Download presentation
Presentation is loading. Please wait.

1
Image Information Retrieval Shaw-Ming Yang IST 497E 12/05/02

2
Overview J. R. Smith and S.-F. Chang, Visually Searching the Web for Content, IEEE Multimedia. July - Sept, 1997, Vol. 4, No. 3, pp. 12- 20; part of paper also in Columbia University CTR Technical Report # 45996-25, 1996.Visually Searching the Web for Content Introduction: 5-min Recap Webseek What is Webseek? Data Collection Process Subject Classification Process Search and Retrieval Process Conclusion

4
5-min Recap Why is Image IR important? “a picture is worth a 1000 words” Alternative form of communication Not everything can be described in text; Not everything can be described in images Popular medium of information on the Internet

5
5-min Recap Visual Feature Extraction What is the best way to represent all data contained in an image empirically? Multi-Dimensional Indexing What is the best way to scale large size image collections? Retrieval System Design

6
What is Webseek? “WebSEEK is a Content- Based Image and Video Search and Catalog Tool for the Web. Search through more than 650,000 images and videos.” (Advent Project) Developed by The Advent Project at Columbia University Founded 1995 Foster industrial collaboration between researchers and media technology
 Developed by The Advent Project at Columbia University Founded 1995 Foster industrial collaboration between researchers and media technology.")
7
What is Webseek? More Specifically… Uses multiple agents to automatically analyze, index, and assign images/videos to subject classes Uses both visual content and text for cataloging and searching Features Searching using image content-based techniques Query modification using content-based relevance feedback Automated collection of visual information Compact presentation of images and videos for displaying query results Image and video subject search and navigation Text-based searching Search results lists manipulations intersection, subtraction and concatenation. http://www.ctr.columbia.edu/webseek

8
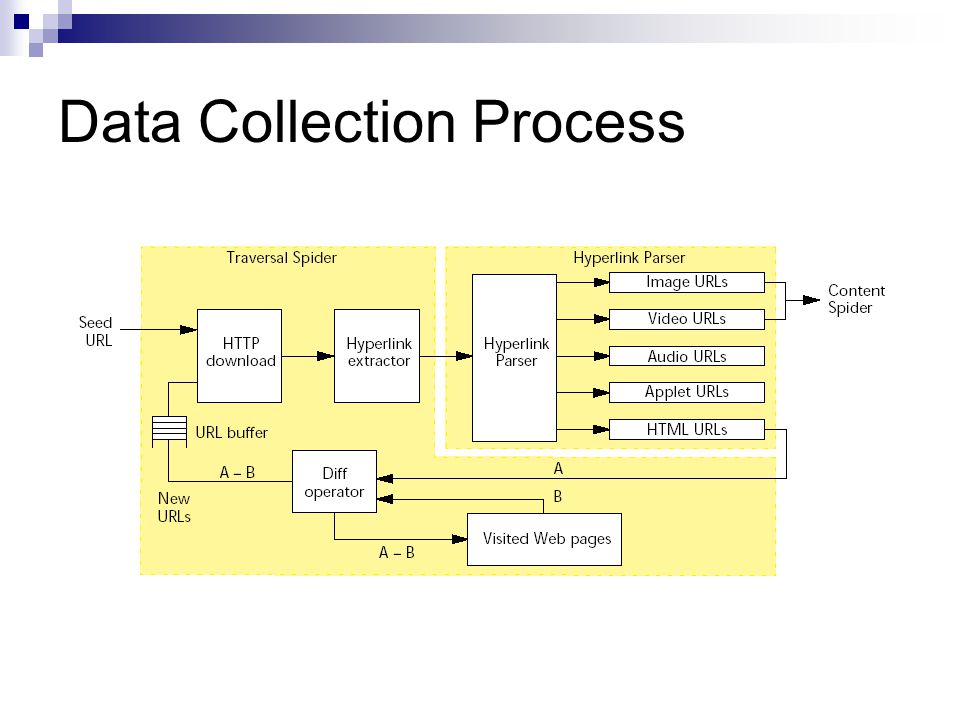
Data Collection Process Autonomous “spiders” Traversal Spider – “assembles lists of candidate Web documents that may include images, videos, or hyperlinks to them” Hyperlink Parser – “which extracts the Web addresses of images and videos” Content Spider – “which retrieves, analyzes, and iconifies the images and videos”

9
Data Collection Process

11
Content Spider Functions “extracts visual features that allow for content-based searching, browsing, and grouping” “extracts other attributes such as width, height, number of frames, type of visual data” Color histogram “generates an icon, or motion icon, which sufficiently compacts and represents the visual information to be used for browsing and displaying query results” Compression algorithms

12
Subject Classification Process “text provides clues about the semantic content of visual information” URL File name Text clues can be found in HTML syntax [hyperlink text]
![Subject Classification Process text provides clues about the semantic content of visual information URL File name Text clues can be found in HTML syntax [hyperlink text]](http://images.slideplayer.com/14/4383958/slides/slide_12.jpg "Subject Classification Process text provides clues about the semantic content of visual information URL File name Text clues can be found in HTML syntax [hyperlink text]")
13
Subject Classification Process Term extraction Extracted from URLs, alt tags, hyperlink text by removing non- alpha characters F key (URL) = F chop (“animals/domestic-beasts1/dog37”) = “animals,” “domestic,” “beasts,” “dog.” Dictionary name extraction F dir (URL) = “animals/domestic-beasts.” Key-term dictionary Terms and Dictionary names are used to create t* k terms t* k terms identified semantically related to subject classes s m M km : t* k s m
 = F chop ( animals/domestic-beasts1/dog37 ) = animals, domestic, beasts, dog. Dictionary name extraction F dir (URL) = animals/domestic-beasts. Key-term dictionary Terms and Dictionary names are used to create t* k terms t* k terms identified semantically related to subject classes s m M km : t* k s m")
14
Subject Classification Process

15
Search and Retrieval Process Search results list manipulation A = Query (Term = “sunset”) Returns Query A results Select Query B from Query A results B = Query (Term = “nature”) C = A ∩ B = Query (Term = “sunset” and Term = “nature”)
 Returns Query A results Select Query B from Query A results B = Query (Term = nature ) C = A ∩ B = Query (Term = sunset and Term = nature )")
16
Search and Retrieval Process

18
Content-based Techniques Color histograms dissimilarity “determines the color dissimilarity between a query image and a target image.” Indexes images by global color Integrated spatial and color query “users can graphically construct a query by placing color regions on a query grid” Analyzes “sizes, spatial locations, and relationships of color regions within the images”

19
Search and Retrieval Process

20
Conclusion Many similarities exist between traditional text-based IR systems and content-based IR systems Although text-based IR systems have been relatively successful, CBIR still has many barriers to overcome. Visual Feature Extraction Multi-Dimensional Indexing Retrieval System Design Although the discussed article is 5 years old, recent studies show Image IR research and development trends continue to focus on similar issues.

21
Conclusion Future research directions Involving humans in the R&D process Identify high-level concepts with low-level visual features Finger print, human face Web oriented High dimensional indexing Performance evaluation criterion and standard testbed Integration of Database and Computer Vision resources

22
Bibliography (2002) Image Retrieval. Retrieved: November 6, 2002, from: http://140.120.7.1/~yloug/images/Image_Retrieval.PDFhttp://140.120.7.1/~yloug/images/Image_Retrieval.PDF. Feng, X. (2002) Content-based Image Retrieval. Retrieved: November 6, 2002, from: http://www.cse.ucsc.edu/classes/ee264/Winter02/xgfeng.ppthttp://www.cse.ucsc.edu/classes/ee264/Winter02/xgfeng.ppt. J. R. Smith and S.-F. Chang, Visually Searching the Web for Content, IEEE Multimedia. July - Sept, 1997, Vol. 4, No. 3, pp. 12-20; part of paper also in Columbia University CTR Technical Report # 45996-25, 1996. Rui, Y., Huang, T. S., & Chang, S. F. (1999). Image Retrieval: Current Techniques, Promising Directions and Open Issues. Vaidya, D. (2002) Visual Information Retrieval. Retrieved: November 6, 2002, from: http://www-isl.ece.arizona.edu/isl- presentations/VISUAL%20INFORMATION%20RETRIEVAL.ppthttp://www-isl.ece.arizona.edu/isl- presentations/VISUAL%20INFORMATION%20RETRIEVAL.ppt Note: All images and quoted content are from J. R. Smith and S.-F. Chang’s Visually Searching the Web for Content.
 Content-based Image Retrieval. Retrieved: November 6, 2002, from: J. R. Smith and S.-F. Chang, Visually Searching the Web for Content, IEEE Multimedia. July - Sept, 1997, Vol. 4, No. 3, pp ; part of paper also in Columbia University CTR Technical Report # , Rui, Y., Huang, T. S., & Chang, S. F. (1999). Image Retrieval: Current Techniques, Promising Directions and Open Issues. Vaidya, D. (2002) Visual Information Retrieval. Retrieved: November 6, 2002, from: presentations/VISUAL%20INFORMATION%20RETRIEVAL.ppthttp://www-isl.ece.arizona.edu/isl- presentations/VISUAL%20INFORMATION%20RETRIEVAL.ppt Note: All images and quoted content are from J. R. Smith and S.-F. Chang’s Visually Searching the Web for Content..")
Similar presentations















 Simon Fraser University March.2005 Shih-Fu Chang, Qian Huang,>")
 Student: Mihaela David Professor: Michael Eckmann Most of the database images in this presentation are from the Annotated.>")
 Video IR.>")



