Download presentation
Presentation is loading. Please wait.

1
Data Compressor---Huffman Encoding and Decoding

2
Huffman Encoding Compression Typically, in files and messages, Each character requires 1 byte or 8 bits Already wasting 1 bit for most purposes! Question What’s the smallest number of bits that can be used to store an arbitrary piece of text? Idea Find the frequency of occurrence of each character Encode Frequent charactersshort bit strings Rarer characterslonger bit strings

8
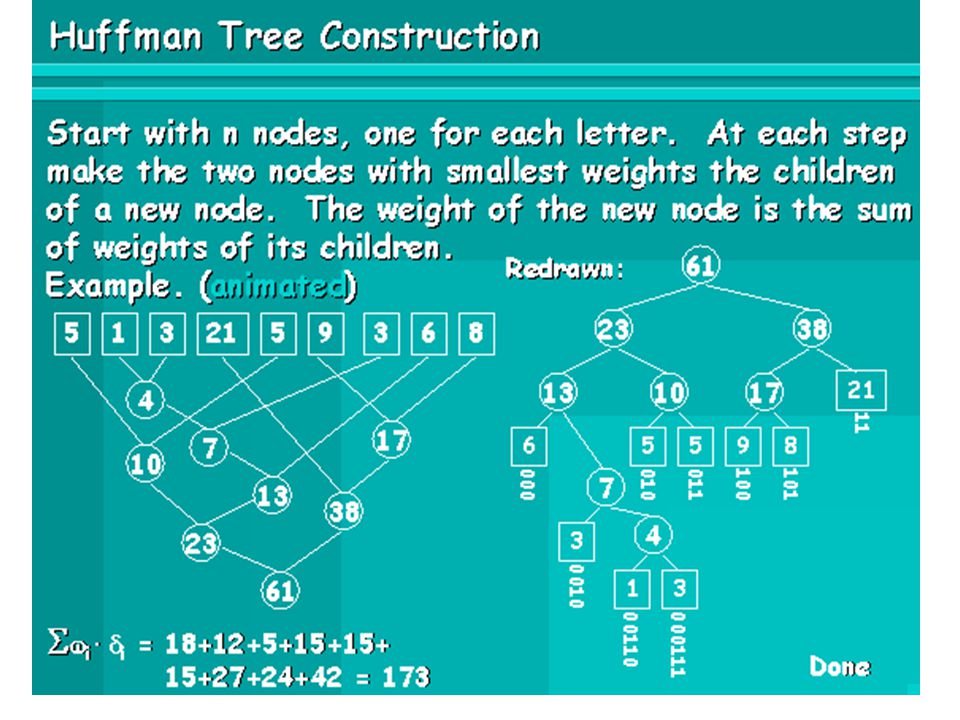
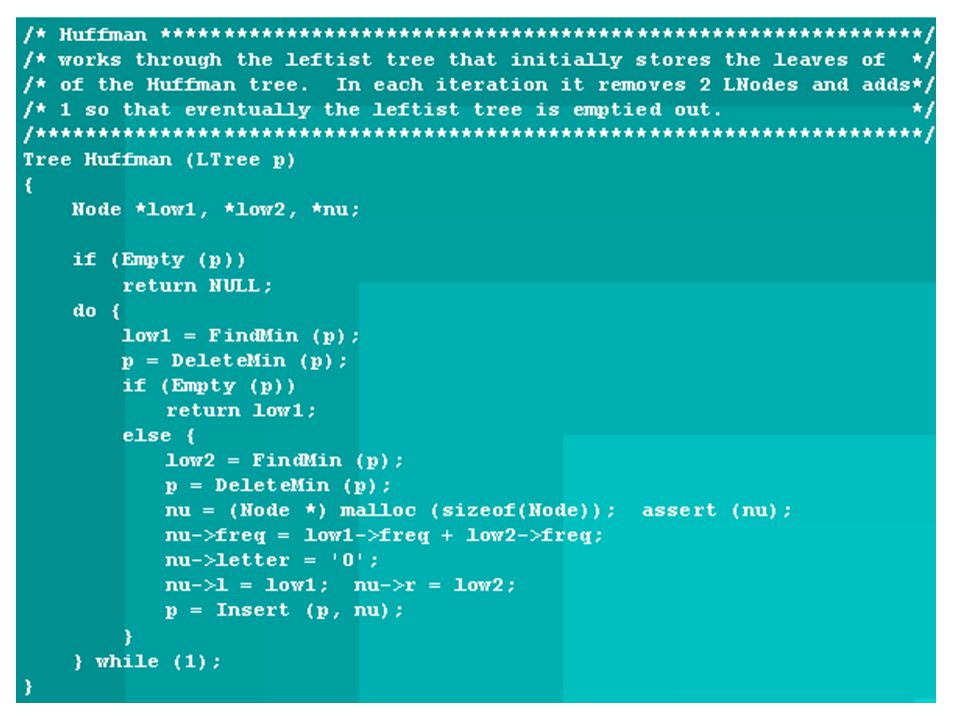
Huffman's Algorithm 1952 Repeatedly merges trees - maintains a forest Tree weight - the sum of its leaves frequencies For C characters to code, start with C single node trees Select two trees, T 1 and T 2, of smallest weights and merge them C - 1 merge operations

9
Huffman Encoding Encoding Use a tree Encode by following tree to leaf eg E is 00 S is 011 Frequent characters E, T2 bit encodings Others A, S, N, O 3 bit encodings

10
Huffman Encoding Encoding Use a tree Inefficient in practice Use a direct-addressed lookup table ?Finding the optimal encoding Smallest number of bits to represent arbitrary text A010 E00 B : : N : S T 110 001 10

11
A divide-and-conquer approach might have us asking which characters should appear in the left and right subtrees and trying to build the tree from the top down. A greedy approach places our n characters in n sub-trees and starts by combining the two least weight nodes into a tree which is assigned the sum of the two leaf node weights as the weight for its root node.

12
Huffman Encoding Divide and conquer Decide on a root - n choices Decide on roots for sub-trees - n choices Repeat n times O(n!) Greedy Approach Sort characters by frequency Form two lowest weight nodes into a sub-tree Sub-tree weight = sum of weights of nodes Move new tree to correct place
 Greedy Approach Sort characters by frequency Form two lowest weight nodes into a sub-tree Sub-tree weight = sum of weights of nodes Move new tree to correct place")
13
Standard Coding Scheme

14
Binary Tree Representation For the character set of C characters, the standard fixed-length coding needs ┌ log C ┐ bits Fixed-length code can be represented by a binary tree where characters are stored only in leaf nodes - binary trie Each character path - start at the root, follow the branches, record 0 for the left branch and 1 for the right branch Optimal code is always a full tree - all nodes are either leaves or have two children

15
Representation by a Binary Trie

16
Improved Binary Trie

17
Prefix Code The fixed-length character code that has characters places only at the leaves guarantees that any bit sequence can be decoded unambiguously Prefix code - characters may have varying lengths as long as no character code is a prefix of another code That means that characters can be only in leafs

19
Optimal Prefix Code Tree

20
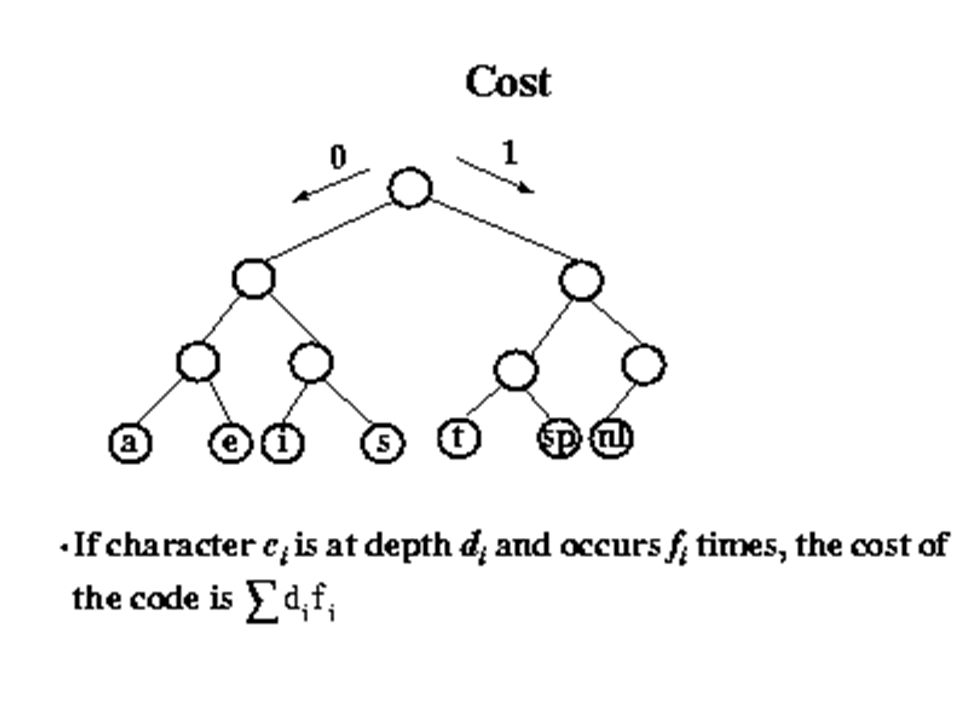
Optimal Prefix Code Cost

22
Huffman’s Algorithm Example - I

23
Huffman’s Algorithm Example - II

24
Huffman’s Algorithm Example - III

25
Huffman’s Algorithm Example - IV

26
Huffman’s Algorithm Example - V

27
Huffman’s Algorithm Example - VI

28
Huffman’s Algorithm Example-VII

32
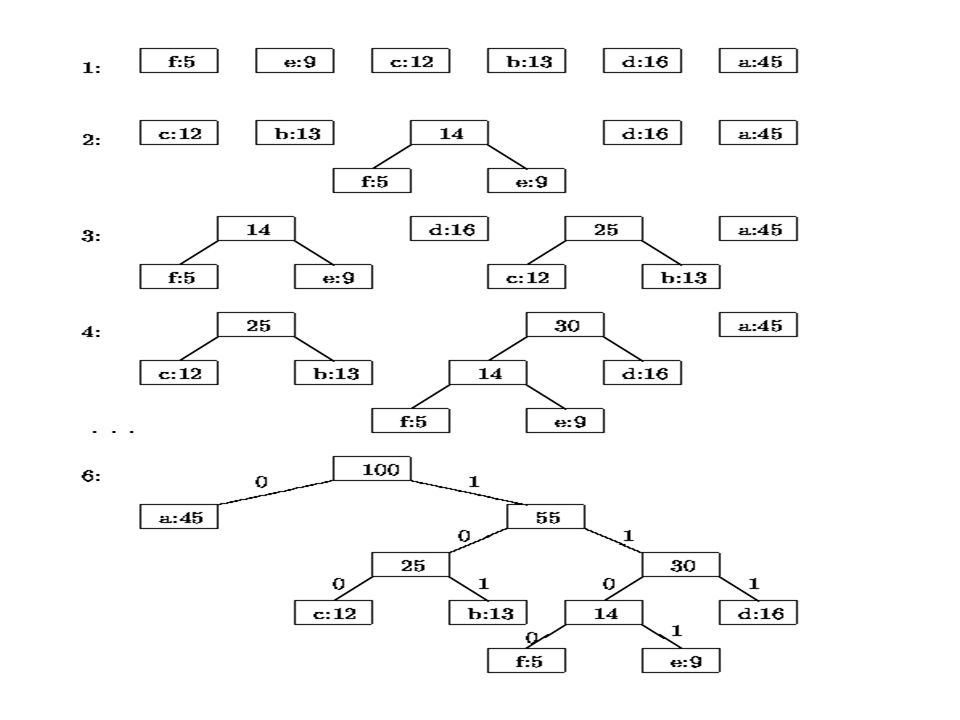
Huffman Encoding - Operation Initial sequence Sorted by frequency Combine lowest two into sub-tree Move it to correct place

33
After shifting sub-tree to its correct place... Huffman Encoding - Operation Combine next lowest pair Move sub-tree to correct place

34
Move the new tree to the correct place... Huffman Encoding - Operation Now the lowest two are the “14” sub-tree and D Combine and move to correct place

35
Move the new tree to the correct place... Huffman Encoding - Operation Now the lowest two are the the “25” and “30” trees Combine and move to correct place

36
Huffman Encoding - Operation Combine last two trees

41
How do we decode a Huffman-encoded bit string? With these variable length strings, it's not possible to break up an encoded string of bits into characters!" The decoding procedure is deceptively simple. Starting with the first bit in the stream, one then uses successive bits from the stream to determine whether to go left or right in the decoding tree. When we reach a leaf of the tree, we've decoded a character, so we place that character onto the (uncompressed) output stream. The next bit in the input stream is the first bit of the next character.
 output stream. The next bit in the input stream is the first bit of the next character..")
42
Huffman Encoding - Decoding

44
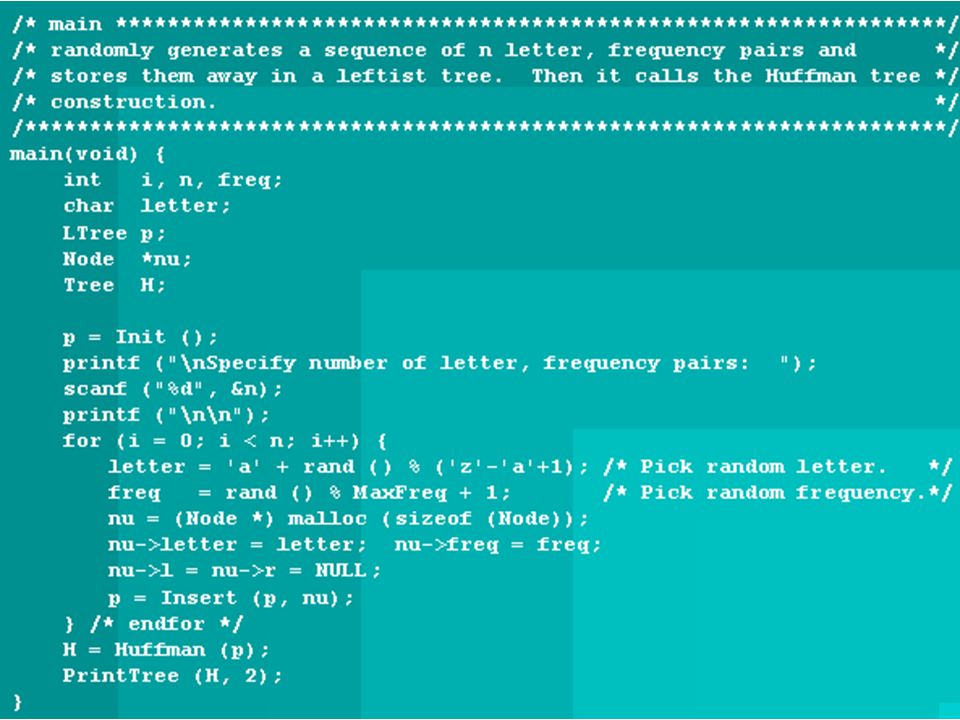
Huffman Encoding - Time Complexity Sort keys O(n log n) Repeat n times Form new sub-tree O(1) Move sub-tree O(logn) (binary search) Total O(n log n) Overall O(n log n)
 Repeat n times Form new sub-tree O(1) Move sub-tree O(logn) (binary search) Total O(n log n) Overall O(n log n)")
Similar presentations
















>")







 they need two things: 1. PROGRAMS 2. DATA A program is a.>")




