Download presentation
Presentation is loading. Please wait.

1
Chapter 10 Learning Sets Of Rules

2
Content Introduction Sequential Covering Algorithm
Learning First-Order Rules (FOIL Algorithm) Induction As Inverted Deduction Inverting Resolution
 Induction As Inverted Deduction. Inverting Resolution.")
3
Introduction GOAL: Learning a target function as a set of IF-THEN rules BEFORE: Learning with decision trees Learning the decision tree Translate the tree into a set of IF-THEN rules (for each leaf one rule) OTHER POSSIBILITY: Learning with genetic algorithms Each set of rule is coded as a bitvector Several genetic operators are used on the hypothesis space TODAY AND HERE: First: Learning rules in propositional form Second: Learning rules in first-order form (Horn clauses which include variables) Sequential search for rules, one after the other
 OTHER POSSIBILITY: Learning with genetic algorithms. Each set of rule is coded as a bitvector. Several genetic operators are used on the hypothesis space. TODAY AND HERE: First: Learning rules in propositional form. Second: Learning rules in first-order form (Horn clauses which include variables) Sequential search for rules, one after the other.")
4
Introduction IF (Outlook = Sunny) ∧ (Humidity = High)
THEN PlayTennis = No IF (Outlook = Sunny) ∧ (Humidity = Normal) THEN PlayTennis = Yes
 ∧ (Humidity = Normal) THEN PlayTennis = Yes.")
5
Introduction An example of first-order rule sets
target concept: Ancestor IF Parent(x,y) THEN Ancestor(x,y) IF Parent(x,y)∧ Parent(y,z) THEN Ancestor(x,z) The content of this chapter Learning algorithms capable of learing such rules , given sets of training examples
 THEN Ancestor(x,y) IF Parent(x,y)∧ Parent(y,z) THEN Ancestor(x,z) The content of this chapter. Learning algorithms capable of learing such rules , given sets of training examples.")
6
Content Introduction Sequential Covering Algorithm
Learning First-Order Rules (FOIL Algorithm) Induction As Inverted Deduction Inverting Resolution
 Induction As Inverted Deduction. Inverting Resolution.")
7
Sequential Covering Algorithm

8
Sequential Covering Algorithm
Goal of such an algorithm: Learning a disjunctive set of rules, which defines a preferably good classification of the training data Principle: Learning rule sets based on the strategy of learning one rule, removing the examples it covers, then iterating this process. Requirement for the Learn-One-Rule method: As Input it accepts a set of positive and negative training examples As Output it delivers a single rule that covers many of the positive examples and maybe a few of the negative examples Required: The output rule has a high accuracy but not necessarily a high coverage

9
Sequential Covering Algorithm
Procedure: Learning set of rules invokes the Learn-One-Rule method on all of the available training examples Remove every positive example covered by the rule Eventually short the final set of the rules: more accurate rules can be considered first Greedy search: It is not guaranteed to find the smallest or best set of rules that covers the training example.

10
Sequential Covering Algorithm
SequentialCovering( target_attribute, attributes, examples, threshold ) learned_rules { } rule LearnOneRule( target_attribute, attributes, examples ) while (Performance( rule, examples ) > threshold ) do learned_rules learned_rules + rule examples examples - { examples correctly classified by rule } rule LearnOneRule( target_attribute, attributes, examples ) learned_rules sort learned_rules according to Performance over examples return learned_rules
 learned_rules { } rule LearnOneRule( target_attribute, attributes, examples ) while (Performance( rule, examples ) > threshold ) do. learned_rules learned_rules + rule. examples examples - { examples correctly classified by rule } rule LearnOneRule( target_attribute, attributes, examples ) learned_rules sort learned_rules according to Performance over examples. return learned_rules.")
11
General to Specific Beam Search
The CN2-Algorithm LearnOneRule (target_attribute, attributes, examples, k ) Initialise best_hypothesis to the most general hypothesis Ø Initialise candidate_hypotheses to the set { best_hypothesis } while ( candidate_hypothesis is not empty ) do 1. Generate the next more-specific candidate_hypothesis 2. Update best_hypothesis 3. Update candidate_hypothesis return a rule of the form “IF best_hypothesis THEN prediction“ where prediction is the most frequent value of target_attribute among those examples that match best_hypothesis. Performance( h, examples, target_attribute ) h_examples the subset of examples that match h return -Entropy( h_examples ), where Entropy is with respect to target_attribute
 Initialise best_hypothesis to the most general hypothesis Ø. Initialise candidate_hypotheses to the set { best_hypothesis } while ( candidate_hypothesis is not empty ) do. 1. Generate the next more-specific candidate_hypothesis. 2. Update best_hypothesis. 3. Update candidate_hypothesis. return a rule of the form IF best_hypothesis THEN prediction where prediction is the most frequent value of target_attribute among those examples that match best_hypothesis. Performance( h, examples, target_attribute ) h_examples the subset of examples that match h. return -Entropy( h_examples ), where Entropy is with respect to target_attribute.")
12
General to Specific Beam Search
Generate the next more specific candidate_hypothesis all_constraints set of all constraints (a = v), where a Î attributes and v is a value of an occuring in the current set of examples new_candidate_hypothesis for each h in candidate_hypotheses, for each c in all_constraints create a specialisation of h by adding the constraint c Remove from new_candidate_hypothesis any hypotheses which are duplicate, inconsistent or not maximally specific Update best_hypothesis for all h in new_candidate_hypothesis do if statistically significant when tested on examples Performance( h, examples, target_attribute ) > Performance( best_hypothesis, examples, target_attribute ) ) then best_hypothesis h
, where a Î attributes and v is a value of an occuring in the current set of examples. new_candidate_hypothesis. for each h in candidate_hypotheses, for each c in all_constraints. create a specialisation of h by adding the constraint c. Remove from new_candidate_hypothesis any hypotheses which are duplicate, inconsistent or not maximally specific. Update best_hypothesis. for all h in new_candidate_hypothesis do. if statistically significant when tested on examples Performance( h, examples, target_attribute ) > Performance( best_hypothesis, examples, target_attribute ) ) then best_hypothesis h.")
13
General to Specific Beam Search
Update the candidate-hypothesis candidate_hypothesis the k best members of new_candidate_hypothesis, according to Performance function Performance function guides the search in the Learn-One -Rule s: the current set of training examples c: the number of possible values of the target attribute : part of the examples, which are classified with the ith. value

14
Learn-One-Rule

15
Learning Rule Sets: Summary
Key dimension in the design of the rule learning algorithm Here sequential covering: learn one rule, remove the positive examples covered, iterate on the remaining examples ID3 simultaneous covering Which one should be preferred? Key difference: choice at the most primitive step in the search ID3: chooses among attributes by comparing the partitions of the data they generated CN2: chooses among attribute-value pairs by comparing the subsets of data they cover Number of choices: learn n rules each containing k attribute-value tests in their precondition CN2: n*k primitive search steps ID3: fewer independent search steps If the data is plentiful, then it may support the larger number of independent decisons If the data is scarce, the sharing of decisions regarding preconditions of different rules may be more effective

16
Learning Rule Sets: Summary
CN2: general-to-specific (cf. Find-S specific-to-general):the direction of the search in LEARN-ONE-RULE. Advantage: there is a single maximally general hypothesis from which to begin the search <=> there are many specific ones GOLEM: choosing several positive examples at random to initialise and to guide the search. The best hypothesis obtained through multiple random choices is the selected one CN2: generate then test Find-S, CANDIDATE-ELIMINATION are example-driven Advantage of the generate and test approach: each choice in the search is based on the hypothesis performance over many examples, the impact of noisy data is minimized
:the direction of the search in LEARN-ONE-RULE. Advantage: there is a single maximally general hypothesis from which to begin the search <=> there are many specific ones. GOLEM: choosing several positive examples at random to initialise and to guide the search. The best hypothesis obtained through multiple random choices is the selected one. CN2: generate then test. Find-S, CANDIDATE-ELIMINATION are example-driven. Advantage of the generate and test approach: each choice in the search is based on the hypothesis performance over many examples, the impact of noisy data is minimized.")
17
Content Introduction Sequential Covering Algorithm
Learning First-Order Rules (FOIL Algorithm) Induction As Inverted Deduction Inverting Resolution
 Induction As Inverted Deduction. Inverting Resolution.")
18
Learning First-Order Rules
Why do that ? Can learn sets of rules such as IF Parent(x,y) THEN Ancestor(x,y) IF Parent(x,y)∧Ancestor(y,z) THEN Ancestor(x,z)
 THEN Ancestor(x,y) IF Parent(x,y)∧Ancestor(y,z) THEN Ancestor(x,z)")
19
Learning First-Order Rules
Terminology Term : Mary , x , age(Mary) , age(x) Literal : Female(Mary), ﹁Female(x) Greater_than(age(Mary) ,20) Clause : M1∨…∨Mn Horn Clause: H←(L1∧…∧Ln) Substitution : {x/3,y/z} Unifying substitution: = FOIL Algorithm (Learning Sets of First-Order Rules)
 , age(x) Literal : Female(Mary), ﹁Female(x) Greater_than(age(Mary) ,20) Clause : M1∨…∨Mn. Horn Clause: H←(L1∧…∧Ln) Substitution : {x/3,y/z} Unifying substitution: = FOIL Algorithm. (Learning Sets of First-Order Rules)")
20
Cover all positive examples
Avoid all negative examples

21
Learning First-Order Rules
Analysis of FOIL Outer Loop Specific-to-general Inner Loop general-to-specific Difference between FOIL and Sequential- covering and Learn-one-rule generate candidate specializations of the rule FOIL_Gain

22
Learning First-Order Rules
Candidate Specializations in FOIL (Ln+1)
")
23
Learning First-Order Rules
Example Target Predicate : GrandDaughter(x,y) Other Predicate: Father , Female Rule : GrandDaughter(x,y) Candidate Literal: Equal(x,y) ,Female(x),Female(y),Father(x,y),Father(y,x), Father(x,z),Father(z,x), Father(y,z), Father(z,y) + negative Literals GrandDaugther(x,y) Father(y,z) GrandDaughter(x,y) Father(y,z) ∧Father(z,x) ∧Female(y)
 Other Predicate: Father , Female. Rule : GrandDaughter(x,y) Candidate Literal: Equal(x,y) ,Female(x),Female(y),Father(x,y),Father(y,x), Father(x,z),Father(z,x), Father(y,z), Father(z,y) + negative Literals. GrandDaugther(x,y) Father(y,z) GrandDaughter(x,y) Father(y,z) ∧Father(z,x) ∧Female(y)")
24
Learning First-Order Rules
Information Gain in FOIL Assertions of training data GrandDaughter(Victor,Sharon) Father(Sharon,Bob) Father(Tom,Bob) Female(Sharon) Father(Bob,Victor) Rule : GrandDaughter(x,y) Variable binding (16): {x/Bob , y/Sharon} Positive example binding: {x/Victor , y/Sharon} Negative example binding (15): {x/Bob,y/Tom} ……
 Father(Sharon,Bob) Father(Tom,Bob) Female(Sharon) Father(Bob,Victor) Rule : GrandDaughter(x,y) Variable binding (16): {x/Bob , y/Sharon} Positive example binding: {x/Victor , y/Sharon} Negative example binding (15): {x/Bob,y/Tom} ……")
25
Learning First-Order Rules
Information Gain in FOIL L the candidate literal to add to rule R p0 number of positive bindings of R n0 number of negative bindings of R p1 number of positive bindings of R+L n1 number of negative bindings of R+L t the number of positive bindings of R also covered by R+L

26
Learning First-Order Rules
Learning Recursive Rule Sets Target Predicate can be the candidate literals IF Parent(x,y) THEN Ancestor(x,y) IF Parent(x,y)∧Ancestor(y,z) THEN Ancestor(x,z)
 THEN Ancestor(x,y) IF Parent(x,y)∧Ancestor(y,z) THEN Ancestor(x,z)")
27
Learning First-Order Rules
Learning Recursive Rule Sets Target Predicate can be the candidate literals IF Parent(x,y) THEN Ancestor(x,y) IF Parent(x,y)∧Ancestor(y,z) THEN Ancestor(x,z)
 THEN Ancestor(x,y) IF Parent(x,y)∧Ancestor(y,z) THEN Ancestor(x,z)")
28
Content Introduction Sequential Covering Algorithm
Learning First-Order Rules (FOIL Algorithm) Induction As Inverted Deduction Inverting Resolution
 Induction As Inverted Deduction. Inverting Resolution.")
29
Induction As Inverted Deduction
Machine Learning Building theories that explain the observed data ( D <xi , f(xi)> ; B ; h ) Induction is finding h such that entail
> ; B ; h ) Induction is finding h such that. entail.")
30
Induction As Inverted Deduction
Example target concept : Child(u , v)
")
31
Induction As Inverted Deduction
What we will be interested is designing inverse entailment operators

32
Content Introduction Sequential Covering Algorithm
Learning First-Order Rules (FOIL Algorithm) Induction As Inverted Deduction Inverting Resolution
 Induction As Inverted Deduction. Inverting Resolution.")
33
Inverting Resolution(逆规约)
C1 C2 C Resolution operator construct C : ( C1 ∧ C C )
")
35
Inverse resolution operator : O( C , C1 )=C2
=C2")
36
Inverting Resolution First-order resolution
Resolution operator (first-order):
:")
37
Inverting Resolution Inverting First order resolution
Inverse resolution (first-order )
")
38
Inverting Resolution Example target predicate : GrandChild(y,x)
D = { GrandChild(Bob,Shannon) } B = {Father(Shannon,Tom) , Father(Tom,Bob)} C C1 L1
 } B = {Father(Shannon,Tom) , Father(Tom,Bob)} C. C1 L1.")
39
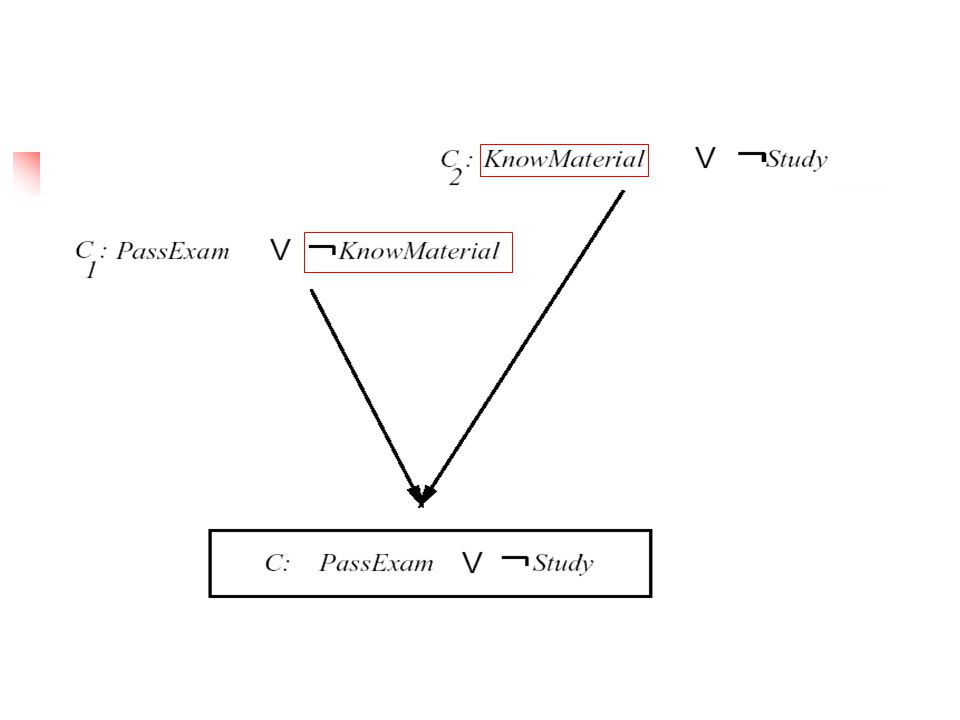
Inverting Resolution C1 C2 C

40
Summary Sequential covering algorithm
Propositional form first-order (FOIL algorithm) A second approach to learning first-order rules Inverting Resolution
 A second approach to learning first-order rules -- Inverting Resolution.")
Similar presentations

>")



>")









 –E.g., days decribed by attributes (or features): Sky, Temp, Humidity, Wind, Water, Forecast.>")

 Vipin Kumar Army High Performance Computing Research Center Department of Computer.>")

