Download presentation
Presentation is loading. Please wait.

1
Bayesian Estimators of Time to Most Recent Common Ancestry Ecology and Evolutionary Biology Adjunct Appointments Molecular and Cellular Biology Plant Sciences Epidemiology & Biostatistics Animal Sciences Bruce Walsh jbwalsh@u.arizona.edu

2
Definitions MRCA - Most Recent Common Ancestor TMRCA - Time to Most Recent Common Ancestor Question: Given molecular marker information from a pair of individuals, what is the estimated time back to their most recent common ancestor? With even a small number of highly polymorphic autosomal markers, trivial to assess zero (subject/ biological sample) and one (parent-offspring) MRCA
 and one (parent-offspring) MRCA.")
3
Problems with Autosomal Markers Often we are very interested in MRCAs that are modest (5-10 generations) or large (100’s to 10,000’s of generations) Unlinked autosomal markers simply don’t work over these time scales. Reason: IBD probabilities for individuals sharing a MRCA 5 or more generations ago are extremely small and hence very hard to estimate (need VERY large number of markers).
..")
4
MRCA-I vs. MRCA-G We need to distinguish between the MRCA for a pair of individuals (MRCA-I) and the MRCA for a particular genetic marker G (MRCA-G). MRCA-G varies between any two individuals over recombination units. For example, we could easily have for a pair of relatives MRCA (mtDNA ) = 180 generations MRCA (Y ) = 350 generations MRCA (one -globulin allele ) = 90 generations MRCA (other -globulin allele ) = 400 generations
 and the MRCA for a particular genetic marker G (MRCA-G). MRCA-G varies between any two individuals over recombination units. For example, we could easily have for a pair of relatives MRCA (mtDNA ) = 180 generations MRCA (Y ) = 350 generations MRCA (one -globulin allele ) = 90 generations MRCA (other -globulin allele ) = 400 generations.")
5
MRCA-G > MRCA-I MRCA-I lost MRCA-G( )
")
6
mtDNA and Y Chromosomes So how can we accurately estimate TMRCA for modest to large number of generations? Answer: Use a set of completely linked markers With autosomes, unlinked markers assort each generation leaving only a small amount of IBD information on each marker, which we must then multiply together. IBD information decays on the order of 1/2 each generation. With completely linked marker loci, information on IBD does not assort away via recombination. IBD information decay is on the order of the mutation rate.

7
Y chromosome microsatellite mutation rates- I Estimate of uSourceReference 0.0028Y chromosomeKayser et al. 2000 0.0021Y chromosomeHeyer et al. 1997 0.001 - 0.0021Autosomal chromosomes Wong & Weber 1993 Brinkmann 1998 Estimates of human mutation rate in microsatellites are fairly consistent over both the Y and the autosomes

8
Basic Structure of the Problem What is the probability that the two marker alleles at a haploid locus from two related individuals agree given that their MRCA was t generation ago? Phrased another way, what is their probability of identity in state (IBS), given they are identical by descent (IBD) when their TMRCA is t generations
, given they are identical by descent (IBD) when their TMRCA is t generations.")
9
Infinite Alleles Model The first step in answering this question is to assume a particular mutational model Our (initial) assumption will be the infinite alleles model (IAM) The key assumption of this model (originally due to Kimura and Crow, 1964) is that each new mutation gives rise to a new allele. The IAM was the first population-genetics model to attempt to formally incorporate the structure of DNA into a model

10
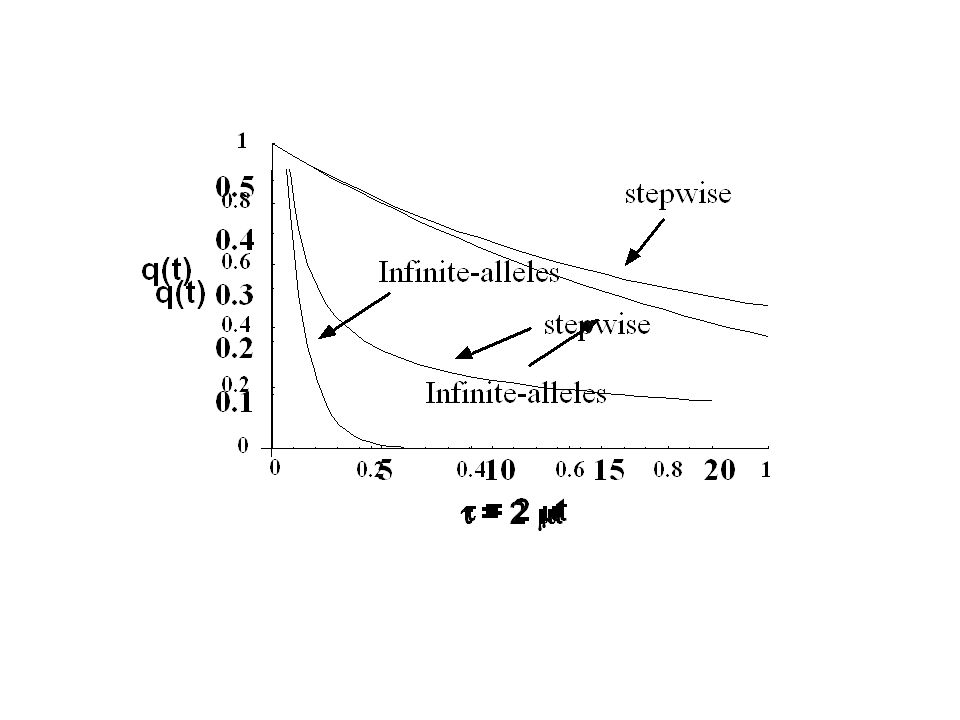
Key: Under the infinite alleles, two alleles that are identical in state that are also ibd have not experienced any mutations since their MRCA. Let q(t) = Probability two alleles with a MRCA t generations ago are identical in state If u = per generation mutation rate, then q(t) = (1-u) 2t MRCA (1-u) t A B MRCA Pr(No mutation from MRCA->A) = (1-u) t Pr(No mutation from MRCA->B) = (1-u) t
 = Probability two alleles with a MRCA t generations ago are identical in state If u = per generation mutation rate, then q(t) = (1-u) 2t MRCA (1-u) t A B MRCA Pr(No mutation from MRCA->A) = (1-u) t Pr(No mutation from MRCA->B) = (1-u) t.")
11
q(t) = (1-u) 2t ≈ e -2ut = e - , = 2ut Building the Likelihood Function for n Loci For any single marker locus, the probability of IBS given a TMRCA of t generations is The probability that k of n marker loci are IBS is just - - - a Binomial distribution with success parameter q(t) - - - - - ( ) Likelihood function for t given k of n matches
 = (1-u) 2t ≈ e -2ut = e - , = 2ut Building the Likelihood Function for n Loci For any single marker locus, the probability of IBS given a TMRCA of t generations is The probability that k of n marker loci are IBS is just a Binomial distribution with success parameter q(t) ( ) Likelihood function for t given k of n matches")
12
ML Analysis of TMRCA - - - - - ( ) It would seem that we now have all the pieces in hand for a likelihood analysis of TMRCA given the marker data (k of n matches) Likelihood function ( = 2ut) MLE for t is solution of ∂ L/∂t = 0 p = fraction of matches - () () ^ ^
 It would seem that we now have all the pieces in hand for a likelihood analysis of TMRCA given the marker data (k of n matches) Likelihood function ( = 2ut) MLE for t is solution of ∂ L/∂t = 0 p = fraction of matches - () () ^ ^")
13
In particular, the MLE for t becomes Likewise, the precision of this estimator follows for the (negative) inverse of the 2nd derivative of the log-likelihood function evaluated at the MLE, ( ) - Var( t ) = - - ( ) ^ ^ -
 inverse of the 2nd derivative of the log-likelihood function evaluated at the MLE, ( ) - Var( t ) = - - ( ) ^ ^ -")
14
Likewise, we can (numerically) easily find 1-LOD support intervals for t and hence construct approximate 95% confidence intervals to TMRCA Finally, hypothesis testing, say Ho: MRCA = t 0, is easily accomplished by comparing -2* the natural log of the ratio of the value of the likelihood function at t = t 0 over the value of the likelihood function at the MLE t = t ^ The resulting log likelihood ratio LR is (asymptotically) distributed as a chi-square distribution with one degree of freedom
 easily find 1-LOD support intervals for t and hence construct approximate 95% confidence intervals to TMRCA Finally, hypothesis testing, say Ho: MRCA = t 0, is easily accomplished by comparing -2* the natural log of the ratio of the value of the likelihood function at t = t 0 over the value of the likelihood function at the MLE t = t ^ The resulting log likelihood ratio LR is (asymptotically) distributed as a chi-square distribution with one degree of freedom")
15
Trouble in Paradise The ML machinery has seem to have done its job, giving us an estimate, its approximate sampling error, approximate confidence intervals, and a scheme for hypothesis testing. Hence, all seems well. Problem: Look at k=n (= complete match at all markers). MLE (TMRCA) = 0 (independent of n) Var(MLE) = 0 (ouch!)
. MLE (TMRCA) = 0 (independent of n) Var(MLE) = 0 (ouch!).")
16
With n=k, the value of the likelihood function is L(t) = (1-u) 2tn ≈ e -2tun What about one-LOD support intervals (95% CI) ? L has a maximum value of one under the MLE Hence, any value of t that gives a likelihood value of 0.1 or larger is in the one-LOD support interval Solving, the one-LOD support interval is from t=0 to t = (1/2n) [ -Ln(10)/Ln(1-u) ] ≈ (1/n) [ Ln(10)/(2u) ] For u = 0.002, CI is (0, 575/n)
 [ -Ln(10)/Ln(1-u) ] ≈ (1/n) [ Ln(10)/(2u) ] For u = 0.002, CI is (0, 575/n).")
17
With n=k, likelihood function reduces to L(t) = (1-u) 2tn ≈ e -2tun t L(t) (Plots for u = 0.002) MLE(t) = 0 for all values on n n=5 n=10 n=20 0.1 of max value (1) of likelihood function 1 LOD ≈ t = 29 1 LOD ≈ t = 58 1 LOD ≈ t = 115
 = (1-u) 2tn ≈ e -2tun t L(t) (Plots for u = 0.002) MLE(t) = 0 for all values on n n=5 n=10 n= of max value (1) of likelihood function 1 LOD ≈ t = 29 1 LOD ≈ t = 58 1 LOD ≈ t = 115")
18
What about Hypothesis testing? Again recall that for k =n that the likelihood at t = t 0 is L(t 0 ) ≈ Exp(-2 t 0 un) Hence, the LR test statistic for Ho: t = t 0 is just LR = -2 ln [ L(t 0 )/ L(0) ] = -2 ln [ Exp(-2 t 0 un) / 1 ] = 4t 0 un Thus the probability for the test that TMRCA = t 0 is just Pr( 1 2 > 4t 0 un)
 ≈ Exp(-2 t 0 un) Hence, the LR test statistic for Ho: t = t 0 is just LR = -2 ln [ L(t 0 )/ L(0) ] = -2 ln [ Exp(-2 t 0 un) / 1 ] = 4t 0 un Thus the probability for the test that TMRCA = t 0 is just Pr( 1 2 > 4t 0 un).")
19
The problem(s) with ML The expressions developed for the sampling variance, approximate confidence intervals, and hypothesis testing are all large-sample approximations Problem 1: Here our sample size is the number of markers scored in the two individuals. Not likely to be large. Problem 2: These expressions are obtained by taking appropriate limits of the likelihood function. If the ML is exactly at the boundary of the admissible space on the likelihood surface, this limit may not formally exist, and hence the above approximations are incorrect.

20
The solution? “Ain’t Too Proud to Bayes” -- Brad Carlin

21
Why Go Bayesian An extension of likelihood is Bayesian statistics p( | x) = C * l(x | ) p( ) Instead of simply estimating a point estimate (e.g., the MLE), the goal is the estimate the entire distribution for the unknown parameter given the data x posterior distribution of given x Likelihood function for Given the data x prior distribution for The appropriate constant so that the posterior integrates to one. Why Bayesian? Exact for any sample size Marginal posteriors Efficient use of any prior information MCMC (such as Gibbs sampling) methods
 methods.")
22
The Prior on TMRCA The first step in any Bayesian analysis is choice of an appropriate prior distribution p(t) -- our thoughts on the distribution of TMRCA in the absence of any of the marker data Standard approach: Use a flat or uninformative prior, with p(t) = a constant over the admissible range of the parameter. Can cause problems if the likelihood function is unbounded (integrates to infinity) In our case, population-genetic theory provides the prior: under very general settings, the time to MRCA for a pair of individuals follows a geometric distribution
 In our case, population-genetic theory provides the prior: under very general settings, the time to MRCA for a pair of individuals follows a geometric distribution.")
23
In particular, for a haploid gene, TMRCA follows a geometric distribution with mean 1/N e. Hence, our prior is just p(t) = (1- ) t ≈ e - t, where = 1/N e Hence, we can use an exponential prior with hyperparameter (the parameter fully characterizing the distribution) = 1/N e. The posterior thus becomes - - - - Previous likelihood function (ignoring constants that cancel when we compute the normalizing factor C) Prior Prior hyperparameter = 1/N e
 = (1- ) t ≈ e - t, where = 1/N e Hence, we can use an exponential prior with hyperparameter (the parameter fully characterizing the distribution) = 1/N e. The posterior thus becomes Previous likelihood function (ignoring constants that cancel when we compute the normalizing factor C) Prior Prior hyperparameter = 1/N e.")
24
The Normalizing constant - - - - where - -- - I ensures that the posterior distribution integrates to one, and hence is formally a probability distribution

25
What is the effect of the hyperparameter? - - - - If 2uk >>, then essentially no dependence on the actual value of chosen. Hence, if 2N e uk >> 1, essentially no dependence on (hyperparameter) assumptions of the prior. For a typical microsatellite rate of u = 0.002, this is just N e k >> 250, which is a very weak assumption. For example, with k =10 matches, N e >> 25. Even with only 1 match (k=1), just require N e >> 250.
 assumptions of the prior. For a typical microsatellite rate of u = 0.002, this is just N e k >> 250, which is a very weak assumption. For example, with k =10 matches, N e >> 25. Even with only 1 match (k=1), just require N e >>")
26
Closed-form Solutions for the Posterior Distribution Complete analytic solutions to the prior can be obtained by using a series expansion (of the (1-e x ) n term) to give -- - - --- - - - - ( = - - -- - - Each term is just a * e bt, which is easily integrated
 n term) to give ( = Each term is just a * e bt, which is easily integrated")
27
- - - - -- - - - - - - - - - - With the assumption of a flat prior, = 0, this reduces to - -

28
Hence, the complete analytic solution of the posterior is Suppose k = n (no mismatches) -- - - - - - - ( In this case, the prior is simply an exponential distribution with mean 2un +, -
 ( In this case, the prior is simply an exponential distribution with mean 2un +, -")
29
Analysis of n = k case Mean TMRCA and its variance: < -- Cumulative probability: In particular, the time T satisfying P(t < T ) = is - -
 = is - -")
30
For a flat prior ( = 0), the 95% (one-side) credible interval is thus given by -ln(0.5)/(2nu) ≈ 1.50/(nu) Hence, under a Bayesian analysis for u = 0.02, the 95% upper credible interval is given by ≈ 749/n Recall that the one-LOD support interval (approximate 95% CI) under an ML analysis is ≈ 575/n The ML solution’s asymptotic approximation significantly underestimates the true interval relative to the exact analysis under a full Bayesian model
, the 95% (one-side) credible interval is thus given by -ln(0.5)/(2nu) ≈ 1.50/(nu) Hence, under a Bayesian analysis for u = 0.02, the 95% upper credible interval is given by ≈ 749/n Recall that the one-LOD support interval (approximate 95% CI) under an ML analysis is ≈ 575/n The ML solution’s asymptotic approximation significantly underestimates the true interval relative to the exact analysis under a full Bayesian model")
31
Why the difference? Under ML, we plot the likelihood function and look for the 0.1 value Under a Bayesian analysis, we look at the posterior probability distribution (likelihood adjusted to integrate to one) and find the values that give an area of 0.95 n = 20, area to left of t=38 = 0.95 n = 10, area to left of t=75 = 0.95 t Pr(TMRCA < t) n = 20, t 0.95 = 38 n = 10, t 0.95 = 75
 and find the values that give an area of 0.95 n = 20, area to left of t=38 = 0.95 n = 10, area to left of t=75 = 0.95 t Pr(TMRCA < t) n = 20, t 0.95 = 38 n = 10, t 0.95 = 75.")
32
Posteriors for n = 10 Sample Posteriors for u = 0.002 Posteriors for n = 20 Posteriors for n = 50 2019181716151413121110987654321 0.00 0.05 0.10 0.15 0.20 0.25 0.30 Time t to MRCA p( t | k ) 100 99 98 96 95 97 n = 100 65605550454035302520151050 0.000 0.010 0.020 0.030 0.040 0.050 0.060 Time t to MRCA p( t | k ) 94 93 92 91 90 89 n = 100
 n = Time t to MRCA p( t | k ) n = 100")
33
Key points By using the appropriate number of markers we can get accurate estimates for TMRCA for even just a few generations. 20-50 markers will do. By using markers on a non-recombining chromosomal section, we can estimate TMRCA over much, much longer time scales than with unlinked autosomal markers Hence, we have a fairly large window of resolution for TMRCA when using a modest number of completely linked markers.

34
Extensions I: Different Mutation Rates Let marker locus k have mutation rate u k. Code the observations as x k = 1 if a match, otherwise code x k = 0 - ( [ ] - - - The posterior becomes:

35
Stepwise Mutation Model (SMM) The Infinite alleles model (IAM) is not especially realistic with microsatellite data, unless the fraction of matches is very high. Under IAM, score as a match, and hence no mutations In reality, there are two mutations Microsatellite allelic variants are scored by their number of repeat units. Hence, two “matching” alleles can actually hide multiple mutations (and hence more time to the MRCA) Mutation 1 Mutation 2
 Mutation 1 Mutation 2.")
36
Y chromosome microsatellite mutation rates- II The SMM model is an attempt to correct for multiple hits by fully accounting for the mutational structure. Good fit to array sizes in natural populations when assuming the symmetric single-step model Equal probability of a one-step move up or down In direct studies of (Y chromosome) microsatellites 35 of 37 dectected mutations in pedigrees were single step, other 2 were two-step
 microsatellites 35 of 37 dectected mutations in pedigrees were single step, other 2 were two-step.")
37
SMM0 model -- match/no match under SMM The simplest implementation of the SMM model is to simply replace the match probabilities q(t) under the IAM model with those for the SMM model. This simply codes the marker loci as match / no match We refer to this as the SMMO model

38
Formally, the SMM model assumes the following transition probabilities - - - > Note that two alleles can match only if they have experienced an even number of mutations in total between them. In such cases, the match probabilities become ()
.")
39
() Number of mutations Prob(Match) 20.500 40.375 60.313 80.273 100.246 - - ( The zero-order modifed Type I Bessel Function Hence, -
 Number of mutations Prob(Match) ( The zero-order modifed Type I Bessel Function Hence, -")
41
Under the SMM model, the prior hyperparameter can now become important. This is the case when the number n of markers is small and/or k/n is not very close to one Why? Under the prior, TMRCA is forced by a geometric with 1/Ne. Under the IAM model for most values this is still much more time than the likelihood function predicts from the marker data Under the SMM model, the likelihood alone predicts a much longer value so that the forcing effect of the initial geometric can come into play

42
n =5, k = 3, u = 0.02 Time, t Pr(TMRCA < t) IAM, both flat prior and Ne = 5000 SSMO, N e = 5000 SSMO, flat prior Prior with N e =5000
 IAM, both flat prior and Ne = 5000 SSMO, N e = 5000 SSMO, flat prior Prior with N e =5000")
43
An Exact Treatment: SMME With a little work we can show that the probability two sites differ by j steps is just - > The resulting likelihood thus becomes … … Where n j is the number of sites that differ by k (observed) steps The jth-order modifed Type I Bessel Function
 steps The jth-order modifed Type I Bessel Function")
44
With this likelihood, the resulting posterior becomes … - This rearranges to give the general posterior under the Exact SMM model (SMME) as - - … Number of exact matchesNumber of k steps differences
 as - - … Number of exact matchesNumber of k steps differences")
45
Example Consider comparing haplotypes 1 and 3 from Thomas et al.’s (2000) study on the Lemba and Cohen Y chromosome modal haplotypes. Here six markers used, four exactly match, one differs by one repeat, the other by two repeats Hence, n = 6, k = 4 for IAM and SMM0 models n 0 = 4, n 1 = 1, n 2 = 1, n = 6 under SMME model Assume Hammer’s value of N e =5000 for the prior

46
IAM SMM0 SMME Time to MRCA, t P(t | markers) TMRCA for Lemba and Cohen Y Model usedMeanMedium2.5%97.5% IAM152.3135.431.1371 SMM0454.7233.740.42389 SMME422.3286.265.11631
 TMRCA for Lemba and Cohen Y Model usedMeanMedium2.5%97.5% IAM SMM SMME")
47
Time to MRCA, t Pr(TMRCA < t) IAM SMM0 SMME
 IAM SMM0 SMME")
49
Technology Transfer Family Tree DNA (ftDNA) -- provides Y chromosome marker kits for genealogical studies So far, ftDNA has processed over 80,000 such kits This amounts to a rough gross of around 8 million dollars. The expressions developed above have direct commercial applications

50
Forensic applications of the Y A not uncommon situation is the only DNA is from fingernail scrappings. The result is a mixture wherein the victim's DNA often overwhelms the DNA of the perpetrator. Result: only modest match probability as many autosomal markers cannot be detected One solution: use Y chromosome markers. Easily amplified over (female) background
 background.")
51
Problem: How do we combine Y match with autosomal match? NRC 1996 recommendations (autosomal loci) Prob(Y match)*Prob(autosomal match) Problem: Y markers may provide information about population substructure membership For example, a particular haplotype may be restricted to a certain subpopulation, e.g., Native Americans Product rule across markers Population substructure correction within markers
 Prob(Y match)*Prob(autosomal match) Problem: Y markers may provide information about population substructure membership For example, a particular haplotype may be restricted to a certain subpopulation, e.g., Native Americans Product rule across markers Population substructure correction within markers.")
52
Correcting for Y substructure Let y denote the observed Y haplotype A the multilocus autosomal marker genotype P(y,A) = P(A | y)*P(y) Simple approach: knowledge of y indicates membership in a particular subpopulation, P(A) computed using allele frequencies for that subpopulation. Suggestion: Multiply freq(y)* max Freq(A over subgroups)
* max Freq(A over subgroups).")
53
A more precise accounting Suppose two individuals share the same y haplotype. What is there average coancestry, ? Balding and Nichols give expressions for autosomal single-locus genotype frequencies given that the population shows structure with coancestry . Second approach: Compute from haplotype matching. Using this value in Balding - Nichols expressions to compute (single-locus) autosomal frequencies.
 autosomal frequencies..")
54
> Posterior Distribution for a match at all n markers with a prior of = 1/Ne > > With a MRCA of t generations, = (1/2) 2t+1
 2t+1")
55
Typical situation is where we can exclude father-son and paternal half-sibs, k > 2 > Typical values, n = 11, = 1/500 For = 1/5000, E [ ] = 0.00186 For = 1/500, E [ ] = 0.00194 For = 1/50, E [ ] = 0.00272 For these values, unless p i < 0.01, Balding-Nichols expression are essentially HW.
![Typical situation is where we can exclude father-son and paternal half-sibs, k > 2 > Typical values, n = 11, = 1/500 For = 1/5000, E [ ] = For = 1/500, E [ ] = For = 1/50, E [ ] = For these values, unless p i < 0.01, Balding-Nichols expression are essentially HW.](http://images.slideplayer.com/14/4369024/slides/slide_55.jpg "Typical situation is where we can exclude father-son and paternal half-sibs, k > 2 > Typical values, n = 11, = 1/500 For = 1/5000, E [ ] = For = 1/500, E [ ] = For = 1/50, E [ ] = For these values, unless p i < 0.01, Balding-Nichols expression are essentially HW.")
56
Formal procedure Estimate P(y) from a database (counting methods, Bayesian estimators) Compute mutlilocus autosomal frequencies by each major ethnic group using the product of the single-locus genotypes computed using group-specific allele frequencies and = 0.002 correction. Conservative P(y,A) = P(y)*max P(A)
 = P(y)*max P(A).")
Similar presentations




 is sufficient for >")


 Tests>")
 values must be estimated before.>")






 compromise predictions of selection response by changing allele frequencies and generating.>")




