Download presentation
Presentation is loading. Please wait.

1
Automated Exploration of Bioinformatics Spaces Simon Colton Computational Bioinformatics Laboratory

2
Purpose of the Talk To make you aware of another tool which may have some potential for use in the Metalog project To get feedback on this potential To briefly describe two other projects

3
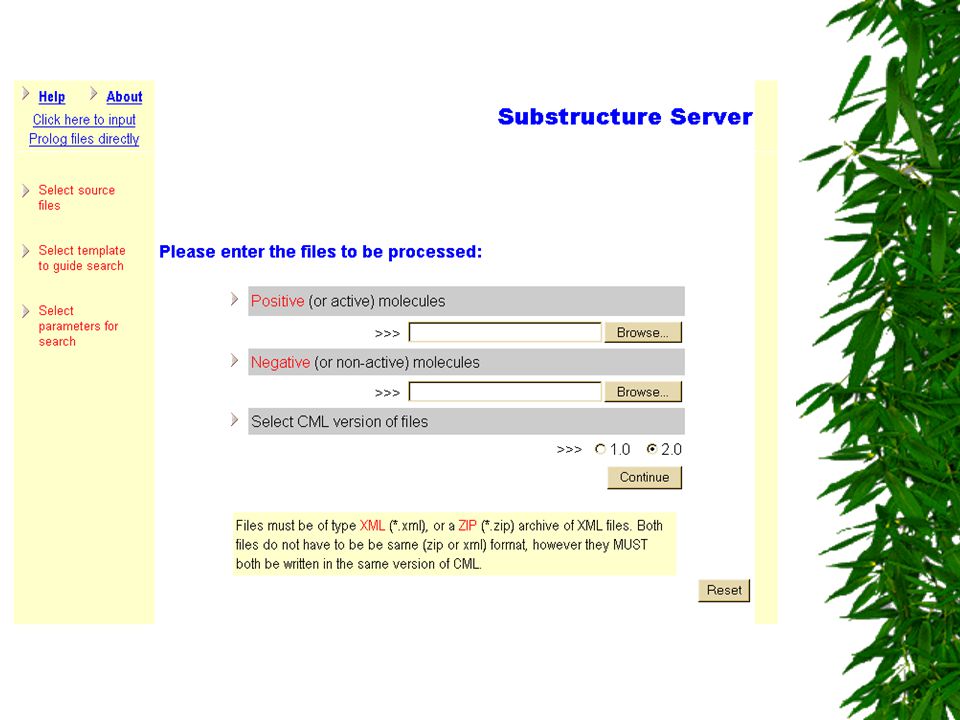
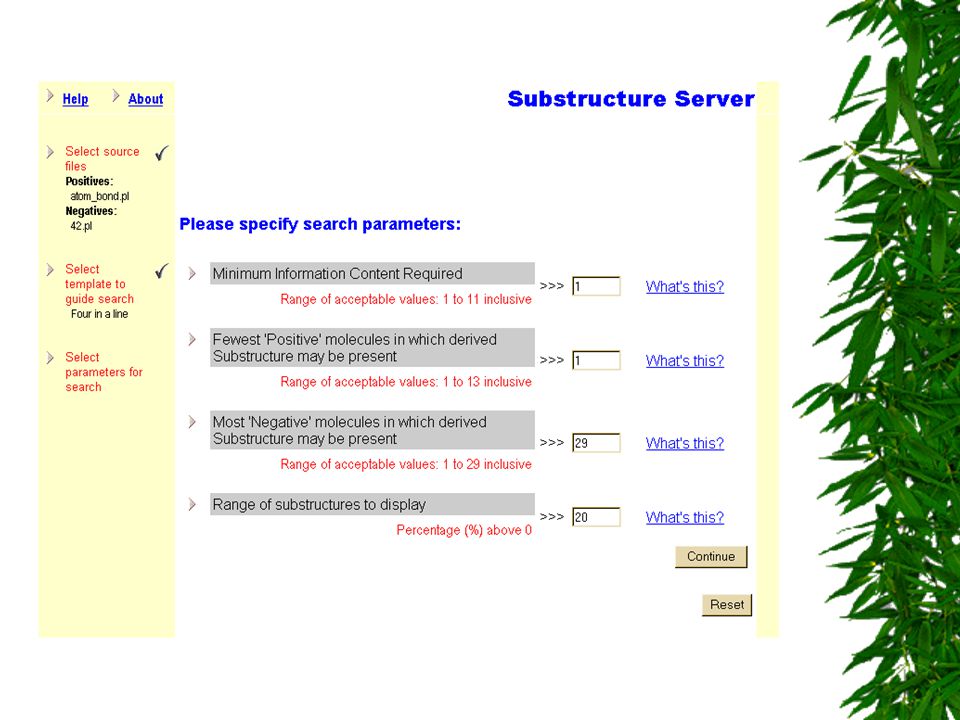
The Substructure Server Old-style approach to using machine learning (ML) for predictive toxicology –What do the positives have in common that the negatives do not? –For chemicals, possibly using ILP is like using a sledgehammer to crack a nut Substructures are often the answer (e.g., mutagenesis) –Substructure server looks explicitly for substructures Vehicle for me to understand ML in predictive toxicology and server-client technology –May even be of some use one day
 –Substructure server looks explicitly for substructures Vehicle for me to understand ML in predictive toxicology and server-client technology –May even be of some use one day.")
8
Substructure Server Development Team –Simon Colton Prolog machine learning routine (FIND-S) –Saravanan Anandathiyagar Server technology –Laurence Darby Distributing the process over our linux farm –Gives roughly 5 times speed up –A.N.Other masters student (TBA) Front end (Babel) Back end (Molgen, etc.)
 –Saravanan Anandathiyagar Server technology –Laurence Darby Distributing the process over our linux farm –Gives roughly 5 times speed up –A.N.Other masters student (TBA) Front end (Babel) Back end (Molgen, etc.)")
9
Old-Style Predictive Toxicology Reason 1: –Using only chemistry, attributes etc. Not using biochemical pathways Reason 2: –Using predictive machine learning Not using descriptive machine learning

10
Predictive Induction in Bioinformatics Interesting problem found –Interesting from a biochemistry perspective –Interesting from a computer science perspective Packaged as prediction/classification –Turned into positives and negatives –Much work done to shoe-horn into a prediction task Reason(s) learned why positives are positive –Almost guaranteed that any answer found will be interesting, because the problem is interesting
 learned why positives are positive –Almost guaranteed that any answer found will be interesting, because the problem is interesting")
11
Generating Hypotheses Predictive machine learning produces hypotheses of the form: –A Toxic –Toxic C –B Toxic –D ¬Toxic –etc. With any luck, A, B or C will be interesting in their own right –And enter the biochemistry literature!

12
But what if… There was an interesting relationship –Between a concept and a subset of the positives. Isn’t this interesting? Examples: A Toxic & B C ¬Toxic & D & E

13
Predictive versus Descriptive Learning Predictive learning –You know what you are looking for –You just don’t know what it looks like Descriptive learning –You don’t know what you are looking for –But you want to find something interesting Eventually: –You don’t even know you are looking for something

14
Descriptive Induction Not as goal directed as predictive induction Same background information given –Perhaps no categorisation into pos & neg A theory is produced which contains: –Examples –Concepts which categorise/describe sets of examples –Hypotheses which relate concepts –Explanations which explain the hypotheses For instance: –Acid + Base Salt + Water Tools are supplied so that –The user can extract interesting parts of the theory

15
The HR System in 3 Slides Concept formation –Starts with background info like Progol –Builds new concepts from old ones Using one of 15 production rules (composition, instantiation, counting, matching, etc.) Unary or binary Many settings for how concept formation occurs –Derives examples & definition of concepts Heuristic search (if user specifies) –Uses a best first search 20+ measures of interestingness for concepts/conjectures Chooses to build new concepts from best old ones
 Unary or binary Many settings for how concept formation occurs –Derives examples & definition of concepts Heuristic search (if user specifies) –Uses a best first search 20+ measures of interestingness for concepts/conjectures Chooses to build new concepts from best old ones")
16
The HR System in 3 Slides Conjecture Making –“Proper” induction! –Notices patterns in examples for concepts Newly formed concept has no examples –Makes a non-existence conjecture Two concepts have exactly the same examples –Makes an equivalence conjecture One concept’s examples are subset of another –Makes an implication conjecture –Extracts simpler hypotheses from empirical ones –Able to make “near-conjectures” Patterns don’t have to be exact User specifies a tolerance level

17
The HR System in 3 Slides Generating explanations –User supplies a set of axioms –HR appeals to a third party theorem prover And a third party model generator (otter/mace) –To attempt to prove/disprove That the hypothesis follows from the axioms Sometimes, explanations are interesting –In domains such as group theory Explanations are proofs of theorems Sometimes, explanations show that a hypothesis is dull –Anything provable by the theorem prover is trivial
 –To attempt to prove/disprove That the hypothesis follows from the axioms Sometimes, explanations are interesting –In domains such as group theory Explanations are proofs of theorems Sometimes, explanations show that a hypothesis is dull –Anything provable by the theorem prover is trivial")
18
Extreme(!) Theory Formation All my best examples are from maths Given only one concept: –How to divide two integers HR finds the conjecture –Odd refactorable numbers are squares Invented concepts: –Odd, square, refactorable, (even, tau, …) Made concept of odd refactorables –Noticed the examples are a subset of the examples for square numbers No proof supplied (I proved this one)
 Theory Formation All my best examples are from maths Given only one concept: –How to divide two integers HR finds the conjecture –Odd refactorable numbers are squares Invented concepts: –Odd, square, refactorable, (even, tau, …) Made concept of odd refactorables –Noticed the examples are a subset of the examples for square numbers No proof supplied (I proved this one)")
19
What HR Can Deliver HR generates hypotheses like Progol –But there are too many –Require filters to prune dull ones Some concepts might be interesting aside from their relation to toxicity HR points out interesting examples –E.g., a molecule has the only occurrence of a particular sub-molecule

20
Interesting New Angle Anomaly detection First experiments in analysis of Bach chorale melodies –Which ones were different to the rest Not necessarily breaking rules Could be: something occurring more often –“Parsimony outlier” measure of interestingness Hope to try this with metabolic pathways –Give me 30 pathways I’ll give you reasons why each is unique –Give me an invented pathway I’ll show you possible reasons it’s wrong…

21
What I need Objects of interest –Pathways Background concepts –Ways to describe the pathways Axioms –What we know is true about pathways Measures of interestingness –Essential to separate the wheat from chaff –Evolve over time as we use HR together

22
Future for my Work Form theories about biochemical data Domain of interest –Pathways Technical problems –Enabling HR to work with probabilistic information (not yet possible) –Enabling HR to work with larger datasets –Understanding pathways!
 –Enabling HR to work with larger datasets –Understanding pathways!")
23
The Amaze Database Bioinformatics MSc. Project –Organised by Marek Sergot Challenge –To resurrect the Amaze database Of biochemical pathways –EBI originally, now Université libre de Bruxelles –To get hold of data, put into a database, put a front- end onto this, etc. –And write translation routines So that we can get at the information This is a resource we should use –Please let me know your requirements

Similar presentations









 Weiss, Sec. 7.2, page 233 (b) Course slides for lecture and notes recitation. Every criticism from a.>")











