Download presentation
Presentation is loading. Please wait.

1
Tier1A Status Andrew Sansum GRIDPP 8 23 September 2003

2
Contents GRID Stuff – clusters and interfaces Hardware and utilisation Software and utilities

3
Layout

4
EDG Status 1 (Steve Traylen) EDG 2.0.x deployed on production testbed since early September. Provides: –EDG RGMA info catalogue: http://gppic06.gridpp.rl.ac.uk:8080/R-GMA/ –RLS for lhcb, biom, eo, wpsix, tutor and babar EDG 2.1 deployed on dev testbed. VOMS integration work underway. May be found useful by small GRIDPP experiments (eg NA48, MICE and MINOS)
.")
5
EDG Status (2) EDG 1.4 gatekeeper continues to provide gateway into main CSF production farm. Provides access for small amount of Babar and ATLAS work. Being prepared for forthcoming D0 production via SAMGrid Along with IN2P3, CSFUI provides main UI for EDG Many WP3 and WP5 mini testbeds Further GRID integration into production farm via LCG – not EDG

6
LCG Integration (M. Bly) LCG 0 mini testbed deployed in July LCG 0 upgraded to LCG 1 in September. Consists of: –Lcgwst regional GIIS –RB –CE, SE, UI, BDII, PROXY –Five worker nodes Soon need to make important decisions about how much hardware to deploy into LCG – whatever experiments/EB want.

7
LCG Experience Mainly known issues: –Installation and configuration still difficult for non experts. –Documentation still thin in many places. –Support often very helpful but answers not always forthcoming for some problems. –Not everything works – all of the time. Beginning to discuss internally how to interoperate with production farm.

8
SRB Service For CMS Considerable learning experience for Datastore team (and CMS)! SRB MCAT for whole CMS production. Consists of enterprise class ORACLE servers and thin” MCAT ORACLE client. SRB interface into Datastore SRB enabled disk server to handle data imports. SRB clients on disk servers for data moving

9
New Hardware (March) 80 Dual Processor P4 2.66GHz Xeon 11 disk servers: 40TB IDE disk –11 dual P4 servers (with PCIx), each with 2 Infortrend IFT-6300 arrays –12 Maxtor 200GB Diamondmax Plus 9 drives per array. Major Datastore upgrade over summer

10
P4 Operation Problematic Disappointing performance with gcc –Hope for 2.66P4/1.4P3=1.5 – see 1.2 - 1.3 Can obtain more by exploiting hyper- threading but Linux CPU scheduling causes difficulties (ping pong effects) CPU accounting now depends on number of jobs running. Beginning to look closely at Opteron solutions.

11
Datastore Upgrade STK 9310 robot, 6000 slots –IBM 3590 drives being phased out (10GB 10MB/Sec) –STK 9940B drives in production (200GB 30MB/sec) 4 IBM 610+ servers with two FC connections and Gbit networking on PCI-X –9940 drives FC connected via 2 switches for redundancy –SCSI raid 5 disk with hot spare for 1.2Tbytes cache space
 –STK 9940B drives in production (200GB 30MB/sec) 4 IBM 610+ servers with two FC connections and Gbit networking on PCI-X –9940 drives FC connected via 2 switches for redundancy –SCSI raid 5 disk with hot spare for 1.2Tbytes cache space")
12
Switch_1Switch_2 RS6000 fsc0fsc1 fsc0 9940B 12345678 1114111415 fsc1fsc0fsc1fsc0 1213121315 rmt1 rmt4rmt3rmt2 rmt5-8 AAAAAAAA STK 9310 “Powder Horn” Gbit network 1.2TB

13
Operating Systems Redhat 6.2 finally closed in August Redhat 7.2 remains in production for Babar. Will migrate all batch workers to Redhat 7.3 shortly. Redhat 7.3 service now main workhorse for LHC experiments. Need to start looking at Redhat 9/10 Need to deploy Redhat Advanced Server

16
Next Procurement Based on experiments expected demand profile (as best they can estimate). Exact numbers still being finalised, but about: –250 dual processor CPU nodes –70TB available disk –100TB tape

17
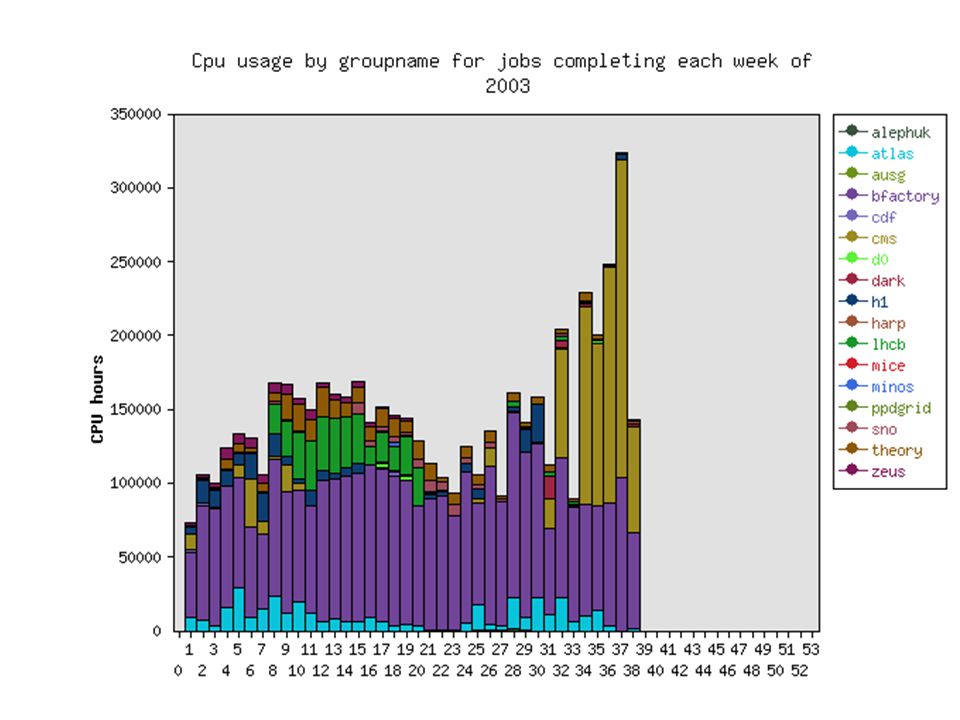
CPU Requirements (KSI2K)
")
19
New Helpdesk Need to deploy new helpdesk (had Remedy). Wanted: –Web based. –Free open source. –Multiple queues and personalities. Looked at Bugzilla, OTRS and Requestracker. Finally selected request tracker. http://helpdesk.gridpp.rl.ac.uk/.http://helpdesk.gridpp.rl.ac.uk/ Available for other Tier 2 sites and other GRIDPP projects if needed.

21
YUMIT: RPM Monitoring Many nodes on the farm. Need to make sure RPMs are up to date. Wanted light-weight solution until full fabric management tools are deployed. Package written by Steve Traylen: –Yum installed on hosts –Nightly comparison with YUM database uploaded to MYSQL server. –Simple web based display utility in perl

24
Exception Monitoring: Nagios Already have an exception handling system (CERN’s SURE coupled with the commercial Automate). Looking at alternatives – no firm plans yet but currently looking at NAGIOS: http://www.nagios.org/

26
Summary: Outstanding Issues Many new developments and new services deployed this year. We have to run many distinct services. For example, FERMI Linux, RH 6.2/7.2/7.3, EDG testbeds, LCG, CMS DC03, SRB etc. Waiting to hear when the experiments want LCG in volume. The Pentium 4 processor is performing poorly. Redhat’s changing policy is a major concern

Similar presentations






















 just started Short-term.>")


