‘forgetfulness’ property is part of the definition of an HMM!")
15
What is the probability of x 1,x 2,...,x n, π 1, π 2,..., π n ? Example: Take n = 2. P(x 1,x 2, π 1, π 2 ) = P(x 1, π 1,x 2, π 2 ) = P(x 2, π 2 | x 1, π 1 )·P(x 1, π 1 ) (conditional probability) = P(x 2 | π 2 )·P( π 2 | x 1, π 1 )·P(x 1, π 1 ) (conditional probability) = P(x 2 | π 2 )·P( π 2 | π 1 )·P(x 1, π 1 ) (‘forgetfulness’) = P(x 2 | π 2 )·P( π 2 | π 1 )·P(x 1 | π 1 )·P( π 1 ) (conditional probability) = e π (x 2 )·e π (x 1 )·a π π · a 0 π 21112
 = P(x 1, π 1,x 2, π 2 ) = P(x 2, π 2 | x 1, π 1 )·P(x 1, π 1 ) (conditional probability) = P(x 2 | π 2 )·P( π 2 | x 1, π 1 )·P(x 1, π 1 ) (conditional probability) = P(x 2 | π 2 )·P( π 2 | π 1 )·P(x 1, π 1 ) (‘forgetfulness’) = P(x 2 | π 2 )·P( π 2 | π 1 )·P(x 1 | π 1 )·P( π 1 ) (conditional probability) = e π (x 2 )·e π (x 1 )·a π π · a 0 π")
16
In general, for the sequence x 1,x 2,...,x n, π 1, π 2,..., π n, we have that P(x 1,...,x n, π 1,..., π n ) = Π e π (x k )·a π π kk-1kk=1 n 2 x1x1 1 x2x2 K x3x3 2 xnxn a 21 a1Ka1K a K* a *2 e2(x1)e2(x1)e1(x2)e1(x2)eK(x3)eK(x3)e2(xn)e2(xn) … …
 = Π e π (x k )·a π π kk-1kk=1 n 2 x1x1 1 x2x2 K x3x3 2 xnxn a 21 a1Ka1K a K* a *2 e2(x1)e2(x1)e1(x2)e1(x2)eK(x3)eK(x3)e2(xn)e2(xn) … …")
17
Do you want to play? The Dishonest Casino (cont.) 4251265121 π = F F F F F F F F F F x =
 π = F F F F F F F F F F x =")
18
a 0F = ½ a 0L = ½ P(x, π ) = a 0F e F (1)·a FF e F (2)· a FF e F (1)· a FF e F (5)· a FF e F (6)· a FF e F (2)· a FF e F (1)· a FF e F (5)· a FF e F (2) a FF e F (4) = ½·(1/6) 10 (0.95) 9 =.00000000521158647211 ≈ 5.21 10 -9 Suppose the starting probabilities are as follows: Now suppose that π = L L L L L L L L L L P(x, π ) = a 0L e L (1)·a LL e L (2)· a LL e L (1)· a LL e L (5)· a LL e L (6)· a LL e L (2)· a LL e L (1)· a LL e L (5)· a LL e L (2) a LL e L (4) = ½·(1/2) 1 ·(1/10) 9· (0.95) 9 =.00000000015756235243 ≈ 0.16 10 -9
 = a 0F e F (1)·a FF e F (2)· a FF e F (1)· a FF e F (5)· a FF e F (6)· a FF e F (2)· a FF e F (1)· a FF e F (5)· a FF e F (2) a FF e F (4) = ½·(1/6) 10 (0.95) 9 = ≈ 5.21 Suppose the starting probabilities are as follows: Now suppose that π = L L L L L L L L L L P(x, π ) = a 0L e L (1)·a LL e L (2)· a LL e L (1)· a LL e L (5)· a LL e L (6)· a LL e L (2)· a LL e L (1)· a LL e L (5)· a LL e L (2) a LL e L (4) = ½·(1/2) 1 ·(1/10) 9· (0.95) 9 = ≈ 0.16 10 -9")
19
6366265661 π = F F F F F F F F F F x = P(x, π ) = a 0F e F (1)·a FF e F (6)· a FF e F (6)· a FF e F (5)· a FF e F (6)· a FF e F (2)· a FF e F (6)· a FF e F (6)· a FF e F (3) a FF e F (6) = ½·(1/6) 10 (0.95) 9 =.00000000521158647211 ≈ 5.21 10 -9 Now suppose that π = L L L L L L L L L L P(x, π ) = a 0L e L (1)·a LL e L (6)· a LL e L (6)· a LL e L (5)· a LL e L (6)· a LL e L (2)· a LL e L (6)· a LL e L (6)· a LL e L (3) a LL e L (6) = ½·(1/2) 6 ·(1/10) 4· (0.95) 9 =.00000049238235134735 ≈ 492 10 -9 ≈100 times more likely!
 = a 0F e F (1)·a FF e F (6)· a FF e F (6)· a FF e F (5)· a FF e F (6)· a FF e F (2)· a FF e F (6)· a FF e F (6)· a FF e F (3) a FF e F (6) = ½·(1/6) 10 (0.95) 9 = ≈ 5.21 Now suppose that π = L L L L L L L L L L P(x, π ) = a 0L e L (1)·a LL e L (6)· a LL e L (6)· a LL e L (5)· a LL e L (6)· a LL e L (2)· a LL e L (6)· a LL e L (6)· a LL e L (3) a LL e L (6) = ½·(1/2) 6 ·(1/10) 4· (0.95) 9 = ≈ 492 ≈100 times more likely!")
20
Evaluation Problem (solved by Forward-Backward algorithm) GIVEN: an HMM M and a sequence x FIND: P(x | M ) Decoding Problem (solved by Viterbi algorithm) GIVEN:an HMM M and a sequence x FIND:sequence of states that maximizes P(x, | M ) Learning Problem (solved by Baum-Welch algorithm) GIVEN: a HMM M, with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) Three Fundamental Problems
 GIVEN: an HMM M and a sequence x FIND: P(x | M ) Decoding Problem (solved by Viterbi algorithm) GIVEN:an HMM M and a sequence x FIND:sequence of states that maximizes P(x, | M ) Learning Problem (solved by Baum-Welch algorithm) GIVEN: a HMM M, with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) Three Fundamental Problems")
21
Let’s not get confused by notation...(lots of different ones!) P(x | M ) : probability that x is generated by the model M (the model M consists of the transition and emission probabilities and the architecture of the HMM, that is, the underlying directed graph) P(x | θ ) : probability that x is generated by the model M where θ is the vector of parameter values, that, is the transition and emission probabilities (note that P(x | M ) is equivalent to P(x | θ )) P(x) : same as P(x | M ) and P(x | θ ) : probability that x is generated by the model and π is the sequence of states that produced x P(x, | M ), P(x, | ) and P(x, )
 P(x | M ) : probability that x is generated by the model M (the model M consists of the transition and emission probabilities and the architecture of the HMM, that is, the underlying directed graph) P(x | θ ) : probability that x is generated by the model M where θ is the vector of parameter values, that, is the transition and emission probabilities (note that P(x | M ) is equivalent to P(x | θ )) P(x) : same as P(x | M ) and P(x | θ ) : probability that x is generated by the model and π is the sequence of states that produced x P(x, | M ), P(x, | ) and P(x, )")
22
1 2 K 1 2 K 1 2 K x1x1 x2x2 x3x3 1 2 K xnxn ……… … … … … Decoding Problem for HMMs GIVEN: Sequence x = x 1 x 2 … x n generated by the model M FIND: Path π = π 1 π 2 … π n that maximizes P(x, π ) π π1π1 π2π2 π3π3 πnπn π = π 1, π 2, …, π n
 π π1π1 π2π2 π3π3 πnπn π = π 1, π 2, …, π n")
23
Formally, the Decoding Problem for HHMs is to find the following given a sequence x = x 1 x 2 … x n generated by the model M : π* = argmax {P(x, π | M )} P* = max {P(x, π | M )} =P(x, π* | M )} π π P(x 1,...,x n, π 1,..., π n ) = Π e π (x k )·a π π kk-1kk=1 n
} P* = max {P(x, π | M )} =P(x, π* | M )} π π P(x 1,...,x n, π 1,..., π n ) = Π e π (x k )·a π π kk-1kk=1 n")
24
Let V k (i) denote the probability of the maximum probability path from stage 1 to stage i ending in state k generating x i in state k. Can we write an equation (hopefully recursive) for V k (i)? V k (i) = max {P(x 1,...,x i-1, π 1,..., π i-1,x i, π i = k | M )} = e k (x i )·max {a jk ·V j (i-1)} π 1,..., π i-1 j … (proof using properties of conditional probabilities...) Recursive equation... so...dynamic programming!
 for V k (i). V k (i) = max {P(x 1,...,x i-1, π 1,..., π i-1,x i, π i = k | M )} = e k (x i )·max {a jk ·V j (i-1)} π 1,..., π i-1 j … (proof using properties of conditional probabilities...) Recursive equation... so...dynamic programming!.")
25
k …… ak1ak1 ak2ak2 a kK a1ka1k a 2k a Kk xixi Stage i, State k ek(xi)ek(xi) 1 2 K Stage (i – 1) V 1 (i-1) V 2 (i-1) V K-1 (i-1)
ek(xi) 1 2 K Stage (i – 1) V 1 (i-1) V 2 (i-1) V K-1 (i-1)")
26
1 2 K 1 2 K 1 2 K x1x1 x2x2 x3x3 1 2 K xnxn ……… … … … … 1 2 K … 0 V 1 (0) = 0 V 2 (0) = 0 V K (0) = 0 V 0 (0) = 1 a0ka0k a 02 a 01 Initialization step is needed to start the algorithm! (‘dummy’ 0 th stage) How do we start the algorithm? Stage 1Stage 2Stage 3 … Stage n
 How do we start the algorithm. Stage 1Stage 2Stage 3 … Stage n.")
27
1. Initialization Step. //initialize matrix V 0 (0) = 1 V j (0) = 0 for all j > 0 2. Main Iteration. //fill in table for each i = 1 to n for each k = 1 to K V k (i) = e k (x i )·max {a jk ·V j (i-1)} Ptr k (i) = argmax {a jk ·V j (i-1)} 3. Termination. //recover optimal probability and path P* = max {P(x, π | M )} = max { V j (n)} π * = argmax {V j (n)} for each i = n – 1 downto 1 π * = Ptr π (i+1) Viterbi Algorithm for Decoding an HMM Time: O(K 2 n) Space: O(Kn) j j j π n j i i+1
 = e k (x i )·max {a jk ·V j (i-1)} Ptr k (i) = argmax {a jk ·V j (i-1)} 3. Termination. //recover optimal probability and path P* = max {P(x, π | M )} = max { V j (n)} π * = argmax {V j (n)} for each i = n – 1 downto 1 π * = Ptr π (i+1) Viterbi Algorithm for Decoding an HMM Time: O(K 2 n) Space: O(Kn) j j j π n j i i+1.")
28
x 1 x 2 x 3 x n 1 2 K … … States V 1 (1) = e 1 (x 1 )·a 01 V K (1) = e K (x 1 )·a 0K V 2 (1) = e 2 (x 1 )·a 02 V k (2) = e k (x 2 )·max {a jk ·V j (1)} j
 = e 1 (x 1 )·a 01 V K (1) = e K (x 1 )·a 0K V 2 (1) = e 2 (x 1 )·a 02 V k (2) = e k (x 2 )·max {a jk ·V j (1)} j")
29
FAIRLOADED 0.05 0.95 P(1 | F) = 1/6 P(2 | F) = 1/6 P(3 | F) = 1/6 P(4 | F) = 1/6 P(5 | F) = 1/6 P(6 | F) = 1/6 P(1 | L) = 1/10 P(2 | L) = 1/10 P(3 | L) = 1/10 P(4 | L) = 1/10 P(5 | L) = 1/10 P(6 | L) = 1/2 Computational Example of the Viterbi Algorithm x = 2 6 6
 = 1/6 P(2 | F) = 1/6 P(3 | F) = 1/6 P(4 | F) = 1/6 P(5 | F) = 1/6 P(6 | F) = 1/6 P(1 | L) = 1/10 P(2 | L) = 1/10 P(3 | L) = 1/10 P(4 | L) = 1/10 P(5 | L) = 1/10 P(6 | L) = 1/2 Computational Example of the Viterbi Algorithm x = 2 6 6")
30
1/2*1/6 = 1/12 1/6*max{19/20*1/12,1/20 *1/20} = 19/1440 = 0.0131944 1/6*max{19/20* 19/1440,1/20*19/800} = 361/172800 = 0.002089120 1/2*1/10 = 1/20 1/2*max{1/20*1/12,19/20 *1/20} = 19/800 = 0.02375 1/2*max{1/20* 19/1440,19/20*19/800} = 361/32000 = 0.01128125 F L 2 6 6 P* = 0.01128125 π = LLL x = 2 6 6 P(266,LLL) = (1/2) 3 ·(1/10)·(95/100) 2 = 361/32000 = 0.01128125
 = (1/2) 3 ·(1/10)·(95/100) 2 = 361/32000 =")
31
How well does Viterbi perform? 300 rolls by the casino Viterbi is correct 91% of the time!

32
Problem of Underflow in the Viterbi Algorithm V k (i) = max {P(x 1,...,x i-1, π 1,..., π i-1,x i, π i = k | M )} = e k (x i )·max {a jk ·V j (i-1)} π 1,..., π i- 1 j Numbers become very small since probabilities are being multiplied together! V k (i) = log(e k (x i )) + max {log(a jk ) + V j (i-1)} j Compute with the logarithms of the probabilities to reduce the occurrence of underflow!
 = log(e k (x i )) + max {log(a jk ) + V j (i-1)} j Compute with the logarithms of the probabilities to reduce the occurrence of underflow!.")
33
Evaluation Problem (solved by Forward-Backward algorithm) GIVEN: an HMM M and a sequence x FIND: P(x | M ) Decoding Problem (solved by Viterbi algorithm) GIVEN:an HMM M and a sequence x FIND:sequence of states that maximizes P(x, | M ) Learning Problem (solved by Baum-Welch algorithm) GIVEN: a HMM M, with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) Three Fundamental Problems Done!
 GIVEN: an HMM M and a sequence x FIND: P(x | M ) Decoding Problem (solved by Viterbi algorithm) GIVEN:an HMM M and a sequence x FIND:sequence of states that maximizes P(x, | M ) Learning Problem (solved by Baum-Welch algorithm) GIVEN: a HMM M, with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) Three Fundamental Problems Done!")
34
1 2 K 1 2 K 1 2 K x1x1 x2x2 x3x3 1 2 K xnxn ……… … … … … Evaluation Problem for HMMs GIVEN: Sequence x = x 1 x 2 … x n generated by the model M FIND: Find P(x), the probability of x given the model M π π1π1 π2π2 π3π3 πnπn
, the probability of x given the model M π π1π1 π2π2 π3π3 πnπn")
35
Formally, the Evaluation Problem for HHMs is to find the following given a sequence x = x 1 x 2 … x n generated by the model M : P(x) = Σ P(x, π | M ) = Σ P(x | π )·P( π ) π π Exponential number of paths π ! Since there are an exponential number of paths, specifically K n, the probability P(x) cannot be computed directly. So...dynamic programming again!
 cannot be computed directly. So...dynamic programming again!.")
36
Let f k (i) denote the probability of the subsequence x 1 x 2,...,x i of x such that π i = k. The quantity f k (i) is called the forward probability. Can we write an equation (hopefully recursive) for f k (i)? f k (i) = Σ P(x 1,...,x i-1, π 1,..., π i-1,x i, π i = k | M ) = e k (x i )· Σ {a jk ·f j (i-1)} π 1,..., π i-1 j … (proof using properties of conditional probabilities...) Recursive equation suitable for dynamic programming
 is called the forward probability. Can we write an equation (hopefully recursive) for f k (i). f k (i) = Σ P(x 1,...,x i-1, π 1,..., π i-1,x i, π i = k | M ) = e k (x i )· Σ {a jk ·f j (i-1)} π 1,..., π i-1 j … (proof using properties of conditional probabilities...) Recursive equation suitable for dynamic programming.")
37
k …… ak1ak1 ak2ak2 a kK a1ka1k a 2k a Kk xixi Stage i, State k ek(xi)ek(xi) 1 2 K Stage (i – 1) f 1 (i-1) f 2 (i-1) f K (i-1)
ek(xi) 1 2 K Stage (i – 1) f 1 (i-1) f 2 (i-1) f K (i-1)")
38
1 2 K 1 2 K 1 2 K x1x1 x2x2 x3x3 1 2 K xnxn ……… … … … … 1 2 K … 0 f 1 (0) = 0 f 2 (0) = 0 f K (0) = 0 f 0 (0) = 1 a0ka0k a 02 a 01 Initialization step is needed to start the algorithm! (‘dummy’ 0 th stage) How do we start the algorithm? Stage 1Stage 2Stage 3 … Stage n
 How do we start the algorithm. Stage 1Stage 2Stage 3 … Stage n.")
39
1. Initialization Step. //initialize matrix f 0 (0) = 1 f j (0) = 0 for all j > 0 2. Main Iteration. //fill in table for each i = 1 to n for each k = 1 to K f k (i) = e k (x i )· Σ a jk ·f j (i-1) 3. Termination. //recover probability of x P(x) = Σ f j (n) Forward Algorithm for Evaluation Time: O(K 2 n) Space: O(Kn) j j
 = e k (x i )· Σ a jk ·f j (i-1) 3. Termination. //recover probability of x P(x) = Σ f j (n) Forward Algorithm for Evaluation Time: O(K 2 n) Space: O(Kn) j j.")
40
x 1 x 2 x 3 x n 1 2 K … … States f 1 (1) = e 1 (x 1 )·a 01 f K (1) = e K (x 1 )·a 0K f 2 (1) = e 2 (x 1 )·a 02 f k (2) = e k (x 2 )· Σ {a jk ·f j (1)} j
 = e 1 (x 1 )·a 01 f K (1) = e K (x 1 )·a 0K f 2 (1) = e 2 (x 1 )·a 02 f k (2) = e k (x 2 )· Σ {a jk ·f j (1)} j")
41
1. Initialization Step. //initialize matrix V 0 (0) = 1 V j (0) = 0 for all j > 0 2. Main Iteration. //fill in table for each i = 1 to n for each k = 1 to K V k (i) = e k (x i )·max {a jk ·V j (i-1)} Ptr k (i) = argmax {a jk ·V j (i-1)} 3. Termination. //recover optimal probability and path P* = max {P(x, π | M )} = max {V j (n)} π * = argmax {V j (n)} for each i = n – 1 downto 1 π * = Ptr π (i+1) Viterbi vs. Forward j j n i i+1 j j π 1. Initialization Step. //initialize matrix f 0 (0) = 1 f j (0) = 0 for all j > 0 2. Main Iteration. //fill in table for each i = 1 to n for each k = 1 to K f k (i) = e k (x i )· Σ a jk ·f j (i-1) 3. Termination. //recover probability P(x) = Σ f j (n) j j
 = e k (x i )·max {a jk ·V j (i-1)} Ptr k (i) = argmax {a jk ·V j (i-1)} 3. Termination. //recover optimal probability and path P* = max {P(x, π | M )} = max {V j (n)} π * = argmax {V j (n)} for each i = n – 1 downto 1 π * = Ptr π (i+1) Viterbi vs. Forward j j n i i+1 j j π 1. Initialization Step. //initialize matrix f 0 (0) = 1 f j (0) = 0 for all j > 0 2. Main Iteration. //fill in table for each i = 1 to n for each k = 1 to K f k (i) = e k (x i )· Σ a jk ·f j (i-1) 3. Termination. //recover probability P(x) = Σ f j (n) j j.")
42
1/2*1/6 = 1/12 1/6*[19/20*1/12+1/20*1/2 0] = 49/3600 = 0.0136111 1/6*[19/20*49/3600+1/20 *31/1200] = 8/3375 = 0.0023703 1/2*1/10 = 1/20 1/2*[1/20*1/12+19/20*1/2 0] = 31/1200 = 0.0258333 1/2*[1/20*49/3600+19/20 *31/1200] = 227/18000 = 0.0126111 F L 2 6 6 P(x) = P(266) = 8/3375 + 227/18000 = 809/54000 = 0.01498148148 x = 2 6 6
![1/2*1/6 = 1/12 1/6*[19/20*1/12+1/20*1/2 0] = 49/3600 = /6*[19/20*49/3600+1/20 *31/1200] = 8/3375 = /2*1/10 = 1/20 1/2*[1/20*1/12+19/20*1/2 0] = 31/1200 = /2*[1/20*49/ /20 *31/1200] = 227/18000 = F L P(x) = P(266) = 8/ /18000 = 809/54000 = x = 2 6 6](http://images.slideplayer.com/15/4757520/slides/slide_42.jpg "1/2*1/6 = 1/12 1/6*[19/20*1/12+1/20*1/2 0] = 49/3600 = /6*[19/20*49/3600+1/20 *31/1200] = 8/3375 = /2*1/10 = 1/20 1/2*[1/20*1/12+19/20*1/2 0] = 31/1200 = /2*[1/20*49/ /20 *31/1200] = 227/18000 = F L P(x) = P(266) = 8/ /18000 = 809/54000 = x = 2 6 6")
43
(1/2*1/10 * (95/100)*(1/2) * (95/100)*(1/2)) + (1/2*1/10 * (95/100)*(1/2) * (1/20)*(1/6)) + (1/2*1/10 * (1/20)*(1/6) * (1/20)*(1/2)) + (1/2*1/10 * (1/20)*(1/6) * (95/100)*(1/6) ) + (1/2*1/6 * (1/20)*(1/2) * (95/100)*(1/2) ) + (1/2*1/6 * (1/20)*(1/2) * (1/20)*(1/6)) + (1/2*1/6 * (95/100)*(1/6) * (1/20)*(1/2)) + (1/2*1/6 * (95/100)*(1/6) * (95/100)*(1/6)) P(x) = Σ P(x, π | M ) = π = 0.01498148148 Checking, we see that for x = 266,
*(1/2) * (95/100)*(1/2)) + (1/2*1/10 * (95/100)*(1/2) * (1/20)*(1/6)) + (1/2*1/10 * (1/20)*(1/6) * (1/20)*(1/2)) + (1/2*1/10 * (1/20)*(1/6) * (95/100)*(1/6) ) + (1/2*1/6 * (1/20)*(1/2) * (95/100)*(1/2) ) + (1/2*1/6 * (1/20)*(1/2) * (1/20)*(1/6)) + (1/2*1/6 * (95/100)*(1/6) * (1/20)*(1/2)) + (1/2*1/6 * (95/100)*(1/6) * (95/100)*(1/6)) P(x) = Σ P(x, π | M ) = π = Checking, we see that for x = 266,")
44
Backward Algorithm: Motivation Suppose we wish to compute the probability that the i th state is k given the observed sequence of outputs x. (Notice that we would then know the density of the random variable π i.) That is, we must compute We start by computing P( π i = k | x) = P( π i = k, x) / P(x) P( π i = k, x) = P(x 1,...,x i, π i = k,x i+1,...,x n ) = P(x 1,...,x i, π i = k) · P(x i+1,...,x n | x 1,...,x i, π i = k) fk(i)fk(i)bk(i)bk(i) new!
 That is, we must compute We start by computing P( π i = k | x) = P( π i = k, x) / P(x) P( π i = k, x) = P(x 1,...,x i, π i = k,x i+1,...,x n ) = P(x 1,...,x i, π i = k) · P(x i+1,...,x n | x 1,...,x i, π i = k) fk(i)fk(i)bk(i)bk(i) new!.")
45
P( π i = k | x) = P( π i = k, x) / P(x) = f k (i)·b k (i) / P(x) So then, we have the following equation. The quantity b k (i) is called the backward probability and is defined by b k (i) = P(x i+1,...,x n | π i = k)
 is called the backward probability and is defined by b k (i) = P(x i+1,...,x n | π i = k).")
46
= Σ e j (x i+1 )·a kj ·b j (i+1) j … (proof using properties of conditional probabilities...) Recursive equation suitable for dynamic programming Can we write an equation (hopefully recursive) for b k (i)?
·a kj ·b j (i+1) j … (proof using properties of conditional probabilities...) Recursive equation suitable for dynamic programming Can we write an equation (hopefully recursive) for b k (i)")
47
1. Initialization Step. //initialize matrix b j (n) = 1 for all j > 0 2. Main Iteration. //fill in table for each i = n - 1 downto 1 for each k = 1 to K b k (i) = Σ e j (x i+1 )·a kj ·b j (i+1) 3. Termination. //recover probability of x P(x) = Σ e j ( x 1 )· b j (1)·a 0j Backward Algorithm for Evaluation Time: O(K 2 n) Space: O(Kn) j j
 = Σ e j (x i+1 )·a kj ·b j (i+1) 3. Termination. //recover probability of x P(x) = Σ e j ( x 1 )· b j (1)·a 0j Backward Algorithm for Evaluation Time: O(K 2 n) Space: O(Kn) j j.")
48
x 1 x 2 x 3 x n 1 2 K … … States b 1 (n) = 1 b K (n) = 1 b 2 (n) = 1 b k (n - 1) = Σ e j (x n )·a kj ·b j (n) j
 = 1 b K (n) = 1 b 2 (n) = 1 b k (n - 1) = Σ e j (x n )·a kj ·b j (n) j")
49
1/6*19/20*11/60+1/2*1/2 0*29/60 = 37/900 = 0.041111 1/6*19/20*1+1/2*1/20*1 = 11/60 = 0.183333 1 1/6*1/20*11/60+1/2*19/2 0*29/60 = 52/225 = 0.231111 1/6*1/20*1+1/2*19/20*1 = 29/60 = 0.483333 1 F L 2 6 6 P(x) = P(266) = 1/6*37/900*1/2 + 1/10*52/225*1/2 = 809/54000 = 0.01498148148 x = 2 6 6
 = P(266) = 1/6*37/900*1/2 + 1/10*52/225*1/2 = 809/54000 = x = 2 6 6")
50
Posterior Decoding P( π i = k | x) = P( π i = k, x) / P(x) = f k (i)·b k (i) / P(x) Now we can ask what is the most probable state at stage i. Let π i denote this state. Clearly, we have π i = argmax {P( π i = k | x)} ^ ^ Therefore, ( π 1, π 2,..., π n ) is the sequence of the most probable states. Notice that the above sequence is not (necessarily) the most probable path that the HMM went through to produce x and may not even be a valid path! There are two types of decoding for an HMM: Viterbi decoding and posterior decoding. ^^^
} ^ ^ Therefore, ( π 1, π 2,..., π n ) is the sequence of the most probable states. Notice that the above sequence is not (necessarily) the most probable path that the HMM went through to produce x and may not even be a valid path. There are two types of decoding for an HMM: Viterbi decoding and posterior decoding. ^^^.")
51
π 1 = argmax{f F (1)·b F (1)/P(x), f L (1)·b L (1)/P(x)} = argmax{1/12*37/900/(809/54000),1/20*52/225 /(809/54000)} = argmax{185/809,624/809} = argmax{0.2286773795,0.7713226205} = L ^ π 2 = argmax{f F (2)·b F (2)/P(x), f L (2)·b L (2)/P(x)} = argmax{49/3600*11/60/(809/54000),31/1200*29/60/(809/54000)} = argmax{539/3236,2697/3236} = argmax{0.1665636588,0.8334363412} = L ^
·b F (1)/P(x), f L (1)·b L (1)/P(x)} = argmax{1/12*37/900/(809/54000),1/20*52/225 /(809/54000)} = argmax{185/809,624/809} = argmax{ , } = L ^ π 2 = argmax{f F (2)·b F (2)/P(x), f L (2)·b L (2)/P(x)} = argmax{49/3600*11/60/(809/54000),31/1200*29/60/(809/54000)} = argmax{539/3236,2697/3236} = argmax{ , } = L ^")
52
π 3 = argmax{f F (3)·b F (3)/P(x), f L (3)·b L (3)/P(x)} = argmax{8/3375*1/(809/54000),227/18000*1/(809/54000)} = argmax{128/809,681/809} = argmax{0.1582200247,0.8417799753} = L ^ ( π 1, π 2, π 3 ) = (L, L, L) ^^^ The sequence of most probable states given x = 266 is
·b F (3)/P(x), f L (3)·b L (3)/P(x)} = argmax{8/3375*1/(809/54000),227/18000*1/(809/54000)} = argmax{128/809,681/809} = argmax{ , } = L ^ ( π 1, π 2, π 3 ) = (L, L, L) ^^^ The sequence of most probable states given x = 266 is")
53
f π (k | x) = P( π i = k | x) i P( π i = k | x) is the (conditional) density function of the random variable π i.
 = P( π i = k | x) i P( π i = k | x) is the (conditional) density function of the random variable π i.")
54
1. Initialization Step. V 0 (0) = 1 V 0 (j) = 0 for all j > 0 2. Main Iteration. for each i = 1 to n for each k = 1 to K V k (i) = e k (x i )·max {a jk ·V j (i-1)} Ptr k (i) = argmax {a jk ·V j (i-1)} 3. Termination. P* = max {P(x, π | M )} = max {V j (n)} π * = argmax {V j (n)} for each i = n – 1 downto 1 π * = Ptr π (i+1) Viterbi vs. Forward vs. Backward j j n i i+1 j j π 1. Initialization Step. f 0 (0) = 1 f 0 (j) = 0 for all j > 0 2. Main Iteration. for each i = 1 to n for each k = 1 to K f k (i) = e k (x i )· Σ a jk ·f j (i-1) 3. Termination. P(x) = Σ f j (n) j j 1. Initialization Step. b j (n) = 1 for all j > 0 2. Main Iteration. for each i = n - 1 downto 1 for each k = 1 to K b k (i) = Σ e j (x i+1 )·a kj ·b j (i+1) 3. Termination. P(x) = Σ e j (x 1 )·b j (1)·a 0j j j
 = e k (x i )·max {a jk ·V j (i-1)} Ptr k (i) = argmax {a jk ·V j (i-1)} 3. Termination. P* = max {P(x, π | M )} = max {V j (n)} π * = argmax {V j (n)} for each i = n – 1 downto 1 π * = Ptr π (i+1) Viterbi vs. Forward vs. Backward j j n i i+1 j j π 1. Initialization Step. f 0 (0) = 1 f 0 (j) = 0 for all j > 0 2. Main Iteration. for each i = 1 to n for each k = 1 to K f k (i) = e k (x i )· Σ a jk ·f j (i-1) 3. Termination. P(x) = Σ f j (n) j j 1. Initialization Step. b j (n) = 1 for all j > 0 2. Main Iteration. for each i = n - 1 downto 1 for each k = 1 to K b k (i) = Σ e j (x i+1 )·a kj ·b j (i+1) 3. Termination. P(x) = Σ e j (x 1 )·b j (1)·a 0j j j.")
55
Evaluation Problem (solved by Forward-Backward algorithm) GIVEN: an HMM M and a sequence x FIND: P(x | M ) Decoding Problem (solved by Viterbi algorithm) GIVEN:an HMM M and a sequence x FIND:sequence of states that maximizes P(x, | M ) Learning Problem (solved by Baum-Welch algorithm) GIVEN: a HMM M, with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) Three Fundamental Problems Done!
 GIVEN: an HMM M and a sequence x FIND: P(x | M ) Decoding Problem (solved by Viterbi algorithm) GIVEN:an HMM M and a sequence x FIND:sequence of states that maximizes P(x, | M ) Learning Problem (solved by Baum-Welch algorithm) GIVEN: a HMM M, with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) Three Fundamental Problems Done!")
56
Two Learning Scenarios Learning when states are known GIVEN: an HMM M with unspecified transition/emission probabilities, a sequence x, and a sequence π 1,..., π n FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) For example, the Dishonest Casino dealer allows an observer to view him changing dice while he produces a large number of rolls. Learning when states are unknown GIVEN: an HMM M with unspecified transition/emission probabilities and a sequence x FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) The Dishonest Casino dealer does not allow an observer to view him changing dice while he produces a large number of rolls.
, a ij ) that maximize P(x | ) The Dishonest Casino dealer does not allow an observer to view him changing dice while he produces a large number of rolls..")
57
Learning When States are Known GIVEN: an HMM M with unspecified transition/emission probabilities, a sequence x, and a sequence π 1,..., π n FIND: parameter vector = (e i (.), a ij ) that maximize P(x | ) A jk = # times there is a j → k transition in π 1,..., π n E k (b) = # times state k in π 1,..., π n emits b The following can be shown to be the maximum likelihood estimators for the parameters in θ (that is, those parameter values that maximize P(x | ). a jk = A jk Σ A ji i e k (b) = Ek(b)Ek(b) Σ Ek(c)Σ Ek(c) c ^^
 = Ek(b)Ek(b) Σ Ek(c)Σ Ek(c) c ^^.")
58
300 rolls by the casino = 262/(262 + 6) = 0.9776 a FF = A FF ^ A FF + A FL = 6/(262 + 6) = 0.0224 a FL = A FL ^ A FF + A FL e L (6) = E L (6) Σ EL(c)Σ EL(c) c ^ = 54/95 = 0.5684 e L (1) = E L (1) Σ EL(c)Σ EL(c) c ^ = 8/95 = 0.0842
 = a FF = A FF ^ A FF + A FL = 6/( ) = a FL = A FL ^ A FF + A FL e L (6) = E L (6) Σ EL(c)Σ EL(c) c ^ = 54/95 = e L (1) = E L (1) Σ EL(c)Σ EL(c) c ^ = 8/95 =")
59
Problem of ‘Overfitting’ a FF = 1, a FL = 0, a LL = und., a LF = und. e F (1) = e F (3) = 0.2 e F (2) = 0.3, e F (4) = 0, e F (5) = 0.1, e F (6) = 0.2 x= 2156123623 π = FFFFFFFFFF P(x | ) is maximized, but is unreasonable! More data is needed to derive sensible parameter values or, as an alternative, pseudocounts can be used. ^^^^ ^^ ^^^^
 = e F (3) = 0.2 e F (2) = 0.3, e F (4) = 0, e F (5) = 0.1, e F (6) = 0.2 x= π = FFFFFFFFFF P(x | ) is maximized, but is unreasonable. More data is needed to derive sensible parameter values or, as an alternative, pseudocounts can be used. ^^^^ ^^ ^^^^.")
60
Learning When States are Unknown GIVEN: an HMM M with unspecified transition/emission probabilities and a sequence x (the values of A jk and E k (b) cannot be computed since π 1,..., π n are unknown) FIND: parameter vector = (e i (.), a ij ) that maximizes P(x | ) STEP 1: Estimate our ‘best guess’ on what A jk and E k (b) should be STEP 2: Update the parameters of the model based on our guess Repeat STEPS 1 and 2 until convergence of P(x | θ)
 cannot be computed since π 1,..., π n are unknown) FIND: parameter vector = (e i (.), a ij ) that maximizes P(x | ) STEP 1: Estimate our ‘best guess’ on what A jk and E k (b) should be STEP 2: Update the parameters of the model based on our guess Repeat STEPS 1 and 2 until convergence of P(x | θ)")
61
How do we update the current parameters of the model?... Assume that θ curr represents the current estimates of the HMM parameters. We will derive the new estimate of A jk (as an example). First, at each state j, find the probability that j → k transition is used. Assume that θ curr appears in the appropriate places in the formulas below. P( π i = j, π i+1 = k | x) = P( π i = j, π i+1 = k, x 1,...,x n ) / P(x) = P(x 1,...,x i, π i = j, π i+1 = k, x i+1,...,x n ) / P(x) = P( π i+1 = k, x i+1,...,x n | π i = j )·P(x 1,...,x i π i = j) / P(x) = P( π i+1 = k, x i+1,x i+2...,x n | π i = j )·f j (i) / P(x) = P(x i+2...,x n | π i+1 = k)·P(x i+1 | π i+1 = k )·P( π i+1 = k | π i = j)·f j (i) / P(x) = b k (i+1)·e k (x i+1 )·a jk ·f j (i) / P(x)
. First, at each state j, find the probability that j → k transition is used. Assume that θ curr appears in the appropriate places in the formulas below. P( π i = j, π i+1 = k | x) = P( π i = j, π i+1 = k, x 1,...,x n ) / P(x) = P(x 1,...,x i, π i = j, π i+1 = k, x i+1,...,x n ) / P(x) = P( π i+1 = k, x i+1,...,x n | π i = j )·P(x 1,...,x i π i = j) / P(x) = P( π i+1 = k, x i+1,x i+2...,x n | π i = j )·f j (i) / P(x) = P(x i+2...,x n | π i+1 = k)·P(x i+1 | π i+1 = k )·P( π i+1 = k | π i = j)·f j (i) / P(x) = b k (i+1)·e k (x i+1 )·a jk ·f j (i) / P(x).")
62
jk x i+1 a jk e k (x i+1 ) b k (i+1) fj(i)fj(i) x 1,...,x i-1 xixi x i+2,...,x n P(x)P(x)
 b k (i+1) fj(i)fj(i) x 1,...,x i-1 xixi x i+2,...,x n P(x)P(x)")
63
So, we have derived a formula for the probability of a j → k transition from stage i to stage i+1 given the output x and the current values of the parameters. So, the new value of A jk (expected number of j → k transitions) can be found as P( π i = j, π i+1 = k | x, θ curr ) = b k (i+1)·e k (x i+1 )·a jk ·f j (i) / P(x | θ curr ) A jk = P( π i = j, π i+1 = k | x, θ curr ) = b k (i+1)·e k (x i+1 )·a jk ·f j (i) / P(x | θ curr ) Σ i Σ i
 can be found as P( π i = j, π i+1 = k | x, θ curr ) = b k (i+1)·e k (x i+1 )·a jk ·f j (i) / P(x | θ curr ) A jk = P( π i = j, π i+1 = k | x, θ curr ) = b k (i+1)·e k (x i+1 )·a jk ·f j (i) / P(x | θ curr ) Σ i Σ i.")
64
In a similar way, E k (b) = b k (i)·f k (i) / P(x | θ curr ) Σ i, x i = b a jk = A jk Σ A ji i e k (b) = Ek(b)Ek(b) Σ Ek(c)Σ Ek(c) c ^^ To obtain new (updated) values for the parameters of the HMM, we normalize as before. Recall that

65
The Baum-Welch algorithm is normally applied to an entire group of sequences that are assumed to have been generated independently by the model. Typically, training sequences are collected over a period of time. Let x 1, x 2,..., x r be r sequences of length n 1, n 2,..., n r. x 1 x 1...x 1 12 n1n1 x 2 x 2...x 2 12 n2n2 x 1 = x 2 =...... x r x r...x r 1 2nrnr x r = Training Sequences for the Baum-Welch Algorithm Training sequences

66
1. Initialization Step. //initialize parameters Pick the initial guess θ curr for model parameters (or arbitrary) 2. Main Iteration. //refine model parameters by iteration repeat for each training sequence perform the Forward Algorithm perform the Backward Algorithm calculate the A jk and E k (b) given θ curr and using all the training sequences x 1, x 2,..., x r calculate new model parameters θ new : a jk and e k (b) calculate P(x 1, x 2,..., x r | θ new ) //theory guarantees that value will increase; note that P(x 1, x 2,..., x r | θ new ) = P(x 1 | θ new )·P(x 2 | θ new )·... · P(x r | θ new ) by independence until (P(x 1, x 2,..., x r | θ new )) does not change much) 3. Termination. return θ new as the parameter values Baum-Welch Algorithm Time: O(K 2 n)/interation Space: O(Kn)
 2. Main Iteration. //refine model parameters by iteration repeat for each training sequence perform the Forward Algorithm perform the Backward Algorithm calculate the A jk and E k (b) given θ curr and using all the training sequences x 1, x 2,..., x r calculate new model parameters θ new : a jk and e k (b) calculate P(x 1, x 2,..., x r | θ new ) //theory guarantees that value will increase; note that P(x 1, x 2,..., x r | θ new ) = P(x 1 | θ new )·P(x 2 | θ new )·... · P(x r | θ new ) by independence until (P(x 1, x 2,..., x r | θ new )) does not change much) 3. Termination. return θ new as the parameter values Baum-Welch Algorithm Time: O(K 2 n)/interation Space: O(Kn).")
67
Baum-Welch Algorithm Example 1 2 EB 1/2 0 0 0 1 1 0 x 1 = ABA x 2 = ABB x 3 = AB e 1 (A) = 1/4 e 1 (B) = 3/4 e 2 (A) = 1/2 e 2 (B) = 1/2
 = 1/4 e 1 (B) = 3/4 e 2 (A) = 1/2 e 2 (B) = 1/2")
68
Iteration #1 The Forward and Backward probability tables must be computed for each of the training sequences! 1/43/323/256 01/163/128 x 1 = ABA A B A 1212 Forward Probabilities P(x 1 ) = (0)(3/256) + (1)(3/128) = 3/128
 = (0)(3/256) + (1)(3/128) = 3/128.")
69
3/321/40 001 x 1 = ABA A B A 1212 Backward Probabilities P(x 1 ) = (1/4)(3/32)(1) + (1/2)(0)(0) = 3/128
 = (1/4)(3/32)(1) + (1/2)(0)(0) = 3/128")
70
1/43/329/256 01/163/128 x 2 = ABB A B B 1212 Forward Probabilities P(x 2 ) = (3/128)(1) + (9/256)(0)
 = (3/128)(1) + (9/256)(0)")
71
3/321/40 001 x 2 = ABB A B B 1212 Backward Probabilites P(x 2 ) = (1/4)(3/32)(1) + (1/2)(0)(0) = 3/128
 = (1/4)(3/32)(1) + (1/2)(0)(0) = 3/128")
72
1/43/32 01/16 x 3 = AB A B 1212 Forward Probabilites P(x 3 ) = (1/16)(1) + (3/32)(0)
 = (1/16)(1) + (3/32)(0)")
73
1/40 01 x 3 = AB A B 1212 Backward Probabilities P(x 3 ) = (1/4)(1/4)(1) + (1/2)(0)(0) = 1/16
 = (1/4)(1/4)(1) + (1/2)(0)(0) = 1/16")
74
All the expected number of transition values must be computed. A 12 = f 1 (1)·a 12 ·e 2 (B)·b 2 (2) + f 1 (2)·a 12 ·e 2 (A)·b 2 (3) P(x1)P(x1) (1/4)·(1/2)·(1/2)·(0) + (3/32)·(1/2)·(1/2)·(1) f 1 (1)·a 12 ·e 2 (B)·b 2 (2) + f 1 (2)·a 12 ·e 2 (B)·b 2 (3) P(x2)P(x2) f 1 (1)·a 12 ·e 2 (B)·b 2 (2) P(x3)P(x3) + + = 3/128 (1/4)·(1/2)·(1/2)·(0) + (3/32)·(1/2)·(1/2)·(1) 3/128 ++ (1/4)·(1/2)·(1/2)·(1) 1/16 = 3 Likewise, A 11 = 2, A 21 = 0 = A 22.
·a 12 ·e 2 (B)·b 2 (2) + f 1 (2)·a 12 ·e 2 (A)·b 2 (3) P(x1)P(x1) (1/4)·(1/2)·(1/2)·(0) + (3/32)·(1/2)·(1/2)·(1) f 1 (1)·a 12 ·e 2 (B)·b 2 (2) + f 1 (2)·a 12 ·e 2 (B)·b 2 (3) P(x2)P(x2) f 1 (1)·a 12 ·e 2 (B)·b 2 (2) P(x3)P(x3) + + = 3/128 (1/4)·(1/2)·(1/2)·(0) + (3/32)·(1/2)·(1/2)·(1) 3/ (1/4)·(1/2)·(1/2)·(1) 1/16 = 3 Likewise, A 11 = 2, A 21 = 0 = A 22..")
75
A B 1 = a B 1 ·e 1 (A)·b 1 (1) P(x1)P(x1) P(x2)P(x2) P(x3)P(x3) ++ = (1)·(1/4)·(3/32) 3/128 (1)·(1/4)·(3/32) 3/128 (1)·(1/4)·(1/4) 1/16 ++ Computations for the states B and E must be adjusted accordingly. = 3 A 2 E = f 2 (3)·a 2 E P(x1)P(x1) P(x2)P(x2) f 2 (2)·a 2 E P(x3)P(x3) ++ = (3/128)·(1) 3/128 (3/128)·(1) 3/128 (1/16)·(1) 1/16 ++ = 3 Likewise, A 1 E = 0 = A B 2.
·a 2 E P(x1)P(x1) P(x2)P(x2) f 2 (2)·a 2 E P(x3)P(x3) ++ = (3/128)·(1) 3/128 (3/128)·(1) 3/128 (1/16)·(1) 1/16 ++ = 3 Likewise, A 1 E = 0 = A B 2..")
76
All the expected number of emission values must be computed. E 1 (A) = f 1 (1)·b 1 (1) + f 1 (3)·b 1 (3) P(x1)P(x1) f 1 (1)·b 1 (1) P(x2)P(x2) + P(x3)P(x3) + = (1/4)·(3/32) + (3/256)·(0) 3/128 (1/4)·(3/32) 3/128 (1/4)·(1/4) 1/16 ++ = 3 Likewise, E 1 (B) = 2, E 2 (A) = 1, E 2 (B) = 2.
 = f 1 (1)·b 1 (1) + f 1 (3)·b 1 (3) P(x1)P(x1) f 1 (1)·b 1 (1) P(x2)P(x2) + P(x3)P(x3) + = (1/4)·(3/32) + (3/256)·(0) 3/128 (1/4)·(3/32) 3/128 (1/4)·(1/4) 1/16 ++ = 3 Likewise, E 1 (B) = 2, E 2 (A) = 1, E 2 (B) = 2..")
77
Finally, all the new parameter values must be computed. a 12 = ^ A 12 A 11 + A 12 + A 1 E 3 2 + 3 + 0 = 3 5 = a 12 = ^ 3 5 a 11 = ^ 2 5 a 1 E = 0 ^ a 21 = 0 ^ a 22 = 0 ^ a 2 E = 1 ^ a B 1 = 1 ^ a B 2 = 0 ^ Similar computations yield the following new transition probabilities.

78
e 1 (A) = E 1 (A) E 1 (A) + E 1 (B) 3 3 + 2 = 3 5 = e 1 (A) = 2 5 e 1 (B) = 1 3 e 2 (A) = 2 3 e 2 (B) = ^^ ^^ 3 5 Similar computations yield the following new emission probabilities.
 = E 1 (A) E 1 (A) + E 1 (B) = 3 5 = e 1 (A) = 2 5 e 1 (B) = 1 3 e 2 (A) = 2 3 e 2 (B) = ^^ ^^ 3 5 Similar computations yield the following new emission probabilities.")
79
1 2 EB 2/5 0 3/50 0 1 1 0 x 1 = ABA x 2 = ABB x 3 = AB e 1 (A) = 3/5 e 1 (B) = 2/5 e 2 (A) = 1/3 e 2 (B) = 2/3
 = 3/5 e 1 (B) = 2/5 e 2 (A) = 1/3 e 2 (B) = 2/3")
80
Iteration #2 The Forward and Backward probability tables must be computed for each of the training sequences! Only the Forward probabilities will be computed this time. 3/512/12572/3125 06/2512/625 x 1 = ABA A B A 1212 Forward Probabilities P(x 1 ) = (0)(72/3125) + (1)(12/625) = 12/625
 = (0)(72/3125) + (1)(12/625) = 12/625.")
81
3/512/12548/3125 06/2524/625 x 2 = ABB A B B 1212 Forward Probabilities P(x 2 ) = (1)(24/625) + (0)(48/3125)
 = (1)(24/625) + (0)(48/3125)")
82
3/512/125 06/25 x 3 = AB A B 1212 Forward Probabilities P(x 3 ) = (1)(6/25) + (0)(12/125)
 = (1)(6/25) + (0)(12/125)")
83
Iteration #1 P(x 1 )·P(x 2 )·P(x 3 ) = (3/128)·(3/128)·(1/16) = 9/262144 =.0000343 Iteration #2 P(x 1 )·P(x 2 )·P(x 3 ) = (12/625)·(24/625)·(6/25) = 1728/9765625 =.0001769 Probability has increased!
·P(x 2 )·P(x 3 ) = (3/128)·(3/128)·(1/16) = 9/ = Iteration #2 P(x 1 )·P(x 2 )·P(x 3 ) = (12/625)·(24/625)·(6/25) = 1728/ = Probability has increased!")
84
A Modeling Example: CpG Islands in DNA Sequence A+C+G+T+ A-C-G-T-

85
What are CpG islands and why are they important? The frequency of the four nucleotides A, T, C, and G are fairly stable across the human genome: A ≈ 29.5%, C ≈ 20.4%, T ≈ 20.5%, and G ≈ 29.6%. Frequencies of dinucleotides (that is, nucleotide pairs) vary widely across the human genome. CG pairs are typically underrepresented. This is because CG pairs often mutate to TG, and so the frequency of CG pairs is less than 1/16. In fact, the CG pair is the least frequent dinucleotide since the C in the CG pair is easily methylated (a mythyl CH 3 “joins” the cytosine), then the methyl- C has the tendency to mutate to a T over the course of evolution by a process called deamination. CG pairs tend to mutate to TG pairs. Methylation is suppressed around genes in a genome, and so CpG dinucleotides occur at greater frequencies in and around genes. These high-frequency stretches of DNA are called CpG (or simply CG ) islands. (The ‘ p ’ stands for the phosphodiester bond between the C and G nucleotide to emphasize that the C and G are on the same strand of DNA and are not a base pair.)
 vary widely across the human genome. CG pairs are typically underrepresented. This is because CG pairs often mutate to TG, and so the frequency of CG pairs is less than 1/16. In fact, the CG pair is the least frequent dinucleotide since the C in the CG pair is easily methylated (a mythyl CH 3 joins the cytosine), then the methyl- C has the tendency to mutate to a T over the course of evolution by a process called deamination. CG pairs tend to mutate to TG pairs. Methylation is suppressed around genes in a genome, and so CpG dinucleotides occur at greater frequencies in and around genes. These high-frequency stretches of DNA are called CpG (or simply CG ) islands. (The ‘ p ’ stands for the phosphodiester bond between the C and G nucleotide to emphasize that the C and G are on the same strand of DNA and are not a base pair.).")
86
CpG Islands & Genes Gene 5’ end Gene promoter CpG islands CpG islands in body Gene 3’ end CpG islands CpG island Gene Finding CpG islands is an important problem!

87
Model of CpG Islands: Architecture A+C+G+T+ A-C-G-T- + : in a CpG island - : not in a CpG island

88
Model of CpG Islands: Transitions + ACGT A.180.274.426.120 C.171.368.274.188 G.161.339.375.125 T.079.355.384.182 - ACGT A.300.205.285.210 C.322.298.078.302 G.248.246.298.208 T.177.239.292 Transition probabilities within CpG islands; emission probability = 1/0, e.g., e A + ( A ) = 1, e A + ( C, G, T ) = 0 Tables below were established from many known (experimentally verified) CpG islands and known non- CpG islands (called training sequences). =1 Note: Transitions out of each state add up to one. There is no room for transitions between (+) and (-) states! What do we do?... Transition probabilities within non- CpG islands; emission probability = 1/0, e.g., e A - ( A ) = 1, e A - ( C, G, T ) = 0
 and (-) states. What do we do ... Transition probabilities within non- CpG islands; emission probability = 1/0, e.g., e A - ( A ) = 1, e A - ( C, G, T ) = 0.")
89
Model of CpG Islands: Transitions (cont.) What about the transitions between the + and – states? Certainly there is a probability (say) p of staying in a CpG island and a probability (say) q of staying in a non- CpG island. A+C+G+T+ A-C-G-T- 1 - p p 1 - q q
 p of staying in a CpG island and a probability (say) q of staying in a non- CpG island. A+C+G+T+ A-C-G-T- 1 - p p 1 - q q.")
90
Model of CpG Islands: Transitions (cont.) To estimate the remaining probabilities, use the following steps. Step 1: Adjust all probabilities by a factor of p or q. For example, a A + C + ← a A + C + · p, a A - C - ← a A - C - · q, etc. Step 2: Calculate all the probabilities between the + states and the – states. Step 2.1: Let f A -, f C -, f G -, and f T - be the frequency of A, C, G, and T among the non- CpG nucleotides in the training sequence. Step 2.2: Let a A + A - ← f A - · (1 – p), a A + C - ← f C - · (1 – p), etc. Do the same for the – to + states. Step 3: Estimate the probabilities p and q. But how?...
, a A + C - ← f C - · (1 – p), etc. Do the same for the – to + states. Step 3: Estimate the probabilities p and q. But how ....")
91
Geometric Distribution A random variable X is said to be geometrically distributed if it has a density given by f X (x) = p·(1 – p) x-1, x = 1,2,... p is the probability of a success in a series of Bernoulli trials. The random variable X counts the number of trials up to and including the first success. The expected value and variance of X are easy to remember! E(X) = 1/p Var(X) = (1 – p)/p 2
 = 1/p Var(X) = (1 – p)/p 2.")
92
Model of CpG Islands: Transitions (cont.) Let L + denote the length in nucleotides of a CpG island. L + is a random variable, and one approach is to model L + as a geometric random variable (controversial since CpG islands may not have an exponential-length distribution in the genome under study). P(L + = 1) = 1 – p (leaving is considered a success!) P(L + = 2) = p(1 – p) P(L + = 3) = p 2 (1 – p) P(L + = k) = p k-1 (1 – p) The expected value of L + is E(L + ) = 1/(1 – p). Similarly, E(L - ) = 1/(1 – q) where L - is the length in nucleotides of a non- CpG island. From the training data, compute the average length of a CpG island, and then set that number equal to E(L + ) = 1/(1 – p), and solve for p. Do the same for non- CpG islands. For example, if the average length of a CpG island is 300, then p = 299/300. …
. P(L + = 1) = 1 – p (leaving is considered a success!) P(L + = 2) = p(1 – p) P(L + = 3) = p 2 (1 – p) P(L + = k) = p k-1 (1 – p) The expected value of L + is E(L + ) = 1/(1 – p). Similarly, E(L - ) = 1/(1 – q) where L - is the length in nucleotides of a non- CpG island. From the training data, compute the average length of a CpG island, and then set that number equal to E(L + ) = 1/(1 – p), and solve for p. Do the same for non- CpG islands. For example, if the average length of a CpG island is 300, then p = 299/300. ….")
93
Duration Modeling in Hidden Markov Models Length distribution of introns and exons show considerable variation.

94
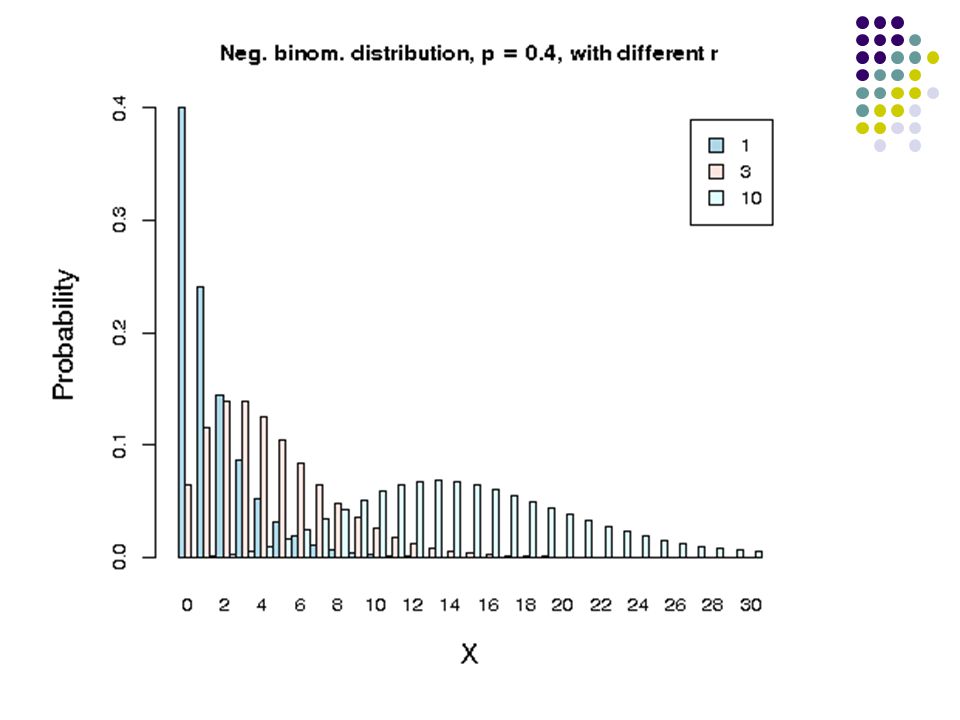
k (1) k (2) k (n-1) k(n)k(n) pp pp 1-p n copies of state k Negative Binomial Distribution The shortest sequence through the states that can be modeled has length n. Let D denote the duration of state k. (Clearly, D is at least n.) Note that D has a negative binomial distribution with parameters 1 – p (probability of a success) and n (number of successes needed). j 1-p... P(D = L) = L-1 n-1 (1-p) n pL-npL-n
 Note that D has a negative binomial distribution with parameters 1 – p (probability of a success) and n (number of successes needed). j 1-p... P(D = L) = L-1 n-1 (1-p) n pL-npL-n.")
96
Model of CpG Islands: Applications A+C+G+T+ A-C-G-T- So what is it good for?

97
Viterbi Decoding: Given a long strand of DNA, we can decode it using the model! ATCGTTAGCTACCGACC... A-T-C-G-T-T-A-G+C+T+A+C+C+G+A+C+C+... CpG island Viterbi decoding For Example...

98
Posterior Decoding: Given a long strand of DNA, we can derive the probability distribution of a given position. ATCGTTAGCTACCGACC... posterior decoding i th position f π (k) = P( π i = k | x) i
 = P( π i = k | x) i.")
99
What if a new genome comes along...? Porcupine

100
We just sequenced the porcupine genome We know CpG islands play the same role in this genome. That is, they signal the occurrence of a gene. However, we have no known CpG islands for porcupines. We suspect the frequency and characteristics of CpG islands are quite different in porcupines and humans. What do we do...?

101
Alignment Penalties Revisited: Affine Gap Penalties If, for example n ≥ m, then the time needed to run the algorithm is O(n 2 m). A compromise between general convex gap penalties and linear gap penalties is the affine gap penalty. In the following discussion, we assume that a deletion will not be followed directly by an insertion. That is, Ix and Iy can not jump between each other. d is the gap opening penalty and e is the gap extension penalty. For affine gap penalties, there is an implementation of the N-W algorithm that runs in O(nm) time like the original algorithm. γ(n) = d + (n – 1)e d e (n)(n)
 time like the original algorithm. γ(n) = d + (n – 1)e d e (n)(n).")
102
1. x i is aligned to y j x 1...x i-1 x i y 1...y j-1 y j 2. x i is aligned to a gap x 1...x i-2 x i-1 x i y 1...y j - - 3. y j is aligned to a gap x 1...x i - - - y 1...y j-3 y j-2 y j-1 y j Updating the Score (cont.) Updating the score is complicated by the fact that gaps are not assessed the same penalty. Opening a gap is penalized more (typically a lot more!) than extending a group of gaps. Keeping one value, F(i,j) does not suffice! M(i,j) = optimal score aligning x 1 x 2...x i to y 1 y 2 …y j given x i is aligned to y j I x (i,j) = optimal score aligning x 1 x 2...x i to y 1 y 2 …y j given x i is aligned to a gap I y (i,j) = optimal score aligning x 1 x 2...x i to y 1 y 2 …y j given y j is aligned to a gap
 Updating the score is complicated by the fact that gaps are not assessed the same penalty. Opening a gap is penalized more (typically a lot more!) than extending a group of gaps. Keeping one value, F(i,j) does not suffice. M(i,j) = optimal score aligning x 1 x 2...x i to y 1 y 2 …y j given x i is aligned to y j I x (i,j) = optimal score aligning x 1 x 2...x i to y 1 y 2 …y j given x i is aligned to a gap I y (i,j) = optimal score aligning x 1 x 2...x i to y 1 y 2 …y j given y j is aligned to a gap.")
103
1. x i is aligned to y j x 1...x i-1 x i y 1...y j-1 y j 2. x i is aligned to a gap x 1...x i-2 x i-1 x i y 1...y j - - 3. y j is aligned to a gap x 1...x i - - - y 1...y j-3 y j-2 y j-1 y j M(i - 1,j - 1) + m, if x i = y j M(i - 1,j - 1) - s, if x i ≠ y j I x (i - 1,j - 1) + m, if x i = y j I x (i - 1,j - 1) - s, if x i ≠ y j I y (i - 1,j - 1) - m, if x i = y j I y (i - 1,j - 1) - s, if x i ≠ y j M(i,j) = max M(i - 1,j) – d (opening) I x (i - 1,j) – e (extending) I x (i,j) = max M(i,j - 1) – d (opening) I y (i,j - 1) – e (extending) I y (i,j) = max Updating the Score (cont.) Now we assume that I x and I y can not jump between each other.
 + m, if x i = y j M(i - 1,j - 1) - s, if x i ≠ y j I x (i - 1,j - 1) + m, if x i = y j I x (i - 1,j - 1) - s, if x i ≠ y j I y (i - 1,j - 1) - m, if x i = y j I y (i - 1,j - 1) - s, if x i ≠ y j M(i,j) = max M(i - 1,j) – d (opening) I x (i - 1,j) – e (extending) I x (i,j) = max M(i,j - 1) – d (opening) I y (i,j - 1) – e (extending) I y (i,j) = max Updating the Score (cont.) Now we assume that I x and I y can not jump between each other..")
104
HMMs for Sequence Alignment M Δ(+1,+1) I y Δ(0,+1) I x Δ(+1,0) Δ(i,j) = change in indices when the state is entered
 I y Δ(0,+1) I x Δ(+1,0) Δ(i,j) = change in indices when the state is entered")
105
Needleman-Wunsch Algorithm With Affine Gap Penalties (FSA Representation) The recursive equations of dynamic programming have an elegant representation as a finite-state automaton (FSA). A finite state machine (FSM) or finite state automaton (plural: automata), or simply a state machine, is a model of behavior composed of a finite number of states, transitions between those states, and actions. The new value of the state variable at indices (i,j) is the maximum of the scores corresponding to the transitions coming into the state. Each transition score is given by the values of the source state at the offsets specified by the Δ(i,j) of the target state, plus the specified score increment. This type of representation corresponds to a finite-state automaton (FSA) common in computer science.
 or finite state automaton (plural: automata), or simply a state machine, is a model of behavior composed of a finite number of states, transitions between those states, and actions. The new value of the state variable at indices (i,j) is the maximum of the scores corresponding to the transitions coming into the state. Each transition score is given by the values of the source state at the offsets specified by the Δ(i,j) of the target state, plus the specified score increment. This type of representation corresponds to a finite-state automaton (FSA) common in computer science..")
106
An alignment corresponds to a path through the states, with symbols from the underlying pair of sequences being transferred to the alignment according to the Δ(i,j) values in the states. MM IxIx IxIx M M IyIy M x = V L S P A D K y = H L A E S K Consider the alignment x = V L S P A D - K y = H L - - A E S K

107
Pair HMMs We would like to transform the FSA for the Needleman-Wunsch affine gap penalty algorithm into a HMM. Why? The HMM methods allow us to use the resulting probabilistic model to explore questions about the reliability of the alignment obtained by dynamic programming, and to explore alternative (suboptimal) alignments. By weighting all alternatives probabilistically, we will be able to score the similarity of two sequences independent of any specific alignment. We can also build more specialized probabilistic models out of simple pieces, to model more complex versions of sequence alignment. How? Two issues need to be resolved. Emission probabilities and transition probabilities must be established. We will keep the parameters arbitrary. The model must be fitted to training data to estimate the parameter values.
 alignments. By weighting all alternatives probabilistically, we will be able to score the similarity of two sequences independent of any specific alignment. We can also build more specialized probabilistic models out of simple pieces, to model more complex versions of sequence alignment. How. Two issues need to be resolved. Emission probabilities and transition probabilities must be established. We will keep the parameters arbitrary. The model must be fitted to training data to estimate the parameter values..")
108
Probabilistic Model M p x y IxpxIxpx IypyIypy δ ε i i j j δε 1- ε 1 - 2δ Something is missing...a begin and end state!

109
M p x y IxpxIxpx IypyIypy δ ε i i j j δε 1- ε - τ 1 - 2δ - τ E ττ τ B τ δδ Pair HMM With Begin and End States

110
MM IxIx IxIx M M IyIy M x = V y = H x = V L S P A D K y = H L A E S K LLLL S-S- P-P- AAAA DEDE -S-S KKKK Probability of an Alignment P = (1 – 2δ – τ )·p VH · (1 – 2δ – τ )·p LL ·δ·pS·δ·pS ·ε·pP·ε·pP · (1 – ε – τ )·p AA · (1 – 2δ – τ )·p DE ·δ·pS·δ·pS · (1 – ε – τ )·p KK · τ
·p VH · (1 – 2δ – τ )·p LL ·δ·pS·δ·pS ·ε·pP·ε·pP · (1 – ε – τ )·p AA · (1 – 2δ – τ )·p DE ·δ·pS·δ·pS · (1 – ε – τ )·p KK · τ")
111
What is the most probable alignment?...Use Viterbi! All the algorithms we have seen for HMMs apply, for example, the Viterbi algorithm, forward-backward, etc. There is an extra dimension in the search space because of the extra emitted sequence Instead of using V k (i), we will use V k (i,j), because an observation of x i does not necessarily mean an observation of y j Imagine we have two clocks, one for the sequence x and one for the sequence y that work differently in different time zones V k (i,j) can only advance in certain ways 1.In time zone M, both i and j advance 2.In time zone I x, only i advances 3.In time zone I y, only j advances
, we will use V k (i,j), because an observation of x i does not necessarily mean an observation of y j Imagine we have two clocks, one for the sequence x and one for the sequence y that work differently in different time zones V k (i,j) can only advance in certain ways 1.In time zone M, both i and j advance 2.In time zone I x, only i advances 3.In time zone I y, only j advances.")
112
1. Initialization Step. //initialize three matrices V M (0,0) = 1, V M (i,0) = V M (0,j) = 0 for i, j > 0 V X (0,0) = 0, V X (i,0) = V X (0,j) = 0 for i, j > 0 V Y (0,0) = 0, V Y (i,0) = V Y (0,j) = 0 for i, j > 0 2. Main Iteration. //fill in three tables for each i = 1 to m for each j = 1 to n V M (i,j) = p x y ·max {( 1 – 2δ – τ )·V M (i-1,j-1), ( 1 – ε – τ )·V X (i-1,j-1), ( 1 – ε – τ )·V Y (i-1,j-1 } V X (i,j) = p x ·max { δ ·V M (i-1,j), ε ·V X (i-1,j)} V Y (i,j) = p y ·max { δ ·V M (i,j-1), ε ·V Y (i,j-1)} //keep pointers so that the most probable alignment can be reconstructed Viterbi Algorithm for Decoding a Pair HMM Time: O(mn) Space: O(mn) i j j i
 = 1, V M (i,0) = V M (0,j) = 0 for i, j > 0 V X (0,0) = 0, V X (i,0) = V X (0,j) = 0 for i, j > 0 V Y (0,0) = 0, V Y (i,0) = V Y (0,j) = 0 for i, j > 0 2. Main Iteration. //fill in three tables for each i = 1 to m for each j = 1 to n V M (i,j) = p x y ·max {( 1 – 2δ – τ )·V M (i-1,j-1), ( 1 – ε – τ )·V X (i-1,j-1), ( 1 – ε – τ )·V Y (i-1,j-1 } V X (i,j) = p x ·max { δ ·V M (i-1,j), ε ·V X (i-1,j)} V Y (i,j) = p y ·max { δ ·V M (i,j-1), ε ·V Y (i,j-1)} //keep pointers so that the most probable alignment can be reconstructed Viterbi Algorithm for Decoding a Pair HMM Time: O(mn) Space: O(mn) i j j i.")
113
3. Termination. //recover optimal probability and path P* = τ ·max { V M (m,n), V X (m,n), V Y (m,n)} //use pointers to reconstruct the most probable alignment Remark With the initialization conditions of the Viterbi algorithm for the pair HMM as suggested above (Durbin et al., 1998, p 84), the resulting alignment of two sequences will always start with a matched pair x 1, y 1 for any two sequences x and y. Hence the alignment generated by a pair HMM with such a restriction on the initialization step may not be the optimal one. Question How to change the initialization condition to allow for alignments starting with a gap aligned to a letter in x or y?
, V X (m,n), V Y (m,n)} //use pointers to reconstruct the most probable alignment Remark With the initialization conditions of the Viterbi algorithm for the pair HMM as suggested above (Durbin et al., 1998, p 84), the resulting alignment of two sequences will always start with a matched pair x 1, y 1 for any two sequences x and y. Hence the alignment generated by a pair HMM with such a restriction on the initialization step may not be the optimal one. Question How to change the initialization condition to allow for alignments starting with a gap aligned to a letter in x or y .")
114
Optimal log-odds alignment In log-odds terms, we can compute in terms of an additive model with log-odds emission scores and log-odds transition scores. In practice, this is normally the most practical way to implement pair HMM. It is possible to merge the emission scores with the transitions as to produce scores that correspond to the standard terms used in sequence alignment by dynamic programming.

115
Example: Pair HMM Example: Pair HMM The Pair HMM shown on Slide 109 generates two aligned DNA sequences x and y. State M emits aligned pairs of nucleotides with emission probabilities defined as follows: P TT = P CC = P AA = P GG = 0.5, P CT = P AG = 0.05, P AT = P GC = 0.3, P GT = P AC = 0.15. The insert states X and Y emit (aligned with gaps) symbols from sequences x and y, respectively. The emission probabilities are the same for both insert states: p A = p C = p G = p T = 0.25 No symbols are emitted by begin and end states. The values of other parameters are as follows:
 symbols from sequences x and y, respectively. The emission probabilities are the same for both insert states: p A = p C = p G = p T = 0.25 No symbols are emitted by begin and end states. The values of other parameters are as follows:.")
116
Pair HMM: Viterbi Now consider the Viterbi algorithm to find the optimal alignment of DNA sequences x = TAG and y = TTACG. Answer: V M (0,0) = 1, V M (i,0) = V M (0,j) = 0 for i, j > 0 V X (0,0) = 0, V X (i,0) = V X (0,j) = 0 for i, j > 0 V Y (0,0) = 0, V Y (i,0) = V Y (0,j) = 0 for i, j > 0 We start calculations as follows: and continue by using equations on slide112, filling the computed probability values in the cells of the V matrix (next slide). At the termination step we have: The traceback through the V matrix determines the optimal path : which corresponds to the alignment T T A C G T - A - G
 = 1, V M (i,0) = V M (0,j) = 0 for i, j > 0 V X (0,0) = 0, V X (i,0) = V X (0,j) = 0 for i, j > 0 V Y (0,0) = 0, V Y (i,0) = V Y (0,j) = 0 for i, j > 0 We start calculations as follows: and continue by using equations on slide112, filling the computed probability values in the cells of the V matrix (next slide). At the termination step we have: The traceback through the V matrix determines the optimal path : which corresponds to the alignment T T A C G T - A - G.")
117
j=0 j=1 j=2 j=3 j=4 j=5 V(i,j) - T T A C G i=0 - 1 0.0000000 0.000000 0.0000000 0.000e+00 0.000e+00 - 0 0.0000000 0.000000 0.0000000 0.000e+00 0.000e+00 i=1 T 0 0.2500000 0.000000 0.0000000 0.000e+00 0.000e+00 T 0 0.0000000 0.000000 0.0000000 0.000e+00 0.000e+00 T 0 0.0000000 0.012500 0.0003125 7.813e-06 1.953e-07 i=2 A 0 0.0000000 0.037500 0.0050000 3.750e-05 3.125e-07 A 0 0.0125000 0.000000 0.0000000 0.000e+00 0.000e+00 A 0 0.0000000 0.000000 0.0018750 2.500e-04 6.250e-06 i=3 G 0 0.0000000 0.001500 0.0009375 7.500e-04 1.000e-04 G 0 0.0003125 0.001875 0.0002500 1.875e-06 1.563e-08 G 0 0.0000000 0.000000 0.0000750 4.688e-05 3.750e-05 The matrix of probability values V(i,j) determined by the Viterbi algorithm. Each cell (i,j) contains three values, V M (i,j), V X (i,j) and V Y (i,j), written in top down order. Entries on the optimal path are shown in red bold.
 contains three values, V M (i,j), V X (i,j) and V Y (i,j), written in top down order. Entries on the optimal path are shown in red bold..")
118
Pair HMM: Forward Now find P(x,y) for DNA sequences x = TAG and y = TTACG using the forward algorithm. Answer: (the forward variables are on next slide) Initial value f M (0,0) = 1, f X (0,0) = f Y (0,0) = 0, for any i, j and M, X or Y matrices, f (i, -1) = f (-1,j) = 0 Main iteration At the termination step we have:
 Initial value f M (0,0) = 1, f X (0,0) = f Y (0,0) = 0, for any i, j and M, X or Y matrices, f (i, -1) = f (-1,j) = 0 Main iteration At the termination step we have:.")
119
j=0 j=1 j=2 j=3 j=4 j=5 f(i,j) - T T A C G i=0 - 1.000e+00 0.0000000 0.00e+00 0.000e+00 0.000e+00 0.000e+00 - 0.000e+00 0.0000000 0.00e+00 0.000e+00 0.000e+00 0.000e+00 - 0.000e+00 0.0500000 1.25e-03 3.125e-05 7.813e-07 1.953e-08 i=1 T 0.000e+00 0.2500000 2.00e-02 3.000e-04 1.250e-06 9.375e-08 T 5.000e-02 0.0000000 0.00e+00 0.000e+00 0.000e+00 0.000e+00 T 0.000e+00 0.0000000 1.25e-02 1.313e-03 4.781e-05 1.258e-06 i=2 A 0.000e+00 0.0120000 3.75e-02 1.000e-02 1.800e-04 1.944e-06 A 1.250e-03 0.0125000 1.00e-03 1.500e-05 6.250e-08 4.688e-09 A 0.000e+00 0.0000000 6.00e-04 1.890e-03 5.473e-04 2.268e-05 i=3 G 0.000e+00 0.0001500 2.40e-03 1.002e-03 1.957e-03 2.639e-04 G 3.125e-05 0.0009125 1.90e-03 5.004e-04 9.002e-06 9.730e-08 G 0.000e+00 0.0000000 7.50e-06 1.202e-04 5.308e-05 9.919e-05 Forward variables f(i,j) determined by the forward algorithm. Each cell (i,j) contains three values, f M (i,j), f X (i,j) and f Y (i,j), written in top down order.
 contains three values, f M (i,j), f X (i,j) and f Y (i,j), written in top down order..")
120
Pair HMM: an example question Question: For sequences x = TAG and y = TTACG find the posterior probability of the optimal alignment obtained by the Viterbi algorithm for the pair HMM as described above. Answer: The posterior probability of path is given by From the previous calculations, we have and, therefore,

Similar presentations

 = a st Emission probabilities:>")

 Michael Gutkin Shlomi Haba Prepared by Originally presented at Yaakov Stein’s DSPCSP Seminar, spring 2002 Modified.>")







>")







