Download presentation
Presentation is loading. Please wait.

1
Mixture of trees model: Face Detection, Pose Estimation and Landmark Localization
Presenter: Zhang Li

2
Problem Give an image, detect the face, pose estimation and the landmark points on each face

3
Existing works separately handle the tasks
Face detection: viola-Jones, Adaboost with LBP Pose estimation: Morphable model, 2D view based Facial Landmark: AAM, ASM, Flandmark(Deformable Part Models )
")
4
This work (CVPR2012) A unified model for face detection, pose estimation, and landmark estimation. Based on a mixtures of trees with a shared pool of parts Use global mixtures to capture topological changes Open source, result is par to commercial software, while training is based on hundreds of images May helpful for my building digital double project

5
Mixture of Trees Model Generic model, can use for many tasks, such as object detection and human tracking Works lists on this area: 1. Mixtures of Trees for Object Recognition, CVPR 2001 2. Human Tracking with Mixtures of Trees, ICCV 2001 3. Discriminative Mixture-of-Templates for Viewpoint Classification, ECCV2010 3. Articulated pose estimation with flexible mixtures of parts, CVPR2011 4. Face Detection, Pose Estimation, and Landmark Localization in the wild, CVPR2012 …..
![]()
6
Mixture of Trees Model Generic model, can use for many tasks, such as object detection and human tracking Works lists on this area: 1. Mixtures of Trees for Object Recognition, CVPR 2001 2. Human Tracking with Mixtures of Trees, ICCV 2001 3. Discriminative Mixture-of-Templates for Viewpoint Classification, ECCV2010 3. Articulated pose estimation with flexible mixtures of parts, CVPR2011 4. Face Detection, Pose Estimation, and Landmark Localization in the wild, CVPR2012 ….. To introduce the model
![]()
7
Modeling with mixtures of trees
1. An object is s a collection of K primitives 2. Primitive: a vector representing its configuration(e.g., the position in the image) 3. Given an image, the object detector will give a set of candidate of each primitive Goal: build an assembly by choosing an element from each candidate set, so that the resulting set of primitives satisfies some global constraints.
 3. Given an image, the object detector will give a set of candidate of each primitive. Goal: build an assembly by choosing an element from each candidate set, so that the resulting set of primitives satisfies some global constraints.")
8
Modeling with mixtures of trees
brute search, maximize time consuming, time complexity M is the number of candidate for each primitive 4. Instead, build a tree structure of K primitives MAP estimation on training data maximize : root of the tree : parent of

9
Single tree to Mixtures of trees
Why this? Same to Gaussian to Multiple Gaussian occlusions, variations in aspect or failures of the local detectors. Therefore, What set S of primitives consist of objects, therefore, in total, there will be components :the weight of configuration as structure S Learning required: and

10
Mixtures of trees to shared structure
Why this? Exploit structure is computationally expensive Instead, use a seed to generate to approximate or some existing tree templates A generating tree(seed) T : direct tree with K primitives, Then for each structure S, then denote the event of this primitives belonging to the S
 T : direct tree with K primitives, Then for each structure S, then. denote the event of this primitives belonging to the S.")
11
Grouping using mixtures of tress
Goal: localize an object in an image maximize Perform search on tree T We select not only the best primitives to choose from the children’s candidate sets, but also the edges to be included in the tree(which parts constitute an object instance) To see the application on face, refer to their paper
 To see the application on face, refer to their paper.")
12
Mixture of Trees Model Generic model, can use for many tasks, such as object detection and human tracking Works lists on this area: 1. Mixtures of Trees for Object Recognition, CVPR 2001 2. Human Tracking with Mixtures of Trees, ICCV 2001 3. Discriminative Mixture-of-Templates for Viewpoint Classification, ECCV2010 3. Articulated pose estimation with flexible mixtures of parts, CVPR2011 4. Face Detection, Pose Estimation, and Landmark Localization in the wild, CVPR2012 …..
![]()
13
mixture-of-trees model
Prior Input: topological changes due to viewpoints, note no closed loops maintaining the tree property

14
How to model Each facial landmark: as a part, similar to primitives We write each tree Tm =(Vm,Em) as a linearly-parameterized ,where m indicates a mixture and I : image, and li = (xi, yi) : the pixel location of part I (the ith facial landmark). We score a configuration of parts Meaning: the similarity of the input image I with facial landmarks positions as L under the m-th topology : a scalar bias associated with viewpoint mixture m
 as a linearly-parameterized ,where m indicates a mixture and . I : image, and li = (xi, yi) : the pixel location of part I (the ith facial landmark). We score a configuration of parts. Meaning: the similarity of the input image I with facial landmarks positions as L under the m-th topology. : a scalar bias associated with viewpoint mixture m.")
15
Tree structured part model
Meaning: sums the appearance similarity for placing a template for part i, under the m-th topology, at location li. Meaning: sums the mixture-specific spatial arrangement of parts L : Local feature representation at location li

16
Shape model the shape model can be rewritten
: re-parameterizations of the shape model (a, b, c, d), similar to AAM and ASM distance : a block sparse precision matrix, with non-zero entries corresponding to pairs of parts i, j connected in Em.
, similar to AAM and ASM distance. : a block sparse precision matrix, with non-zero entries corresponding to pairs of parts i, j connected in Em.")
17
Optimization Inference corresponds to maximizing S(I, L,m) in Eqn.1 over L and m: Since each mixture Tm =(Vm,Em) is a tree, the inner maximization can be done efficiently with dynamic programming.
 is a tree, the inner maximization can be done efficiently with dynamic programming.")
18
Learning Given labeled positive examples {In,Ln,mn} and negative examples {In}, they will define a structured prediction objective function similar to one proposed in [41]. Rewrite, zn = {Ln,mn}. Concatenating Eqn1’s parameters into a single vector Concatenate and {a, b, c ,d } in to From (1), we know it is linear to and {a, b ,c ,d} [41] Y. Yang and D. Ramanan. Articulated pose estimation using flexible mixtures of parts. In CVPR 2011.
, we know it is linear to and {a, b ,c ,d} [41] Y. Yang and D. Ramanan. Articulated pose estimation using flexible mixtures of parts. In CVPR")
19
Learning, max-margin(SVM)
Now we can learn a model of the form: The objective function penalizes violations of these constraints using slack variables write K for the indices of the quadratic spring terms (a, c) in parameter vector .
 in parameter vector .")
20
Experimental Results

21
Dataset CMU MultiPIE annotated face in-the-wild (AFW)
(from Flickr images)
")
22
Dataset

23
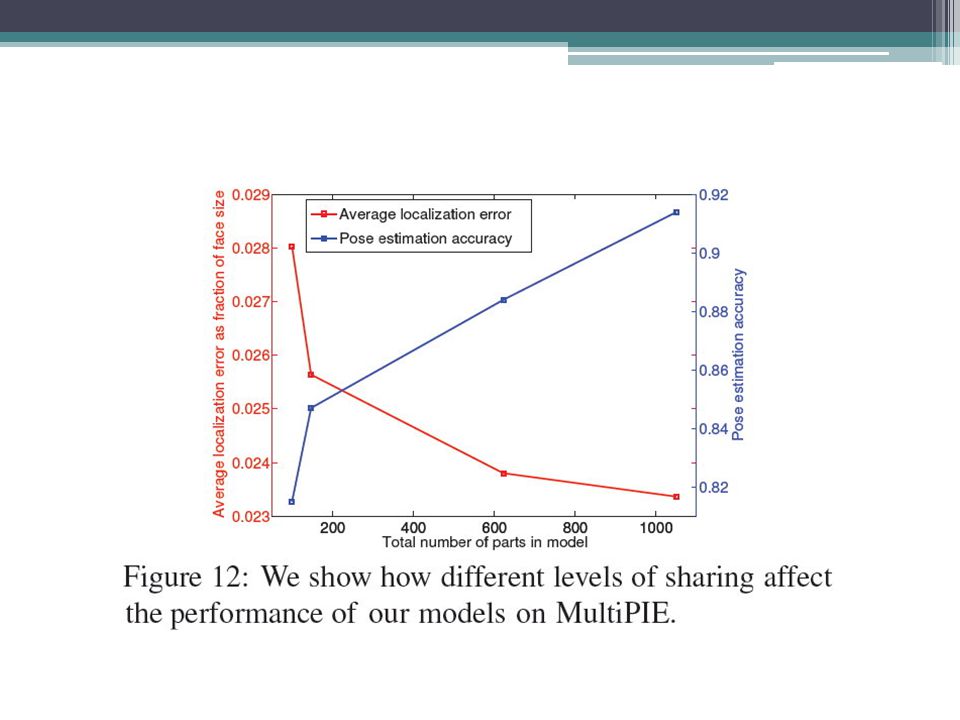
Sharing We explore 4 levels of sharing, denoting each model with the number of distinct templates encoded. Share-99 (i.e. fully shared model) Share-146 Share-622 Independent-1050 (i.e. independent model)
 Share-146. Share-622. Independent-1050 (i.e. independent model)")
25
In-house baselines We define Multi.HoG to be rigid, multiview HoG template detectors, trained on the same data as our models. We define Star Model to be equivalent to Share- 99 but defined using a “star” connectivity graph, where all parts are directly connected to a root nose part.

26
Face detection on AFW testset
[22] Z. Kalal, J. Matas, and K. Mikolajczyk. Weighted sampling for large-scale boosting. In BMVC 2008.

27
Pose estimation

28
Landmark localization

29
Landmark localization

30
AFW image

31
Conclusion This model outperforms state-of-the-art methods, including large-scale commercial systems, on all three tasks under both constrained and in-the-wild environments.

Similar presentations