Download presentation
Presentation is loading. Please wait.

1
Creating a Data Interchange Standard for Researchers, Research, and Research Resources: VIVO-ISF Dean B. Krafft Brian Lowe Coalition for Networked Information 10 December 2013

2
What is VIVO? Software: An open-source semantic-web-based researcher and research discovery tool Data: Institution-wide, publicly-visible information about research and researchers Standards: A standard ontology (VIVO data) that interconnects researchers, communities, and campuses using Linked Open Data Community: An open community with strong national and international participation
 that interconnects researchers, communities, and campuses using Linked Open Data Community: An open community with strong national and international participation.")
3
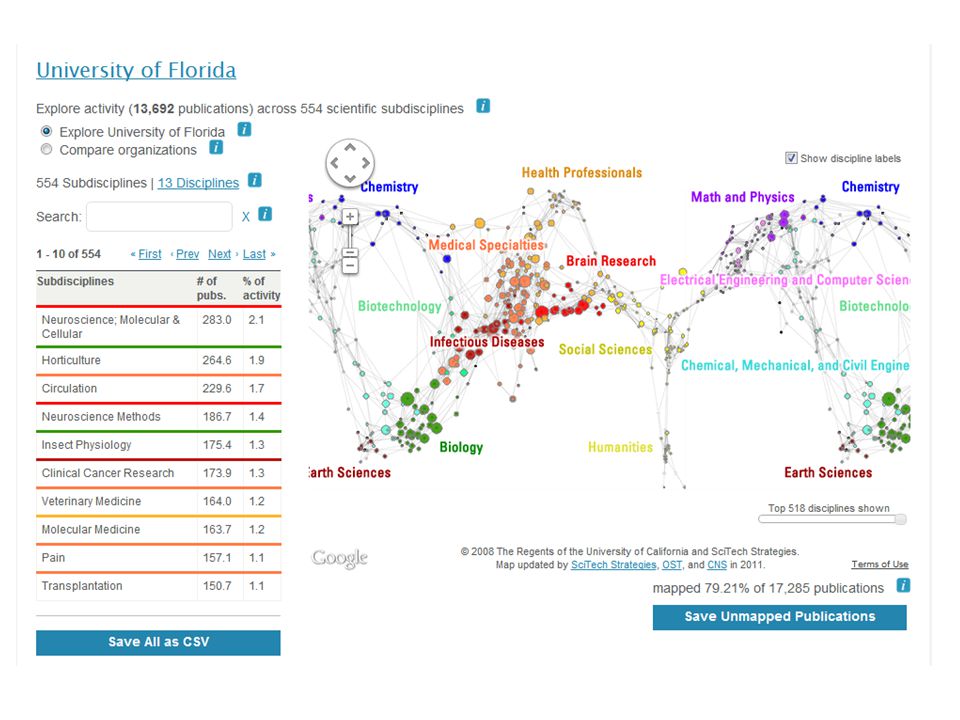
VIVO Normalizes Complex Inputs People Grants Data Google Scholar Center/ Dept/ Program websites Research Facilities & Services Courses Tech transfer Publications VP Research Univ. Communic ations HPC HR data Faculty Reporting Grad School Pubmed Cross Ref Researcher. gov arXiv other databases NIH RePorter Self- editing Other campuses

4
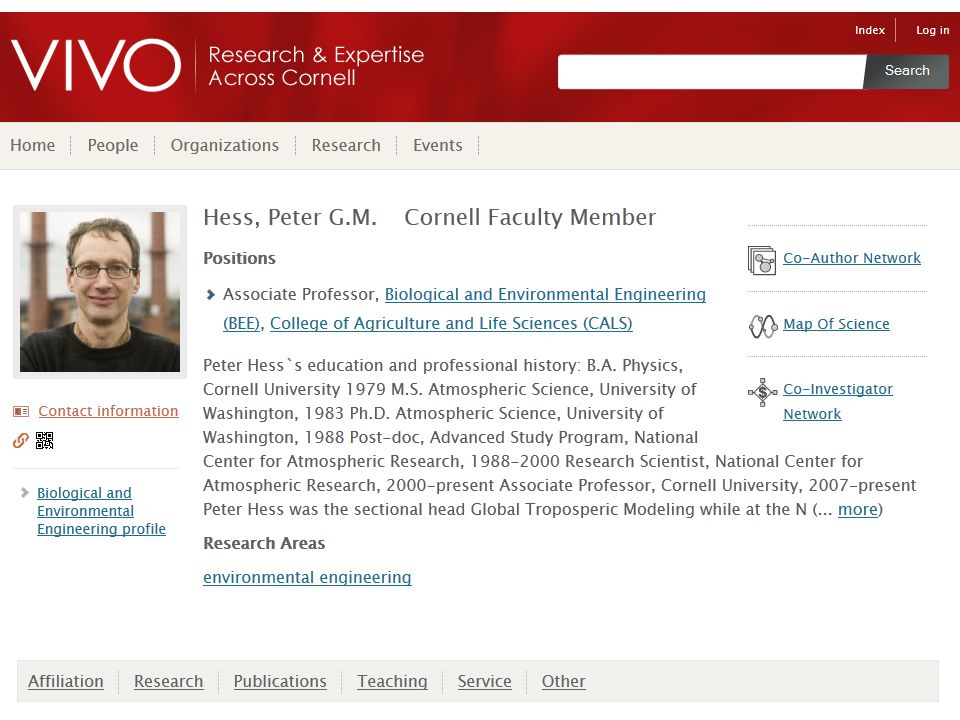
VIVO connects scientists and scholars with and through their research and scholarship

6
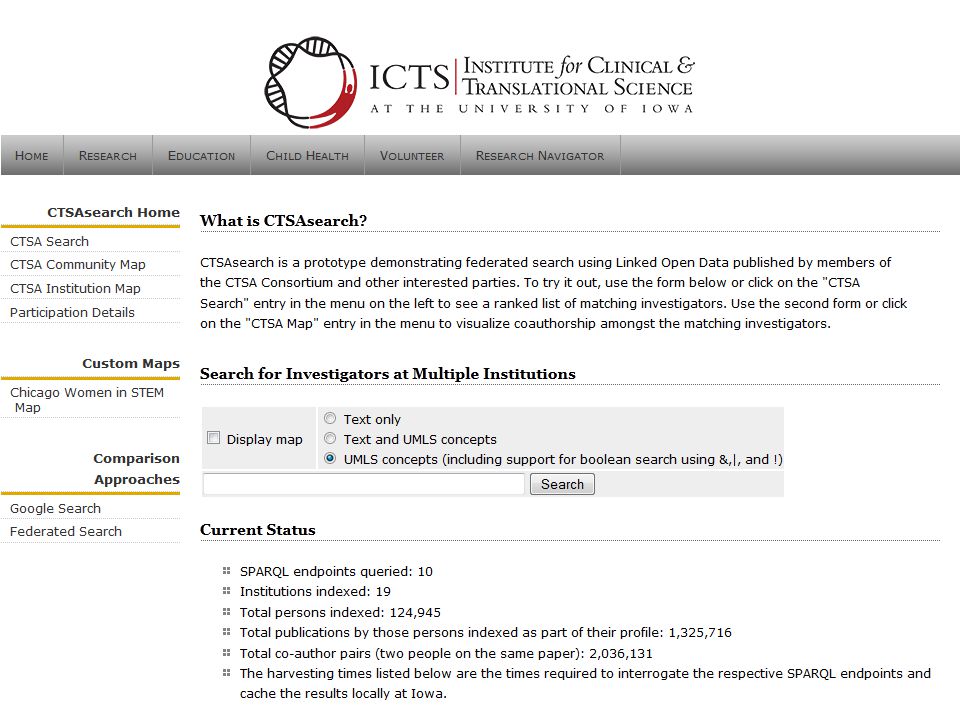
SKE Knowledge Environment http://ske.las.ac.cn/

9
C ustomization

12
The VIVO Community is now over 100 institutions worldwide

13
Why is VIVO important? It is the only standard way to exchange information about research and researchers across diverse institutions It provides authoritative data from institutional databases of record as Linked Open Data Structured VIVO data supports search, analysis and visualization across institutions and consortia It is highly flexible and extensible to cover research resources, facilities, datasets, and more

14
An HTTP request can return HTML or data

15
Value for institutions and consortia Common data substrate – Public, granular and direct – Discovery via external and internal search engines – Available for reuse at many levels Distributed curation – E.g., affiliations beyond what HR system tracks – Data coordination across functional silos – Feeding changes back to systems of record – Direct linking across campuses Data that is visible gets fixed

16
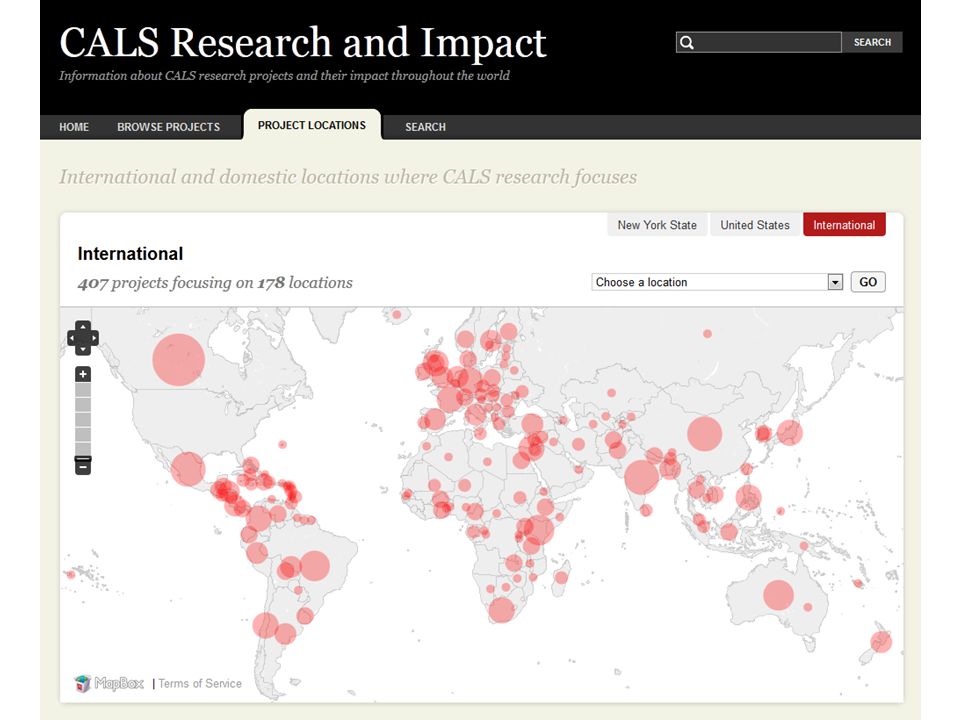
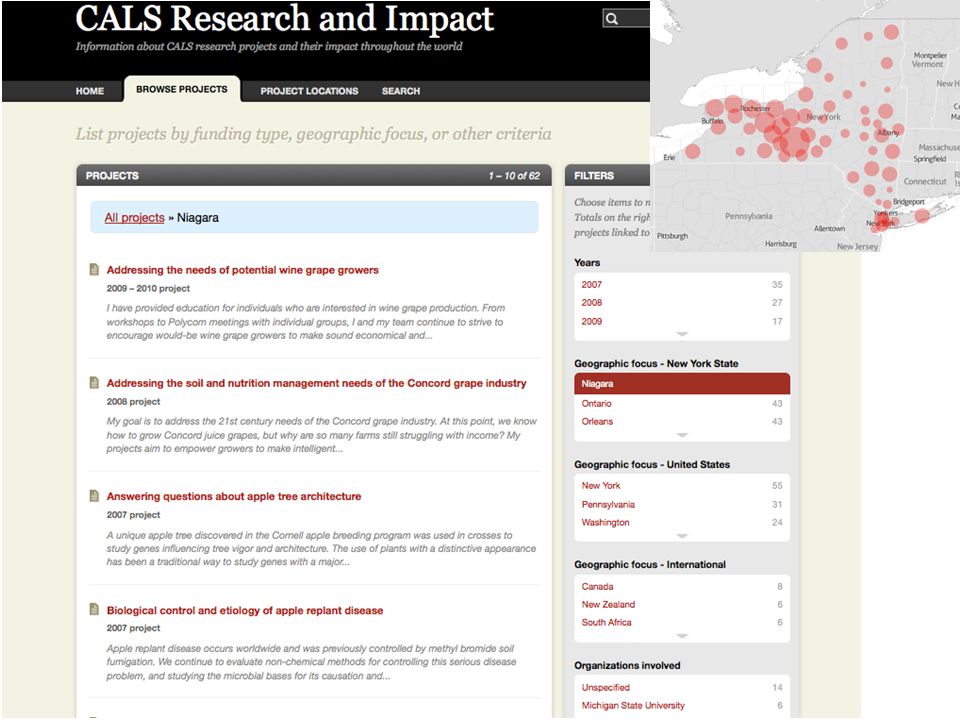
Example: U.S. Dept. of Agriculture Multiple agencies including Agricultural Research Service and U.S. Forest Service VIVO portal for 45,000 intramural researchers Goal to link to Land Grant universities and international agricultural research centers Using VIVO as an integration tool to send data for federal STAR METRICS/SciENCV projects RDF exposed via a SPARQL endpoint constitutes compliance

17
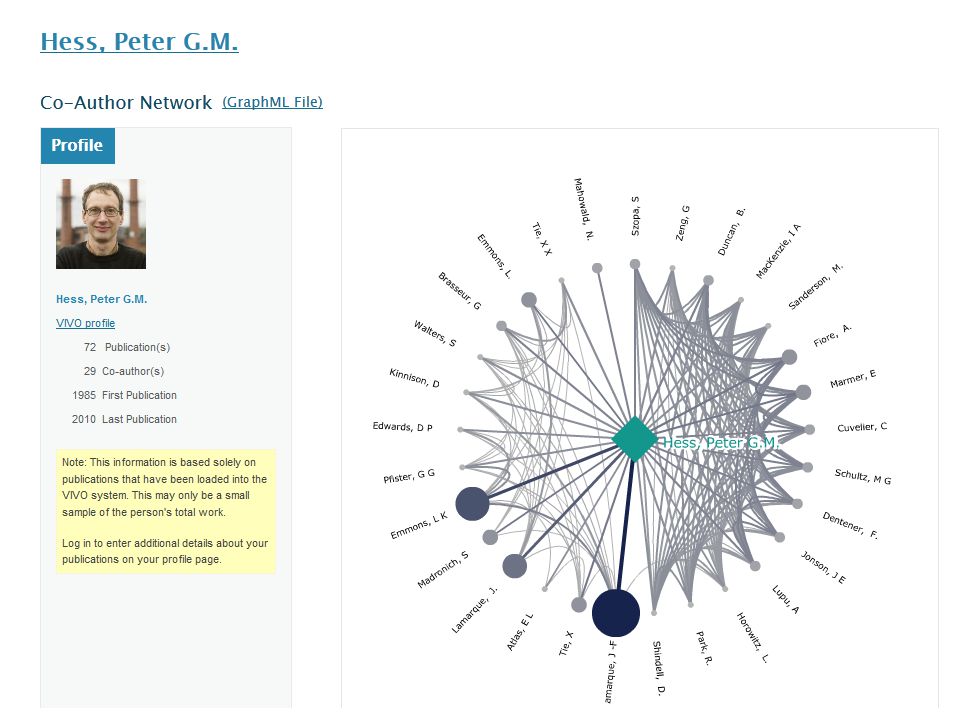
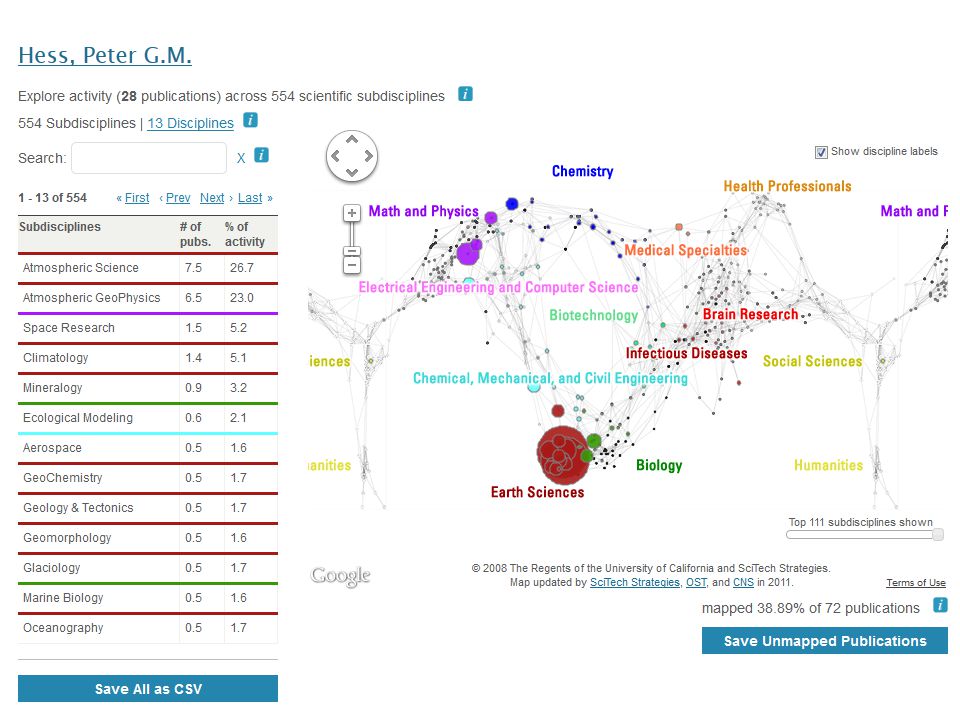
VIVO Exploration and Analytics Since VIVO is structured data, it can be navigated, analyzed, and visualized uniformly within or across institutions VIVO can visualize the strengths of networks within and across institutions You can create dashboards to help understand academic outputs and collaborations VIVO can map research engagements and impact

24
Providing the Context for Research Data Context is critical to finding, understanding, and reusing research data Contexts include: – Narrative publications – The researcher, research resources, grants, etc. – Dataset registries – Structured Knowledge Environments – The web of Linked Open Data

28
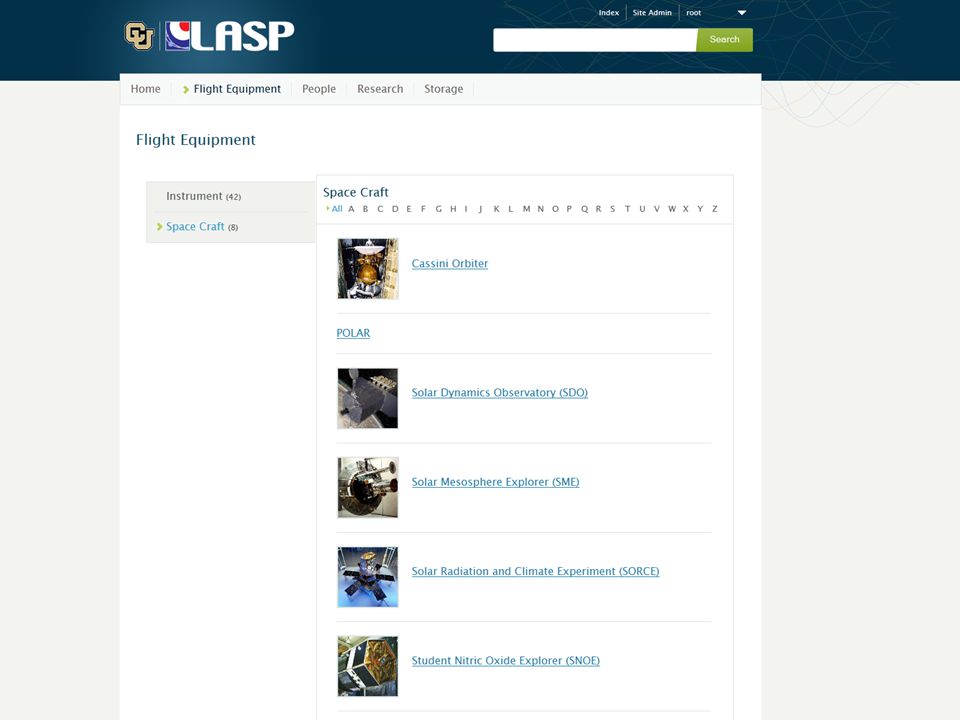
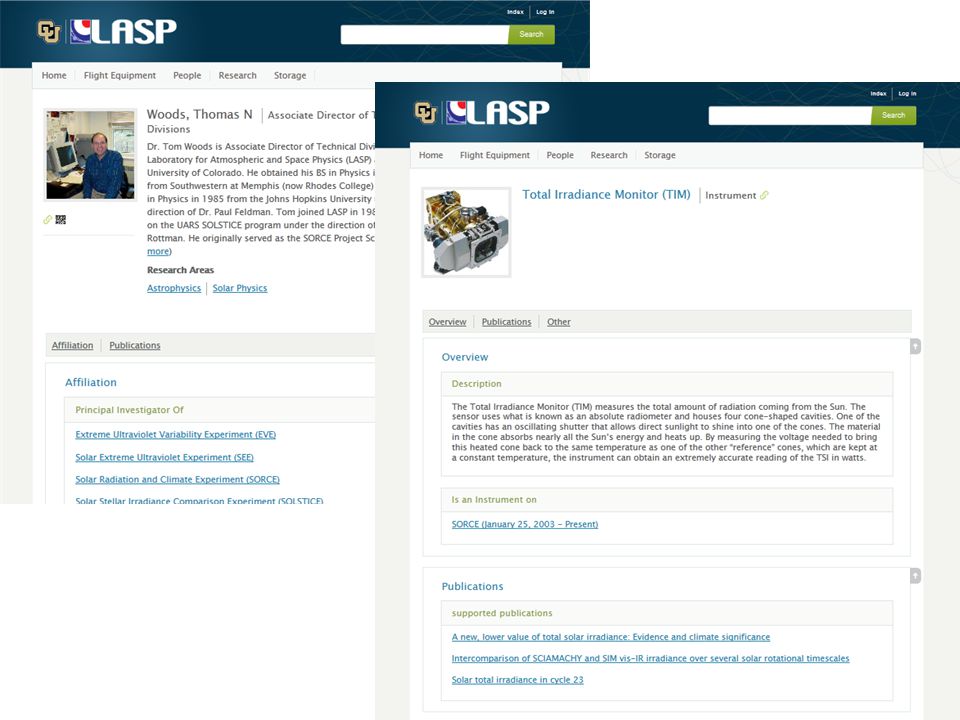
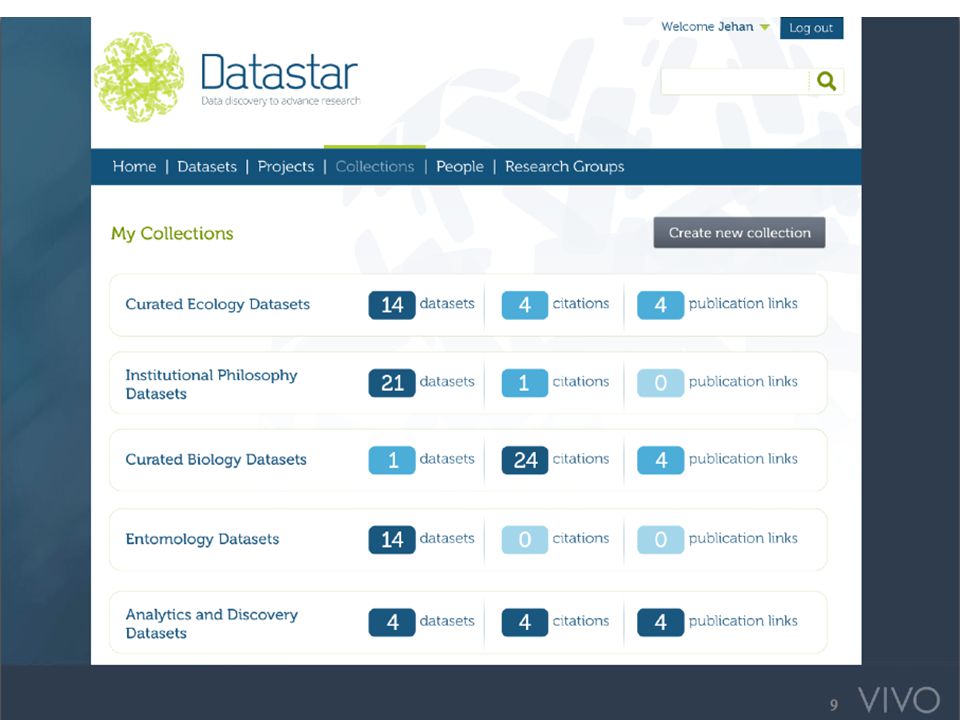
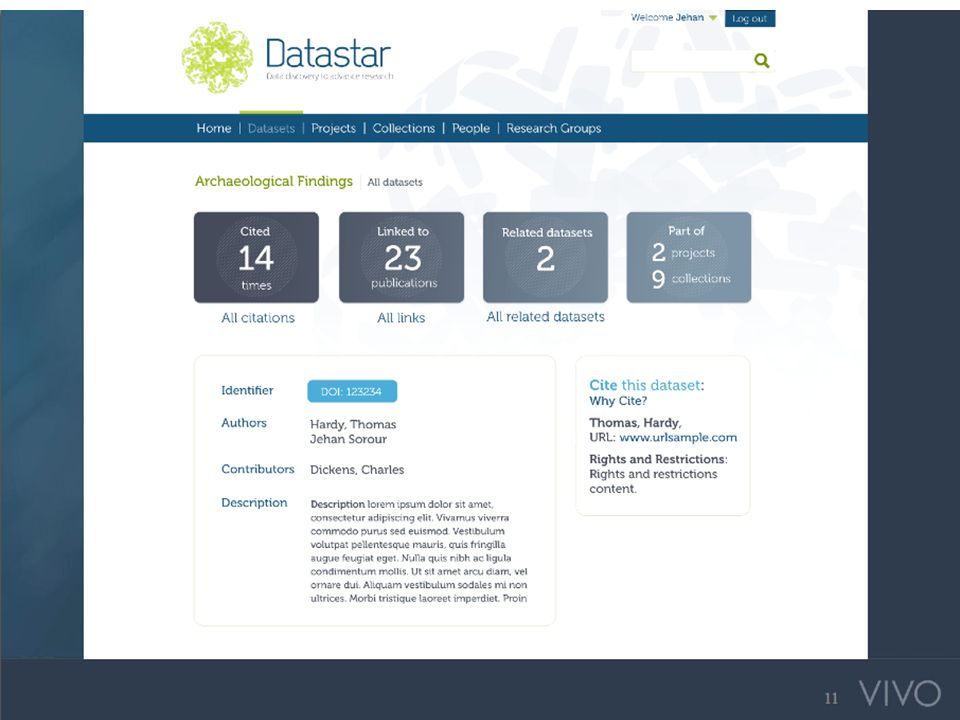
VIVO Dataset Registries VIVO/ANDS consortium in Australia – Link research data with researcher profiles and publications – Harvest to national registry Datastar data registry tool – Add-on to VIVO or independent companion – Complement to other library data-related services – Institute for Museum and Library Services (IMLS) grant
 grant")
29
Melbourne Central Research Data Registry

32
What is VIVO Today? An open community hosted by the DuraSpace 501(c)3 with strong national and international participation, for which we are currently hiring a full-time VIVO Project Director An open suite of software tools A growing body of interoperable data An ontology (VIVO-ISF) with a community- driven process for extension
3 with strong national and international participation, for which we are currently hiring a full-time VIVO Project Director An open suite of software tools A growing body of interoperable data An ontology (VIVO-ISF) with a community- driven process for extension.")
33
VIVO and the Integrated Semantic Framework

34
What is the Integrated Semantic Framework? A semantic infrastructure to represent people based on all the products of their research and activities – To support both networking and reporting A partnership between VIVO, eagle-i, and ShareCenter A Clinical and Translational Information Exchange Project (CTSAConnect) – 18 Months (February 2012 – August 2013) – Funded by NIH NCATS via Booz Allen Hamilton
 – 18 Months (February 2012 – August 2013) – Funded by NIH NCATS via Booz Allen Hamilton.")
35
CTSAconnect Team OHSU: Melissa Haendel, Carlo Torniai, Nicole Vasilevsky, Shahim Essaid, Eric Orwoll Cornell University: Jon Corson-Rikert, Dean Krafft, Brian Lowe University of Florida: Mike Conlon, Chris Barnes, Nicholas Rejack Stony Brook University: Moises Eisenberg, Erich Bremer, Janos Hajagos Harvard University: Daniela Bourges-Waldegg Sophia Cheng Share Center: Chris Kelleher, Will Corbett, Ranjit Das, Ben Sharma University at Buffalo: Barry Smith, Dagobert Soergel

36
People and Resources techniques training protocols affiliation roles grants credentials genes anatomy manufacturer publications

37
Connecting researchers, resources, and clinical activities

38
Beyond Static CVs Distributed data Research and scholarship in context Context aids in disambiguation Contributor roles Outputs and outcomes beyond publications

39
Ontologies for Linked Data First level text – Second level Third level – Fourth level » Fifth Level

40
Linked Data Vocabularies FOAF (people, organizations, groups) VCard (contact information) BIBO (publications) SKOS (terminologies)
 VCard (contact information) BIBO (publications) SKOS (terminologies)")
41
Open Biomedical Ontologies OBI (Ontology of Biomedical Investigations) ERO (eagle-i Research Resource Ontology) RO (Relationship Ontology) IAO (Information Artifact Ontology)
 ERO (eagle-i Research Resource Ontology) RO (Relationship Ontology) IAO (Information Artifact Ontology)")
42
Basic Formal Ontology Process Spatial Region Szabolcs Toth http://www.flickr.com/photos/necccc/5726970855/ Role Site Occurrent Continuant

43
Relationships Person Org. Position Person Article Author- ship

44
Aggregate Data over Time Person Org. Position time interval

45
Aggregate Data over Time Person Org. 1 Position 1 time Interval 1 Org. 2 Position 2 time Interval 2

46
Aggregate Data over Time Person Name VCard time interval

47
Aggregate Data over Time Person Old Name VCard 1 time Interval 1 New Name VCard 2 time Interval 2

48
Aggregate Data over Time Person Author- ship VCard time interval

49
Beyond Publication Bylines Person Project Role What are people doing? Roles in projects, activities Other kinds of scholarly contribution Datasets, resources

50
Roles and Outputs Person Project Role document /resource / etc.

51
Application Examples: Search

52
Ponce VIVO WashU VIVO IU VIVO Cornell Ithaca VIVO Cornell Ithaca VIVO Weill Cornell VIVO Weill Cornell VIVO eagle-I Research resources eagle-I Research resources Harvard Profiles RDF Harvard Profiles RDF Other VIVOs Other VIVOs Digital Vita RDF Digital Vita RDF Iowa Loki RDF Iowa Loki RDF Linked Open Data vivo search.org UF VIVO Scripps VIVO Solr search index Solr search index Alter- nate Solr index Alter- nate Solr index

53
Application Examples: Search

55
Use Cases Find publications supported by grants Discover and re-use expensive equipment and resources Demonstrate importance of facilities services to research results Discover people with access to resources or with expertise in techniques

56
Linking People through Terminologies ISF + UMLS Clinicians ICD9 codes Researchers MeSH keywords linked data http://cstaconnect.org /

57
Humanities and Artistic Works Performances of a work Translations Collections and exhibits Steven McCauley and Theodore Lawless, Brown University http://www.vivoweb.org/files/vivo2013/friday_pm/ VIVO-Humanities_McCauley.pdf

58
Collaborative Development DuraSpace VIVO-ISF Working Group Biweekly calls (Wed 2 pm ET) https://wiki.duraspace.org/display/VIVO/ - look for “Ontology Working Group”
 - look for Ontology Working Group")
59
Interest Groups

60
Linked Data for Libraries: Creating a Scholarly Resource Semantic Information Store (SRSIS)
")
61
Linked Data for Libraries On December 5, 2013, the Andrew W. Mellon Foundation made a two-year $999K grant to Cornell, Harvard, and Stanford starting Jan ‘14 Partners will work together to develop an ontology and linked data sources that provide relationships, metadata, and broad context for Scholarly Information Resources Leverages existing work by both the VIVO project and the Hydra Partnership

62
The Project Team Cornell: Dean Krafft, Jon Corson-Rikert, Brian Lowe, Simeon Warner, and 1.5 new FTE Harvard: David Weinberger, Paul Deschner, and an outside consultant Stanford: Tom Cramer and 1 new FTE

63
“The goal is to create a Scholarly Resource Semantic Information Store model that works both within individual institutions and through a coordinated, extensible network of Linked Open Data to capture the intellectual value that librarians and other domain experts add to information resources when they describe, annotate, organize, select, and use those resources, together with the social value evident from patterns of usage.”

64
Project timeline 2014 Jan-June 2014: Initial ontology design; identify data sources; identify external vocabularies; begin SRSIS and Hydra ActiveTriples development July-Dec 2014: Complete initial ontology; complete initial ActiveTriples development; pilot initial data ingests into Vitro-based SRSIS instance at Cornell

65
Workshop – December 2014 Hold a two-day workshop for 25 attendees from 10-12 interested library, archive, and cultural memory institutions Demonstrate initial prototypes of SRSIS and ontology Obtain feedback on initial ontology design Obtain feedback on overall design and approach Make connections to support participants in piloting this approach at their institutions Understand how institutions see this approach fitting in with their own multi-institutional collaborations and existing cross-institutional efforts such as the Digital Public Library of America, VIVO, and SHARE

66
Project timeline Jan-June 2015 Pilot SRSIS instances at Harvard and Stanford Populate Cornell SRSIS instance from multiple data sources including MARC catalog records, EAD finding aids, VIVO data, CuLLR, and local digital collections Develop a test instance of the SRSIS Search application harvesting RDF across the three partner institutions Integrate SRSIS with ActiveTriples

67
Project timeline July-Dec 2015 Implement fully functional SRSIS instances at Cornell, Harvard, and Stanford Public release of open source SRSIS code and ontology Public release of open source ActiveTriples Hydra Component Create public demonstration of SRSIS Search- based discovery and access system across the three SRSIS instances

68
Project Outcomes Open source extensible SRSIS ontology compatible with VIVO ontology, BIBFRAME, and other existing library LOD efforts Open source SRSIS semantic editing, display, and discovery system Project Hydra compatible interface to SRSIS, using ActiveTriples to support Blacklight search across multiple SRSIS instances

69
For More Information: http://vivoweb.org @VIVOCollab http://vivoweb.org Questions?

Similar presentations





 Project: A Progress Report Dean B. Krafft, Cornell University Library Tom Cramer, Stanford University Libraries CNI.>")










>")


