Download presentation
Presentation is loading. Please wait.

1
PAC Learning adapted from Tom M.Mitchell Carnegie Mellon University

2
Learning Issues Under what conditions is successful learning … possible ? … assured for a particular learning algorithm ?

3
Sample Complexity How many training examples are needed … for a learner to converge (with high probability) to a successful hypothesis?
 to a successful hypothesis")
4
Computational Complexity How much computational effort is needed … for a learner to converge (with high probability) to a successful hypothesis?
 to a successful hypothesis")
5
The world X is the sample space Example: Two dice {(1,1),(1,2), …,(6,5),(6,6)} x x x x x x x x x x x x x
,(1,2), …,(6,5),(6,6)} x x x x x x x x x x x x x")
6
Weighted world X is a distribution over X Example: Biased dice {(1,1; p 11 ),(1,2 ; p 12 ), …,(6,5 ; p 65 ),(6,6 ; p 66 )} x x x x x x x x x x x x x
,(1,2 ; p 12 ), …,(6,5 ; p 65 ),(6,6 ; p 66 )} x x x x x x x x x x x x x")
7
An event E is a subset of X Example: Two dice {(1,1),(1,2), …,(6,5),(6,6)} x x x x x x x x x x x x x
,(1,2), …,(6,5),(6,6)} x x x x x x x x x x x x x")
8
An event E is a subset of X Example: A pair in Two dice {(1,1),(2,2),(3,3),(4,4),(5,5),(6,6)} x x x x x x x x x x x x x
,(2,2),(3,3),(4,4),(5,5),(6,6)} x x x x x x x x x x x x x")
9
A Concept C is an indicator function of an event E Example: A pair in Two dice c(x,y) := (x==y) x x x x x x x x x x x x x
 := (x==y) x x x x x x x x x x x x x")
10
A hypotesis h is an approximation to a concept c Example: A separating hyperplane h(x,y) := (0.5).[1+sign(a.x+by+c)] x x x x x x x x x x x x x
![A hypotesis h is an approximation to a concept c Example: A separating hyperplane h(x,y) := (0.5).[1+sign(a.x+by+c)] x x x x x x x x x x x x x](http://images.slideplayer.com/15/4547485/slides/slide_10.jpg "A hypotesis h is an approximation to a concept c Example: A separating hyperplane h(x,y) := (0.5).[1+sign(a.x+by+c)] x x x x x x x x x x x x x")
11
The dataset D is an i.i.d. sample from (X, ) { } i=1, …,m m examples
 { } i=1, …,m m examples")
12
An Inductive learner L is an algorithm that uses data D to produce h H Example: The Perceptron Algorithm h(x,y) := (0.5).[1+sign(a(D).x+b(D).y+c(D))] x x x x x x x x x x x x x
![An Inductive learner L is an algorithm that uses data D to produce h H Example: The Perceptron Algorithm h(x,y) := (0.5).[1+sign(a(D).x+b(D).y+c(D))] x x x x x x x x x x x x x](http://images.slideplayer.com/15/4547485/slides/slide_12.jpg "An Inductive learner L is an algorithm that uses data D to produce h H Example: The Perceptron Algorithm h(x,y) := (0.5).[1+sign(a(D).x+b(D).y+c(D))] x x x x x x x x x x x x x")
13
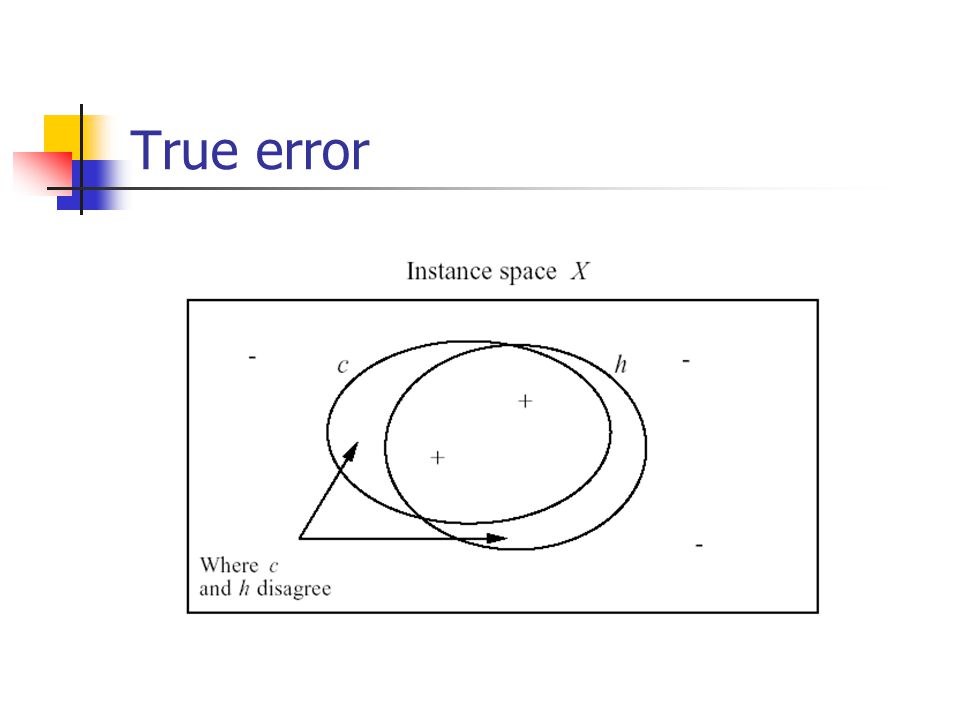
Error Measures Training error of hypothesis h How often over training instances True error of hypothesis h How often over future random instances

14
True error

16
Learnability How to describe Learn-ability ? the number of training examples needed to learn a hypothesis for which = 0. Infeasible

17
PAC Learnability Weaken demands on the learner true error accuracy failure probability and can be arbitrarily small Probably Approximately Correct Learning

18
PAC Learnability C is PAC-learnable by L true error < with probability (1- ) after reasonable # of examples reasonable time per example Reasonable polynomial in terms of 1/ , 1/ , n(size of examples) and target concept encoding length
 after reasonable # of examples reasonable time per example Reasonable polynomial in terms of 1/ , 1/ , n(size of examples) and target concept encoding length")
19
PAC Learnability

20
C is PAC-Learnable each target concept in C can be learned from a polynominal number of training examples the processing time per example is also polynominal bounded polynomial in terms of 1/ , 1/ , n (size of examples) and target c encoding length
 and target c encoding length")
Similar presentations


















>")
