Download presentation
Presentation is loading. Please wait.

1
Assessing Personality 75 Years After Likert: Thurstone Was Right! (And some implications for I/O)
")
2
Colleagues Sasha Chernyshenko Steve Stark

3
Thurstone In a series of papers in the late 1920s, Thurstone asserted “Attitudes Can Be Measured” and provided several methods for their measurement He assumed that a conscientious person would endorse a statement that reflected his/her attitude…but “as a result of imperfections, obscurities, or irrelevancies in the statement, and inaccuracy or carelessness of the subjects” not everyone will endorse a statement, even when it matches their attitude

4
Thurstone, Psych Review, 1929 For N 1 people with attitude S 1, all should endorse a statement with scale value S 1 if they were conscientious and the item was perfect; but only n 1 actually endorse the item These people will endorse another statement with scale value S 2 with a probability p that is a function of |S 1 -S 2 | Figure from Thurstone’s paper:

5
Thurstone 1929

6
Thurstone 1928 Attitudes Can Be Measured Gave an example of an attitude variable, militarism-pacifism, with six statements representing a range of attitudes:

7
Thurstone 1928

8
A pacifist “would be willing to indorse all or most of the opinions in the range d to e and … he would reject as too extremely pacifistic most of the opinions to the left of d, and would also reject the whole range of militaristic opinions.” “His attitude would then be indicated by the average or mean of the range that he indorses”

9
Implications On Thurstone’s pacificism-militarism scale, three people might endorse two items each: Person 1 endorses f and d, and is very pacifistic Person 2 endorses e and b, and is neutral Person 3 endorses c and a, and is very militaristic Thus, it is crucial to know which items are endorsed!

10
Likert 1932 Proposed a much simpler approach: A five- point response scale with options “Strongly Approve”, “Approve”, “Neutral”, “Disapprove”, and “Strongly Disapprove”. The numerical values 1 to 5 were assigned to the different response options And an individual’s score was the sum or mean of the numerical scores

11
Likert 1932 Likert evaluated his scales by Split-half reliability Item-total correlations To make this work, he hit upon the idea of reverse scoring, e.g., statements like d and f from Thurstone needed to be scored in the opposite direction of statements like a and c.

12
Likert 1932 When computing item-total correlations, “if a zero or very low correlation coefficient is obtained, it indicates that the statement fails to measure that which the rest of the statements measure.” (p. 48) “Thus item analysis reveals the satisfactoriness of any statement so far as its inclusion in a given attitude scale is concerned”
 Thus item analysis reveals the satisfactoriness of any statement so far as its inclusion in a given attitude scale is concerned .")
13
Likert 1932 Likert discarded intermediate statements like “Compulsory military training in all countries should be reduced but not eliminated” Such a statement is “double-barreled and of little value because it does not differentiate persons in terms of their attitudes” (p. 34)
.")
14
Likert Scaling Although Likert didn’t articulate a psychometric model for his procedure, his analysis implies what Coombs (1964) called a dominance response process. Specifically, someone high on the trait or attitude measured by a scale is likely to “Strongly Agree” with a positively worded item and “Strongly Disagree” with a negatively worded item

15
Person endorses item if her standing on the latent trait, theta, is more extreme than that of the item. ItemPerson Example of a Dominance Process

16
Thurstone Scaling Thurstone assumed people endorse items reflecting attitudes close to their own feelings Coombs (1964) called this an ideal point process Sometimes called an unfolding model
 called this an ideal point process Sometimes called an unfolding model")
17
Person endorses item if his standing on the latent trait is near that of the item. “I enjoy chatting quietly with a friend at a cafe.” Disagree either because: Too introverted (uncomfortable in public places) Too extraverted (chatting over coffee is boring) Example of an Ideal Point Process Item Too Introverted Too Extraverted
 Too extraverted (chatting over coffee is boring) Example of an Ideal Point Process Item Too Introverted Too Extraverted.")
18
Important Point: The item-total correlation of intermediate ideal point items will be close to zero!

19
Which Process is Appropriate for Temperament Assessment? In a series of studies, we’ve Examined appropriateness of dominance process by fitting models of increasing complexity to data from two personality inventories Compared fits of dominance and ideal point models of similar complexity to 16PF data Compared fits of dominance and ideal point models to sets of items not preselected to fit dominance models

20
Fitting Traditional Dominance Models to Personality Data Data 16PF 5 th Edition 13,059 examinees completed 16 noncognitive scales Goldberg’s Big Five factor markers 1,594 examinees completed 5 noncognitive scales Models examined Parametric – 2PLM, 3PLM Nonparametric – Levine’s Maximum Likelihood Formula Scoring (MFSM)
")
21
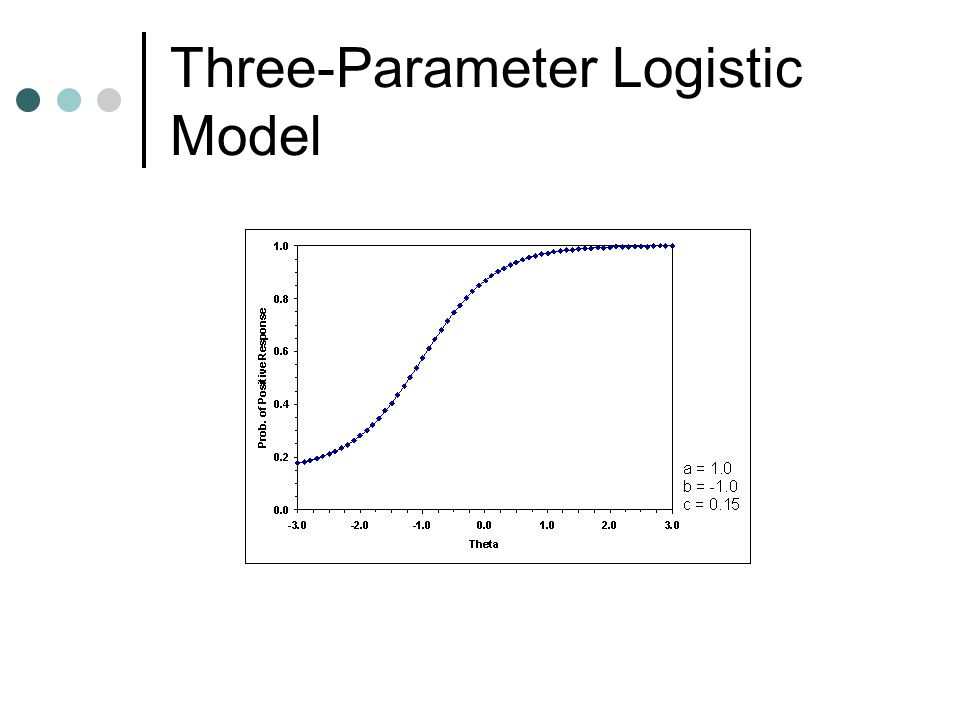
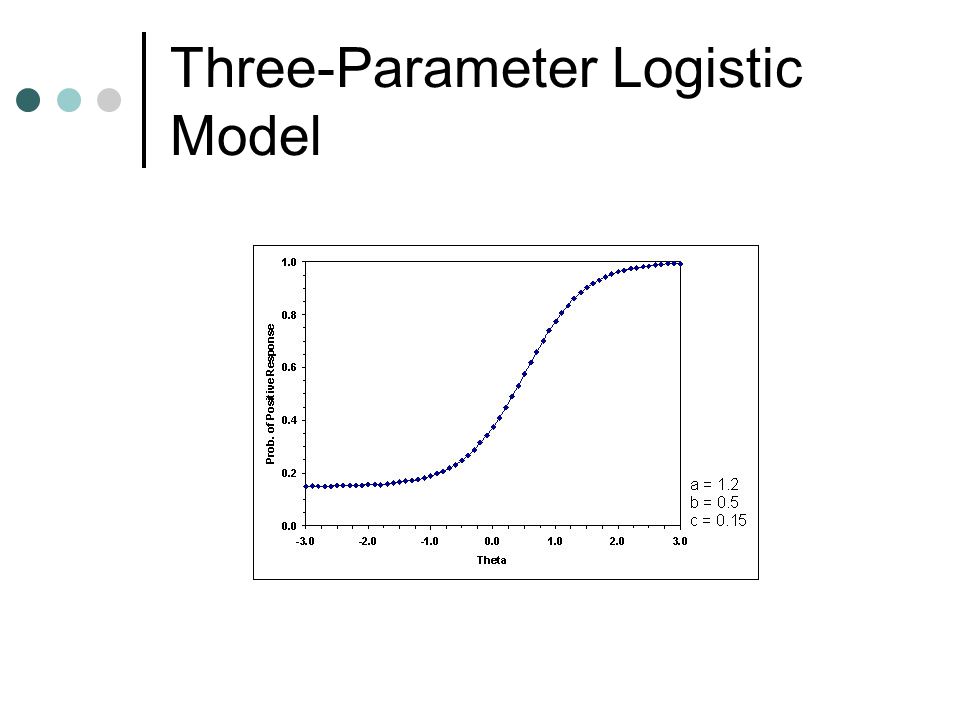
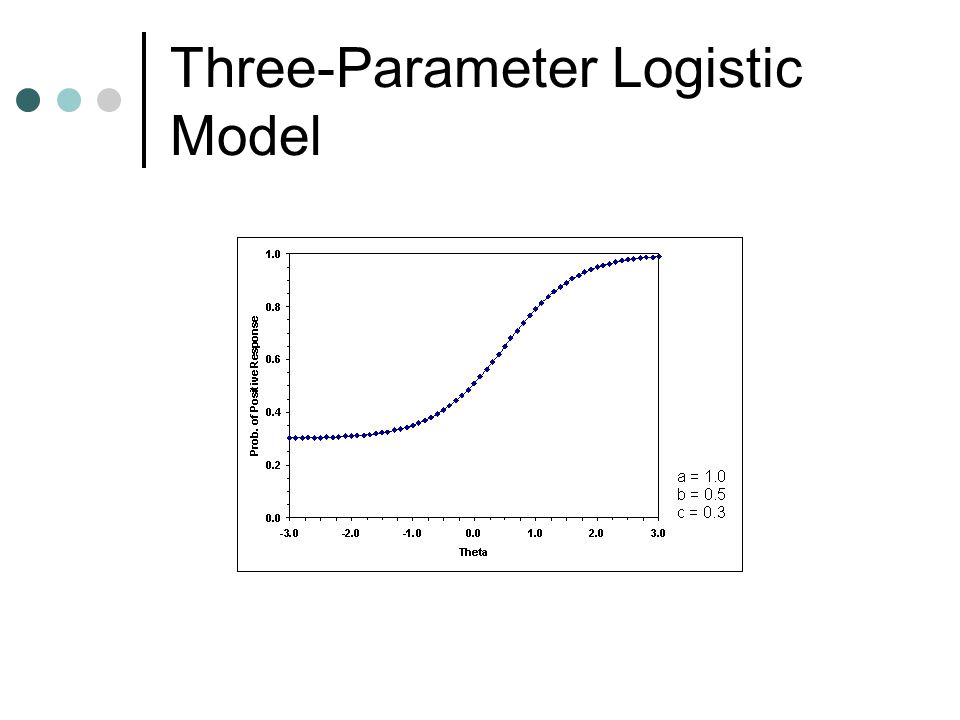
Three-Parameter Logistic Model

27
Two-Parameter Logistic Model

28
Methods for Assessing Fit: Fit Plots

29
Chi-squares typically computed for single items Methods for Assessing Fit: Chi- Squares Very important to examine item pairs and triplets May indicate violations of local independence or misspecified model

30
Methods for Assessing Fit: Chi- Squares To aid interpretation of chi-squares: Adjust to sample size of 3,000 Compare groups of different size The expected value of a non-central chi-square is equal to its df plus N times the noncentrality parameter where N is the sample size. So an estimate of the noncentrality parameter is

31
Adjusted Chi-square To adjust to a sample size of, say, 250, use For IRT, we usually adjust to N = 3000, and divide by the df to get an adjusted chi-square/df ratio Less than 2 is great, less than 3 is OK

32
Adjusted Chi-square/df for an Ability Test AdjChf < 3

33
Results for 16 PF Sensitivity Scale: Mean Chi-sq/df Ratios ModelSinglesDoublesTriples 2PL0.984.055.45 3PL0.873.895.23 SGR0.997.767.12 MFS-dich2.912.612.42 MFS-poly1.552.682.58

34
What if Items Assessed Trait Values Along the Whole Continuum? Items on existing personality scales have been pre-screened on item-total correlation We speculate that items measuring intermediate trait values are systematically deleted So, what happens if a scale includes some intermediate items?

35
TAPAS Well-being Scale Tailored Adaptive Personality Assessment System Assesses up to 22 facets of the Big Five Well-being is a facet of emotional stability We wrote items reflecting low, moderate, and high well-being

36
For example, TAPAS Well- Being Scale WELL04, “I don’t have as many happy moments in my life as others have WELL17, “My life has had about an equal share of ups and downs WELL41, “Most days I feel extremely good about myself In total, 20 items. 5 negative items, 9 positive, and 6 neutral

37
Traditional Analysis Results

38
Fit Plot for 2PL WELL17

39
An Ideal Point Model: The Generalized Graded Unfolding Model (GGUM) Roberts, Donoghue, & Laughlin (2000). Applied Psychological Measurement. The model assumes that the probability of endorsement is higher the closer the item to the person GGUM software provides maximum likelihood estimates of item parameters

40
GGUM The probability of disagree is: and the probability of agree is

41
GGUM Estimated IRF for Moderate Item IRF for Agree response to TAPAS Well-being item “My life has had about an equal share of ups and downs.”

42
TAPAS Well-being Scale 2PL Results: GGUM Results:

43
Summary of Findings 2PLM and 3PLM fit scales developed by traditional methods OK, but if moderate items are included Chi-square doublets and triplets can be large, especially when moderate items are included Discrimination parameter estimates are uniformly small for moderate items (and item-total correlations are near zero). GGUM fits all items, including moderate items Adj. chi-square to df ratios are small for doubles and triples GGUM discrimination parameter estimates are large for the moderate items!

44
So, for Well-Being Fitting a dominance item response theory model (the 2-parameter logistic) produced an adjusted Chi- Square to df ratio of 2.955 for pairs The ideal point model yielded an adjusted Chi-square/df ratio of 0.997 for pairs
 produced an adjusted Chi- Square to df ratio of for pairs The ideal point model yielded an adjusted Chi-square/df ratio of for pairs")
45
Conclusion Ideal point model seems more appropriate for temperament assessment BUT there’s a “Fly in the ointment” for I/O Correct specification of response process does not guarantee more accurate assessment, because … Traditional items are easily FAKED

46
Examples of “Traditional” Items that are Easily Faked I get along well with others. (A+) I try to be the best at everything I do. (C+) I insult people. (A-) My peers call me “absent minded.” (C-) Because these items consist of individual statements, they are commonly referred to as “single stimulus” items. In each case, the positively keyed response is obvious.
 I try to be the best at everything I do. (C+) I insult people. (A-) My peers call me absent minded. (C-) Because these items consist of individual statements, they are commonly referred to as single stimulus items. In each case, the positively keyed response is obvious..")
47
Army Assessment of Individual Motivation (AIM) Uses tetrads: I get along well with others. (A+) I set very high standards for myself. (C+) I worry a lot. (ES-) I like to sit on the couch and eat potato chips. (Physical condition-) Respondent picks the statement that is Most Like Me and the statement that is Least Like Me Army AIM has shown less score inflation What psychometric model would describe this type of data????
 I set very high standards for myself. (C+) I worry a lot. (ES-) I like to sit on the couch and eat potato chips. (Physical condition-) Respondent picks the statement that is Most Like Me and the statement that is Least Like Me Army AIM has shown less score inflation What psychometric model would describe this type of data .")
48
So… US Army researchers Len White and Mark Young (and others) found some fake resistance and criterion-related validity for the tetrad format But modeling four-dimensional items was too hard for me! How about two-dimensional items?

49
Multidimensional Pairwise Preference (MDPP) Format Create items by pairing stimuli that are similar in desirability, but representing different dimensions “Which is more like you?” I get along well with others. (A+) I always get my work done on time. (C+) This led to my work on personality assessment over the past 10 years And the result is:
 I always get my work done on time. (C+) This led to my work on personality assessment over the past 10 years And the result is:.")
50
Tailored Adaptive Personality Assessment System (TAPAS) TAPAS is designed to overcome existing limitations of personality assessment for selection by incorporating recent advancements in: Temperament/personality assessment Item response theory (IRT) Computerized adaptive testing (CAT) Our goal is for TAPAS to be innovative in both how we assess (IRT, CAT) and what we assess (facets of personality)
 TAPAS is designed to overcome existing limitations of personality assessment for selection by incorporating recent advancements in: Temperament/personality assessment Item response theory (IRT) Computerized adaptive testing (CAT) Our goal is for TAPAS to be innovative in both how we assess (IRT, CAT) and what we assess (facets of personality)")
51
TAPAS Vision Fully customizable assessment to fit array of users’ needs Users can select any dimension from a comprehensive superset; a scale length to suit their needs a response format (depends on faking worries) adaptive or static Resulting scores can be used to predict multiple criteria or as source of feedback
 adaptive or static Resulting scores can be used to predict multiple criteria or as source of feedback")
52
TAPAS Facet Dimensions Based on factor analysis of each of the Big Five dimensions E.g., Roberts, B., Chernyshenko, O.S., Stark, S., & Goldberg, L. (2005). The structure of conscientiousness. Personnel Psychology Analyzed 7 major personality inventories Currently 21 facets + additional “physical condition” facet for military jobs
. The structure of conscientiousness. Personnel Psychology Analyzed 7 major personality inventories Currently 21 facets + additional physical condition facet for military jobs.")
53
TAPAS Facet Dimensions Conscientiousness Six facet hierarchical structure: Industriousness: task- and goal-directed Order: planful and organized Self-control: delays gratification Traditionalism: follows norms and rules Social Responsibility: dependable and reliable Virtue: ethical, honest, and moral

54
Factor Analysis Results For each facet, we have an empirical mapping of existing scales to our facets Provide basis for existing scale classification Validity of each facet can be investigated via meta-analysis

55
TAPAS Military Meta-Analysis 42 studies or technical reports 1988-2006 Small number of police and fire-fighter studies were also included 22 TAPAS facets 8 criteria (e.g., task proficiency, contextual performance, leadership, attrition, fitness) 1494 empirical correlations
 1494 empirical correlations")
56
TAPAS Military Meta-Analysis Industriousness Results Validity tables can be used to guide the choice of facets!

57
TAPAS Civiliam Meta-Analysis Studies or technical reports in the period 1988-2006 Same 8 criterion categories and 22 TAPAS facets 4755 validity coefficients (so, in total, we have over 6,000 validities in our database)
")
58
“How” TAPAS Measures Our research on the item response process for personality stimuli (Stark et al., 2006; Chernyshenko et al., 2007) suggests that Response endorsement is driven by the similarity between the person and the behavior described by the stimulus (aka, an ideal point process) Implications: Different models (not the 3PL or SGR) should be used for item administration and scoring: e.g., GGUM Multiple stimuli per item are possible (i.e., pairs)
 suggests that Response endorsement is driven by the similarity between the person and the behavior described by the stimulus (aka, an ideal point process) Implications: Different models (not the 3PL or SGR) should be used for item administration and scoring: e.g., GGUM Multiple stimuli per item are possible (i.e., pairs)")
59
“How” TAPAS Measures The choice of 4 response formats will be available Single statement dichotomous (Agree/Disagree) Single statement polytomous (SA,A,D,SD) Unidimensional pairwise preference (i.e., two- alternative forced choice) Multidimensional pairwise preference (Stark, 2002) Used when faking is likely
 Single statement polytomous (SA,A,D,SD) Unidimensional pairwise preference (i.e., two- alternative forced choice) Multidimensional pairwise preference (Stark, 2002) Used when faking is likely")
60
Single Statement Scales Generalized Graded Unfolding Model (GGUM; Roberts et al., 1998) Reverse scoring is not needed Basic idea: a person endorses an item if it accurately describes him/her Thus, the probability of endorsement is higher the closer the item to the person
 Reverse scoring is not needed Basic idea: a person endorses an item if it accurately describes him/her Thus, the probability of endorsement is higher the closer the item to the person")
61
GGUM IRFs for two Personality Statements

62
Multidimensional Pairwise Preference (MDPP) Format Create items by pairing stimuli that are similar in desirability, but representing different dimensions “Which is more like you?” I get along well with others. (A+) I set very high standards for myself. (C+)
 I set very high standards for myself. (C+).")
63
MDPP Roots: Assessment of Individual Motivation (AIM) AIM utilizes forced-choice tetrad format to reduce social desirability effects Greater resistance to faking than ABLE (a single statement personality inventory developed by the Army researchers) Low correlations (.00 to.25) with examinee race and gender and measures of cognitive ability Predicts attrition and various job and training performance criteria in research and operational testing
 AIM utilizes forced-choice tetrad format to reduce social desirability effects Greater resistance to faking than ABLE (a single statement personality inventory developed by the Army researchers) Low correlations (.00 to.25) with examinee race and gender and measures of cognitive ability Predicts attrition and various job and training performance criteria in research and operational testing")
64
MDPP Roots: Assessment of Individual Motivation (AIM) But, due to quasi-ipsative scoring AIM items are difficult to create and Score accuracy cannot be checked against known scores, because no formal psychometric model for stimulus endorsement is available CAT is not possible without a psychometric model
 But, due to quasi-ipsative scoring AIM items are difficult to create and Score accuracy cannot be checked against known scores, because no formal psychometric model for stimulus endorsement is available CAT is not possible without a psychometric model")
65
Respondent evaluates each stimulus (personality statement) separately and makes independent decisions about endorsement. Stimuli may be on different dimensions. Single stimulus response probabilities P{0} and P{1} computed using a unidimensional ideal point model for “traditional” items (GGUM) IRT Model for Scoring Multidimensional Pairwise Preference Items (Stark, 2002; Stark, Chernyshenko, & Drasgow, 2005) 1 = Agree 0 = Disagree Refer to new pairwise preference model as MDPP
 IRT Model for Scoring Multidimensional Pairwise Preference Items (Stark, 2002; Stark, Chernyshenko, & Drasgow, 2005) 1 = Agree 0 = Disagree Refer to new pairwise preference model as MDPP.")
66
MDPP IRF for Item Measuring Sociability and Order

67
MDPP Model Performance Stark & Drasgow (2002).77 correlation between estimated and known scores in 2-D tests, 20 pairs, 10% unidimensional Stark & Chernyshenko.88 for 5-D tests, 50 items, 5% unidimensional All possible pairings of dimensions was not required for good parameter recovery
.77 correlation between estimated and known scores in 2-D tests, 20 pairs, 10% unidimensional Stark & Chernyshenko.88 for 5-D tests, 50 items, 5% unidimensional All possible pairings of dimensions was not required for good parameter recovery")
68
CAT vs. Nonadaptive * CAT yielded similar correlations with only half as many items. * 10-d CAT correlations >.9 with 100 items (only 5 unidim!).
..")
69
Summary of MDPP Model Studies MDPP items are attractive for applied use: Faking is more difficult Can create huge pool with relatively few statements representing each dimension (20 stimuli = 190 items) 5% unidimensional pairings sufficient for accurate score recovery As with SS models, MDPP CAT can reduce test length by about 50% while maintaining accuracy, which is important if many dimensions assessed.
 5% unidimensional pairings sufficient for accurate score recovery As with SS models, MDPP CAT can reduce test length by about 50% while maintaining accuracy, which is important if many dimensions assessed.")
70
Current Empirical TAPAS Studies Comparing MDPP format to single statement (SS) format Testing what makes forced-choice items resistant to faking # of dimensions? Matching on social desirability? Matching on statement locations?

71
Study 1: Benchmark Study 4-D MDPP measure (41 pairs) designed using “conventional wisdom” Match stimuli on social desirability (average difference between SocD did not exceed 1.08 on 5-point scale) Match stimuli to have different locations on respective dimensions (average distance 4.3 units on Z-score metric) 4-D SS measure (40 items) Both measures administered under faking and honest conditions (N = 510 and N = 574) 2-D SS measure (20 items) – all honest (n=1084)
 designed using conventional wisdom Match stimuli on social desirability (average difference between SocD did not exceed 1.08 on 5-point scale) Match stimuli to have different locations on respective dimensions (average distance 4.3 units on Z-score metric) 4-D SS measure (40 items) Both measures administered under faking and honest conditions (N = 510 and N = 574) 2-D SS measure (20 items) – all honest (n=1084)")
72
Very Strong Faking Instructions! Unlike in the previous sections where the instructions asked you to be as honest and accurate as possible, we now ask that you PRETEND you are not yet in the Army, but very much want to be. Imagine a recruiter asks you to take this questionnaire to determine if you are GOOD ARMY MATERIAL. If you score well, you will be let into the Army. If you don’t score well, you will not. For the remaining sections, you are to answer the test questions by describing yourself in a way that will make you look like “good Army material” so you are sure to pass the test and get into the Army. Remember you are not yet in the Army, but very much want to be. In other words, create the best possible impression of yourself and convince the Army that you will make a good Soldier.

73
Study 1: Benchmark Study Comparability of formats under Honest Conditions

74
Study 1: Benchmark Study MDPP scales created using conventional wisdom are as fakable as SS scales in strong faking conditions In faking conditions, respondents chose items with “more positive” location (i.e., > 20% endorsement shift across conditions)
")
75
Study 2: Location Matching 11-D MDPP static measure with 117 items Match stimuli on similarity in locations (average distance 2.09 z-score units) 11-D SS measure (7 items each) Both measures administered under faking and honest conditions (N = 286 and N = 358) Again, very strong faking instructions
 11-D SS measure (7 items each) Both measures administered under faking and honest conditions (N = 286 and N = 358) Again, very strong faking instructions")
76
Study 2: Location Matching Unlike benchmark study, only 20 out of 117 items showed inflated percent endorsement shifts Note that we matched only on locations, not Soc.D Scored 97 pair 11-D MDPP measure Similar correlations across formats as in benchmark study But, less score inflation

77
Study 2: Location Matching Compare to: SS scales in benchmarking study had.41 SD inflation for DOM, and.79 SD inflation for TRAD

78
Conclusions MDPP model (Stark, 2002) can be used effectively to score real MDPP response patterns MDPP scores agree with SS scores under honest conditions Fake resistance of forced-choice format should not be taken for granted E.g., must match on item locations, not just Soc.D Our MDPP CAT algorithm has constraints on location difference and Soc.D difference Adaptive testing format may further decrease fakability (e.g., NCAPS results with UPP scales) But, there is lots of R&D work to be done…
 can be used effectively to score real MDPP response patterns MDPP scores agree with SS scores under honest conditions Fake resistance of forced-choice format should not be taken for granted E.g., must match on item locations, not just Soc.D Our MDPP CAT algorithm has constraints on location difference and Soc.D difference Adaptive testing format may further decrease fakability (e.g., NCAPS results with UPP scales) But, there is lots of R&D work to be done…")
79
Current Work TAPAS is being implemented by the US Army for enlistment screening June 8 for applicants without high school diplomas Will it predict their attrition and counter-productive behaviors?

80
Current Work We have about 50 statements for each of the 13 dimensions that are being used by the US Army Are some statements overused? We don’t have a exposure control algorithm In principle, each of the approximately 650 statements could be paired with any of the other 649…but there are lots of constraints on item selection…

81
In Sum, TAPAS designed to bring the latest in Psychometric theory Computer technology Personality theory Our goal is to produce an easily customizable assessment tool to meet the needs of diverse users and researchers

Similar presentations







 Steps for Creating a Personality Questionnaire Generate an item pool Administer the items to a sample of people Assess the uni-dimensionality.>")




 Assume what you believe.>")




 and dependant (Y) variables.>")



