Download presentation
Presentation is loading. Please wait.

1
Presented by: Chaitanya Sambhara - Graduate Student - CSc 8712 ( Advanced Database Systems ) - Spring 2008 - Instructor : Dr Yingshu Li
 - Spring Instructor : Dr Yingshu Li")
2
Index Why this topic Introduction What is a probabilistic database Why probabilistic databases/ the need Where did this concept come from and gains Uncertainties and their types Dependencies and their types Constraints Drawbacks Current research and challenges

3
Why this topic ? The traditional databases are deterministic. Every item is either in the database or is not, 0 or 1. But modern enterprise applications need to deal with lots of imprecise data: different representation of the same object in multiple data sources. Imprecise data is best modeled as probabilistic data, and managed by a probabilistic database system.

5
Relational Databases Usually a relational database (RDB) is defined a finite collection of relations where each relation is a subset of cartesian product of sets referred to as domains. Where as a probabilistic databases provide means of representing types of information that cannot be captured by relational database.

6
What is a probabilistic Database? Traditional databases store solid “facts” that can be considered certain In many cases, we don’t know things precisely I saw a bird, but not sure if it was a dove or a sparrow Uncertain, incomplete data is becoming more and more common

7
Why probabilistic databases ? A conventional relational database model cannot handle probabilistic information well, though there is much application of it. To treat such information in relational models, database users themselves need to determine how to represent such information and define its semantics. Thus, there has been a need for probabilistic database models which can represent such information.

8
Need for probabilistic databases Example : Supplier X supplies part Y From the point of view of data-modelling many situations require more complex forms of information.

9
Need for probabilistic databases How reliable is part Y when supplied by the supplier X? Is the probability that a person of type X will purchase product Y greater if that person has also purchased product Z ? If X is known how much additional information about Y is provided by knowledge of Z ?

10
Where did this concept come from ? Application pull: The need to manage imprecision in data Technology push: Advances in query processing techniques

11
The gain ? Probabilistic Databases provide a framework that generalizes the relational database model. Extends all the concepts that have been developed to deal with the collection of yes/no facts to apply. Also to facts about which one is uncertain (probabilistic databases) or about one has vague or fuzzy information (fuzzy databases).
 or about one has vague or fuzzy information (fuzzy databases)..")
12
Types of Uncertainty's related to probabilistic databases Tuple-level uncertainty Attribute-level uncertainty

13
Tuple Level Uncertainty All attributes in a tuple are known precisely; existence of the tuple is uncertain. Tuple (“GSU”,...) will be present in the answer with some uncertainty
 will be present in the answer with some uncertainty.")
14
Trio Witness 1: Car green; driver was a man, 20 years. Witness 2: Car yellow; driver was 35 years old. Statements are partly contradictory. Statements are partly independent. Need to gather facts and weigh options: – What is the probability that the driver was a man? What is the probability that the car is green and the driver is 35 years old? – (Which witness do you trust; do you trust a witness all or nothing?)
.")
15
Inconsistent Data Types of imprecision addressed: Data from different sources is contradictory. Data is uncertain, hence, arguably, probabilistic Query answers are probabilistic

16
A probabilistic would… Give better recall and precision! Needs to support disjoint tuple events

17
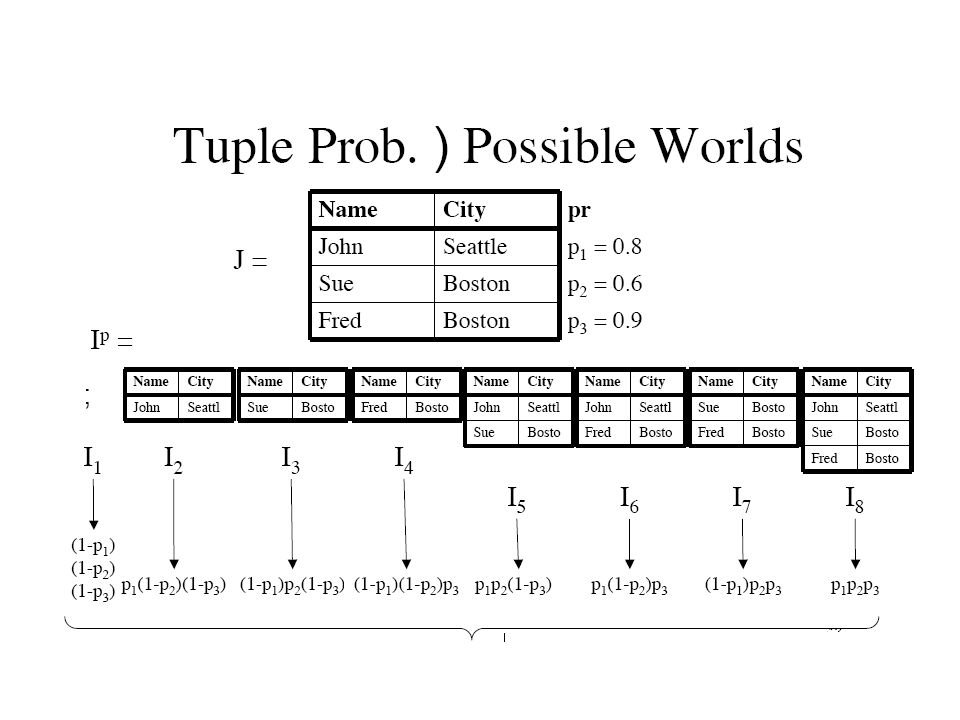
Example for a tuple level uncertainty This figure represents that a tuple (p,e) exists in the database with probability 0.4, which is indicated by a special attribute named pS.However, these models assume that the existence of each tuple is independent, and are not able to represent dependency among tuples such as “at least one tuple of two or more tuples must exist in a database.” StateEventpS p e0.4 p f0.6 q e0.5 q f0.4
 exists in the database with probability 0.4, which is indicated by a special attribute named pS.However, these models assume that the existence of each tuple is independent, and are not able to represent dependency among tuples such as at least one tuple of two or more tuples must exist in a database. StateEventpS p e0.4 p f0.6 q e0.5 q f0.4")
18
Example for a tuple level uncertainty For example, in a this figure, the probability that neither of the two tuples (p,e) and (p,f) exists in the database is given by (1-0.4) * (1-0.6) = 0.24 0.24>0, so it cannot represent the case that at least one tuple of the two must exist in the database. StateEventpS p e0.4 p f0.6 q e0.5 q f0.4

20
Attribute level uncertainty Tuples (identified by keys) exist for certain; an attribute value is however uncertain Tomorrow temperature will be somewhere between 50F and 70F
 exist for certain; an attribute value is however uncertain Tomorrow temperature will be somewhere between 50F and 70F")
21
Attribute level uncertainty Attribute-level uncertainty means the attribute values are uncertain. The attributes are independent of each other

22
Example for attribute level uncertainty Tuples exist with certainty Temperature at time t1 at location 1 etc. But the attribute values (temperatures) are uncertain In particular, each temperature value is a Gaussian
 are uncertain In particular, each temperature value is a Gaussian.")
23
Example for attribute level uncertainty Tuples exist with certainty. Temperature at time t1 at location 1 etc. But the attribute values (temperatures) are uncertain Timetemp low t emp high 12021 22223 31819
 are uncertain Timetemp low t emp high")
24
Probabilistic Data Dependencies In simple relational database applications data dependencies can be inferred from the meaning of the attributes as determined by the application. In complex probabilistic databases though dependencies are not known beforehand.

25
An important analogue of Probabilistic database design To determine which dependencies exist Relative strength of various dependencies when they do not exist in absolute sense. Hence the probabilistic dependencies can broadly be classified in to three types.

26
Types of probabilistic dependencies JOIN, FUNCTIONAL and MULTIVALUED dependencies. They generalize the database in the sense that- They apply both to probabilistic and relational databases They are straightforward, by application of results from information theory.

27
Join Dependency A join dependency hold when a relational or probabilistic database system can be decomposed into a collection of (sub)systems such that the system is equal to the join of the subsystems.
systems such that the system is equal to the join of the subsystems.")
28
Functional Dependencies In relational databases X Y For probabilistic databases the same applies, that is, once the tuple values for attributes X are known, then there is no uncertainty regarding the possible tuple values for attributes Y.

29
Multivalued Dependencies X Y What does it mean ? X Y if knowledge of R-(Y-X) gives the same or less information about Y than does the knowledge of X alone
 gives the same or less information about Y than does the knowledge of X alone.")
30
Example of multivalued dependency Drinkers(name, addr, phones, beersLiked) A drinker’s phones are independent of the beers they like. –name->->phones and name ->->beersLiked. Thus, each of a drinker’s phones appears with each of the beers they like in all combinations. This repetition is unlike FD redundancy. name->addr is the only FD.

31
Constraints The constraints for probabilistic databases are nearly same as those for relational databases. Such as domain, referential, key and entity. Intergrity constraints might have issues

32
Integrity constraints Integrity constraints might not be forced enforced or satisfied. In some environments checking consistency of constraints might be too expensive. Like work loads with high update rates.

33
Query Evaluation Queries in Databases and Information retrieval : Fundamentally different

34
Example

38
Query Evauluation But what if a query looks like:

39
Support for uncertain matches SQL query with uncertain predicates. Assign probability to each tuple according to how well it matches the uncertain predicates. Outputs are now ranked and have probabilistic semantics

40
Example

42
Drawbacks Commercial database systems have been relatively slow to incorporate imprecision capabilities Practitioners are also concerned with compatibility. Many of the query evaluation algorithms for matching imprecise data or for processing imprecise queries are fairly complex and inefficient.

43
Current research and challenges Preliminary work in this area includes investigation of incompleteness in logical databases. The design of a knowledge-rich system that can deal with various aspects of imprecision

44
Current research and challenges The method of data organization presumes knowledge of probabilistic independence among attributes, which may not be known at design time. A model is proposed with some restrictions such as: each relational scheme contains a set of deterministic key attributes.

45
Bibliography Query Evaluation on Probabilistic Databases By : Christopher R´e, Nilesh Dalvi and Dan Suciu University of Washington year 2006 http://www.cs.washington.edu/homes/nilesh/papers/debul06probdb.pdf Probabilistic databases with correlated tuples By : Prithviraj Sen, Amol Deshpande and Lise Getoor A journal published at Dept of Computer science University of Maryland College Park 2006 http://www.cs.purdue.edu/probdb/updb06/prob_db_wkshp.pdf A General Probabilistic database model By :Veronica Biazzo, Alfredo Ferro, Angelo Gilio and Rosalba Giugno Dipartimento di Matematica e Informatica, Viale A. Doria, 6 - 95125 Catania, Italy December 18, 2002 http://www.dmi.unict.it/~giugno/ipmu00.pdf

46
Bibliography Models for Incomplete and Probabilistic information By : Todd J. Green and Val Tannen Department of Computer and Information Science University of Pennsylvania International Workshop on Inconsistency and Incompleteness in Databases March 26, 2006 http://www.cis.upenn.edu/~tjgreen/iidb06-talk.pdf Efficient Management of Inconsistent Databases. By : Ariel Fuxman, Elham Fazli, and Renee J. Miller. In ACM SIGMOD Conference, 155-166, 2005 http://www.cs.toronto.edu/~afuxman/publications/sigmod05.pdf A System for Efficient Query Answering Over Inconsistent Databases. Ariel Fuxman, Diego Fuxman, and Renee J. Miller. In International Conference on Very Large Databases (VLDB), 1354-1357, 2005 http://www.cs.toronto.edu/~afuxman/publications/vldbdemo05.pdf
, ,")
47
Suggestions/ Question time

Similar presentations












, 2007 PRESENTED BY : JITENDRA GUPTA.>")






 express a condition among tuples of a relation.>")

 Functional Dependencies and Normalization. u Read Sections 3.5-3.6. Project Part 1 due. Oct.>")

 Modern Information Retrieval Spring 2000.>")
