Download presentation
Presentation is loading. Please wait.

1
Learning Near-Isometric Linear Embeddings Richard Baraniuk Rice University Chinmay Hegde MIT Aswin Sankaranarayanan CMU Wotao Yin UCLA

2
challenge 1 too much data

3
Large Scale Datasets

4
Case in Point: DARPA ARGUS- IS 1.8 Gigapixel image sensor

7
Case in Point: DARPA ARGUS- IS 1.8 Gpixel image sensor –video rate output: 444 Gbits/s –comm data rate: 274 Mbits/s factor of 1600x way out of reach of existing compression technology Reconnaissance without conscience –too much data to transmit to a ground station –too much data to make effective real-time decisions

8
challenge 2 data too expensive

9
Case in Point: MR Imaging Measurements very expensive $1-3 million per machine 30 minutes per scan

10
Case in Point: IR Imaging

11
DIMENSIONALITY REDUCTION

12
Intrinsic Dimensionality Intrinsic dimension << Extrinsic dimension! Why? Geometry, that’s why Exploit to perform more efficient analysis and processing of large-scale data

13
Linear Dimensionality Reduction measurements signal

14
Linear Dimensionality Reduction Goal: Create a (linear) mapping from R N to R M with M < N that preserves the key geometric properties of the data ex: configuration of the data points
 mapping from R N to R M with M < N that preserves the key geometric properties of the data ex: configuration of the data points")
15
Dimensionality Reduction Given a training set of signals, find “best” that preserves its geometry

16
Dimensionality Reduction Given a training set of signals, find “best” that preserves its geometry Approach 1:Principal Component Analysis (PCA) via SVD of training signals –find “average” best fitting subspace in least-squares sense –average error metric can distort point cloud geometry
 via SVD of training signals –find average best fitting subspace in least-squares sense –average error metric can distort point cloud geometry")
17
Embedding Given a training set of signals, find “best” that preserves its geometry Approach 2: Inspired by Restricted Isometry Property (RIP) Whitney Embedding Theorem
 Whitney Embedding Theorem")
18
Isometric Embedding Given a training set of signals, find “best” that preserves its geometry Approach 2: Inspired by RIP and Whitney –design to preserve inter-point distances (secants) –more faithful to training data
 –more faithful to training data")
19
Near-Isometric Embedding Given a training set of signals, find “best” that preserves its geometry Approach 2: Inspired by RIP and Whitney –design to preserve inter-point distances (secants) –more faithful to training data –but exact isometry can be too much to ask
 –more faithful to training data –but exact isometry can be too much to ask")
20
Near-Isometric Embedding Given a training set of signals, find “best” that preserves its geometry Approach 2: Inspired by RIP and Whitney –design to preserve inter-point distances (secants) –more faithful to training data –but exact isometry can be too much to ask
 –more faithful to training data –but exact isometry can be too much to ask")
21
Why Near-Isometry? Sensing –guarantees existence of a recovery algorithm Machine learning applications –kernel matrix depends only on pairwise distances Approximate nearest neighbors for classification –efficient dimensionality reduction

22
Existence of Near Isometries Johnson-Lindenstrauss Lemma Given a set of Q points, there exists a Lipchitz map that achieves near-isometry (with constant ) provided Random matrices with iid subGaussian entries work –compressive sensing, locality sensitive hashing, database monitoring, cryptography Existence of solution! –but constants are poor –oblivious to data structure [J-L, 84] [Frankl and Meahara, 88][Indyk and Motwani, 99] [Achlioptas, 01][Dasgupta and Gupta, 02]

23
Designed Embeddings Unfortunately, random projections are data-oblivious (by definition) Q: Can we beat random projections? Our quest: A new approach for designing linear embeddings for specific datasets

24
[math alert]
![[math alert]](http://images.slideplayer.com/15/4659099/slides/slide_24.jpg "[math alert]")
25
Designing Embeddings Normalized secants [Whitney; Kirby; Wakin, B ’09] Goal: approximately preserve the length of Obviously, projecting in direction of is a bad idea
![Designing Embeddings Normalized secants [Whitney; Kirby; Wakin, B ’09] Goal: approximately preserve the length of Obviously, projecting in direction of is a bad idea](http://images.slideplayer.com/15/4659099/slides/slide_25.jpg "Designing Embeddings Normalized secants [Whitney; Kirby; Wakin, B ’09] Goal: approximately preserve the length of Obviously, projecting in direction of is a bad idea")
26
Designing Embeddings Normalized secants Goal: approximately preserve the length of Note: total number of secants is large:

27
“Good” Linear Embedding Design Given: normalized secants Seek: the “shortest” matrix such that Think of as the knob that controls the “maximum distortion” that you are willing to tolerate

28
“Good” Linear Embedding Design Given: (normalized) secants Seek: the “shortest” matrix such that
 secants Seek: the shortest matrix such that")
29
Lifting Trick Convert quadratic constraints in into linear constraints in Given, obtain via matrix square root

30
Relaxation Relax rank minimization problem to nuclear norm minimization problem

31
NuMax Nuclear norm minimization with Max-norm constraints (NuMax) Semi-Definite Program (SDP) –solvable by standard interior point methods Rank of solution is determined by
 Semi-Definite Program (SDP) –solvable by standard interior point methods Rank of solution is determined by")
32
Accelerating NuMax Poor scaling with N and S –least squares involves matrices with S rows –SVD of an NxN matrix Several avenues to accelerate: –Alternating Direction Method of Multipliers (ADMM) –exploit fact that intermediate estimates of P are low-rank –exploit fact that only a few secants define the optimal embedding (“column generation”)
 –exploit fact that intermediate estimates of P are low-rank –exploit fact that only a few secants define the optimal embedding ( column generation )")
33
Accelerated NuMax Can solve for datasets with Q=100k points in N=1000 dimensions in a few hours

34
[/math alert]
![[/math alert]](http://images.slideplayer.com/15/4659099/slides/slide_34.jpg "[/math alert]")
35
App: Linear Compression Images of translating blurred squares live on a K=2 dimensional smooth “surface” (manifold) in N=256 dimensional space Project a collection of 1000 such images into M-dimensional space while preserving structure (as measured by distortion constant ) N=16x16=256
 in N=256 dimensional space Project a collection of 1000 such images into M-dimensional space while preserving structure (as measured by distortion constant ) N=16x16=256")
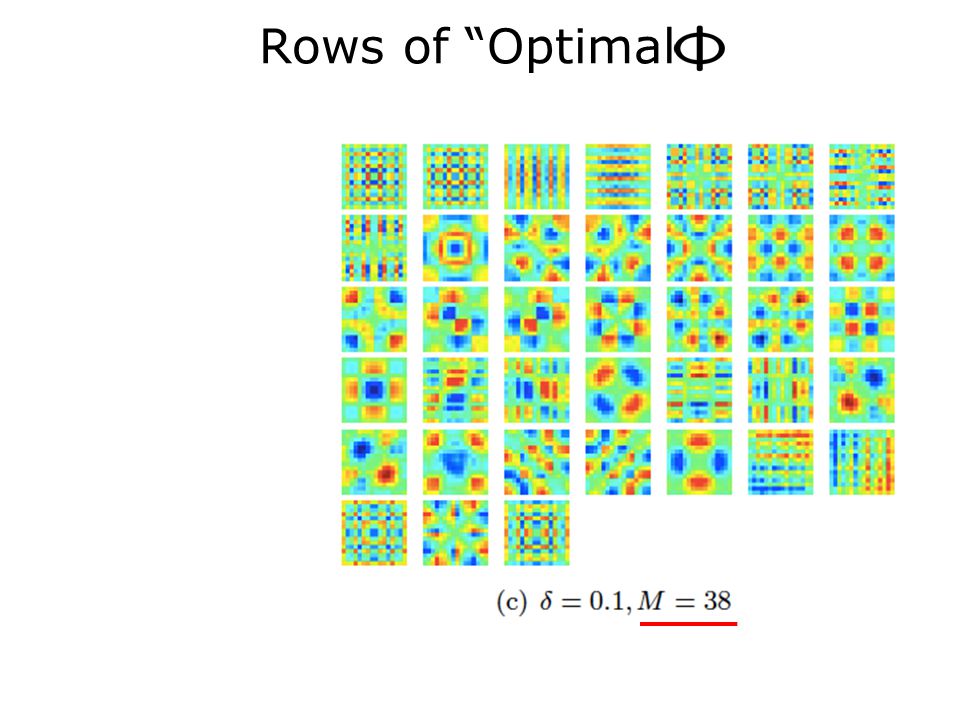
36
Rows of “Optimal” measurements signal N=16x16=256

37
Rows of “Optimal”

40
App: Linear Compression M=40 linear measurements enough to ensure isometry constant of = 0.01

41
Secant Distortion Distribution of secant distortions for the translating squares dataset Embedding dimension M=30 Input distortion to NuMax is \delta=0.03 As opposed to PCA and random, NuMax provides distortions sharply concentrated at \delta.

42
Secant Distortion Translating squares dataset –N = 16x16 = 256 –M = 30 – = 0.03 Histograms of normalized secant distortions randomPCANuMax 0.06

43
MNIST (8) – Near Isometry M = 14 basis functions achieve = 0.05 N=20x20=400
 – Near Isometry M = 14 basis functions achieve = 0.05 N=20x20=400")
44
MNIST (8) – Near Isometry N=20x20=400
 – Near Isometry N=20x20=400")
45
Goal:Preserve neighborhood structure of a set of images App: Image Retrieval LabelMe Image Dataset N = 512, Q = 4000, M = 45 suffices to preserve 80% of neighborhoods

46
App: Classification MNIST digits dataset –N = 20x20 = 400-dim images –10 classes: digits 0-9 –Q = 60000 training images Nearest neighbor (NN) classifier –Test on 10000 images Mis-classification rate of NN classifier using original dataset: 3.63%
 classifier –Test on images Mis-classification rate of NN classifier using original dataset: 3.63%")
47
App: Classification MNIST dataset –N = 20x20 = 400-dim images –10 classes: digits 0-9 –Q = 60000 training images, so S = 1.8 billion secants! –NuMax-CG took 3 hours to process Mis-classification rate of NN classifier: 3.63% NuMax provides the best NN-classification rates! δ 0.40 0.250.1 Rank of NuMax solution7297167 Mis- classification rates in % NuMax2.993.113.31 Gaussian5.794.513.88 PCA4.404.384.41

48
NuMax and Task Adaptivity Prune the secants according to the task at hand –If goal is reconstruction / retrieval, then preserve all secants –If goal is signal classification, then preserve inter-class secants differently from intra-class secants –This preferential weighting approach is akin to “boosting”

49
Optimized Classification Intra-class secants are not expanded Inter-class secants are not shrunk This simple modification improves NN classification rates while using even fewer measurements

50
Optimized Classification MNIST dataset –N = 20x20 = 400-dim images –10 classes: digits 0-9 –Q = 60000 training images, so >1.8 billion secants! –NuMax-CG took 3-4 hours to process 1.Significant reduction in number of measurements (M) 1.Significant improvement in classification rate δ0.400.250.1 AlgorithmNuMax NuMax Class NuMax NuMax Class NuMax NuMax Class Rank72529769167116 Miss-classification rate in % 2.992.683.112.723.313.09
 1.Significant improvement in classification rate δ AlgorithmNuMax NuMax Class NuMax NuMax Class NuMax NuMax Class Rank Miss-classification rate in %")
51
Conclusions NuMax – new adaptive data representation that is linear, near-isometric –minimize distortion to preserve geometrical info in a set of training signals Posed as a rank-minimization problem –relaxed to a Semi-definite program (SDP) –NuMax solves very efficiently via ADMM and CG Applications: Classification, retrieval, compressive sensing, ++ Nontrivial extension from signal recovery to signal inference
 –NuMax solves very efficiently via ADMM and CG Applications: Classification, retrieval, compressive sensing, ++ Nontrivial extension from signal recovery to signal inference")
52
Open Problems Equivalence between the solutions of min-rank and min-trace problems ? Convergence rate of NuMax –Preliminary studies show o(1/k) rate of convergence Scaling of the algorithm –Given dataset of Q-points, #secants is O(Q 2 ) –Are there alternate formulations that scale linearly/sub-linearly in Q ? More applications
 rate of convergence Scaling of the algorithm –Given dataset of Q-points, #secants is O(Q 2 ) –Are there alternate formulations that scale linearly/sub-linearly in Q . More applications.")
53
Software GNuMax Software package at dsp.rice.edu PneuMax French-version software package coming soon References C. Hegde, A. C. Sankaranarayanan, W. Yin, and R. G. Baraniuk, “A Convex Approach for Learning Near-Isometric Linear Embeddings,” Submitted to Journal of Machine Learning Research, 2012 C. Hegde, A. C. Sankaranarayanan, and R. G. Baraniuk, “Near-Isometric Linear Embeddings of Manifolds,” IEEE Statistical Signal Processing Workshop (SSP), August 2012 Y. Li, C. Hegde, A. Sankaranarayanan, R. Baraniuk, K. Kelly, “Compressive Classification via Secant Projections,” submitted to Optics Express, February 2014
, August 2012 Y. Li, C. Hegde, A. Sankaranarayanan, R. Baraniuk, K. Kelly, Compressive Classification via Secant Projections, submitted to Optics Express, February")
54
BONUS SLIDES

55
Practical Considerations In practice N large, Q very large! Computational cost per iteration scales as

56
Alternating Direction Method of Multipliers (ADMM) - solve for P using spectral thresholding - solve for L using least-squares - solve for q using “clipping” Computational/memory cost per iteration: Solving NuMax
 - solve for P using spectral thresholding - solve for L using least-squares - solve for q using clipping Computational/memory cost per iteration: Solving NuMax")
57
Accelerating NuMax Poor scaling with N and Q –least squares involves matrices with Q 2 rows –SVD of an NxN matrix Observation 1 –intermediate estimates of P are low-rank –use low-rank representation to reduce memory and accelerate computations –use incremental SVD for faster computations

58
Accelerating NuMax Observation 2 –by KKT conditions, by complementary slackness, only constraints that are satisfied with equality determine solutions (“active constraints”) Analogy: Recall support vector machines (SVMs)., where we solve The solution is determined only by the support vectors – those for which
 Analogy: Recall support vector machines (SVMs)., where we solve The solution is determined only by the support vectors – those for which")
59
NuMax-CG Observation 2 –by KKT conditions, by complementary slackness, only constraints that are satisfied with equality determine solutions (“active constraints”) Hence, given feasibility of a solution P *, only secants v k for which |v k T P * v k – 1| = determine the value of P * Key: Number of “support secants” << total number of secants –and so we only need to track the support secants –“column generation” approach to solving NuMax
 Hence, given feasibility of a solution P *, only secants v k for which |v k T P * v k – 1| = determine the value of P * Key: Number of support secants << total number of secants –and so we only need to track the support secants – column generation approach to solving NuMax")
61
Example from our paper with Yun and Kevin. (a) & (b) : example target images (toy bus vs toy car; 1D manifold of rotations) (c): PCA basis functions learned from inter-class secants. (d): NuMax basis functions learned from inter-class secants.
 & (b) : example target images (toy bus vs toy car; 1D manifold of rotations) (c): PCA basis functions learned from inter-class secants. (d): NuMax basis functions learned from inter-class secants..")
62
(Optional) Real-World Expts Real-data experiments using the Rice Single-Pixel Camera Test scenes: toy bus/car at unknown orientations NuMax results:
 Real-World Expts Real-data experiments using the Rice Single-Pixel Camera Test scenes: toy bus/car at unknown orientations NuMax results:")
63
(Optional) Real-World Expts Experimental details: –N = 64x64 = 4096, 72 images for each class –Acquire M measurements using {PCA, Bernoulli-random, NuMax} –Perform nearest-neighbor classification
 Real-World Expts Experimental details: –N = 64x64 = 4096, 72 images for each class –Acquire M measurements using {PCA, Bernoulli-random, NuMax} –Perform nearest-neighbor classification")
65
NuMax: Analysis Performance of NuMax depends upon the tightness of the convex relaxation: Q. When is this relaxation tight? A. Open Problem, likely very hard

66
NuMax: Analysis However, can rigorously analyze if is further constrained to be orthonormal Essentially enforces that the rows of are (i) unit norm and (ii) pairwise orthogonal Upshot: Models a per-sample energy constraint of a CS acquisition system –Different measurements necessarily probe “new” portions of the signal space –Measurements remain uncorrelated, so noise/perturbations in the input data are not amplified
 unit norm and (ii) pairwise orthogonal Upshot: Models a per-sample energy constraint of a CS acquisition system –Different measurements necessarily probe new portions of the signal space –Measurements remain uncorrelated, so noise/perturbations in the input data are not amplified")
67
Slight Refinement 1. Look at the converse problem fix the embedding dimension and solve for the linear embedding with minimum distortion,, as a function of M –Does not change the problem qualitatively 2. Restrict the problem to the space of orthonormal embeddings orthonormality

68
Slight Refinement As in NuMax, lifting + trace-norm relaxation: Efficient solution algorithms (NuMax, NuMax-CG) remain essentially unchanged However, solutions come with guarantees …
 remain essentially unchanged However, solutions come with guarantees …")
69
Analytical Guarantee Theorem [Grant, Hegde, Indyk ‘13] Denote the optimal distortion obtained by a rank-M orthonormal embedding as Then, by solving an SDP, we can efficiently construct a rank-2M embedding with distortion at most ie: One can get close to the optimal distortion by paying an additional price in the measurement budget (M)
![Analytical Guarantee Theorem [Grant, Hegde, Indyk ‘13] Denote the optimal distortion obtained by a rank-M orthonormal embedding as Then, by solving an SDP, we can efficiently construct a rank-2M embedding with distortion at most ie: One can get close to the optimal distortion by paying an additional price in the measurement budget (M)](http://images.slideplayer.com/15/4659099/slides/slide_69.jpg "Analytical Guarantee Theorem [Grant, Hegde, Indyk ‘13] Denote the optimal distortion obtained by a rank-M orthonormal embedding as Then, by solving an SDP, we can efficiently construct a rank-2M embedding with distortion at most ie: One can get close to the optimal distortion by paying an additional price in the measurement budget (M)")
71
CVDomes Radar Signals Training data: 2000 secants (inter-class, joint) Test data: 100 signatures from each class
 Test data: 100 signatures from each class")
Similar presentations







>")

















