Download presentation
Presentation is loading. Please wait.

1
eWika: Digitalization of Philippine Languages
Isalin Translate Good morning. I’m happy to be here today. I am representing our group from DLSU-Manila. I belong to a team of computer scientists developing a hybrid English-to-Filipino, bidirectional machine translation system. I would say that we are specialists in different types languages. You are specialists in natural languages, while ours is in artificial programming languages. Charibeth K. Cheng March 19, 2008

2
Machine Translation Automate translation
A study under Natural Language Processing MT System Sentence in SOURCE LANGUAGE TARGET LANGUAGE For discussion purposes, let me define what a machine translation system is. It is a computer program that aims to automate part or ultimately all of the processes of translating documents written in one natural language to another. This study on computational linguistics falls under the computer science area of natural language processing, which is under the area of artificial intelligence.

3
ENG-FIL MT System Project
3-year project started last year funded by DOST-PCASTRD composition: 6 faculty members of College of Computer Studies 15 computer science majors assisted by the Filipino Dept and Dept in English & Applied Linguistics of DLSU-M We are developing an English-Filipino, Filipino-English machine translation system. This is a 3-year project funded by the Department of Science and Technology’s Philippine Council on Advanced Science and Technology Research and Development or DOST-PCASTRD. We recently completed our first year. Our group is composed of 6 faculty members from the College of Computer Studies of De La Salle-Manila. We have about 10 research assistants consisting of undergraduate and graduate student whose thesis is related to this project. On the linguistic side aspect, we consult are colleagues from the Filipino Department and the Department of English and Applied Linguistics.

4
Agenda Architecture of the MT System Linguistic resources
Demo of the Translation Engine Results for English to Japanese translation My presentation today will focus on the following. I will briefly describe the architecture of the machine translation system. Followed by the challenges we are facing regarding the linguistic resources needed by the machine translator. Then I’ll show you the actual machine translation program we developed. Finally, the results we got when we applied this system to the Japanese Language. Switch to the program This is how our system looks like. We place here the sentences to be translated. It could translate from English to Filipino and vice-versa. When we click this button, it will perform the translation then show the results here. Let’s consider the sentence – “The cat is happy.”

5
Architectural Design of the Program
Source Text User Interface Target Text MT: Example-based Output Modeller MT: Rule-based Translator Engine This is the architectural design of the system. The input goes through the user interface which talks to the translator engine. The engine is supposed to use 2 approaches to translate, namely the example-based approach and rule-based approach. The rule-based translation engine uses a database of rules for language representation and translation created by linguists and other experts. On the other hand, the example-based translation engine automatically learns such information from sample text translations. Our program currently only uses the example-based approach, for reasons I will explain later. To be able to translate, the engine needs certain resources. First would be the lexicon or the English-Filipino bilingual electronic dictionary to translate the words in the sentence. It would need a morphological analyzer and generator to conjugate words when needed. It would also needed a Part-Of-Speech tagger to determine how a word is being used within the sentence. Next, it needs to know the grammar of the languages to understand and form valid sentences. Since the example-based engine learns from sample translations, it would need a corpus of correctly translated sentences. Language Resources: Lexicon (electronic dictionary), Morphological Analyzer & Generator Part-of-Speech tagger Grammar, Corpus (Tagged)
, Morphological Analyzer & Generator. Part-of-Speech tagger. Grammar, Corpus (Tagged)")
6
Challenge! Language resources
Quality of translation is dependent on it. Built from almost non-existent digital forms manual vs. automatic construction The accuracy of the translation of the system is largely dependent on the comprehensiveness and correctness of the language resources for Filipino and English-Filipino translation. Language resources such as the grammar, lexicon, morphological information, and the corpora are literally built from almost non-existent digital forms. Linguistics information on Philippine languages are available, but as of yet, the focus has been on theoretical linguistics and little is done about the computational aspects of these languages. We address the manual construction of these language resources, and also automatic extraction. We report here the building of these various language resources, the problems associated with these, and the solutions provided.

7
Lexicon Builder Used IsaWika! database as initial lexicon
Created a lexicon extraction program to automatically determine candidate translation pairs from corpora Currently contains about 23,000 entries Co-occurring words are likely translation Challenge: Lexical resources parallel corpora part-of-speech tagger The lexicon (or dictionary) is a collection of source words with the corresponding translation in the target language, and their features (such as part-of-speech tag, sample sentences, and semantic information). Since languages are in the process of evolution, it is imperative that the project provides some way to be able to determine and capture new words and probably new meanings of words in the languages considered in this study. New terms can be added into the base lexicon through a computer program that automatically extracts new dictionary entries from documents on English and Filipino. To be able to do it’s job, the lexicon extractor needs a parallel corpora of ENG-FIL translated documents and a part-of-speech tagger that will place the part-of-speech tags of each word. The lexicon extractor currently has an accuracy rate of about 57%. Database
 is a collection of source words with the corresponding translation in the target language, and their features (such as part-of-speech tag, sample sentences, and semantic information). Since languages are in the process of evolution, it is imperative that the project provides some way to be able to determine and capture new words and probably new meanings of words in the languages considered in this study. New terms can be added into the base lexicon through a computer program that automatically extracts new dictionary entries from documents on English and Filipino. To be able to do it’s job, the lexicon extractor needs a parallel corpora of ENG-FIL translated documents and a part-of-speech tagger that will place the part-of-speech tags of each word. The lexicon extractor currently has an accuracy rate of about 57%. Database.")
8
Morphological Analyzer
Initially collected morphological rules from grammar books Developed an example-based morphological phenomenon learner learn from <inflected word, root-word> example: <kumakain, kain> Challenge : Lexical resources lexicon part-of-speech tagger morphological rules Since the dictionary would not contain all the words in the English and Filipino language, there is a need to supplement the dictionary with a morphological analyzer that will determine the root word of a word not found in the dictionary; as well as a morphological generator to conjugate words when needed. With this subsystem, it is no longer no longer a requirement to have separate entries for the different forms of a word. We initially collected morphological rules from grammar books. Realizing that not all the rules are there for the Filipino language, we decided to develop a morphological phenomenon learner. Based on sample <inflected word, and root word> pairs, the learner will learn the morphological rules of a language. We currently have a morphological generator that can generate the different forms of a verb. Unfortunately, it still cannot determine the specific form of the word needed in a translation. Generator

9
Part-Of-Speech Tagger
automatic association of parts-of-speech to words in a document existing Filipino tagger achieves < 80% accuracy Challenge : Lexical resource tagged parallel corpora lexicon morphological analyzer grammar This subsystem is supposed to automatically aspociate the part-of-speech of a word, to determine how the word is being used in the sentence. The currently Filipino part-of-speech tagger achieve less than 80% accuracy. This is still unacceptable when used by the other lexical resources for the errors will propagate. The part-of-speech tagger needs a tagged parallel corpora, the lexicon, the MA and the grammar of the languages. At this point, I would like to point out that the lexical resources are completely dependent on each other. To build the part-of-speech tagger, we need an MA. The MA on the other hand needs the tagger. The part-of-speech tagger needs a comprehensive lexicon, to build a comprehensive lexicon, we need a good part-of-speech tagger. Thus our challenge becomes the chicken-and-egg problem. Where do we start?

10
The man bought an umbrella from the store.
Grammar Derived manually Challenge: Free word order in sentence formation. The man bought an umbrella from the store. Bumili ang lalaki ng payong sa tindahan. Bumili sa tindahan ng payong ang lalaki. Ang lalaki ay bumili ng payong sa tindahan. The Filipino grammar is manually being derived with the help of linguists. In the absence of a complete grammar, we are currently relying on the part-of-speech tagger. One of the major challenges of the Filipino language is its free word order in sentence formation. Due to its free word order nature, one sentence in English can be translated to various sentences in Filipino. For instance, the English sentence “The man bought an umbrella from the store” can be translated into many different Filipino sentences while maintaining the semantics of the original English sentence, some of which Bumili ang lalaki ng payong sa tindahan, Bumili sa tindahan ng payong ang lalaki. Ang lalaki ay bumili ng payong sa tindahan. Because of this free-word order phenomenon in Filipino sentences, there are problems in capturing the rules for the Filipino language to be able to represent all the possible combinations that the language provides. This means that the number of production rules for the Filipino grammar representation to a great extent is more than its English counterpart.

11
Corpora used by the lexicon extractor and part-of-speech tagger, example-based MT came from translation works of DLSU English majors, verified by linguists consists of 207,000 words, 5000 of which are tagged A corpora of English and Filipino documents is needed by the lexicon extractor, the part-of-speech tagger and the example-based machine translator. A mono-lingual Filipino corpus of about 4,000 words with specific and linguist-verified POS tags was gathered from various domains such as children’s books, the Bible, and news articles. The We currently have a bilingual parallel English-Filipino corpora consisting of 207,000 words from translation works of students and checked by their translation teachers, books and online articles; where only 5,000 words in the Filipino documents are tagged and verified by linguists. Unfortunately, our project encountered problems with the inconsistencies of tags associated with words in the two languages using our automatic tools, so verification has to be tediously done by the human evaluators. This particular problem has to be addressed and assessed in more detail. To address the need of building a reliable Filipino corpora and yet minimizing the need for manual encoding, automatic methods for corpora creation was explored. We developed AutoCor, which performs automatic acquisition and classification of corpora of documents in closely-related languages, specifically, three Philippine languages: Bicolano, Cebuano and Tagalog.

12
Translation Rules currently learned from the corpora disadvantages
garbage-in-garbage-out comprehensiveness need for linguistic-verified rules Cue to the absence of translation rules, our system currently automatically learns how translation is done through examples found in a corpus of translated documents. The system can incrementally learn when new translated documents are added into the knowledge-base, thus, any changes to the language can also be accommodated through the updates on the example translations. This means it can handle translation of documents from various domains. The principle of garbage-in-garbage-out applies here; if the example translations are faulty, the learned rules will also be faulty. That is why, although human linguists do not have to specify and come up with the translation rules, the linguist will have to first verify the translated documents and consequently, the learned rules, for accuracy. Unfortunately, the rules that were learned by our systems that we developed are still not readable and understandable to expert linguists and have to be translated into a form that would be comprehensible to them. It is not only the quality of the collection of translations that affects the overall performance of the system, but also the quantity. The collection of translations has to be comprehensive so that the translation system produced will be able to translate as much sentences as possible. The challenge here is coming up with the quantity of examples that is sufficient for accurate translation of documents. With more data, a new problem arises when the knowledge-base grows so large that access to it and search for applicable rules during translation requires tremendous amount of access time and to an extreme becomes difficult. Exponential growth of the knowledge-base may also happen due to the free word order nature of Filipino sentence construction, such that one English sentence can be translated to several Filipino sentences. When all these combinations are part of the translation examples, a translation rule will be learned and extracted by the system for each combination, thus, causing growth of the knowledge-base. Thus, algorithms that perform generalization of rules are considered to remove specificity of translation rules extracted and thus, reduce the size of the rule knowledge-base.

13
Let me now demonstrate to you how the REAL Translation system or Rule Extraction Applied in Language Translation system learns translation rules through example.

14
Bringing it home … 171 Philippine Languages (SIL)
No Philippine Corpora Unfortunately, today, the Philippines has one of the highest rates of dying languages (Solfed Foundation Inc) “Without our language, we have no culture, we have no identity, we are nothing.” (Thorrson) 171 Philippine Languages (SIL) No Philippine Corpora: NNLPRS, workshops Unfortunately, today, the Philippines has one of the highest rates of dying languages (Solfed Foundation Inc) In the 1800s, Ornolfor Thorsson, an adviser of the President of Iceland, said, “Without our language, we have no culture, we have no identity, we are nothing.” Ornolfor Thorsson said this when the Icelandic language was in danger of disappearing after years of Norwegian colonialism.
 Without our language, we have no culture, we have no identity, we are nothing. (Thorrson) 171 Philippine Languages (SIL) No Philippine Corpora: NNLPRS, workshops. Unfortunately, today, the Philippines has one of the highest rates of dying languages (Solfed Foundation Inc) In the 1800s, Ornolfor Thorsson, an adviser of the President of Iceland, said, Without our language, we have no culture, we have no identity, we are nothing. Ornolfor Thorsson said this when the Icelandic language was in danger of disappearing after years of Norwegian colonialism.")
15
eWika: Digitalization of Philippine Languages
Build the Philippine Corpus Build software tools to study or use the corpus Across Languages Across Regions Across Forms and Genres Across Land and Sea

16
Across Languages 171 Philippine Languages (SIL List)
Summer Institute of Linguistics Major languages Near extinction languages How about the languages in-between?

17
Filipino Sign Language
The History of Sign Language in the Philippines: Piecing Together the Puzzle (Abat & Martinez, 9th Phil Linguistics Congress, 2006) Deaf individuals: handicapped vs members of a linguistic minority Sign languages as true languages Throughout this entire century, the progressive global philosophy regarding deafness and deaf people have risen beyond a medical / infirmity model and moved towards a cultural /linguistic framework. Deaf individuals are no longer then simply viewed as hearing impaired or handicapped, but rather as Deaf, or, members of a cultural and linguistic minority. My first personal encounter with the group was during our first consultative workshop towards building the Philippine corpus. Despite the super typhoon that later hit Taiwan as well last August 2007, the workshop was well attended by at least 10 members of the Philippine Federation for the Deaf. They are enthusiastic, they are very active, driven community and they have a cause. Personally, I felt humbled by their presence, I felt that my world was so small, and when I met them, I felt that I should enlarge my coast (as the Bible puts it). This new linguistic framework is largely due to the emergence of sign linguistics as a discipline. The documentation and consequent acceptance of sign languages as true languages have been key to the recognition of Deaf communities. Deaf individuals of various nations throughout the world, including the Philippines, now draw from the strength of this collective identity for advocacies in various aspects of their lives. The history of manual communication in general in the Philippines, and the emergence and development of Filipino Sign Language (FSL) as the linguistic entity and sociocultural symbol of the Filipino Deaf community is a matter of great importance to Deaf individuals as well as the community at large.
 Deaf individuals: handicapped vs members of a linguistic minority. Sign languages as true languages. Throughout this entire century, the progressive global philosophy regarding deafness and deaf people have risen beyond a medical / infirmity model and moved towards a cultural /linguistic framework. Deaf individuals are no longer then simply viewed as hearing impaired or handicapped, but rather as Deaf, or, members of a cultural and linguistic minority. My first personal encounter with the group was during our first consultative workshop towards building the Philippine corpus. Despite the super typhoon that later hit Taiwan as well last August 2007, the workshop was well attended by at least 10 members of the Philippine Federation for the Deaf. They are enthusiastic, they are very active, driven community and they have a cause. Personally, I felt humbled by their presence, I felt that my world was so small, and when I met them, I felt that I should enlarge my coast (as the Bible puts it). This new linguistic framework is largely due to the emergence of sign linguistics as a discipline. The documentation and consequent acceptance of sign languages as true languages have been key to the recognition of Deaf communities. Deaf individuals of various nations throughout the world, including the Philippines, now draw from the strength of this collective identity for advocacies in various aspects of their lives. The history of manual communication in general in the Philippines, and the emergence and development of Filipino Sign Language (FSL) as the linguistic entity and sociocultural symbol of the Filipino Deaf community is a matter of great importance to Deaf individuals as well as the community at large.")
18
Across Boundaries Across Regions Across Languages
Across Forms and Genres Across Land and Sea

19
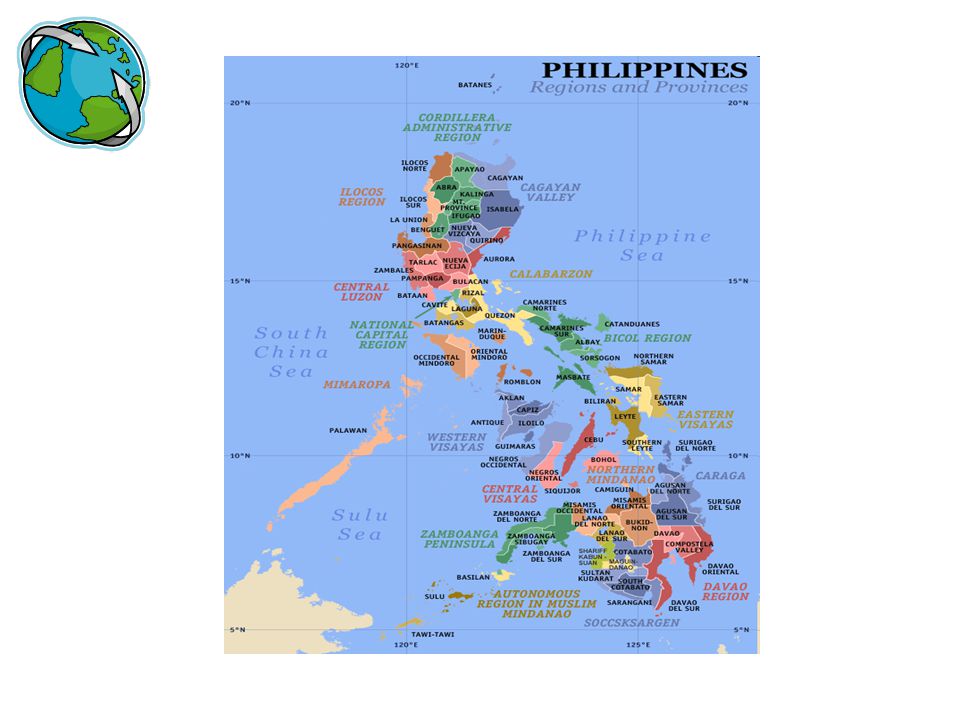
Across Regions e-Wika: Connecting the Philippine Islands through Language 17 Regions: The regions are: Ilocos Region (Region I), Cagayan Valley (Region II), Central Luzon (Region III), CALABARZON (Region IV-A) , MIMAROPA (Region IV-B) , Bicol Region (Region V), Western Visayas (Region VI), Central Visayas (Region VII), Eastern Visayas (Region VIII), Zamboanga Peninsula (Region IX), Northern Mindanao (Region X), Davao Region (Region XI), SOCCSKSARGEN (Region XII), Caraga (Region XIII), Autonomous Region in Muslim Mindanao (ARMM), Cordillera Administrative Region (CAR), National Capital Region (NCR) (Metro Manila)
, Cagayan Valley (Region II), Central Luzon (Region III), CALABARZON (Region IV-A) , MIMAROPA (Region IV-B) , Bicol Region (Region V), Western Visayas (Region VI), Central Visayas (Region VII), Eastern Visayas (Region VIII), Zamboanga Peninsula (Region IX), Northern Mindanao (Region X), Davao Region (Region XI), SOCCSKSARGEN (Region XII), Caraga (Region XIII), Autonomous Region in Muslim Mindanao (ARMM), Cordillera Administrative Region (CAR), National Capital Region (NCR) (Metro Manila)")
21
Across Boundaries Across Forms and Genres
Across Time: historical, contemporary Across Languages Across Regions Across Forms and Genres Across Land and Sea

22
Across Forms and Genres
In various forms: Text Speech: speech to text system (ongoing project) Video: Filipino sign language In various Genres: categories of entries in the corpus
 Video: Filipino sign language. In various Genres: categories of entries in the corpus.")
23
Across Boundaries Across Land and Sea
Across Time: historical, contemporary Across Languages Across Regions Across Forms and Genres Across Land and Sea

24
Across Land and Sea Web-based application: c/o Solomon See (upload, download, tools) Contributors (Main players) Verify-ers Facilitators Server: DLSU-M commits to host the server for the next three years. Terms of Use: Research purposes.

25
The dream of building Philippine language resources and tools
Many many many major hurdles to overcome Language Resources, Tools, & Peopleware: Needed 25

Similar presentations

 & Text Corpora.>")







>")
 – Corpora – Treebanks Secondary resources – Designed for a.>")








