Download presentation
Presentation is loading. Please wait.

1
Last lecture summary Which measures of variability do you know? What are they advantages and disadvantages? Empirical rule

2
Statistical jargon population (census) vs. sample parameter (population) vs. statistic (sample)
 vs. sample parameter (population) vs. statistic (sample)")
3
Statistical inference A statistic is a value calculated from our observed data (sample). A parameter is a value that describes the population. We want to be able to generalize what we observe in our data to our population. In order to this, the sample needs to be representative. How to select a representative sample? Use randomization.

4
New stuff

5
Random sampling Simple Random Sampling (SRS) – each possible sample from the population is equally likely to be selected. Stratified Sampling – simple random sample from subgroups of the population subgroups: gender, age groups, … Cluster sampling – divide the population into non- overlapping groups (clusters), sample is a randomly chosen cluster example: population are all students in an area, randomly select schools and create a sample from students of the given school
, sample is a randomly chosen cluster example: population are all students in an area, randomly select schools and create a sample from students of the given school.")
6
Simple random sampling sampling with replacement (WR) výběr s navrácením Generates independent samples Two sample values are independent if that what we get on the first one doesn't affect what we get on the second. sampling without replacement (WOR) výběr bez navrácení Deliberately avoid choosing any member of the population more than once. This type of sampling is not independent, however it is more common. The error is small as long as 1. the sample is large 2. the sample size is no more than 10% of population size
 výběr bez navrácení Deliberately avoid choosing any member of the population more than once. This type of sampling is not independent, however it is more common. The error is small as long as 1. the sample is large 2. the sample size is no more than 10% of population size.")
7
Bias If a sample is not representative, it can introduce bias into our results. bias – zkreslení, odchylka A sample is biased if it differs from the population in a systematic way. The Literary Digest poll, 1936, U. S. presidential election surveyed 10 mil. people – subscribers 2.3 mil. responded predicting (3:2) a Republican candidate to win a Democrat candidate won What went wrong? only wealthy people were surveyed (selection bias) survey was voluntary response (nonresponse bias) – angry people or people who want a change
 a Republican candidate to win a Democrat candidate won What went wrong. only wealthy people were surveyed (selection bias) survey was voluntary response (nonresponse bias) – angry people or people who want a change.")
8
Bessel’s correction www.udacity.com – Statistics

9
Sample vs. population SD

10
Bessel's game

12
Bessel’s game 1. List all possible samples of 2 cards. 2. Calculate sample averages. Sample Sample average Population of all cards in a bag

13
Bessel’s game 1. List all possible samples of 2 cards. 2. Calculate sample averages. 3. Now, half of you calculate sample variance using /n, and half of you using /(n-1). 4. And then average all sample variances. Sample Sample average Sample variance 0,21 0,42 2,01 2,43 4,02 4,23 0,00 2,22 4,44 Population of all cards in a bag
. 4. And then average all sample variances. Sample Sample average Sample variance 0,21 0,42 2,01 2,43 4,02 4,23 0,00 2,22 4,44 Population of all cards in a bag.")
14
Bessel’s game Sample Sample average Sample variance (n-1)Sample variance (n) 0,2121 0,4284 2,0121 2,4321 4,0284 4,2321 0,0000 2,2200 4,4400 average
Sample variance (n) 0,2121 0,4284 2,0121 2,4321 4,0284 4,2321 0,0000 2,2200 4,4400 average")
15
Median absolute deviation (MAD) standard deviation is not robust IQR is robust mean absolute deviation MAD – a robust equivalent of the standard deviation Také your data, find median, calculate absolute deviation from the median, find the median of absolutes deviations
 standard deviation is not robust IQR is robust mean absolute deviation MAD – a robust equivalent of the standard deviation Také your data, find median, calculate absolute deviation from the median, find the median of absolutes deviations")
16
Median absolute deviation (MAD) DataMedian deviationAbsolute deviation 5 10 30 20 30 5 15 10 15 Median: MAD:
 DataMedian deviationAbsolute deviation Median: MAD:")
17
NORMAL DISTRIBUTION

18
Playing chess Pretend I am a chess player. Which of the following tells you most about how good I am: 1. My rating is 1800. 2. 8110 th place among world competitive chess players. 3. Ranked higher than 88% of competitive chess players.

19
Distribution Distribution of scores in one particular year We should use relative frequencies and convert all absolute frequencies to proportions.

20
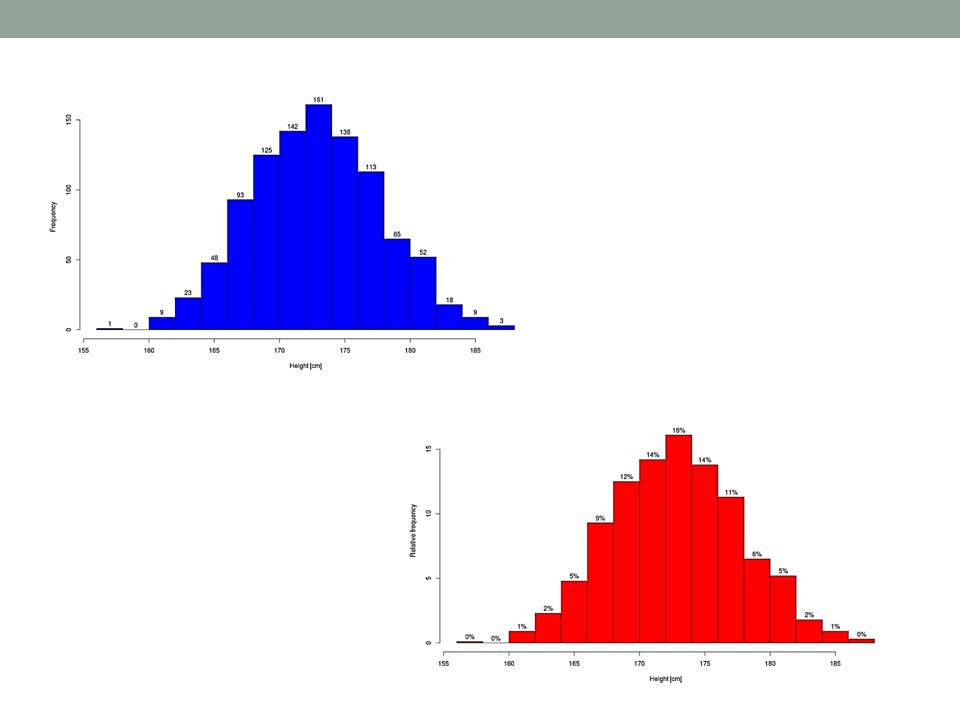
Height data – absolute frequencies http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_Dinov_020108_HeightsWeights

21
Height data – relative frequencies

23
30% What proportion of values is between 170 cm and 173.75 cm?

24
Height data – relative frequencies What proportion of values is between 170 cm and 175 cm? We can’t tell for certain.

25
How should we modify data/histogram to allow us a more detail? 1. Adding more value to the dataset 2. Increasing the bin size 3. A smaller bin size

26
Height data – relative frequencies What proportion of values is between 170 cm and 175 cm? 36%

27
Height data – relative frequencies

29
Normal distribution recall the empirical rule 68-95-99.7

Similar presentations