Download presentation
Presentation is loading. Please wait.

1
Social Networks First half based on slides by Kentaro Toyama,
And their applications to Web First half based on slides by Kentaro Toyama, Microsoft Research, India

2
Networks—Physical & Cyber
Typhoid Mary (Mary Mallon) Patient Zero (Gaetan Dugas)
 Patient Zero. (Gaetan Dugas)")
4
Applications of Network Theory
World Wide Web and hyperlink structure The Internet and router connectivity Collaborations among… Movie actors Scientists and mathematicians Sexual interaction Cellular networks in biology Food webs in ecology Phone call patterns Word co-occurrence in text Neural network connectivity of flatworms Conformational states in protein folding Source: Albert and Barabasi, “Statistical mechanics of complex networks.” Review of Modern Physics. 74: (2002)
")
5
Web Applications of Social Networks
Web pages (and link-structure) Online social networks (FOAF networks such as ORKUT, myspace etc) Blogs Analyzing influence/importance Page Rank Related to recursive in-degree computation Authorities/Hubs Discovering Communities Finding near-cliques Analyzing Trust Propagating Trust Using propagated trust to fight spam In In Web page ranking
 Online social networks (FOAF networks such as ORKUT, myspace etc) Blogs. Analyzing influence/importance. Page Rank. Related to recursive in-degree computation. Authorities/Hubs. Discovering Communities. Finding near-cliques. Analyzing Trust. Propagating Trust. Using propagated trust to fight spam. In . In Web page ranking.")
7
Society as a Graph People are represented as nodes.

8
Society as a Graph People are represented as nodes.
Relationships are represented as edges. (Relationships may be acquaintanceship, friendship, co-authorship, etc.)
")
9
Society as a Graph People are represented as nodes.
Relationships are represented as edges. (Relationships may be acquaintanceship, friendship, co-authorship, etc.) Allows analysis using tools of mathematical graph theory
 Allows analysis using tools of mathematical graph theory.")
10
History (based on Freeman, 2000)
17th century: Spinoza developed first model 1937: J.L. Moreno introduced sociometry; he also invented the sociogram 1948: A. Bavelas founded the group networks laboratory at MIT; he also specified centrality

11
History (based on Freeman, 2000)
1949: A. Rapaport developed a probability based model of information flow 50s and 60s: Distinct research by individual researchers 70s: Field of social network analysis emerged. New features in graph theory – more general structural models Better computer power – analysis of complex relational data sets

12
Graphs – Sociograms (based on Hanneman, 2001)
Strength of ties: Nominal Signed Ordinal Valued

13
Visualization Software: Krackplot
Sources:

14
Connections Size Density Out-degree In-degree Number of nodes
Number of ties that are present the amount of ties that could be present Out-degree Sum of connections from an actor to others In-degree Sum of connections to an actor

15
Distance Walk Geodesic distance Maximum flow
A sequence of actors and relations that begins and ends with actors Geodesic distance The number of relations in the shortest possible walk from one actor to another Maximum flow The amount of different actors in the neighborhood of a source that lead to pathways to a target

16
Some Measures of Power & Prestige (based on Hanneman, 2001)
Degree Sum of connections from or to an actor Transitive weighted degreeAuthority, hub, pagerank Closeness centrality Distance of one actor to all others in the network Betweenness centrality Number that represents how frequently an actor is between other actors’ geodesic paths

17
Cliques and Social Roles (based on Hanneman, 2001)
Sub-set of actors More closely tied to each other than to actors who are not part of the sub-set (A lot of work on “trawling” for communities in the web-graph) Often, you first find the clique (or a densely connected subgraph) and then try to interpret what the clique is about Social roles Defined by regularities in the patterns of relations among actors
 Often, you first find the clique (or a densely connected subgraph) and then try to interpret what the clique is about. Social roles. Defined by regularities in the patterns of relations among actors.")
18
Outline Small Worlds Random Graphs Alpha and Beta Power Laws
Searchable Networks Six Degrees of Separation

19
Outline Small Worlds Random Graphs Alpha and Beta Power Laws
Searchable Networks Six Degrees of Separation

20
Trying to make friends Kentaro
When I first decided to move to India, I wondered about how I could make new friends.

21
Trying to make friends Microsoft Bash Kentaro
First, I met Bash at Microsoft, through an NGO called Asha for Eduation.

22
Trying to make friends Microsoft Bash Asha Kentaro Ranjeet
Bash suggested I contact Asha’s Bangalore chapter. On my second day in India, I ended up going on a field trip with Asha Bangalore, and met Ranjeet. We started to talk, and when I mentioned I had gone to graduate school at Yale, he said, “I know one person from Yale, but I think he was there earlier than you. His name was Sharad.”

23
Ranjeet and I already had a friend in common!
Trying to make friends Microsoft Bash Asha Kentaro Ranjeet Yale Sharad New York City Ranjeet and I already had a friend in common! Sharad was my roommate at Yale.

24
I didn’t have to worry… Bash Kentaro Sharad Anandan Venkie Karishma
Maithreyi Soumya

25
It’s a small world after all!
Rao Bash Kentaro Ranjeet Sharad Prof. McDermott Anandan Prof. Sastry Prof. Veni Prof. Kannan Prof. Balki Venkie Ravi’s Father Karishma Ravi Prof. Prahalad Pres. Kalam Maithreyi Pawan Prof. Jhunjhunwala Soumya Aishwarya PM Manmohan Singh Dr. Isher Judge Ahluwalia Amitabh Bachchan Nandana Sen Dr. Montek Singh Ahluwalia Prof. Amartya Sen

26
The Kevin Bacon Game Invented by Albright College students in 1994:
Craig Fass, Brian Turtle, Mike Ginelly Goal: Connect any actor to Kevin Bacon, by linking actors who have acted in the same movie. Oracle of Bacon website uses Internet Movie Database (IMDB.com) to find shortest link between any two actors: Boxed version of the Kevin Bacon Game
 to find shortest link between any two actors: Boxed version of the. Kevin Bacon Game.")
27
The Kevin Bacon Game Kevin Bacon Amitabh Bachchan Tim Robbins Om Puri
An Example Kevin Bacon Mystic River (2003) Tim Robbins Code 46 (2003) Om Puri (Actually, Amitabh is closer to Kevin, but the minimal path of 4 uses two actors who always play minor parts in movies, so I used this path, which involves better known actors.) Yuva (2004) Rani Mukherjee Black (2005) Amitabh Bachchan
 Tim Robbins. Code 46 (2003) Om Puri. (Actually, Amitabh is closer to Kevin, but the minimal path of 4 uses two actors who always play minor parts in movies, so I used this path, which involves better known actors.) Yuva (2004) Rani Mukherjee. Black (2005) Amitabh Bachchan.")
28
…actually Bachchan has a Bacon number 3
Perhaps the other path is deemed more diverse/ colorful…

29
The Kevin Bacon Game Total # of actors in database: ~550,000
Average path length to Kevin: Actor closest to “center”: Rod Steiger (2.53) Rank of Kevin, in closeness to center: th Most actors are within three links of each other! Source: Watts (2003), Six Degrees; Barabasi (2003), Linked. Center of Hollywood?
 Rank of Kevin, in closeness to center: 876th. Most actors are within three links of each other! Source: Watts (2003), Six Degrees; Barabasi (2003), Linked. Center of Hollywood")
30
Not Quite the Kevin Bacon Game
Cavedweller (2004) Aidan Quinn Looking for Richard (1996) Kevin Spacey Ben and I are good friends from college. Ben wrote a book, Bringing Down the House, for which the movie rights were sold to Kevin Spacey (I’ve seen a photo of Ben and Kevin posing in a picture with Hugh Hefner, of all people). Kevin is two movies away from Kevin Bacon. Bringing Down the House (2004) Ben Mezrich Roommates in college (1991) Kentaro Toyama
 Aidan Quinn. Looking for Richard (1996) Kevin Spacey. Ben and I are good friends from college. Ben wrote a book, Bringing Down the House, for which the movie rights were sold to Kevin Spacey (I’ve seen a photo of Ben and Kevin posing in a picture with Hugh Hefner, of all people). Kevin is two movies away from Kevin Bacon. Bringing Down the House (2004) Ben Mezrich. Roommates in college (1991) Kentaro Toyama.")
31
Erdős Number (Bacon game for Brainiacs )
Number of links required to connect scholars to Erdős, via co-authorship of papers Erdős wrote papers with 507 co-authors. Jerry Grossman’s (Oakland Univ.) website allows mathematicians to compute their Erdos numbers: Connecting path lengths, among mathematicians only: average is 4.65 maximum is 13 Source: Paul Erdős ( ) Unlike Bacon, Erdos has better centrality in his network
 website allows mathematicians to compute their Erdos numbers: Connecting path lengths, among mathematicians only: average is maximum is 13. Source: Paul Erdős ( ) Unlike Bacon, Erdos has. better centrality in his network.")
32
Erdős Number Paul Erdős Kentaro Toyama Mike Molloy Dimitris Achlioptas
An Example Paul Erdős Alon, N., P. Erdos, D. Gunderson and M. Molloy (2002). On a Ramsey-type Problem. J. Graph Th. 40, Mike Molloy Achlioptas, D. and M. Molloy (1999). Almost All Graphs with n Edges are not 3-Colourable. Electronic J. Comb. (6), R29. Dimitris Achlioptas Achlioptas, D., F. McSherry and B. Schoelkopf. Sampling Techniques for Kernel Methods. NIPS 2001, pages Bernard Schoelkopf Romdhani, S., P. Torr, B. Schoelkopf, and A. Blake (2001). Computationally efficient face detection. In Proc. Int’l. Conf. Computer Vision, pp Andrew Blake Toyama, K. and A. Blake (2002). Probabilistic tracking with exemplars in a metric space. International Journal of Computer Vision. 48(1):9-19. Kentaro Toyama
. On a Ramsey-type Problem. J. Graph Th. 40, Mike Molloy. Achlioptas, D. and M. Molloy (1999). Almost All Graphs with n Edges are not 3-Colourable. Electronic J. Comb. (6), R29. Dimitris Achlioptas. Achlioptas, D., F. McSherry and B. Schoelkopf. Sampling Techniques for Kernel Methods. NIPS 2001, pages Bernard Schoelkopf. Romdhani, S., P. Torr, B. Schoelkopf, and A. Blake (2001). Computationally efficient face detection. In Proc. Int’l. Conf. Computer Vision, pp Andrew Blake. Toyama, K. and A. Blake (2002). Probabilistic tracking with exemplars in a metric space. International Journal of Computer Vision. 48(1):9-19. Kentaro Toyama.")
33
..and Rao has even shorter distance

34
..collaboration distances

35
--Project part 1 returned --Midterm after spring break
3/9 --Project part 1 returned --Midterm after spring break

36
Six Degrees of Separation
Milgram (1967) The experiment: Random people from Nebraska were to send a letter (via intermediaries) to a stock broker in Boston. Could only send to someone with whom they were on a first-name basis. Among the letters that found the target, the average number of links was six. Milgram was a brilliant psychologist, notorious for his studies of obedience, where subjects continued to deliver what they believed to be painful electric shocks, just because a person in a lab coat told them they should do so as part of an experiment. Note on the small-worlds experiment: – Not many of the letters in the original experiment arrived. -- The experiment presaged some later discoveries, including hubs, tendency to go by geography and profession, etc. Stanley Milgram ( ) Many “issues” with the experiment…
 The experiment: Random people from Nebraska were to send a letter (via intermediaries) to a stock broker in Boston. Could only send to someone with whom they were on a first-name basis. Among the letters that found the target, the average number of links was six. Milgram was a brilliant psychologist, notorious for his studies of obedience, where subjects continued to deliver what they believed to be painful electric shocks, just because a person in a lab coat told them they should do so as part of an experiment. Note on the small-worlds experiment: – Not many of the letters in the original experiment arrived. -- The experiment presaged some later discoveries, including hubs, tendency to go by geography and profession, etc. Stanley Milgram ( ) Many issues with the experiment…")
37
Some issues with Milgram’s setup
A large fraction of his test subjects were stockbrokers So are likely to know how to reach the “goal” stockbroker A large fraction of his test subjects were in boston As was the “goal” stockbroker A large fraction of letters never reached Only 20% reached

38
Six Degrees of Separation
Robert Sternberg Mike Tarr Kentaro Toyama Allan Wagner ? Milgram (1967) John Guare wrote a play called Six Degrees of Separation, based on this concept. This link to Milgram is my best guess, based on information I could find on the Internet: Allan Wagner was at the Yale Psychology department through , when Milgram did his experiments. Sternberg was chairman of the psych dept in 1992, during which time, both Allan Wagner and Mike Tarr were in the same department. I know Mike. “Everybody on this planet is separated by only six other people. Six degrees of separation. Between us and everybody else on this planet. The president of the United States. A gondolier in Venice… It’s not just the big names. It’s anyone. A native in a rain forest. A Tierra del Fuegan. An Eskimo. I am bound to everyone on this planet by a trail of six people…”
 John Guare wrote a play called Six Degrees of Separation, based on this concept. This link to Milgram is my best guess, based on information I could find on the Internet: Allan Wagner was at the Yale Psychology department through , when Milgram did his experiments. Sternberg was chairman of the psych dept in 1992, during which time, both Allan Wagner and Mike Tarr were in the same department. I know Mike. Everybody on this planet is separated by only six other people. Six degrees of separation. Between us and everybody else on this planet. The president of the United States. A gondolier in Venice… It’s not just the big names. It’s anyone. A native in a rain forest. A Tierra del Fuegan. An Eskimo. I am bound to everyone on this planet by a trail of six people…")
39
Outline Small Worlds Random Graphs--- Or why does the “small world” phenomena exist? Alpha and Beta Power Laws Searchable Networks Six Degrees of Separation

40
Random Graphs N = 12 Erdős and Renyi (1959) p = 0.0 ; k = 0 N nodes A pair of nodes has probability p of being connected. Average degree, k ≈ pN What interesting things can be said for different values of p or k ? (that are true as N ∞) p = 0.09 ; k = 1 p = 1.0 ; k ≈ N
 p = 0.09 ; k = 1. p = 1.0 ; k ≈ N.")
41
Random Graphs Erdős and Renyi (1959) p = 0.0 ; k = 0 p = 0.09 ; k = 1
Let’s look at… Size of the largest connected cluster p = 1.0 ; k ≈ N Diameter (maximum path length between nodes) of the largest cluster If Diameter is O(log(N)) then it is a “Small World” network Average path length between nodes (if a path exists)
 of the largest cluster. If Diameter is O(log(N)) then it is a Small World network. Average path length between nodes (if a path exists)")
42
An examlple random graph

43
Random Graphs Erdős and Renyi (1959) p = 0.0 ; k = 0
p = 1.0 ; k ≈ N Size of largest component 1 5 11 12 Diameter of largest component 4 7 1 Average path length between (connected) nodes 0.0 2.0 4.2 1.0
 nodes")
44
Random Graphs Where are human Erdős and Renyi (1959)
social networks in this? Erdős and Renyi (1959) Percentage of nodes in largest component Diameter of largest component (not to scale) k ≈ pN If k < 1: small, isolated clusters small diameters short path lengths At k = 1: a giant component appears diameter peaks path lengths are high For k > 1: almost all nodes connected diameter shrinks path lengths shorten 1.0 This is similar to phase transitions in physics, when gases become liquids and liquids become solids. (Even Bose-Einstein condensation is also relevant, it seems.) 1.0 k phase transition
 Percentage of nodes in largest component. Diameter of largest component (not to scale) k ≈ pN. If k < 1: small, isolated clusters. small diameters. short path lengths. At k = 1: a giant component appears. diameter peaks. path lengths are high. For k > 1: almost all nodes connected. diameter shrinks. path lengths shorten This is similar to phase transitions in physics, when gases become liquids and liquids become solids. (Even Bose-Einstein condensation is also relevant, it seems.) 1.0. k. phase transition.")
45
Random Graphs What does this mean?
David Mumford Peter Belhumeur Kentaro Toyama Fan Chung Erdős and Renyi (1959) What does this mean? If connections between people can be modeled as a random graph, then… Because the average person easily knows more than one person (k >> 1), We live in a “small world” where within a few links, we are connected to anyone in the world. Erdős and Renyi showed that average path length between connected nodes is The ln(N) expression is consistent with intuition about branching factors for trees. Even with lots of node repetition, if only 10% of each person’s contacts are not duplicates, links would rapidly span the entire population. I know Peter from the computer vision community. Peter was a student of Mumford’s, I think. David Mumford is a Fields-Medal-winning mathematician, who has singlehandedly reduced the Erdos number of most computer vision researchers by doing work in computer vision. Fan Chung is a mathematician who has authored papers with both Erdos and Mumford.
 What does this mean If connections between people can be modeled as a random graph, then… Because the average person easily knows more than one person (k >> 1), We live in a small world where within a few links, we are connected to anyone in the world. Erdős and Renyi showed that average. path length between connected nodes is. The ln(N) expression is consistent with intuition about branching factors for trees. Even with lots of node repetition, if only 10% of each person’s contacts are not duplicates, links would rapidly span the entire population. I know Peter from the computer vision community. Peter was a student of Mumford’s, I think. David Mumford is a Fields-Medal-winning mathematician, who has singlehandedly reduced the Erdos number of most computer vision researchers by doing work in computer vision. Fan Chung is a mathematician who has authored papers with both Erdos and Mumford.")
46
Random Graphs BIG “IF”!!! What does this mean?
David Mumford Peter Belhumeur Kentaro Toyama Fan Chung Erdős and Renyi (1959) What does this mean? If connections between people can be modeled as a random graph, then… Because the average person easily knows more than one person (k >> 1), We live in a “small world” where within a few links, we are connected to anyone in the world. Erdős and Renyi computed average path length between connected nodes to be: BIG “IF”!!!
 What does this mean If connections between people can be modeled as a random graph, then… Because the average person easily knows more than one person (k >> 1), We live in a small world where within a few links, we are connected to anyone in the world. Erdős and Renyi computed average. path length between connected nodes to be: BIG IF !!!")
47
Outline Small Worlds Random Graphs Alpha and Beta
Power Laws ---and scale-free networks Searchable Networks Six Degrees of Separation

48
Degree Distribution in Random Graphs
In a Erdos-Renyi (uniform) Random Graph with n nodes, the probability that a node has degree k is given by As ninfinity, this becomes a Poisson distribution (where l is the mean degree and is equal to pn) Unlike normal distribution which has two parameters poisson has only one.. (so fewer degrees of freedom) Both mean and variance are l
 Random Graph with n nodes, the probability that a node has degree k is given by. As ninfinity, this becomes a Poisson distribution (where l is the mean degree and is equal to pn) Unlike normal distribution. which has two parameters. poisson has only one.. (so fewer degrees of. freedom) Both mean and. variance are l.")
49
Degree Distributions in Real Networks (in log-log spae
Poisson won’t Give straight line Plot in log-log… We have straight lines in log-log space with negative slope (say -r) So log y = -r log k log y = log k-r y = k-r So, y is reducing polynomially w.r.t. k (not exponentially as would be mandated by poisson..) Source: Albert and Barabasi, “Statistical mechanics of complex networks.” Review of Modern Physics. 74: (2002) Power laws in real networks: (a) WWW hyperlinks (b) co-starring in movies (c) co-authorship of physicists (d) co-authorship of neuroscientists
 So log y = -r log k log y = log k-r y = k-r. So, y is reducing polynomially w.r.t. k. (not exponentially as would be mandated. by poisson..) Source: Albert and Barabasi, Statistical mechanics of complex networks. Review of Modern Physics. 74: (2002) Power laws in real networks: (a) WWW hyperlinks. (b) co-starring in movies. (c) co-authorship of physicists. (d) co-authorship of neuroscientists.")
50
Degree Distribution & Power Laws
Rare events are not so rare! --they are only polynomially less probable (as against exponentially less probable in Poisson) Sharp drop (*NOT* surprising) Long tail (Surprising!) Both mean and variance are l k-r Source: Albert and Barabasi, “Statistical mechanics of complex networks.” Review of Modern Physics. 74: (2002) But, many real-world networks exhibit a power-law distribution. also called “Heavy tailed” distribution Degree distribution of a random graph, N = 10,000 p = k = 15. (Curve is a Poisson curve, for comparison.) Typically 2<r<3. For web graph r ~ 2.1 for in degree distribution 2.7 for out degree distribution Note that poisson decays exponentially while power law decays polynomially
 Sharp drop. (*NOT* surprising) Long tail. (Surprising!) Both mean and. variance are l. k-r. Source: Albert and Barabasi, Statistical mechanics of complex networks. Review of Modern Physics. 74: (2002) But, many real-world networks exhibit a power-law distribution. also called Heavy tailed distribution. Degree distribution of a random graph, N = 10,000 p = k = 15. (Curve is a Poisson curve, for comparison.) Typically 2<r<3. For web graph. r ~ 2.1 for in degree distribution. 2.7 for out degree distribution. Note that poisson decays exponentially. while power law decays polynomially.")
51
The Tale of Tails.. Uniform distribution Power-law distribution
No tail No point talking about 6-sigma kids.. They are no different.. Power-law distribution Long tail 6-sigma kids are not all that special Exponential distribution Fast vanishing tail 6-sigma kids are special తాడిని తన్నే వాడోకడుంటే, వాడి తలదన్నే వాడిన్కోడుంటాడు

52
Random vs. Real Social networks
Real networks are not exactly like these Tend to have a relatively few nodes of high connectivity (the “Hub” nodes) These networks are called “Scale-free” networks Macro properties scale-invariant Random network models introduce an edge between any pair of vertices with a probability p The problem here is NOT randomness, but rather the distribution used (which, in this case, is uniform)
 These networks are called Scale-free networks. Macro properties scale-invariant. Random network models introduce an edge between any pair of vertices with a probability p. The problem here is NOT randomness, but rather the distribution used (which, in this case, is uniform)")
53
Properties of Power law distributions
Ratio of area under the curve [from b to infinity] to [from a to infinity] =(b/a)1-r Depends only on the ratio of b to a and not on the absolute values “scale-free”/ “self-similar” A moment of order m exists only if r>m+1 Even mean doesn’t exist for r=1 (which defines a harmonic series) a b
1-r. Depends only on the ratio of b to a and not on the absolute values. scale-free / self-similar A moment of order m exists only if r>m+1. Even mean doesn’t exist for r=1 (which defines a harmonic series) a. b.")
54
Power Laws Albert and Barabasi (1999) Power-law distributions are straight lines in log-log space. -- slope being r y=k-r log y = -r log k ly= -r lk How should random graphs be generated to create a power-law distribution of node degrees? Hint: Pareto’s* Law: Wealth distribution follows a power law. Source: Albert and Barabasi, “Statistical mechanics of complex networks.” Review of Modern Physics. 74: (2002) Power laws in real networks: (a) WWW hyperlinks (b) co-starring in movies (c) co-authorship of physicists (d) co-authorship of neuroscientists * Same Velfredo Pareto, who defined Pareto optimality in game theory.
 Power laws in real networks: (a) WWW hyperlinks. (b) co-starring in movies. (c) co-authorship of physicists. (d) co-authorship of neuroscientists. * Same Velfredo Pareto, who defined Pareto optimality in game theory.")
55
Generating Scale-free Networks..
“The rich get richer!” Power-law distribution of node-degree arises if (but not “only if”) As Number of nodes grow edges are added in proportion to the number of edges a node already has. Alternative: Copy model—where the new node copies a random subset of the links of an existing node Sort of close to the WEB reality Examples of Scale-free networks (i.e., those that exhibit power law distribution of in degree) Social networks, including collaboration networks. An example that has been studied extensively is the collaboration of movie actors in films. Protein-interaction networks. Sexual partners in humans, which affects the dispersal of sexually transmitted diseases. Many kinds of computer networks, including the World Wide Web.
 As Number of nodes grow edges are added in proportion to the number of edges a node already has. Alternative: Copy model—where the new node copies a random subset of the links of an existing node. Sort of close to the WEB reality. Examples of Scale-free networks (i.e., those that exhibit power law distribution of in degree) Social networks, including collaboration networks. An example that has been studied extensively is the collaboration of movie actors in films. Protein-interaction networks. Sexual partners in humans, which affects the dispersal of sexually transmitted diseases. Many kinds of computer networks, including the World Wide Web.")
56
3/11 Road network vs. Airline network
Which is uniform-random and which is scale-free?

57
“uniform-random networks” are also called “exponential” Networks --as their tail tails off exponentially

58
Small-world Phenomena in Scale-free Networks
Scale-free networks also exhibit small-world phenomena For a random graph having the same power law distribution as the Web graph, it has been shown that Avg path length = log10 N However, scale-free networks tend to be more brittle You can drastically reduce the connectivity by deliberately taking out a few nodes This can also be seen as an opportunity.. Disease prevention by quarantining super-spreaders As they actually did to poor Typhoid Mary..

59
Attacks vs. Disruptions on Scale-free vs. Random networks
A random percentage of the nodes are removed How does the diameter change? Increases monotonically and linearly in random graphs Remains almost the same in scale-free networks Since a random sample is unlikely to pick the high-degree nodes Attack A precentage of nodes are removed willfully (e.g. in decreasing order of connectivity) How does the diameter change? For random networks, essentially no difference from disruption All nodes are approximately same For scale-free networks, diameter doubles for every 5% node removal! This is an opportunity when you are fighting to contain spread…
 How does the diameter change For random networks, essentially no difference from disruption. All nodes are approximately same. For scale-free networks, diameter doubles for every 5% node removal! This is an opportunity when you are fighting to contain spread…")
60
Exploiting/Navigating Small-Worlds
How does a node in a social network find a path to another node? 6 degrees of separation will lead to n6 search space (n=num neighbors) Easy if we have global graph.. But hard otherwise Case 1: Centralized access to network structure Paths between nodes can be computed by shortest path algorithms E.g. All pairs shortest path ..so, small-world ness is trivial to exploit.. This is what ORKUT, Linkedin etc are trying to do.. Case 2: Local access to network structure Each node only knows its own neighborhood Search without children-generation function Idea 1: Broadcast method Obviously crazy as it increases traffic everywhere Idea 2: Directed search But which neighbors to select? Are there conditions under which decentralized search can still be easy? There are very few “fully decentralized” search applications (unless centralization is banned ) hybrid methods between Case 1 & 2 typical Computing one’s Erdos number used to take days in the past!
 Easy if we have global graph.. But hard otherwise. Case 1: Centralized access to network structure. Paths between nodes can be computed by shortest path algorithms. E.g. All pairs shortest path. ..so, small-world ness is trivial to exploit.. This is what ORKUT, Linkedin etc are trying to do.. Case 2: Local access to network structure. Each node only knows its own neighborhood. Search without children-generation function Idea 1: Broadcast method. Obviously crazy as it increases traffic everywhere. Idea 2: Directed search. But which neighbors to select Are there conditions under which decentralized search can still be easy There are very few fully decentralized search. applications (unless centralization is banned ) hybrid methods between Case 1 & 2 typical. Computing one’s Erdos number used to take days in the past!")
61
Searchability in Small World Networks
Searchability is measured in terms of Expected time to go from a random source to a random destination We know that in Smallworld networks, the diameter is exponentially smaller than the size of the network. If the expected time is proportional to some small power of log N, we are doing well Qn: Is this always the case in small world networks? To begin to answer this we need to look generative models that take a notion of absolute (lattice or coordinate-based) neighborhood into account Kleinberg experimented with Lattice networks (where the network is embedded in a lattice—with most connections to the lattice neighbors, but a few shortcuts to distant neighbors) and found that the answer is “Not always” Source: Jon Kleinberg, “Navigation in a small world.” Science, 406:845 (2000). Kleinberg (2000)
 neighborhood into account. Kleinberg experimented with Lattice networks (where the network is embedded in a lattice—with most connections to the lattice neighbors, but a few shortcuts to distant neighbors) and found that the answer is Not always Source: Jon Kleinberg, Navigation in a small world. Science, 406:845 (2000). Kleinberg (2000)")
62
Summary A network is considered to exhibit small world phenomenon, if its diameter is approximately logarithm of its size (in terms of number of nodes) Most uniform random networks exhibit small world phenomena Most real world networks are not uniform random Their in degree distribution exhibits power law behavior However, most power law random networks also exhibit small world phenomena But they are brittle against attack The fact that a network exhibits small world phenomenon doesn’t mean that an agent with strictly local knowledge can efficiently navigate it (i.e, find paths that are O(log(n)) length It is always possible to find the short paths if we have global knowledge This is the case in the FOAF (friend of a friend) networks on the web
 Most uniform random networks exhibit small world phenomena. Most real world networks are not uniform random. Their in degree distribution exhibits power law behavior. However, most power law random networks also exhibit small world phenomena. But they are brittle against attack. The fact that a network exhibits small world phenomenon doesn’t mean that an agent with strictly local knowledge can efficiently navigate it (i.e, find paths that are O(log(n)) length. It is always possible to find the short paths if we have global knowledge. This is the case in the FOAF (friend of a friend) networks on the web.")
63
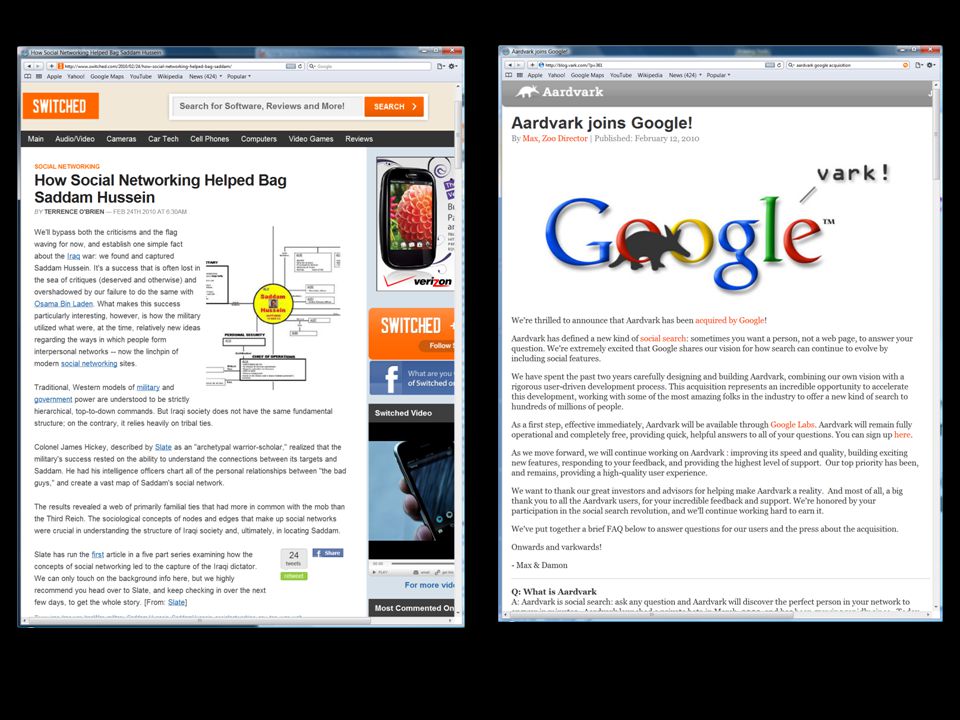
Web Applications of Social Networks
Analyzing page importance Page Rank Related to recursive in-degree computation Authorities/Hubs Discovering Communities Finding near-cliques Finding human sources and/or helpful FOAFs Aardvark (got acquired by Google in 2010 for 50M) Analyzing Trust Propagating Trust Using propagated trust to fight spam In In Web page ranking
 Analyzing Trust. Propagating Trust. Using propagated trust to fight spam. In . In Web page ranking.")
64
Spam is a serious problem…
We have Spam Spam Spam Spam Spam with Eggs and Spam in Most mail transmitted is junk web pages Many different ways of fooling search engines This is an open arms race Annual conference on and Anti-Spam Started 2004 Intl. workshop on AIR-Web (Adversarial Info Retrieval on Web) Started in 2005 at WWW
 Started in 2005 at WWW.")
65
Trust & Spam (Knock-Knock. Who is there?)
Not Funny Knock Knock Who’s there? Aardvark. Okay. (Open Door) A powerful way we avoid spam in our physical world is by preferring interactions only with “trusted” parties Trust is propagated over social networks When knocking on the doors of strangers, the first thing we do is to identify ourselves as a friend of a friend of friend … So they won’t train their dogs/guns on us.. We can do it in cyber world too Accept product recommendations only from trusted parties E.g. Epinions Accept mails only from individuals who you trust above a certain threshold Bias page importance computation so that it counts only links from “trusted” sites.. Sort of like discounting links that are “off topic” Aardvark WHO? Aardvark a million miles to see you smile!
 A powerful way we avoid spam in our physical world is by preferring interactions only with trusted parties. Trust is propagated over social networks. When knocking on the doors of strangers, the first thing we do is to identify ourselves as a friend of a friend of friend … So they won’t train their dogs/guns on us.. We can do it in cyber world too. Accept product recommendations only from trusted parties. E.g. Epinions. Accept mails only from individuals who you trust above a certain threshold. Bias page importance computation so that it counts only links from trusted sites.. Sort of like discounting links that are off topic Aardvark WHO Aardvark a million miles to see you smile!")
66
Case Study: Epinions Users can write reviews and also express trust/distrust on other users Reviewers get royalties …so some tried to game the system So, distrust measures introduced Num nodes Out degree [Guha et. Al. WWW 2004] compares some 81 different ways of propagating trust and distrust on the Epinion trust matrix

67
Evaluating Trust Propagation Approaches
Given n users, and a sparsely populated nxn matrix of trusts between the users And optionally an nxn matrix of distrusts between the users Start by “erasing” some of the entries (but remember the values you erased) For each trust propagation method Use it to fill the nxn matrix Compare the predicted values to the erased values
 For each trust propagation method. Use it to fill the nxn matrix. Compare the predicted values to the erased values.")
68
Fighting Page Spam We saw discussion of these in the Henzinger
et. Al. paper Can social networks, which gave rise to the ideas of page importance computation, also rescue these computations from spam?

69
[Gyongyi et al, VLDB 2004] TrustRank idea Tweak the “default” distribution used in page rank computation (the distribution that a bored user uses when she doesn’t want to follow the links) From uniform To “Trust based” Very similar in spirit to the Topic-sensitive or User-sensitive page rank Where too you fiddle with the default distribution Sample a set of “seed pages” from the web Have an oracle (human) identify the good pages and the spam pages in the seed set Expensive task, so must make seed set as small as possible Propagate Trust (one pass) Use the normalized trust to set the initial distribution Slides modified from Anand Rajaraman’s lecture at Stanford
![[Gyongyi et al, VLDB 2004] TrustRank idea.](http://slideplayer.com/slide/4580052/15/images/69/%5BGyongyi+et+al%2C+VLDB+2004%5D+TrustRank+idea..jpg "Tweak the default distribution used in page rank computation (the distribution that a bored user uses when she doesn’t want to follow the links) From uniform. To Trust based Very similar in spirit to the Topic-sensitive or User-sensitive page rank. Where too you fiddle with the default distribution. Sample a set of seed pages from the web. Have an oracle (human) identify the good pages and the spam pages in the seed set. Expensive task, so must make seed set as small as possible. Propagate Trust (one pass) Use the normalized trust to set the initial distribution. Slides modified from Anand Rajaraman’s lecture at Stanford.")
70
Example 1 2 3 good 4 bad 5 6 7 Assumption: Bad pages are “isolated”
from “good” pages.. (and vice versa)
")
71
Trust Propagation Trust is “transitive” so easy to propagate
..but attenuates as it traverses as a social network If I trust you, I trust your friend (but a little less than I do you), and I trust your friend’s friend even less Trust may not be symmetric.. Trust is normally additive If you are friend of two of my friends, may be I trust you more.. Distrust is difficult to propagate If my friend distrusts you, then I probably distrust you …but if my enemy distrusts you? …is the enemy of my enemy automatically my friend? Trust vs. Reputation “Trust” is a user-specific metric Your trust in an individual may be different from someone else’s “Reputation” can be thought of as an “aggregate” or one-size-fits-all version of Trust Most systems such as EBay tend to use Reputation rather than Trust Sort of the difference between User-specific vs. Global page rank
, and I trust your friend’s friend even less. Trust may not be symmetric.. Trust is normally additive. If you are friend of two of my friends, may be I trust you more.. Distrust is difficult to propagate. If my friend distrusts you, then I probably distrust you. …but if my enemy distrusts you …is the enemy of my enemy automatically my friend Trust vs. Reputation. Trust is a user-specific metric. Your trust in an individual may be different from someone else’s. Reputation can be thought of as an aggregate or one-size-fits-all version of Trust. Most systems such as EBay tend to use Reputation rather than Trust. Sort of the difference between User-specific vs. Global page rank.")
72
Rules for trust propagation
Trust attenuation The degree of trust conferred by a trusted page decreases with distance Trust splitting The larger the number of outlinks from a page, the less scrutiny the page author gives each outlink Trust is “split” across outlinks Combining splitting and damping, each out link of a node p gets a propagated trust of: b*t(p)/|O(p)| 0<b<1; O(p) is the out degree and t(p) is the trust of p Trust additivity Propagated trust from different directions is added up
/|O(p)| 0<b<1; O(p) is the out degree and t(p) is the trust of p. Trust additivity. Propagated trust from different directions is added up.")
73
Simple model Suppose trust of page p is t(p)
Set of outlinks O(p) For each q2O(p), p confers the trust bt(p)/|O(p)| for 0<b<1 Trust is additive Trust of p is the sum of the trust conferred on p by all its inlinked pages Note similarity to Topic-Specific Page Rank Within a scaling factor, trust rank = biased page rank with trusted pages as teleport set
 For each q2O(p), p confers the trust. bt(p)/|O(p)| for 0<b<1. Trust is additive. Trust of p is the sum of the trust conferred on p by all its inlinked pages. Note similarity to Topic-Specific Page Rank. Within a scaling factor, trust rank = biased page rank with trusted pages as teleport set.")
74
Picking the seed set Two conflicting considerations
Human has to inspect each seed page, so seed set must be as small as possible Must ensure every “good page” gets adequate trust rank, so need make all good pages reachable from seed set by short paths

75
Approaches to picking seed set
Suppose we want to pick a seed set of k pages The best idea would be to pick them from the top-k hub pages. Note that “trustworthiness” is subjective Al jazeera may be considered more trustworthy than NY Times by some (and the reverse by others) PageRank Pick the top k pages by page rank Assume high page rank pages are close to other highly ranked pages We care more about high page rank “good” pages
 PageRank. Pick the top k pages by page rank. Assume high page rank pages are close to other highly ranked pages. We care more about high page rank good pages.")
76
Inverse page rank (= Hub??)
Pick the pages with the maximum number of outlinks Can make it recursive Pick pages that link to pages with many outlinks Formalize as “inverse page rank” Construct graph G’ by reversing each edge in web graph G Page Rank in G’ is inverse page rank in G Pick top k pages by inverse page rank

77
Social Search

78
Aardvark’s Social Search
WWW 2010 Aardvark’s Social Search Given a query, find the “closest” person in your social network who might be able to answer the query “closeness” defined on the social network “ability to answer” defined in terms of the match between the query and the person’s declared competencies Using (what else?) tf/idf
 tf/idf.")
79
Score computation Relevance of a user to a query is done through “topics” p(u|t) is the probability that user has competence in topic t p(t|q) is the probability that the query q belongs to topic t Both computed in terms of tf/idf scores p(u|q) is the probability that the user can answer query q p(ui|uj) is the probability that ui will answer a query for uj & uj will “trust” ui’s answer. Computed in terms of social network distance Score of a user ui for the query q for user uj is
 is the probability that the query q belongs to topic t. Both computed in terms of tf/idf scores. p(u|q) is the probability that the user can answer query q. p(ui|uj) is the probability that ui will answer a query for uj & uj will trust ui’s answer. Computed in terms of social network distance. Score of a user ui for the query q for user uj is.")
80
Fall 2013 Survey Summary: A non-trivial percentage of you seem happy. There is some buyer’s remorse Some good suggestions were made “The power of instruction is seldom of much efficacy except in those happy dispositions where it is almost superfluous.” Edward Gibbons author of "The History of the Decline and Fall of the Roman Empire"

81
Buyers Remorse.. Some buyer’s remorse..
It is easier to concentrate in class (agreed; but it is also easy to lose concentration in the class and not recover..) It takes more than 2hr 30min as you rewind/stop etc to make sure you understand [But this is a *feature*!! No one stops you from leaving it running as you think.. Take-home vs. In-class exams] In class, I can get my doubts cleared right away [Wishful thinking.. More than 40% said this, and I never had more than 3-4 people ask questions in 20 years of teaching.. You may be confusing tutoring with class-room ;-)] Have to watch again before home works (*feature*! students did it last year too)
 It takes more than 2hr 30min as you rewind/stop etc to make sure you understand [But this is a *feature*!! No one stops you from leaving it running as you think.. Take-home vs. In-class exams] In class, I can get my doubts cleared right away [Wishful thinking.. More than 40% said this, and I never had more than 3-4 people ask questions in 20 years of teaching.. You may be confusing tutoring with class-room ;-)] Have to watch again before home works (*feature*! students did it last year too)")
82
Suggestions made Encourage students to post questions on Piazza before class, which are discussed in class For sure!! “Go over some of the important topics quickly before opening the floor for questions” (--will do). “Assign only one lecture viewing per class” Difficult in the current once a week meeting
. Assign only one lecture viewing per class Difficult in the current once a week meeting.")
83
Other Power Laws of Interest to CSE494
A little digression Other Power Laws of Interest to CSE494 If this is the power-law curve about in degree distribution, where is Google page on this curve?

84
Zipf’s Law: Power law distriubtion between rank and frequency
Digression Zipf’s Law: Power law distriubtion between rank and frequency In a given language corpus, what is the approximate relation between the frequency of the kth most frequent word and (k+1)th most frequent word? For s>1 f=1/r Most popular word is twice as frequent as the second most popular word! Word freq in wikipedia Law of categories in Marketing…
th most frequent word For s>1. f=1/r. Most popular word is twice as. frequent as the second most. popular word! Word freq in wikipedia. Law of categories in Marketing…")
85
What is the explanation for Zipf’s law?
Zipf’s law is an empirical law in that it is observed rather than “proved” Many explanations have been advanced as to why this holds. Zipf’s own explanation was “principle of least effort” Balance between speaker’s desire for a small vocabulary (note the ubiquitous use of pronouns in everyday speech; even when the pronoun reference is “hazy” at best— Rao’s MS thesis) and hearer’s desire for a large one (so meaning can be easily disambiguated) Alternate explanation— “rich get richer” –popular words get used more often Li (1992) shows that just random typing of letters with space will lead to a “language” with zipfian distribution..
 and hearer’s desire for a large one (so meaning can be easily disambiguated) Alternate explanation— rich get richer –popular words get used more often. Li (1992) shows that just random typing of letters with space will lead to a language with zipfian distribution..")
86
Heap’s law: A corollary of Zipf’s law
What is the relation between the size of a corpus (in terms of words) and the size of the lexicon (vocabulary)? V = K nb K ~ 10—100 b ~ 0.4 – 0.6 So vocabulary grows as a square root of the corpus size.. Explanation? --Assume that the corpus is generated by randomly picking words from a zipfian distribution.. Notice the impact of Zipf on generating random text corpuses!
 and the size of the lexicon (vocabulary) V = K nb. K ~ 10—100. b ~ 0.4 – 0.6. So vocabulary grows as a square root of the corpus size.. Explanation --Assume that the corpus is. generated by randomly. picking words from a. zipfian distribution.. Notice the impact of Zipf on generating. random text corpuses!")
87
(aka first digit phenomenon)
Digression begets its own digression (aka first digit phenomenon) Benford’s law How often does the digit 1 appear in numerical data describing a natural phenomenon? About 1/9 or 11%? This law holds so well in practice that it is used to catch forged data!! WHY? Iff there exists a universal distribution, it must be scale invariant (i.e., should work in any units) starting from there we can show that the distribution must satisfy the differential eqn x P’(x) = -P(x) For which, the solution is P(x)=1/x ! 1 6 2 7 3 8 4 9 5
 Benford’s law. How often does the digit 1 appear in numerical data describing a natural phenomenon About 1/9 or 11% This law holds so well in practice. that it is used to catch forged data!! WHY Iff there exists a universal distribution, it must be scale invariant (i.e., should work in any units) starting from there we can show that. the distribution must satisfy the differential eqn. x P’(x) = -P(x) For which, the solution is P(x)=1/x !")
88
2/15 Review power laws Small-world phenomena in scale-free networks
Link analysis for Web Applications

89
Searchable Networks Kleinberg (2000) Just because a short path exists, doesn’t mean you can easily find it. You don’t know all of the people whom your friends know. Under what conditions is a network searchable?

90
Neighborhood based random networks
Lattice is d-dimensional (d=2). One random link per node. Probability that there is a link between two nodes u and v is r(u,v)- a r(u,v) is the “lattice” distance between u and v (computed as manhattan distance) As against geodesic or network distance computed in terms of number of edges E.g. North-Rim and South-Rim - a determines how steeply the probability of links to far away neighbors reduces Source: Jon Kleinberg, “Navigation in a small world.” Science, 406:845 (2000). View of the world from 9th Ave
. One random link per node. Probability that there is a link between two nodes u and v is r(u,v)- a. r(u,v) is the lattice distance between u and v (computed as manhattan distance) As against geodesic or network distance computed in terms of number of edges. E.g. North-Rim and South-Rim. - a determines how steeply the probability of links to far away neighbors reduces. Source: Jon Kleinberg, Navigation in a small world. Science, 406:845 (2000). View of the world from 9th Ave.")
91
Searcheability in lattice networks
For d=2, dip in time-to-search at a=2 For low a, random graph; no “geographic” correlation in links For high a, not a small world; no short paths to be found. Searcheability dips at a=2 (inverse square distribution), in simulation Corresponds to using greedy heuristic of sending message to the node with the least lattice distance to goal For d-dimensional lattice, minimum occurs at a=d Source: Jon Kleinberg, “Navigation in a small world.” Science, 406:845 (2000).
, in simulation. Corresponds to using greedy heuristic of sending message to the node with the least lattice distance to goal. For d-dimensional lattice, minimum occurs at a=d. Source: Jon Kleinberg, Navigation in a small world. Science, 406:845 (2000).")
92
Searchable Networks Ramin Zabih Kentaro Toyama Kleinberg (2000) Watts, Dodds, Newman (2002) show that for d = 2 or 3, real networks are quite searchable. the dimensions are things like “geography”, “profession”, “hobbies” Killworth and Bernard (1978) found that people tended to search their networks by d = 2: geography and profession. Source: Duncan Watts, Six Degrees (2003). I know Ramin as a computer vision researcher. Ramin is in the CS department at Cornell; I assume he knows Jon Kleinberg. The Watts-Dodds-Newman model closely fitting a real-world experiment
 show that for d = 2 or 3, real networks are quite searchable. the dimensions are things like geography , profession , hobbies Killworth and Bernard (1978) found that people tended to search their networks by d = 2: geography and profession. Source: Duncan Watts, Six Degrees (2003). I know Ramin as a computer vision researcher. Ramin is in the CS department at Cornell; I assume he knows Jon Kleinberg. The Watts-Dodds-Newman model. closely fitting a real-world experiment.")
93
..but didn’t Milgram’s letter experiment show that navigation is easy?
…may be not A large fraction of his test subjects were stockbrokers So are likely to know how to reach the “goal” stockbroker A large fraction of his test subjects were in boston As was the “goal” stockbroker A large fraction of letters never reached Only 20% reached So how about (re)doing Milgram experiment with s? People are even more burned out with (e)mails now Success rate for chain completion < 1% !
doing Milgram experiment with s People are even more burned out with (e)mails now. Success rate for chain completion < 1% !")
94
Credits Albert, Reka and A.-L. Barabasi. “Statistical mechanics of complex networks.” Reviews of Modern Physics, 74(1): (2002) Barabasi, Albert-Laszlo. Linked. Plume Publishing. (2003) Kleinberg, Jon M. “Navigation in a small world.” Science, 406:845. (2000) Watts, Duncan. Six Degrees: The Science of a Connected Age. W. W. Norton & Co. (2003)
 Kleinberg, Jon M. Navigation in a small world. Science, 406:845. (2000) Watts, Duncan. Six Degrees: The Science of a Connected Age. W. W. Norton & Co. (2003)")
95
Six Degrees of Separation
Milgram (1967) The experiment: Random people from Nebraska were to send a letter (via intermediaries) to a stock broker in Boston. Could only send to someone with whom they were on a first-name basis. Among the letters that found the target, the average number of links was six. Milgram was a brilliant psychologist, notorious for his studies of obedience, where subjects continued to deliver what they believed to be painful electric shocks, just because a person in a lab coat told them they should do so as part of an experiment. Note on the small-worlds experiment: – Not many of the letters in the original experiment arrived. -- The experiment presaged some later discoveries, including hubs, tendency to go by geography and profession, etc. Stanley Milgram ( )
 The experiment: Random people from Nebraska were to send a letter (via intermediaries) to a stock broker in Boston. Could only send to someone with whom they were on a first-name basis. Among the letters that found the target, the average number of links was six. Milgram was a brilliant psychologist, notorious for his studies of obedience, where subjects continued to deliver what they believed to be painful electric shocks, just because a person in a lab coat told them they should do so as part of an experiment. Note on the small-worlds experiment: – Not many of the letters in the original experiment arrived. -- The experiment presaged some later discoveries, including hubs, tendency to go by geography and profession, etc. Stanley Milgram ( )")
96
Outline Small Worlds Random Graphs Alpha and Beta Power Laws
Searchable Networks Six Degrees of Separation

97
Neighborhood based generative models
These essentially give more links to close neighbors.. Discuss the powerlaw curve

98
by MSR Redmond’s Social Computing Group
The Alpha Model Watts (1999) The people you know aren’t randomly chosen. People tend to get to know those who are two links away (Rapoport *, 1957). The real world exhibits a lot of clustering. The Personal Map by MSR Redmond’s Social Computing Group * Same Anatol Rapoport, known for TIT FOR TAT!
 The people you know aren’t randomly chosen. People tend to get to know those who are two links away (Rapoport *, 1957). The real world exhibits a lot of clustering. The Personal Map. by MSR Redmond’s Social Computing Group. * Same Anatol Rapoport, known for TIT FOR TAT!")
99
The Alpha Model Watts (1999) a model: Add edges to nodes, as in random graphs, but makes links more likely when two nodes have a common friend. For a range of a values: The world is small (average path length is short), and Groups tend to form (high clustering coefficient). Probability of linkage as a function of number of mutual friends (a is 0 in upper left, 1 in diagonal, and ∞ in bottom right curves.)
, and. Groups tend to form (high clustering coefficient). Probability of linkage as a function. of number of mutual friends. (a is 0 in upper left, 1 in diagonal, and ∞ in bottom right curves.)")
100
The Alpha Model Watts (1999) a model: Add edges to nodes, as in random graphs, but makes links more likely when two nodes have a common friend. For a range of a values: The world is small (average path length is short), and Groups tend to form (high clustering coefficient). Clustering coefficient / Normalized path length Clustering coefficient (C) and average path length (L) plotted against a Source: Duncan Watts, Six Degrees (2003). a
, and. Groups tend to form (high clustering coefficient). Clustering coefficient / Normalized path length. Clustering coefficient (C) and. average path length (L) plotted against a. Source: Duncan Watts, Six Degrees (2003). a.")
101
and a few distant people.
The Beta Model Watts and Strogatz (1998) b = 0 b = 0.125 b = 1 People know their neighbors. Clustered, but not a “small world” People know their neighbors, and a few distant people. Clustered and “small world” People know others at random. Not clustered, but “small world”
 b = 0. b = b = 1. People know. their neighbors. Clustered, but. not a small world People know. their neighbors, and a few distant people. Clustered and. small world People know. others at. random. Not clustered, but small world")
102
The Beta Model Jonathan Donner Kentaro Toyama Watts and Strogatz (1998) Nobuyuki Hanaki First five random links reduce the average path length of the network by half, regardless of N! Both a and b models reproduce short-path results of random graphs, but also allow for clustering. Small-world phenomena occur at threshold between order and chaos. Clustering coefficient / Normalized path length Source: Duncan Watts, Six Degrees (2003). Small-world phenomena of random graphs emerges even with less random links. Jonathan Donner will be working with us at MSR India. Jonathan is now at the Earth Institute at Columbia, where he knows Nobuyuki Hanaki, who has co-authored papers with Duncan Watts. Clustering coefficient (C) and average path length (L) plotted against b
. Small-world phenomena of random graphs emerges even with less random links. Jonathan Donner will be working with us at MSR India. Jonathan is now at the Earth Institute at Columbia, where he knows Nobuyuki Hanaki, who has co-authored papers with Duncan Watts. Clustering coefficient (C) and average. path length (L) plotted against b.")
Similar presentations
















>")



