Download presentation
Presentation is loading. Please wait.

1
x0 xn w0 wn o Threshold units SOM

2
Self-Organizing Maps

3
Inputs Neurons Teuvo Kohonen

4
Self-Organizing Maps : Origins
Ideas first introduced by C. von der Malsburg (1973), developed and refined by T. Kohonen (1982) Neural network algorithm using unsupervised competitive learning Primarily used for organization and visualization of complex data Biological basis: ‘brain maps’
, developed and refined by T. Kohonen (1982) Neural network algorithm using unsupervised competitive learning. Primarily used for organization and visualization of complex data. Biological basis: ‘brain maps’")
5
Self-Organizing Maps SOM - Architecture 2d array of neurons
Lattice of neurons (‘nodes’) accepts and responds to set of input signals Responses compared; ‘winning’ neuron selected from lattice Selected neuron activated together with ‘neighbourhood’ neurons Adaptive process changes weights to more closely resemble inputs 2d array of neurons Set of input signals (connected to all neurons in lattice) Weighted synapses x1 x2 x3 xn ... wj1 wj2 wj3 wjn j
 accepts and responds to set of input signals. Responses compared; ‘winning’ neuron selected from lattice. Selected neuron activated together with ‘neighbourhood’ neurons. Adaptive process changes weights to more closely resemble inputs. 2d array of neurons. Set of input signals. (connected to all neurons in lattice) Weighted synapses. x1. x2. x3. xn. ... wj1. wj2. wj3. wjn. j.")
6
Self-Organizing Maps Randomly initialise all weights
SOM – Algorithm Overview Randomly initialise all weights Select input vector x = [x1, x2, x3, … , xn] Compare x with weights wj for each neuron j to determine winner Update winner so that it becomes more like x, together with the winner’s neighbours Adjust parameters: learning rate & ‘neighbourhood function’ Repeat from (2) until the map has converged (i.e. no noticeable changes in the weights) or pre-defined no. of training cycles have passed
 until the map has converged (i.e. no noticeable changes in the weights) or pre-defined no. of training cycles have passed.")
7
Initialisation Randomly initialise the weights

8
Finding a Winner Euclidean distance
Find the best-matching neuron w(x), usually the neuron whose weight vector has smallest Euclidean distance from the input vector x The winning node is that which is in some sense ‘closest’ to the input vector ‘Euclidean distance’ is the straight line distance between the data points, if they were plotted on a (multi-dimensional) graph Euclidean distance between two vectors a and b, a = (a1,a2,…,an), b = (b1,b2,…bn), is calculated as: Euclidean distance
, usually the neuron whose weight vector has smallest Euclidean distance from the input vector x. The winning node is that which is in some sense ‘closest’ to the input vector. ‘Euclidean distance’ is the straight line distance between the data points, if they were plotted on a (multi-dimensional) graph. Euclidean distance between two vectors a and b, a = (a1,a2,…,an), b = (b1,b2,…bn), is calculated as: Euclidean distance.")
9
wj(t +1) = wj(t) + (t) (x)(j,t) [x - wj(t)]
Weight Update SOM Weight Update Equation wj(t +1) = wj(t) + (t) (x)(j,t) [x - wj(t)] “The weights of every node are updated at each cycle by adding Current learning rate × Degree of neighbourhood with respect to winner × Difference between current weights and input vector to the current weights” Example of (t) Example of (x)(j,t) L. rate No. of cycles x-axis shows distance from winning node y-axis shows ‘degree of neighbourhood’ (max. 1)
![wj(t +1) = wj(t) + (t) (x)(j,t) [x - wj(t)]](http://slideplayer.com/slide/4710654/15/images/9/wj%28t+%2B1%29+%3D+wj%28t%29+%2B+%EF%81%AD%28t%29+%EF%81%AC%EF%81%B7%28x%29%28j%2Ct%29+%5Bx+-+wj%28t%29%5D.jpg "Weight Update. SOM Weight Update Equation. wj(t +1) = wj(t) + (t) (x)(j,t) [x - wj(t)] The weights of every node are updated at each cycle by adding. Current learning rate × Degree of neighbourhood with respect to winner × Difference between current weights and input vector. to the current weights Example of (t) Example of (x)(j,t) L. rate. No. of cycles. x-axis shows distance from winning node. y-axis shows ‘degree of neighbourhood’ (max. 1)")
10
Kohonen’s Algorithm jth input Winner ith

11
Neighborhoods Square and hexagonal grid with
neighborhoods based on box distance Grid-lines are not shown

12
i One-dimensional i Two-dimensional Neighborhood of neuron i

14
A neighborhood function (i, k) indicates how closely neurons i and k in the output layer are connected to each other. Usually, a Gaussian function on the distance between the two neurons in the layer is used: position of i position of k

16
Clustering of the Self Organising Map
A simple toy example Clustering of the Self Organising Map

17
However, instead of updating only the winning neuron i
However, instead of updating only the winning neuron i*, all neurons within a certain neighborhood Ni* (d), of the winning neuron are updated using the Kohonen rule. Specifically, we adjust all such neurons i Ni* (d), as follow Here the neighborhood Ni* (d), contains the indices for all of the neurons that lie within a radius d of the winning neuron i*.
, of the winning neuron are updated using the Kohonen rule. Specifically, we adjust all such neurons i Ni* (d), as follow. Here the neighborhood Ni* (d), contains the indices for all of the neurons that lie within a radius d of the winning neuron i*.")
18
Topologically Correct Maps
The aim of unsupervised self-organizing learning is to construct a topologically correct map of the input space.

19
Self Organizing Map Determine the winner (the neuron of which the weight vector has the smallest distance to the input vector) Move the weight vector w of the winning neuron towards the input i Before learning i w After learning i w

20
Network Features Input nodes are connected to every neuron
The “winner” neuron is the one whose weights are most “similar” to the input Neurons participate in a “winner-take-all” behavior The winner output is set to 1 and all others to 0 Only weights to the winner and its neighbors are adapted

21
P 1 2 3 4 5 6 7 8 9 wi

22
P1 P2 1 2 3 4 5 6 7 8 9 wi2 wi1

23
output input (n-dimensional) winner
 winner")
25
Example I: Learning a one-dimensional representation of a two-dimensional (triangular) input space:
20 100 10000 25000 1000

26
Some nice illustrations

27
Some nice illustrations

28
Some nice illustrations

29
Self Organizing Map Impose a topological order onto the competitive neurons (e.g., rectangular map) Let neighbors of the winner share the “prize” (The “postcode lottery” principle) After learning, neurons with similar weights tend to cluster on the map
 After learning, neurons with similar weights tend to cluster on the map.")
30
Conclusion Advantages
SOM is Algorithm that projects high-dimensional data onto a two-dimensional map. The projection preserves the topology of the data so that similar data items will be mapped to nearby locations on the map. SOM still have many practical applications in pattern recognition, speech analysis, industrial and medical diagnostics, data mining Disadvantages Large quantity of good quality representative training data required No generally accepted measure of ‘quality’ of a SOM e.g. Average quantization error (how well the data is classified)
")
31
Topologies (gridtop, hextop, randtop)
pos = gridtop(3,2) pos = plotsom (pos) pos = gridtop(2,3) pos = plotsom (pos)
 pos = plotsom (pos) pos = gridtop(2,3) pos = plotsom (pos)")
32
pos = gridtop(8,10); plotsom(pos)
; plotsom(pos)")
33
pos = hextop(2,3) pos =

34
pos = hextop(3,2) pos = plotsom(pos)
")
35
pos = hextop(8,10); plotsom(pos)
; plotsom(pos)")
36
pos = randtop(2,3) pos =

37
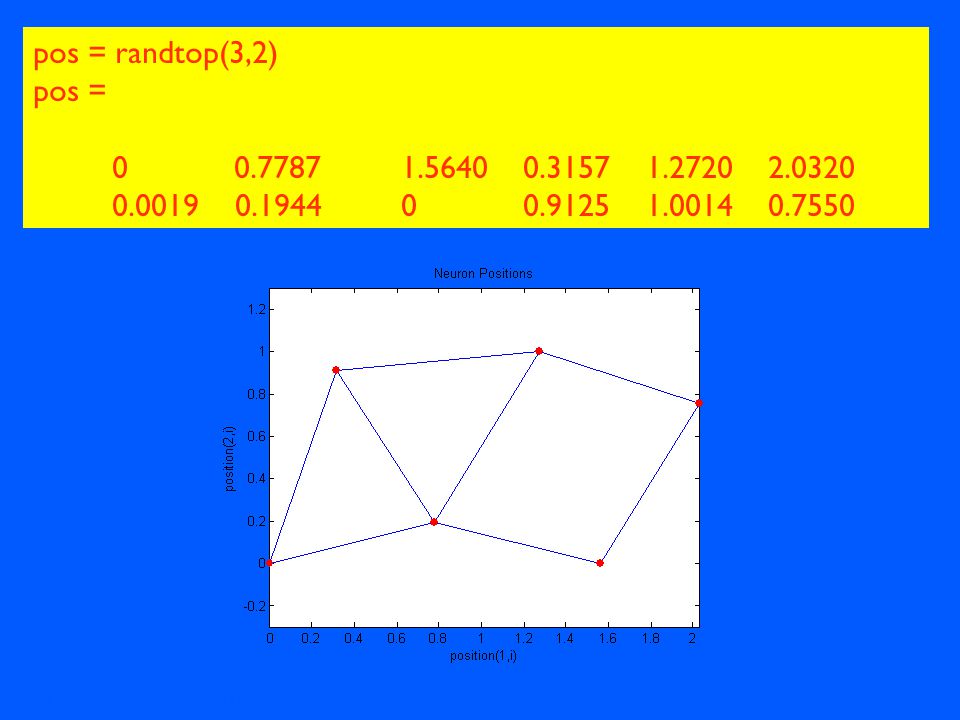
pos = randtop(3,2) pos =
38
pos = randtop(8,10); plotsom(pos)
; plotsom(pos)")
39
Distance Funct. (dist, linkdist, mandist, boxdist)
pos2 = [ 0 1 2; 0 1 2] pos2 = D2 = dist(pos2) D2 =
 D2 =")
41
pos = gridtop(2,3) pos = plotsom(pos) d = boxdist(pos) d =
 d =")
42
pos = gridtop(2,3) pos = plotsom(pos) d=linkdist(pos) d =
 d =")
43
The Manhattan distance between two vectors x and y is calculated as
D = sum(abs(x-y)) Thus if we have W1 = [ 1 2; 3 4; 5 6] W1 = and P1= [1;1] P1 = 1 then we get for the distances Z1 = mandist(W1,P1) Z1 = 5 9
) Thus if we have. W1 = [ 1 2; 3 4; 5 6] W1 = and. P1= [1;1] P1 = 1. then we get for the distances. Z1 = mandist(W1,P1) Z1 =")
44
A One-dimensional Self-organizing Map
angles = 0:2*pi/99:2*pi; P = [sin(angles); cos(angles)]; plot(P(1,:),P(2,:),'+r')
; cos(angles)]; plot(P(1,:),P(2,:), +r )")
45
net = newsom([-1 1;-1 1],[30]); net.trainParam.epochs = 100;
net = train(net,P); plotsom(net.iw{1,1},net.layers{1}.distances) The map can now be used to classify inputs, like [1; 0]: Either neuron 1 or 10 should have an output of 1, as the above input vector was at one end of the presented input space. The first pair of numbers indicate the neuron, and the single number indicates its output. p = [1;0]; a = sim (net, p) a = (1,1)
![net = newsom([-1 1;-1 1],[30]); net.trainParam.epochs = 100;](http://slideplayer.com/slide/4710654/15/images/45/net+%3D+newsom%28%5B-1+1%3B-1+1%5D%2C%5B30%5D%29%3B+net.trainParam.epochs+%3D+100%3B.jpg "net = train(net,P); plotsom(net.iw{1,1},net.layers{1}.distances) The map can now be used to classify inputs, like [1; 0]: Either neuron 1 or 10 should have an output of 1, as the above input vector was at one end of the presented input space. The first pair of numbers indicate the neuron, and the single number indicates its output. p = [1;0]; a = sim (net, p) a = (1,1) 1.")
46
x = -4:0.01:4 P = [x;x.^2]; plot(P(1,:),P(2,:),'+r') net = newsom([-10 10;0 20],[10 10]); net.trainParam.epochs = 100; net = train(net,P); plotsom(net.iw{1,1},net.layers{1}.distances)
![x = -4:0.01:4 P = [x;x.^2]; plot(P(1,:),P(2,:), +r ) net = newsom([-10 10;0 20],[10 10]); net.trainParam.epochs = 100;](http://slideplayer.com/slide/4710654/15/images/46/x+%3D+-4%3A0.01%3A4+P+%3D+%5Bx%3Bx.%5E2%5D%3B+plot%28P%281%2C%3A%29%2CP%282%2C%3A%29%2C+%2Br+%29+net+%3D+newsom%28%5B-10+10%3B0+20%5D%2C%5B10+10%5D%29%3B+net.trainParam.epochs+%3D+100%3B.jpg "net = train(net,P); plotsom(net.iw{1,1},net.layers{1}.distances)")
Similar presentations






>")









. Unsupervised neural networks, equivalent to clustering. Two layers – input and output – The input layer represents the input.>")





 l Biological Neurons l Artificial Neurons l Perceptrons l Multilayer Neural Networks l Backpropagation.>")
