Download presentation
Presentation is loading. Please wait.

1
Overview of Spark project Presented by Yin Zhu (yinz@ust.hk)yinz@ust.hk Materials from http://spark-project.org/documentation/ Hadoop in Practice by A. Holmes My demo code : https://bitbucket.org/blackswift/spark-examplehttps://bitbucket.org/blackswift/spark-example 25 March 2013

2
Outline Review of MapReduce (15’) Going Through Spark (NSDI’12) Slides (30’) Demo (15’)
 Going Through Spark (NSDI’12) Slides (30’) Demo (15’)")
3
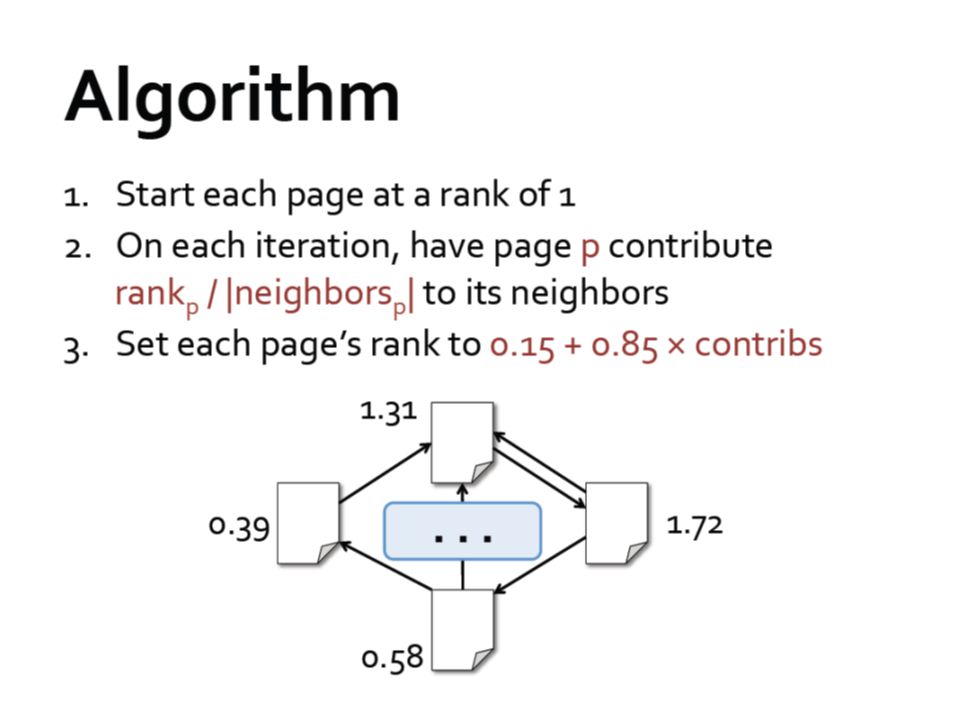
Review of MapReduce Pagerank implemented in Scala and Hadoop Why Pagerank? > More complicated than the “hello world” WordCount >Widely used in search engines, very large scale input (the whole web graph!) >Iterative algorithm (typical style for most numerical algorithms for data mining)
 >Iterative algorithm (typical style for most numerical algorithms for data mining).")
5
New score: 0.15 + 0.5*0.85 = 0.575

10
A functional implementation def pagerank(links: Array[(UrlId, Array[UrlId])], numIters: Int):Map[UrlId, Double] = { val n = links.size var ranks = (Array.fromFunction(i => (i, 1.0)) (n)).toMap // init: each node has rank 1.0 for (iter <- 1 to numIters) { // Take some interactions val contrib = links.flatMap(node => { val out_url = node._1 val in_urls = node._2 val score = ranks(out_url) / in_urls.size // the score each outer link recieves in_urls.map(in_url => (in_url, score) ) } ).groupBy(url_score => url_score._1) // group the (url, score) pairs by url.map(url_scoregroup => // sum the score for each unique url (url_scoregroup._1, url_scoregroup._2.foldLeft (0.0) ((sum,url_score) => sum+url_score._2))) ranks = ranks.map(url_score => (url_score._1, if (contrib.contains(url_score._1)) 0.85 * contrib(url_score._1) + 0.15 else url_score._2)) } ranks } Map Reduce
![A functional implementation def pagerank(links: Array[(UrlId, Array[UrlId])], numIters: Int):Map[UrlId, Double] = { val n = links.size var ranks = (Array.fromFunction(i => (i, 1.0)) (n)).toMap // init: each node has rank 1.0 for (iter <- 1 to numIters) { // Take some interactions val contrib = links.flatMap(node => { val out_url = node._1 val in_urls = node._2 val score = ranks(out_url) / in_urls.size // the score each outer link recieves in_urls.map(in_url => (in_url, score) ) } ).groupBy(url_score => url_score._1) // group the (url, score) pairs by url.map(url_scoregroup => // sum the score for each unique url (url_scoregroup._1, url_scoregroup._2.foldLeft (0.0) ((sum,url_score) => sum+url_score._2))) ranks = ranks.map(url_score => (url_score._1, if (contrib.contains(url_score._1)) 0.85 * contrib(url_score._1) else url_score._2)) } ranks } Map Reduce](http://images.slideplayer.com/14/4499861/slides/slide_10.jpg "A functional implementation def pagerank(links: Array[(UrlId, Array[UrlId])], numIters: Int):Map[UrlId, Double] = { val n = links.size var ranks = (Array.fromFunction(i => (i, 1.0)) (n)).toMap // init: each node has rank 1.0 for (iter <- 1 to numIters) { // Take some interactions val contrib = links.flatMap(node => { val out_url = node._1 val in_urls = node._2 val score = ranks(out_url) / in_urls.size // the score each outer link recieves in_urls.map(in_url => (in_url, score) ) } ).groupBy(url_score => url_score._1) // group the (url, score) pairs by url.map(url_scoregroup => // sum the score for each unique url (url_scoregroup._1, url_scoregroup._2.foldLeft (0.0) ((sum,url_score) => sum+url_score._2))) ranks = ranks.map(url_score => (url_score._1, if (contrib.contains(url_score._1)) 0.85 * contrib(url_score._1) else url_score._2)) } ranks } Map Reduce")
11
Hadoop implementation https://github.com/alexholmes/hadoop- book/tree/master/src/main/java/com/manning/h ip/ch7/pagerank

12
Hadoop/MapReduce implementation Fault tolerance the result after each iteration is saved to Disk Speed/Disk IO disk IO is proportional to the # of iterations ideally the link graph should be loaded for only once

13
Resilient Distributed Datasets A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley UC BERKELEY

14
Motivation MapReduce greatly simplified “big data” analysis on large, unreliable clusters But as soon as it got popular, users wanted more: »More complex, multi-stage applications (e.g. iterative machine learning & graph processing) »More interactive ad-hoc queries Response: specialized frameworks for some of these apps (e.g. Pregel for graph processing)
 »More interactive ad-hoc queries Response: specialized frameworks for some of these apps (e.g. Pregel for graph processing).")
15
Motivation Complex apps and interactive queries both need one thing that MapReduce lacks: Efficient primitives for data sharing In MapReduce, the only way to share data across jobs is stable storage slow!

16
Examples iter. 1 iter. 2... Input HDFS read HDFS write HDFS read HDFS write Input query 1 query 2 query 3 result 1 result 2 result 3... HDFS read Slow due to replication and disk I/O, but necessary for fault tolerance

17
iter. 1 iter. 2... Input Goal: In-Memory Data Sharing Input query 1 query 2 query 3... one-time processing 10-100× faster than network/disk, but how to get FT?

18
Challenge How to design a distributed memory abstraction that is both fault-tolerant and efficient?

19
Solution: Resilient Distributed Datasets (RDDs) Restricted form of distributed shared memory »Immutable, partitioned collections of records »Can only be built through coarse-grained deterministic transformations (map, filter, join, …) Efficient fault recovery using lineage »Log one operation to apply to many elements »Recompute lost partitions on failure »No cost if nothing fails
 Restricted form of distributed shared memory »Immutable, partitioned collections of records »Can only be built through coarse-grained deterministic transformations (map, filter, join, …) Efficient fault recovery using lineage »Log one operation to apply to many elements »Recompute lost partitions on failure »No cost if nothing fails")
20
Three core concepts of RDD Transformations define a new RDD from an existing RDD Cache and Partitioner Put the dataset into memory/other persist media, and specify the locations of the sub datasets Actions carry out the actual computation

21
RDD and its lazy transformations RDD[T]: A sequence of objects of type T Transformations are lazy: https://github.com/mesos/spark/blob/master/core/src/main/scala/spark/PairRDDFunctions.scala
![RDD and its lazy transformations RDD[T]: A sequence of objects of type T Transformations are lazy:](http://images.slideplayer.com/14/4499861/slides/slide_21.jpg "RDD and its lazy transformations RDD[T]: A sequence of objects of type T Transformations are lazy:")
22
/** * Return an RDD of grouped items. */ def groupBy [ K: ClassManifest ]( f : T => K, p : Partitioner ) : RDD [( K, Seq [ T ])] = { val cleanF = sc. clean ( f ) this. map ( t => ( cleanF ( t ), t )). groupByKey ( p ) } /** * Group the values for each key in the RDD into a single sequence. Allows controlling the * partitioning of the resulting key-value pair RDD by passing a Partitioner. */ def groupByKey ( partitioner : Partitioner ) : RDD [( K, Seq [ V ])] = { def createCombiner ( v : V ) = ArrayBuffer ( v ) def mergeValue ( buf : ArrayBuffer [ V ], v : V ) = buf += v def mergeCombiners ( b1 : ArrayBuffer [ V ], b2 : ArrayBuffer [ V ]) = b1 ++= b2 val bufs = combineByKey [ ArrayBuffer [ V ]]( createCombiner _, mergeValue _, mergeCombiners _, partitioner ) bufs. asInstanceOf [ RDD [( K, Seq [ V ])]] }
 : RDD [( K, Seq [ T ])] = { val cleanF = sc. clean ( f ) this. map ( t => ( cleanF ( t ), t )). groupByKey ( p ) } /** * Group the values for each key in the RDD into a single sequence. Allows controlling the * partitioning of the resulting key-value pair RDD by passing a Partitioner. */ def groupByKey ( partitioner : Partitioner ) : RDD [( K, Seq [ V ])] = { def createCombiner ( v : V ) = ArrayBuffer ( v ) def mergeValue ( buf : ArrayBuffer [ V ], v : V ) = buf += v def mergeCombiners ( b1 : ArrayBuffer [ V ], b2 : ArrayBuffer [ V ]) = b1 ++= b2 val bufs = combineByKey [ ArrayBuffer [ V ]]( createCombiner _, mergeValue _, mergeCombiners _, partitioner ) bufs. asInstanceOf [ RDD [( K, Seq [ V ])]] }.")
23
Actions: carry out the actual computation https://github.com/mesos/spark/blob/master/core/src/main/scala/spark/SparkContext.scala runJob

24
Example lines = spark.textFile(“hdfs://...”) errors = lines.filter(_.startsWith(“ERROR”)) messages = errors.map(_.split(‘\t’)(2)) messages.persist() or.cache() messages.filter(_.contains(“foo”)).count messages.filter(_.contains(“bar”)).count
 errors = lines.filter(_.startsWith( ERROR )) messages = errors.map(_.split(‘\t’)(2)) messages.persist() or.cache() messages.filter(_.contains( foo )).count messages.filter(_.contains( bar )).count")
25
Task Scheduler for actions Dryad-like DAGs Pipelines functions within a stage Locality & data reuse aware Partitioning-aware to avoid shuffles join union groupBy map Stage 3 Stage 1 Stage 2 A: B: C: D: E: F: G: = cached data partition

26
Input query 1 query 2 query 3... RDD Recovery one-time processing iter. 1 iter. 2... Input

27
RDDs track the graph of transformations that built them (their lineage) to rebuild lost data E.g.: messages = textFile(...).filter(_.contains(“error”)).map(_.split(‘\t’)(2)) HadoopRDD path = hdfs://… HadoopRDD path = hdfs://… FilteredRDD func = _.contains(...) FilteredRDD func = _.contains(...) MappedRDD func = _.split(…) MappedRDD func = _.split(…) Fault Recovery HadoopRDDFilteredRDDMappedRDD
 to rebuild lost data E.g.: messages = textFile(...).filter(_.contains( error )).map(_.split(‘\t’)(2)) HadoopRDD path = hdfs://… HadoopRDD path = hdfs://… FilteredRDD func = _.contains(...) FilteredRDD func = _.contains(...) MappedRDD func = _.split(…) MappedRDD func = _.split(…) Fault Recovery HadoopRDDFilteredRDDMappedRDD")
28
Fault Recovery Results Failure happens

29
Generality of RDDs Despite their restrictions, RDDs can express surprisingly many parallel algorithms »These naturally apply the same operation to many items Unify many current programming models »Data flow models: MapReduce, Dryad, SQL, … »Specialized models for iterative apps: BSP (Pregel), iterative MapReduce (Haloop), bulk incremental, … Support new apps that these models don’t
, iterative MapReduce (Haloop), bulk incremental, … Support new apps that these models don’t")
30
Memory bandwidth Network bandwidth Tradeoff Space Granularity of Updates Write Throughput Fine Coarse LowHigh K-V stores, databases, RAMCloud Best for batch workloads Best for transactional workloads HDFSRDDs

31
Outline Spark programming interface Implementation Demo How people are using Spark

32
Spark Programming Interface DryadLINQ-like API in the Scala language Usable interactively from Scala interpreter Provides: »Resilient distributed datasets (RDDs) »Operations on RDDs: transformations (build new RDDs), actions (compute and output results) »Control of each RDD’s partitioning (layout across nodes) and persistence (storage in RAM, on disk, etc)
 »Operations on RDDs: transformations (build new RDDs), actions (compute and output results) »Control of each RDD’s partitioning (layout across nodes) and persistence (storage in RAM, on disk, etc)")
33
Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(_.startsWith(“ERROR”)) messages = errors.map(_.split(‘\t’)(2)) messages.persist() Block 1 Block 2 Block 3 Worker Master messages.filter(_.contains(“foo”)).count messages.filter(_.contains(“bar”)).count tasks results Msgs. 1 Msgs. 2 Msgs. 3 Base RDD Transformed RDD Action Result: full-text search of Wikipedia in <1 sec (vs 20 sec for on-disk data) Result: scaled to 1 TB data in 5-7 sec (vs 170 sec for on-disk data)
 Result: scaled to 1 TB data in 5-7 sec (vs 170 sec for on-disk data).")
34
Example: PageRank 1. Start each page with a rank of 1 2. On each iteration, update each page’s rank to Σ i ∈ neighbors rank i / |neighbors i | links = // RDD of (url, neighbors) pairs ranks = // RDD of (url, rank) pairs for (i <- 1 to ITERATIONS) { ranks = links.join(ranks).flatMap { (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) }.reduceByKey(_ + _) }
 pairs ranks = // RDD of (url, rank) pairs for (i <- 1 to ITERATIONS) { ranks = links.join(ranks).flatMap { (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) }.reduceByKey(_ + _) }.")
35
Optimizing Placement links & ranks repeatedly joined Can co-partition them (e.g. hash both on URL) to avoid shuffles Can also use app knowledge, e.g., hash on DNS name links = links.partitionBy( new URLPartitioner()) reduce Contribs 0 join Contribs 2 Ranks 0 (url, rank) Ranks 0 (url, rank) Links (url, neighbors) Links (url, neighbors)... Ranks 2 reduce Ranks 1
 to avoid shuffles Can also use app knowledge, e.g., hash on DNS name links = links.partitionBy( new URLPartitioner()) reduce Contribs 0 join Contribs 2 Ranks 0 (url, rank) Ranks 0 (url, rank) Links (url, neighbors) Links (url, neighbors)... Ranks 2 reduce Ranks 1.")
36
PageRank Performance

37
Implementation Runs on Mesos [NSDI 11] to share clusters w/ Hadoop Can read from any Hadoop input source (HDFS, S3, …) Spark Hadoop MPI Mesos Node … No changes to Scala language or compiler »Reflection + bytecode analysis to correctly ship code www.spark-project.org
![Implementation Runs on Mesos [NSDI 11] to share clusters w/ Hadoop Can read from any Hadoop input source (HDFS, S3, …) Spark Hadoop MPI Mesos Node … No changes to Scala language or compiler »Reflection + bytecode analysis to correctly ship code](http://images.slideplayer.com/14/4499861/slides/slide_37.jpg "Implementation Runs on Mesos [NSDI 11] to share clusters w/ Hadoop Can read from any Hadoop input source (HDFS, S3, …) Spark Hadoop MPI Mesos Node … No changes to Scala language or compiler »Reflection + bytecode analysis to correctly ship code")
38
Behavior with Insufficient RAM

39
Scalability Logistic RegressionK-Means

40
Breaking Down the Speedup

41
Spark Operations Transformations (define a new RDD) map filter sample groupByKey reduceByKey sortByKey flatMap union join cogroup cross mapValues Actions (return a result to driver program) collect reduce count save lookupKey
 map filter sample groupByKey reduceByKey sortByKey flatMap union join cogroup cross mapValues Actions (return a result to driver program) collect reduce count save lookupKey")
42
Demo

43
Open Source Community 15 contributors, 5+ companies using Spark, 3+ applications projects at Berkeley User applications: »Data mining 40x faster than Hadoop (Conviva) »Exploratory log analysis (Foursquare) »Traffic prediction via EM (Mobile Millennium) »Twitter spam classification (Monarch) »DNA sequence analysis (SNAP) »...
 »Exploratory log analysis (Foursquare) »Traffic prediction via EM (Mobile Millennium) »Twitter spam classification (Monarch) »DNA sequence analysis (SNAP) »...")
44
Related Work RAMCloud, Piccolo, GraphLab, parallel DBs »Fine-grained writes requiring replication for resilience Pregel, iterative MapReduce »Specialized models; can’t run arbitrary / ad-hoc queries DryadLINQ, FlumeJava »Language-integrated “distributed dataset” API, but cannot share datasets efficiently across queries Nectar [OSDI 10] »Automatic expression caching, but over distributed FS PacMan [NSDI 12] »Memory cache for HDFS, but writes still go to network/disk
![Related Work RAMCloud, Piccolo, GraphLab, parallel DBs »Fine-grained writes requiring replication for resilience Pregel, iterative MapReduce »Specialized models; can’t run arbitrary / ad-hoc queries DryadLINQ, FlumeJava »Language-integrated distributed dataset API, but cannot share datasets efficiently across queries Nectar [OSDI 10] »Automatic expression caching, but over distributed FS PacMan [NSDI 12] »Memory cache for HDFS, but writes still go to network/disk](http://images.slideplayer.com/14/4499861/slides/slide_44.jpg "Related Work RAMCloud, Piccolo, GraphLab, parallel DBs »Fine-grained writes requiring replication for resilience Pregel, iterative MapReduce »Specialized models; can’t run arbitrary / ad-hoc queries DryadLINQ, FlumeJava »Language-integrated distributed dataset API, but cannot share datasets efficiently across queries Nectar [OSDI 10] »Automatic expression caching, but over distributed FS PacMan [NSDI 12] »Memory cache for HDFS, but writes still go to network/disk")
45
Conclusion RDDs offer a simple and efficient programming model for a broad range of applications Leverage the coarse-grained nature of many parallel algorithms for low-overhead recovery Try it out at www.spark-project.orgwww.spark-project.org

Similar presentations






>")










 Aditya Akella.>")





>")