Download presentation
Presentation is loading. Please wait.

1
Somdas Bandyopadhyay 09305032 Anirban Basumallik 09305008

2
What are Peer to Peer System Examples of Peer to Peer System What are Distributed Hash Table? DHT Example - CHORD DHT Example - CAN An application of DHT - PIER

3
Distributed and Decentralized Architecture Peers make a portion of their resources directly available to other network participants, without the need for central coordination by servers Peers are equally privileged, equipotent participants in the application. Peers are both suppliers and consumers, in contrast to the traditional client–server model

4
All in the application layer

5
P 2 P file sharing system Central Server stores the index of all the files available on the network To retrieve a file, central server contacted to obtain location of desired file Central server not scalable Single point of failure

6
On start-up, client contacts a few other nodes; these become its neighbors Search: ask neighbors, who ask their neighbors, and so on... when/if found, reply to sender. TTL limits propagation No Single point of failure Search might to succeed even if file was present in the network.

7
First each client connects to a hub Each hub maintains the list of users To search for a file the client sends the following command to the hub - $Search :. is the IP address of the client and is a UDP port on which the client is listening for responses The hub must forward this message unmodified to all the other users. Every other user with one or more matching files must send a UDP packet to : Matching files are found using some kind of hashing.

8
Each client contacts a web server with a file name. The Web server returns a torrent file that contains info like length of the file, size and the URL of the tracker. The client then talks with the tracker, which returns the list of peers that are currently downloading/uploading the file Each peer divides the files in pieces. The client then downloads pieces from its peers. Simultaneously, it also uploads the pieces that it has already downloaded.

9
In any P 2 P system, File transfer process is inherently scalable However, the indexing scheme which maps file names to location crucial for scalability Solution:- Distributed Hash Table

10
Traditional name and location services provide a direct mapping between keys and values What are examples of values? A value can be an address, a document, or an arbitrary data item Distributed hash tables such as CAN/Chord implement a distributed service for storing and retrieving key/value pairs

11
DNS Provides a host name to IP address mapping Relies on a set of special root servers Names reflect administrative boundaries Is specialized to finding named hosts or services DHT Can provide same service: Name = key, value = IP Requires no special servers. Distributed Service Imposes no naming structure. Flat naming Can also be used to find data objects that are not tied to certain machines

12
CHORD

13
CHORD is a distributed hash table implementation Addresses a fundamental problem in P 2 P Efficient location of the node that stores desired data item One operation: Given a key, maps it onto a node Data location by associating a key with each data item Adapts Efficiently Dynamic with frequent node arrivals and departures Automatically adjusts internal tables to ensure availability Uses Consistent Hashing Load balancing in assigning keys to nodes Little movement of keys when nodes join and leave

14
Efficient Routing Distributed routing table Maintains information about only O(logN) nodes Resolves lookups via O(logN) messages Scalable Communication cost and state maintained at each node scales logarithmically with number of nodes Flexible Naming Flat key-space gives applications flexibility to map their own names to Chord keys
 nodes Resolves lookups via O(logN) messages Scalable Communication cost and state maintained at each node scales logarithmically with number of nodes Flexible Naming Flat key-space gives applications flexibility to map their own names to Chord keys")
15
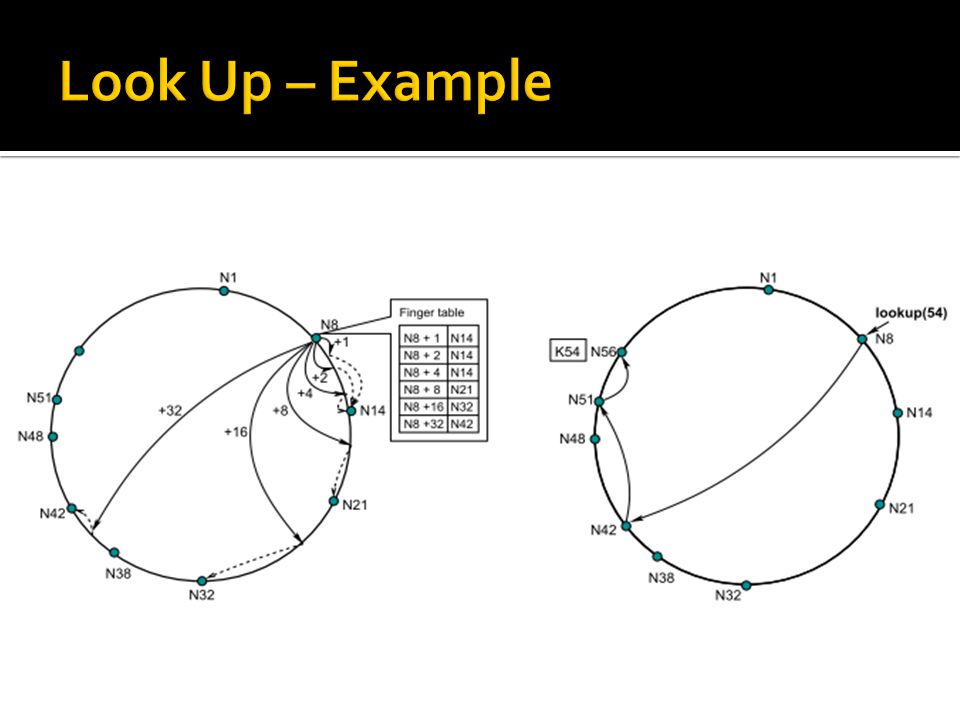
Each node and key is assigned a m-bit Identifier using SHA-1 as a hash function. A node’s identifier is chosen by hashing the node’s IP address, while a key’s identifier is chosen by hashing the key. Identifiers are ordered on an identifier circle modulo 2 m. Key K is assigned to the first node whose identifier is equal to or follows the identifier of K in the identifier circle. This node is called the successor of key K.

16
CHORD RING

17
1) Each node only knows about its successor 2) Minimum state required 3) Maximum path length
 Each node only knows about its successor 2) Minimum state required 3) Maximum path length")
18
Lookups are accelerated by maintaining additional routing information Each node maintains a routing table with (at most) m entries (where N=2 m ) called the finger table i th entry in the table at node n contains the identity of the first node, s, that succeeds n by at least 2 i-1 on the identifier circle (clarification on next slide) s = successor(n + 2 i-1 ) (all arithmetic mod 2) s is called the i th finger of node n, denoted by n.finger(i).node
 m entries (where N=2 m ) called the finger table i th entry in the table at node n contains the identity of the first node, s, that succeeds n by at least 2 i-1 on the identifier circle (clarification on next slide) s = successor(n + 2 i-1 ) (all arithmetic mod 2) s is called the i th finger of node n, denoted by n.finger(i).node")
20
Each node stores information about only a small number of other nodes, and knows more about nodes closely following it than about nodes farther away A node’s finger table generally does not contain enough information to determine the successor of an arbitrary key k Repetitive queries to nodes that immediately precede the given key will lead to the key’s successor eventually

23
0 4 26 5 1 3 7 124124 130130 finger table startsucc. keys 1 235235 3 0 finger table startsucc. keys 2 457457 0 finger table startsucc. keys finger table startsucc. keys 702702 003003 6 6 6 6 6

24
Basic “stabilization” protocol is used to keep nodes’ successor pointers up to date, which is sufficient to guarantee correctness of lookups Those successor pointers can then be used to verify the finger table entries Every node runs stabilize periodically to find newly joined nodes

27
npnp succ(n p ) = n s nsns n pred(n s ) = n p n joins predecessor = nil n acquires n s as successor via some n’ n notifies n s being the new predecessor n s acquires n as its predecessor n p runs stabilize n p asks n s for its predecessor (now n) n p acquires n as its successor n p notifies n n will acquire n p as its predecessor all predecessor and successor pointers are now correct fingers still need to be fixed, but old fingers will still work nil pred(n s ) = n succ(n p ) = n
 = n s nsns n pred(n s ) = n p n joins predecessor = nil n acquires n s as successor via some n’ n notifies n s being the new predecessor n s acquires n as its predecessor n p runs stabilize n p asks n s for its predecessor (now n) n p acquires n as its successor n p notifies n n will acquire n p as its predecessor all predecessor and successor pointers are now correct fingers still need to be fixed, but old fingers will still work nil pred(n s ) = n succ(n p ) = n")
28
For a lookup before stabilization has finished 1. Case 1: All finger table entries involved in the lookup are reasonably current then lookup finds correct successor in O(logN) steps 1. Case 2: Successor pointers are correct, but finger pointers are inaccurate. This scenario yields correct lookups but may be slower 1. Case 3: Incorrect successor pointers or keys not migrated yet to newly joined nodes. Lookup may fail. Option of retrying after a quick pause, during which stabilization fixes successor pointers
 steps 1. Case 2: Successor pointers are correct, but finger pointers are inaccurate. This scenario yields correct lookups but may be slower 1. Case 3: Incorrect successor pointers or keys not migrated yet to newly joined nodes. Lookup may fail. Option of retrying after a quick pause, during which stabilization fixes successor pointers.")
29
After stabilization, no effect other than increasing the value of N in O(logN) Before stabilization is complete Possibly incorrect finger table entries Does not significantly affect lookup speed, since distance halving property depends only on ID-space distance If new nodes’ IDs are between the target predecessor and the target, then lookup speed is influenced
 Before stabilization is complete Possibly incorrect finger table entries Does not significantly affect lookup speed, since distance halving property depends only on ID-space distance If new nodes’ IDs are between the target predecessor and the target, then lookup speed is influenced")
30
0 4 26 5 1 3 7 124124 130130 finger table startsucc. keys 1 235235 330330 finger table startsucc. keys 2 457457 660660 finger table startsucc. keys finger table startsucc. keys 702702 003003 6 6 6 0 3

31
Problem: what if node does not know who its new successor is, after failure of old successor May be in a gap in the finger table Chord would be stuck! Maintain successor list of size r, containing the node’s first r successors If immediate successor does not respond, substitute the next entry in the successor list Modified version of stabilize protocol to maintain the successor list

32
Modified closest_preceding_node to search not only finger table but also successor list for most immediate predecessor Voluntary Node Departures Transfer keys to successor before departure Notify predecessor p and successor s before leaving

33
Implements Iterative Style (other one is recursive style) Node resolving a lookup initiates all communication unlike Recursive Style, where intermediate nodes forward request Optimizations During stabilization, a node updates its immediate successor and 1 other entry in successor list or finger table Each entry out of k unique entries gets refreshed once in ’k’ stabilization rounds When predecessor changes, immediate notification to old predecessor is sent to update its successor, without waiting for next stabilization round
 Node resolving a lookup initiates all communication unlike Recursive Style, where intermediate nodes forward request Optimizations During stabilization, a node updates its immediate successor and 1 other entry in successor list or finger table Each entry out of k unique entries gets refreshed once in ’k’ stabilization rounds When predecessor changes, immediate notification to old predecessor is sent to update its successor, without waiting for next stabilization round")
34
Test ability of consistent hashing, to allocate keys to nodes evenly Number of keys per node exhibits large variations, that increase linearly with the number of keys Association of keys with Virtual Nodes Makes the number of keys per node more uniform and Significantly improves load balance Asymptotic value of query path length not affected much Not much increase in routing state maintained

35
In the absence of Virtual Nodes The mean and 1st and 99th percentiles of the number of keys stored per node in a 10,000 node network.

36
In the presence of Virtual Nodes The 1st and the 99th percentiles of the number of keys per node as a function of virtual nodes mapped to a real node. The network has 10 4 realnodes and stores 10 6 keys.

37
Number of nodes that must be visited to resolve a query, measured as the query path length The number of nodes that must be contacted to find a successor in an N-node Network is O(log N) Mean query path length increases logarithmically with number of nodes A network with N = 2 K nodes No of Keys 100 x 2 K K varied between 3 to 16 and Path length is measured
 Mean query path length increases logarithmically with number of nodes A network with N = 2 K nodes No of Keys 100 x 2 K K varied between 3 to 16 and Path length is measured")
39
No. of Nodes – 1000 Size of Successor list is 20. The 1st and the 99th percentiles are in parentheses The mean path length does not increase too much.

40
CAN

41
CAN is a distributed infrastructure that provides hash table like functionality CAN is composed of many individual nodes Each CAN node stores a chunk (zone) of the entire hash table Request for a particular key is routed by intermediate CAN nodes whose zone contains that key
 of the entire hash table Request for a particular key is routed by intermediate CAN nodes whose zone contains that key")
43
Involves a virtual d-dimensional Cartesian Co-ordinate space The co-ordinate space is completely logical Lookup keys hashed into this space The co-ordinate space is partitioned into zones among all nodes in the system Every node in the system owns a distinct zone

44
To store (Key,value) pairs, keys are mapped deterministically onto a point P in co-ordinate space using a hash function The (Key,value) pair is then stored at the node which owns the zone containing P To retrieve an entry corresponding to Key K, the same hash function is applied to map K to the point P The retrieval request is routed from requestor node to node owning zone containing P
 pairs, keys are mapped deterministically onto a point P in co-ordinate space using a hash function The (Key,value) pair is then stored at the node which owns the zone containing P To retrieve an entry corresponding to Key K, the same hash function is applied to map K to the point P The retrieval request is routed from requestor node to node owning zone containing P")
46
Every CAN node holds IP address and virtual co-ordinates of each of it’s neighbours Every message to be routed holds the destination co-ordinates Using it’s neighbour’s co-ordinate set, a node routes a message towards the neighbour with co-ordinates closest to the destination co- ordinates

47
For a d-dimensional space partitioned into n equal zones, routing path length = O(d.n 1/d ) hops With increase in no. of nodes, routing path length grows as O(n 1/d ) Every node has 2d neighbours With increase in no. of nodes, per node state does not change
 Every node has 2d neighbours With increase in no. of nodes, per node state does not change.")
48
PIER

49
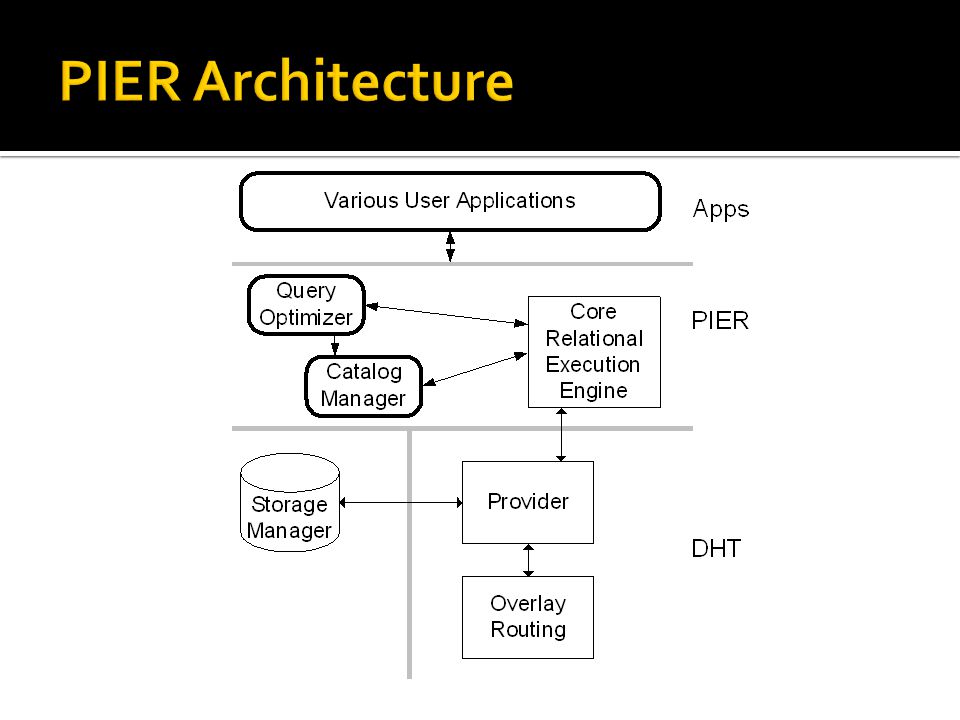
Peer-to-Peer Information Exchange and Retrieval It is a query engine that scales up to thousands of participating nodes and can work on various data It runs on top of P 2 P network step up to distributed query processing at a larger scale way for massive distribution: querying heterogeneous data Architecture meets traditional database query processing with recent peer-to-peer technologies

51
lookup(key) ipaddr join(landmarkNode) leave() locationMapChange() store(key, item) retrieve(key) item remove(key) Routing Layer API Storage Manager API
 ipaddr join(landmarkNode) leave() locationMapChange() store(key, item) retrieve(key) item remove(key) Routing Layer API Storage Manager API")
52
Provider get (namespace, resourceID) item put (namespace, resourceID, instanceID, item, lifetime) renew (namespace, resourceID, instanceID, lifetime) bool multicast(namespace, resourceID, item) lscan(namespace) items CALLBACK: newData(namespace, item) Each object in the DHT has a namespace, resourceID and instanceID DHT key = hash(namespace,resourceID) namespace - application or group of object, table resourceID – what is object, primary key or any attribute instanceID – integer, to separate items with the same namespace and resourceID
 item put (namespace, resourceID, instanceID, item, lifetime) renew (namespace, resourceID, instanceID, lifetime) bool multicast(namespace, resourceID, item) lscan(namespace) items CALLBACK: newData(namespace, item) Each object in the DHT has a namespace, resourceID and instanceID DHT key = hash(namespace,resourceID) namespace - application or group of object, table resourceID – what is object, primary key or any attribute instanceID – integer, to separate items with the same namespace and resourceID")
53
Let N R and N S be two namespaces storing tuples of relations R and S respectively. N R and N S performs lscan() to locate all tuples of R and S. All tuples that satisfy the where clause conditions are put in a new namespace N Q The value for the join attribute is made the resouceID Tuples are tagged with source table names
 to locate all tuples of R and S. All tuples that satisfy the where clause conditions are put in a new namespace N Q The value for the join attribute is made the resouceID Tuples are tagged with source table names.")
54
Each node registers with DHT to receive a newData callback When a tuple arrives, a get is issued to N Q (this stays local.) Matches are concatenated to the probe tuple and the output tuples are generated (which are sent to the next stage in the query or another DHT namespace.) Contd…
 Matches are concatenated to the probe tuple and the output tuples are generated (which are sent to the next stage in the query or another DHT namespace.) Contd…")
55
Questions

Similar presentations










? Napster? Gnutella? Most people think of P2P as music sharing.>")
 Distributed Storage 1Dennis Kafura – CS5204 – Operating Systems.>")


>")












