Download presentation
Presentation is loading. Please wait.

1
A Field Guide part 2 National Center for Biotechnology Information
February 14, 2006 UT-Health Science Center

2
GenBank Records Header The Flatfile Format Feature Table Sequence

3
A Typical GenBank Record
LOCUS NM_ bp mRNA linear INV 28-OCT-2004 DEFINITION Mus musculus REV1-like(S. cerevisiae)(Rev1l),mRNA ACCESSION NM_019570 VERSION NM_ GI: KEYWORDS . A Typical GenBank Record = Title
(Rev1l),mRNA. ACCESSION NM_ VERSION NM_ GI: KEYWORDS . A Typical GenBank Record. = Title.")
4
GenBank Record: Feature Table

5
GenBank Record: Feature Table, con’t.
GenPept identifier

6
GenBank Record: sequence
skip

7
Indexing for Nucleotide UID 59958365
Field Indexed Terms [primary accession] NM_ [title] Bos taurus hemochromatosis (hfe), mRNA. [organism] Bos taurus [sequence length] 1168 [modification date] 2005/02/19 [properties] biomol mrna gbdiv mam srcdb refseq [accn] [orgn] [mdat] [prop]
, mRNA. [organism] Bos taurus. [sequence length] [modification date] 2005/02/19. [properties] biomol mrna. gbdiv mam. srcdb refseq. [accn] [orgn] [mdat] [prop]")
8
Global Entrez Search: HFE

9
Entrez Nucleotide: HFE
137 records [Title] Not HFE

10
Smarter Query hfe[title] AND human[orgn] 42 records Curated HFE
splice variants (11 total)
![Smarter Query hfe[title] AND human[orgn] 42 records Curated HFE](http://slideplayer.com/slide/4372377/14/images/10/Smarter+Query+hfe%5Btitle%5D+AND+human%5Borgn%5D+42+records+Curated+HFE.jpg "splice variants. (11 total)")
11
hfe[title] AND human[orgn] (con’t)
Primary data
![hfe[title] AND human[orgn] (con’t)](http://slideplayer.com/slide/4372377/14/images/11/hfe%5Btitle%5D+AND+human%5Borgn%5D+%28con%E2%80%99t%29.jpg "Primary data.")
12
Preview/Index Gateway to Advanced Searches

13
Preview/Index

14
Preview/Index: Properties, srcdb

15
Preview/Index: Properties, srcdb
…AND srcdb refseq[Properties]

16
Preview/Index: Properties, srcdb
…AND srcdb ddbj/embl/genbank[Properties]

17
Database Queries #1 hfe 137 #2 hfe[title] AND human[orgn] 42
#3 #2 AND srcdb refseq[prop] #4 #2 AND srcdb ddbj/embl/genbank[prop] #5 #4 AND gbdiv pri[prop] #4 #4 AND gbdiv est[prop] Primate division gbdiv pri[prop] EST division gbdiv est[prop]
![Database Queries #1 hfe 137 #2 hfe[title] AND human[orgn] 42](http://slideplayer.com/slide/4372377/14/images/17/Database+Queries+%231+hfe+137+%232+hfe%5Btitle%5D+AND+human%5Borgn%5D+42.jpg "#3 #2 AND srcdb refseq[prop] 11. #4 #2 AND srcdb ddbj/embl/genbank[prop] 31. #5 #4 AND gbdiv pri[prop] 29. #4 #4 AND gbdiv est[prop] 2. Primate division gbdiv pri[prop] EST division gbdiv est[prop]")
18
Molecule Queries #1 hfe 116 #2 hfe[title] AND human[orgn] 42
#3 #2 AND biomol mrna[prop] #4 #2 AND biomol genomic[prop] Genomic DNA biomol genomic[prop] cDNA biomol mrna[prop]
![Molecule Queries #1 hfe 116 #2 hfe[title] AND human[orgn] 42](http://slideplayer.com/slide/4372377/14/images/18/Molecule+Queries+%231+hfe+116+%232+hfe%5Btitle%5D+AND+human%5Borgn%5D+42.jpg "#3 #2 AND biomol mrna[prop] 29. #4 #2 AND biomol genomic[prop] 13. Genomic DNA biomol genomic[prop] cDNA biomol mrna[prop]")
19
srcdb refseq reviewed[prop] AND transcript[title] AND variant[title]
More Queries… Fields are database-specific Entrez Nucleotide Reviewed RefSeqs with transcript variants: srcdb refseq reviewed[prop] AND transcript[title] AND variant[title]
![srcdb refseq reviewed[prop] AND transcript[title] AND variant[title]](http://slideplayer.com/slide/4372377/14/images/19/srcdb+refseq+reviewed%5Bprop%5D+AND+transcript%5Btitle%5D+AND+variant%5Btitle%5D.jpg "More Queries… Fields are database-specific. Entrez Nucleotide. Reviewed RefSeqs with transcript variants: srcdb refseq reviewed[prop] AND transcript[title] AND variant[title]")
20
More Queries… Fields are database-specific Entrez Nucleotide
Reviewed RefSeqs with transcript variants: srcdb refseq reviewed[prop] AND transcript[title] AND variant[title] Topoisomerase genes from Archaea: topoisomerase[gene name] AND archaea[organism] Entrez Gene Genes on human chromosome 2 with OMIM links 2[chromosome] AND human[organism] AND “gene omim”[filter] Membrane proteins linked to cancer: “integral to plasma membrane”[gene ontology] AND cancer[dis]

21
Other Entrez Databases
UniGene: rat clusters that have at least one mRNA rat[organism] NOT 0[mrna count] SNP: uniquely mapped microsatellites on human chr2 microsat[SNP Class] AND 1[Map Weight] AND 2[Chromosome]) AND human[orgn] UniSTS: markers on the Genethon map of human chromosome 12 Genethon[Map Name] AND human[organism] AND 12[chromosome] Structure: structures of bacterial kinases with resolutions below 2 Å bacteria[organism] AND kinase AND :002.00[resolution]
 AND human[orgn] UniSTS: markers on the Genethon map of human chromosome 12. Genethon[Map Name] AND human[organism] AND 12[chromosome] Structure: structures of bacterial kinases with resolutions below 2 Å. bacteria[organism] AND kinase AND :002.00[resolution]")
22
Genome Resources Genomic Biology Genomic Biology UniGene E-PCR
Map Viewer Trace Archive

23
Genomic Biology

24
Gen Biol: Gen Resources

25
Map Viewer – Genome Annotation Updates

26
Gen Biol: Gen Resources

27
Genome Projects: microb

28
Genome Projects: microb
13 Eukaryotic Genome Sequencing Projects Selected: Complete – 0, Assembly – 2, In Progress - 11

29
Genome Projects: microb
13 Eukaryotic Genome Sequencing Projects Selected: Complete – 0, Assembly – 2, In Progress - 11

30
Gen Biol: Gen Resources

31
Gen Biol: Gen Resources

32
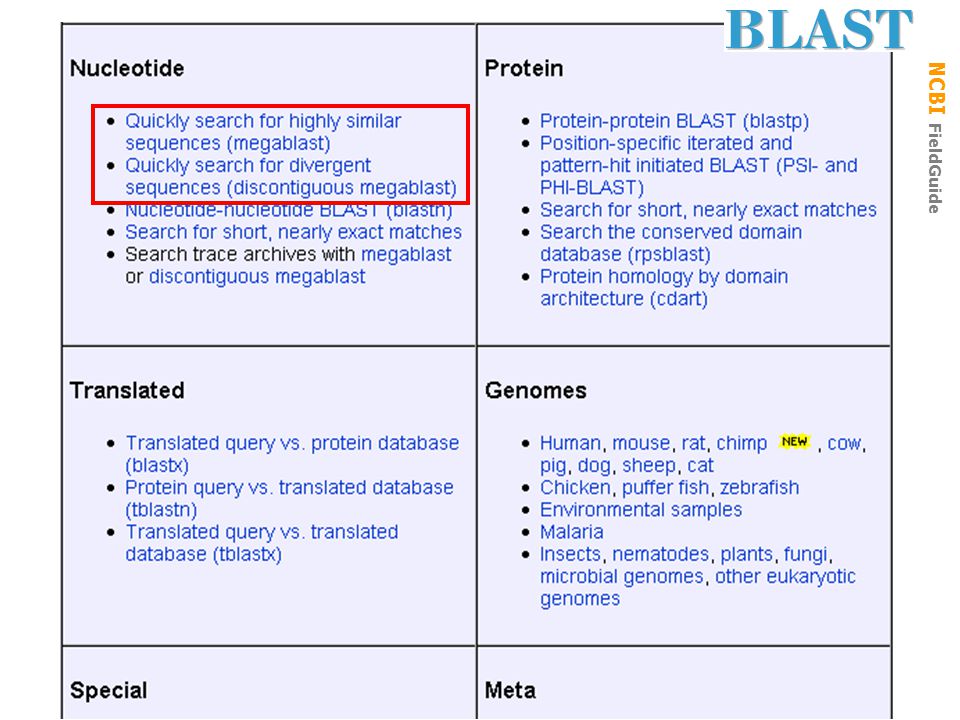
Gen Biol: Gen Resources

33
Gen Biol: Gen Resources

34
Gen Biol: Gen Resources

35
Genome Resources UniGene Genomic Biology E-PCR Map Viewer
Trace Archive

36
Gene-oriented clusters of expressed sequences
UniGene Gene-oriented clusters of expressed sequences Automatic clustering using MegaBlast Each cluster represents a unique gene Informed by genome hits Information on tissue types and map locations Useful for gene discovery and selection of mapping reagents

37
A Cluster of ESTs query 5’ EST hits 3’ EST hits

38
UniGene Collections

39
UniGene Collections Species UniGene

40
UniGene Hs build 188

41
UniGene Cluster Hs.95351 Lipase, hormone-sensitive (LIPE)
")
42
UniGene Cluster Hs.95351

43
UniGene Cluster Hs.95351: expression

44
UniGene Cluster Hs.95351: seqs

45
Get Sequences web page ftp://ftp.ncbi.nih.gov/repository/UniGene/Homo_sapiens/

46
Genome Resources E-PCR Genomic Biology UniGene Map Viewer
Trace Archive

47
E-PCR Genomic sequence here

48
Options

49
Results

50
reverse e-pcr

51
reverse e-pcr

52
reverse e-pcr

53
LY6G6D: lymphocyte antigen 6 complex, locus G6D
reverse e-pcr Gene STS LY6G6D: lymphocyte antigen 6 complex, locus G6D

54
Genome Resources Map Viewer Genomic Biology UniGene E-PCR
Trace Archive

55
List View

56
Human MapViewer adar

57
MapViewer: Human ADAR

58
3’ UTR 5’ UTR MV Hs ADAR

59
Maps & Options Maps & Options --Sequence maps-- --Cytogenetic maps--
Ab initio Assembly Repeats BES_Clone Clone NCI_Clone Contig Component CpG island dbSNP haplotype Fosmid GenBank_DNA Gene Phenotype SAGE_Tag STS TCAG_RNA Transcript (RNA) Hs_UniGene Hs_EST --Cytogenetic maps-- Ideogram FISH Clone Gene_Cytogenetic Mitelman Breakpoint Morbid/Disease --Genetic Maps-- deCODE Genethon Marshfield --RH maps-- GeneMap99-G3 GeneMap99-GB4 NCBI RH Standford-G3 TNG Whitehead-RH Whitehead-YAC Mm_UniGene Mm_EST Rn_UniGene Rn_EST Ssc_UniGene Ssc_EST Bt_UniGene Bt_EST Gga_UniGene Gga_EST Variation = SNP
 Hs_UniGene. Hs_EST. --Cytogenetic maps-- Ideogram. FISH Clone. Gene_Cytogenetic. Mitelman Breakpoint. Morbid/Disease. --Genetic Maps-- deCODE. Genethon. Marshfield. --RH maps-- GeneMap99-G3. GeneMap99-GB4. NCBI RH. Standford-G3. TNG. Whitehead-RH. Whitehead-YAC. Mm_UniGene. Mm_EST. Rn_UniGene. Rn_EST. Ssc_UniGene. Ssc_EST. Bt_UniGene. Bt_EST. Gga_UniGene. Gga_EST. Variation. = SNP.")
60
Component MapViewer Gene UniGene Repeats Customize the annotation

61
Phenotype Variation Gene Customize the annotation

62
Maps & Options Maps & Options
DR52/53 = alternate MHC haplotypes on chr6; hsc_tcag = alternate chr7 assembly.

63
Chimp ADAR Human ADAR Mouse ADAR Customize the annotation

64
Genome Resources Trace Archive Genomic Biology UniGene E-PCR
Map Viewer Trace Archive

65
Trace Archive Page

66
Ciona savignyi Traces

68
Trace Archive BLAST Page
Potential access to sequences NOT yet in GenBank

69
Basic Local Alignment Search Tool

70
BLAST Web Searches, 2005 200,000

71
Precomputed BLAST Services
Nucleotide or protein: Related Sequences BLAST link: BLink Transcript clusters: UniGene Protein homologs: HomoloGene

72
Link to Related Sequences

73
Related Sequences Most similar Least similar

74
BLink (BLAST Link)
")
75
BLink Output Best hits 3D structures CDD-Search

76
Why Is BLAST So Popular? Fast Local alignments
- heuristic approach based on Smith Waterman Local alignments Statistical significance - Expect value Versatile - blastn, blastp, blastx, tblastn, tblastx, rps-blast, psi-blast - www, standalone, and network clients

77
Global vs Local Alignment
Seq 1 Seq 2 Global alignment Seq 1 Seq 2 Local alignment

78
Global vs Local Alignment
Seq1: WHEREISWALTERNOW (16aa) Seq2: HEWASHEREBUTNOWISHERE (21aa) Global Seq1: W--HEREISWALTERNOW 16 W HERE Seq2: 1 HEWASHEREBUTNOWISHERE Local Seq1: 1 W--HERE Seq1: 1 W--HERE 5 W HERE W HERE Seq2: 3 WASHERE Seq2: 15 WISHERE 21
 Seq2: HEWASHEREBUTNOWISHERE (21aa) Global. Seq1: 1 W--HEREISWALTERNOW 16. W HERE. Seq2: 1 HEWASHEREBUTNOWISHERE 21. Local. Seq1: 1 W--HERE 5 Seq1: 1 W--HERE 5. W HERE W HERE. Seq2: 3 WASHERE 9 Seq2: 15 WISHERE 21.")
79
How BLAST Works Make lookup table of “words” for query
Scan database for hits Extend alignment both directions Ungapped extensions of hits (initial HSPs) Gapped extensions (no traceback) Gapped extensions (traceback - alignment details) -X X dropoff value for gapped alignment (in bits) (zero invokes default behavior) blastn 30, megablast 20, tblastx 0, all others 15 [Integer] default = 0 =X2 (in output) -y X dropoff value for ungapped extensions in bits (0.0 invokes default behavior) blastn 20, megablast 10, all others 7 [Real] default = 0.0 =X1 (in output) -Z X dropoff value for final gapped alignment in bits (0.0 invokes default behavior) blastn/megablast 50, tblastx 0, all others 25 [Integer] =X3 (in output)
 Gapped extensions (no traceback) Gapped extensions (traceback - alignment details) -X X dropoff value for gapped alignment (in bits) (zero invokes default. behavior) blastn 30, megablast 20, tblastx 0, all others 15 [Integer] default = 0. =X2 (in output) -y X dropoff value for ungapped extensions in bits (0.0 invokes default. behavior) blastn 20, megablast 10, all others 7 [Real] default = 0.0. =X1 (in output) -Z X dropoff value for final gapped alignment in bits (0.0 invokes default. behavior) blastn/megablast 50, tblastx 0, all others 25 [Integer] =X3 (in output)")
80
Protein Words GTQITVEDLFYNIATRRKALKN GTQ TQI QIT ITV TVE VED EDL DLF
Query: Word size = 3 (default) Word size can only be 2 or 3 GTQ TQI QIT ITV TVE VED EDL DLF ... Make a lookup table of words Neighborhood Words VTV, LTV, VSV, etc. VTV 12 LTV 11 VSV 8 Neighborhood score threshold
 Word size can only be 2 or 3. GTQ. TQI. QIT. ITV. TVE. VED. EDL. DLF. ... Make a lookup. table of words. Neighborhood Words. VTV, LTV, VSV, etc. VTV 12. LTV 11. VSV 8. Neighborhood score threshold.")
81
Highest score – current score
BLASTP Summary Query: IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILEV… example query words HFL 18 HFV 15 HFS 14 HWL 13 NFL 13 DFL 12 HWV 10 etc … YLS 15 YLT 12 YVS 12 YIT 10 Neighborhood words Neighborhood score threshold T (-f) =11 YLS HFL Sbjct 287 LEETYAKYLHKGASYFVYLSLNMSPEQLDVNVHPSKRIVHFLYDQEI 333 Query 1 IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESI 47 +E YA YL K F+ L +SP+ +DVNVHP+K V I Drop-off score = Highest score – current score -X X dropoff value for gapped alignment (in bits) blastn 30, megablast 20, tblastx 0, all others 15
 =11. YLS HFL. Sbjct 287 LEETYAKYLHKGASYFVYLSLNMSPEQLDVNVHPSKRIVHFLYDQEI 333. Query 1 IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESI 47. +E YA YL K F+ L +SP+ +DVNVHP+K V +++ I. Drop-off score = Highest score – current score. -X X dropoff value for gapped alignment (in bits) blastn 30, megablast 20, tblastx 0, all others 15.")
82
BLASTP Summary High-scoring pair (HSP) Final HSP example query words
Query: IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILEV… example query words HFL 18 HFV 15 HFS 14 HWL 13 NFL 13 DFL 12 HWV 10 etc … YLS 15 YLT 12 YVS 12 YIT 10 Neighborhood words Neighborhood score threshold T (-f) =11 YLS HFL Sbjct 287 LEETYAKYLHKGASYFVYLSLNMSPEQLDVNVHPSKRIVHFLYDQEI 333 Query 1 IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESI 47 +E YA YL K F+ L +SP+ +DVNVHP+K V I High-scoring pair (HSP) Gapped extension with trace back Query 1 IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESI-LEV… 50 +E YA YL K F+YLSL +SP+ +DVNVHP+K VHFL+++ I + + Sbjct 287 LEETYAKYLHKGASYFVYLSLNMSPEQLDVNVHPSKRIVHFLYDQEIATSI… 337 Final HSP
 =11. YLS HFL. Sbjct 287 LEETYAKYLHKGASYFVYLSLNMSPEQLDVNVHPSKRIVHFLYDQEI 333. Query 1 IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESI 47. +E YA YL K F+ L +SP+ +DVNVHP+K V +++ I. High-scoring pair (HSP) Gapped extension with trace back. Query 1 IETVYAAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESI-LEV… 50. +E YA YL K F+YLSL +SP+ +DVNVHP+K VHFL+++ I + + Sbjct 287 LEETYAKYLHKGASYFVYLSLNMSPEQLDVNVHPSKRIVHFLYDQEIATSI… 337. Final HSP.")
83
Scoring Systems - Nucleotides
Identity matrix A G C T A +1 –3 –3 -3 G –3 +1 –3 -3 C –3 – T –3 –3 –3 +1 [ -r 1 -q -3 ] The default values for M and N, respectively 5 and -4, having a ratio of 1.25, correspond to about 47 nucleic acid PAMs, or about 58 amino acid PAMs; an M:N ratio of 1 corresponds to 30 nucleic acid PAMs or 38 amino acid PAMs. At higher than about 40 nucleic acid PAMs, or 50 amino acid PAMs, better sensitivity at detecting similarities between coding regions is expected by performing comparisons at the amino acid level (States et al., 1991). CAGGTAGCAAGCTTGCATGTCA || |||||||||||| ||||| raw score = 19-9 = 10 CACGTAGCAAGCTTG-GTGTCA
. CAGGTAGCAAGCTTGCATGTCA. || |||||||||||| ||||| raw score = 19-9 = 10. CACGTAGCAAGCTTG-GTGTCA.")
84
Scoring Systems - Proteins
Position Independent Matrices PAM Matrices (Percent Accepted Mutation) Derived from observation; small dataset of alignments Implicit model of evolution All calculated from PAM1 PAM250 widely used BLOSUM Matrices (BLOck SUbstitution Matrices) Derived from observation; large dataset of highly conserved blocks Each matrix derived separately from blocks with a defined percent identity cutoff BLOSUM62 - default matrix for BLAST Position Specific Score Matrices (PSSMs) PSI- and RPS-BLAST
 Derived from observation; small dataset of alignments. Implicit model of evolution. All calculated from PAM1. PAM250 widely used. BLOSUM Matrices (BLOck SUbstitution Matrices) Derived from observation; large dataset of highly conserved blocks. Each matrix derived separately from blocks with a defined percent identity cutoff. BLOSUM62 - default matrix for BLAST. Position Specific Score Matrices (PSSMs) PSI- and RPS-BLAST.")
85
BLOSUM62 Negative for less likely substitutions
D C Q E G H I L K M F P S T W Y V X A R N D C Q E G H I L K M F P S T W Y V X D F Negative for less likely substitutions Y F Positive for more likely substitutions

86
Position-Specific Score Matrix
Serine/Threonine protein kinases catalytic loop 1 7 4 PSSM scores 5 DAF-1 abnormal DAuer Formation DAF-1, cell-surface receptor daf-1 [Caenorhabditis elegans] gi| |ref|NP_

87
Position-Specific Score Matrix
A R N D C Q E G H I L K M F P S T W Y V 435 K 436 E 437 S 438 N 439 K 440 P 441 A 442 M 443 A 444 H 445 R 446 D 447 I 448 K 449 S 450 K 451 N 452 I 453 M 454 V 455 K 456 N 457 D 458 L catalytic loop cell-surface receptor daf-1 [Caenorhabditis elegans] ; gi| |ref|NP_ ; -j3 vs nr >blastpgp -i NP_ d nr -j 3 -Q NP_ pssm

88
Local Alignment Statistics
Expect Value E = number of database hits you expect to find by chance, ≥ S (applies to ungapped alignments) E = Kmne-S or E = mn2-S’ K = scale for search space = scale for scoring system S’ = bitscore = (S - lnK)/ln2 Lambda -- the expected increase in reliability of an alignment associated with a unit increase in alignment score. E (range 0 to infinity) can be extrapolated to an expectation over the entire database search, by converting the pairwise expectation to a probability (range 0-1) and multiplying the result by the ratio of the entire database size to the length of the database sequence: E_database = (1 - exp(-E)) D / d where D is the size of the database; d is the length of the matching database sequence; and the quantity (1 - exp(-E)) is the probability, P, corresponding to the expectation E for the pairwise comparison. As E approaches 0, E and P approach equality. Due to inaccuracy in the statistical methods as applied in the BLAST programs, whenever E and P are less than about 0.05, the two values can be practically treated as equal. Effective length: computed according to: Length_eff = MAX( Length_real - Lambda S / H , 1) where H is the relative entropy of the target and background residue frequencies (Karlin and Altschul, 1990). H : the information expected to be obtained from each pair of aligned residues in a real alignment that distinguishes the alignment from a random one. More info: The Statistics of Sequence Similarity Scores
 E = Kmne-S or E = mn2-S’ K = scale for search space. = scale for scoring system. S’ = bitscore = (S - lnK)/ln2. Lambda -- the expected increase in reliability of an alignment associated with a unit increase in alignment score. E (range 0 to infinity) can be extrapolated to an expectation over the entire database search, by converting the pairwise expectation to a probability (range 0-1) and multiplying the result by the ratio of the entire database size to the length of the database sequence: E_database = (1 - exp(-E)) D / d where D is the size of the database; d is the length of the matching database sequence; and the quantity (1 - exp(-E)) is the probability, P, corresponding to the expectation E for the pairwise comparison. As E approaches 0, E and P approach equality. Due to inaccuracy in the statistical methods as applied in the BLAST programs, whenever E and P are less than about 0.05, the two values can be practically treated as equal. Effective length: computed according to: Length_eff = MAX( Length_real - Lambda S / H , 1) where H is the relative entropy of the target and background residue frequencies (Karlin and Altschul, 1990). H : the information expected to be obtained from each pair of aligned residues in a real alignment that distinguishes the alignment from a random one. More info: The Statistics of Sequence Similarity Scores.")
89
An Alignment BLAST Cannot Make
1 GAATATATGAAGACCAAGATTGCAGTCCTGCTGGCCTGAACCACGCTATTCTTGCTGTTG || | || || || | || || || || | ||| |||||| | | || | ||| | 1 GAGTGTACGATGAGCCCGAGTGTAGCAGTGAAGATCTGGACCACGGTGTACTCGTTGTCG 61 GTTACGGAACCGAGAATGGTAAAGACTACTGGATCATTAAGAACTCCTGGGGAGCCAGTT | || || || ||| || | |||||| || | |||||| ||||| | | 61 GCTATGGTGTTAAGGGTGGGAAGAAGTACTGGCTCGTCAAGAACAGCTGGGCTGAATCCT 121 GGGGTGAACAAGGTTATTTCAGGCTTGCTCGTGGTAAAAAC |||| || ||||| || || | | |||| || ||| 121 GGGGAGACCAAGGCTACATCCTTATGTCCCGTGACAACAAC Reason: no contiguous exact match of 7 bp.

90
An Alignment BLAST Can Make
Score = 290 bits (741), Expect = 7e-77 Identities = 147/331 (44%), Positives = 206/331 (61%), Gaps = 8/331 (2%) Frame = +3 Solution: compare protein sequences; BLASTX BLAST 2 Sequences (blastx) output:
, Expect = 7e-77 Identities = 147/331 (44%), Positives = 206/331 (61%), Gaps = 8/331 (2%) Frame = +3. Solution: compare protein sequences; BLASTX. BLAST 2 Sequences (blastx) output:")
91
Other BLAST Algorithms
Megablast Discontiguous Megablast PSI-BLAST PHI-BLAST

92
Megablast: NCBI’s Genome Annotator
Long alignments of similar DNA sequences Greedy algorithm Concatenation of query sequences Faster than blastn; less sensitive

93
MegaBLAST & Word Size Trade-off: sensitivity vs speed blastn megablast
2 3 blastp 8 28 megablast 7 11 blastn minimum default WORD SIZE Consider for each search

94
Discontiguous Megablast
Uses discontiguous word matches Better for cross-species comparisons

95
Templates for Discontiguous Words
W = 11, t = 16, coding: W = 11, t = 16, non-coding: W = 12, t = 16, coding: W = 12, t = 16, non-coding: W = 11, t = 18, coding: W = 11, t = 18, non-coding: W = 12, t = 18, coding: W = 12, t = 18, non-coding: W = 11, t = 21, coding: W = 11, t = 21, non-coding: W = 12, t = 21, coding: W = 12, t = 21, non-coding: W = word size; # matches in template t = template length Reference: Ma, B, Tromp, J, Li, M. PatternHunter: faster and more sensitive homology search. Bioinformatics March, 2002; 18(3):440-5
:")
97
Discontiguous (Cross-species) MegaBLAST
 MegaBLAST")
98
Discontiguous Word Options
Non-affine gap scores: gap open penalty = 0; gap extension penalty = match/2 - mismatch (mismatch < 0). Non-affine gapping parameters tend to yield alignments with more gaps, but the gap lengths are shorter. The latter formula is applied automatically if -G and -E command line parameters are both set to 0.
. Non-affine gapping parameters tend to yield alignments with more gaps, but the gap lengths are shorter. The latter formula is applied automatically if -G and -E command line parameters. are both set to 0.")
99
Disco. Megablast Example . . .
Query: NM_078651 Drosophila melanogaster CG18582-PA (mbt) mRNA, (3244 bp) /note= mushroom bodies tiny; synonyms: Pak2, STE20, dPAK2 Database: nr (nt), Mammalia[orgn] MegaBLAST = “No significant similarity found.” Discontiguous megaBLAST = numerous hits . . .
 mRNA, (3244 bp) /note= mushroom bodies tiny; synonyms: Pak2, STE20, dPAK2. Database: nr (nt), Mammalia[orgn] MegaBLAST = No significant similarity found. Discontiguous megaBLAST = numerous hits")
100
Ex: Discontiguous MegaBLAST

101
Ex: BLASTN

102
PSI-BLAST Position-specific Iterated BLAST
Example: Confirming relationships of purine nucleotide metabolism proteins

103
PSI-BLAST E value cutoff for PSSM
>gi|113340|sp|P03958|ADA_MOUSE ADENOSINE DEAMINASE (ADENOSINE MAQTPAFNKPKVELHVHLDGAIKPETILYFGKKRGIALPADTVEELRNIIGMDKPLSLPGF VIAGCREAIKRIAYEFVEMKAKEGVVYVEVRYSPHLLANSKVDPMPWNQTEGDVTPDDVVD EQAFGIKVRSILCCMRHQPSWSLEVLELCKKYNQKTVVAMDLAGDETIEGSSLFPGHVEAY RTVHAGEVGSPEVVREAVDILKTERVGHGYHTIEDEALYNRLLKENMHFEVCPWSSYLTGA VRFKNDKANYSLNTDDPLIFKSTLDTDYQMTKKDMGFTEEEFKRLNINAAKSSFLPEEEKK 0.005 E value cutoff for PSSM

104
RESULTS: Initial BLASTP
Same results as protein-protein BLAST; different format

105
Results of First PSSM Search
Other purine nucleotide metabolizing enzymes not found by ordinary BLAST

106
Tenth PSSM Search: Convergence
Just below threshold, another nucleotide metabolism enzyme Check to add to PSSM

107
PHI-BLAST [GA]xxxxGK[ST]
>gi|231729|sp|P30429|CED4_CAEEL CELL DEATH PROTEIN 4 MLCEIECRALSTAHTRLIHDFEPRDALTYLEGKNIFTEDHSELISKMSTRLERIANFLRIYRRQASE LIDFFNYNNQSHLADFLEDYIDFAINEPDLLRPVVIAPQFSRQMLDRKLLLGNVPKQMTCYIREYHV IKKLDEMCDLDSFFLFLHGRAGSGKSVIASQALSKSDQLIGINYDSIVWLKDSGTAPKSTFDLFTDI LKSEDDLLNFPSVEHVTSVVLKRMICNALIDRPNTLFVFDDVVQEETIRWAQELRLRCLVTTRDVEI ASQTCEFIEVTSLEIDECYDFLEAYGMPMPVGEKEEDVLNKTIELSSGNPATLMMFFKSCEPKTFEK [GA]xxxxGK[ST]
![PHI-BLAST [GA]xxxxGK[ST]](http://slideplayer.com/slide/4372377/14/images/107/PHI-BLAST+%5BGA%5DxxxxGK%5BST%5D.jpg ">gi|231729|sp|P30429|CED4_CAEEL CELL DEATH PROTEIN 4. MLCEIECRALSTAHTRLIHDFEPRDALTYLEGKNIFTEDHSELISKMSTRLERIANFLRIYRRQASE. LIDFFNYNNQSHLADFLEDYIDFAINEPDLLRPVVIAPQFSRQMLDRKLLLGNVPKQMTCYIREYHV. IKKLDEMCDLDSFFLFLHGRAGSGKSVIASQALSKSDQLIGINYDSIVWLKDSGTAPKSTFDLFTDI. LKSEDDLLNFPSVEHVTSVVLKRMICNALIDRPNTLFVFDDVVQEETIRWAQELRLRCLVTTRDVEI. ASQTCEFIEVTSLEIDECYDFLEAYGMPMPVGEKEEDVLNKTIELSSGNPATLMMFFKSCEPKTFEK. [GA]xxxxGK[ST]")
108
What’s New?

109
BLAST Databases nr = nr Nucleotide refseq_rna = NM_*, XM_*
refseq_genomic = NC_*, NG_* env_nt environmental sample[filter], e.g., 16S rRNA Protein refseq = NP_*, XP_* env_nr nr = nr

110
New Formatter Select lower case Select red

111
BLAST Output: Alignments & Filter
low complexity sequence filtered

112
BLAST Output: CDS Feature

113
Advanced Options Limit to Organism Example Entrez Queries
all[filter] NOT ma Example Entrez Queries all[Filter] NOT mammalia[Organism] ray finned fishes[Organism] srcdb refseq[Properties] Nucleotide only: biomol mrna[Properties] biomol genomic[Properties] OtherAdvanced –e expect value -v descriptions -b 2000 alignments -e v 2000

114
Genome BLAST

115
Genome BLAST via Map Viewer

116
Example: Human Genome BLAST
TGCCTCCTTTGGTGAAGGTGACACATCATGTGACCTCTTCAGTGACCACTCTACGGTGTCGGGCCTTGAACTACTACCCCCAGAAC ATCACCATGAAGTGGCTGAAGGATAAGCAGCCAATGGATGCCAAGGAGTTCGAACCTAAAGACGTATTGCCCAATGGGGATGGGAC CTACCAGGGCTGGATAACCTTGGCTGTACCCCCTGGGGAAGAGC Human EST

117
Human Genome BLAST: Results

118
Human Genome BLAST: MapViewer
Entrez Gene

119
Example: Mapping Oligos Onto a Genome
? >forward CCATGGCGACCCTGGAAAAGC >reverse CAGCAGCGGCTGTGCCTGCGG ? ?

120
Map Oligos Onto Genome forward primer reverse primer -W 7 –e 1000
>CCATGGCGACCCTGGAAAAGCNNNNNNNNNNCAGCAGCGGCTGTGCCTGCGG forward primer reverse primer -W 7 –e 1000

121
Genome BLAST Results

122
Primer Alignments reverse primer forward primer

123
MapViewer

124
MapViewer

125
Sequence View (sv) forward reverse
 forward reverse")
126
Service Addresses BLAST blast-help@ncbi.nlm.nih.gov
General Help Wayne Matten

Similar presentations


 Species-specific databases Protein sequence GenBank (Entrez protein) UniProtKB (SwissProt) Protein structure.>")








 discussed in this section is in Box 2.1.>")








