Download presentation
Presentation is loading. Please wait.

1
AdaBoost

2
Classifier Simplest classifier

4
Adaboost: Agenda (Adaptive Boosting, R. Scharpire, Y. Freund, ICML, 1996): Supervised classifier Assembling classifiers Combine many low-accuracy classifiers (weak learners) to create a high-accuracy classifier (strong learners)
 to create a high-accuracy classifier (strong learners)")
5
Example 1

6
Adaboost: Example (1/10)
")
7
Adaboost: Example (2/10)
")
8
Adaboost: Example (3/10)
")
9
Adaboost: Example (4/10)
")
10
Adaboost: Example (5/10)
")
11
Adaboost: Example (6/10)
")
12
Adaboost: Example (7/10)
")
13
Adaboost: Example (8/10)
")
14
Adaboost: Example (9/10)
")
15
Adaboost: Example (10/10)
")
17
Adaboost Strong classifier = linear combination of T weak classifiers
(1) Design of weak classifier (2) Weight for each classifier (Hypothesis weight) (3) Update weight for each data (example distribution) Weak Classifier: < 50% error over any distribution
 Design of weak classifier. (2) Weight for each classifier (Hypothesis. weight) (3) Update weight for each data (example. distribution) Weak Classifier: < 50% error over any distribution.")
18
Adaboost: Terminology (1/2)
")
19
Adaboost: Terminology (2/2)
")
20
Adaboost: Framework

21
Adaboost: Framework

24
Adaboost Strong classifier = linear combination of T weak classifiers
(1) Design of weak classifier (2) Weight for each classifier (Hypothesis weight) (3) Update weight for each data (example distribution) Weak Classifier: < 50% error over any distribution
 Design of weak classifier. (2) Weight for each classifier (Hypothesis. weight) (3) Update weight for each data (example. distribution) Weak Classifier: < 50% error over any distribution.")
25
Adaboost: Design of weak classifier (1/2)
")
26
Adaboost: Design of weak classifier (2/2)
Select a weak classifier with the smallest weighted error Prerequisite:

27
Adaboost Strong classifier = linear combination of T weak classifiers
(1) Design of weak classifier (2) Weight for each classifier (Hypothesis weight) (3) Update weight for each data (example distribution) Weak Classifier: < 50% error over any distribution
 Design of weak classifier. (2) Weight for each classifier (Hypothesis. weight) (3) Update weight for each data (example. distribution) Weak Classifier: < 50% error over any distribution.")
28
Adaboost: Hypothesis weight (1/2)
How to set ?

29
Adaboost: Hypothesis weight (2/2)
")
30
Adaboost Strong classifier = linear combination of T weak classifiers
(1) Design of weak classifier (2) Weight for each classifier (Hypothesis weight) (3) Update weight for each data (example distribution) Weak Classifier: < 50% error over any distribution
 Design of weak classifier. (2) Weight for each classifier (Hypothesis. weight) (3) Update weight for each data (example. distribution) Weak Classifier: < 50% error over any distribution.")
31
Adaboost: Update example distribution (Reweighting)
y * h(x) = 1 y * h(x) = -1
 = 1. y * h(x) = -1.")
32
Reweighting In this way, AdaBoost “focused on” the informative or “difficult” examples.

33
Reweighting In this way, AdaBoost “focused on” the informative or “difficult” examples.

35
Summary t = 1

36
Example 2

37
Example (1/5) Original Training set : Equal Weights to all training samples Taken from “A Tutorial on Boosting” by Yoav Freund and Rob Schapire

38
Example (2/5) ROUND 1
 ROUND 1")
39
Example (3/5) ROUND 2
 ROUND 2")
40
Example (4/5) ROUND 3
 ROUND 3")
41
Example (5/5)
")
42
Example 3

50
Example 4

51
Adaboost:

55
Application

56
Discussion

57
Discrete Adaboost (DiscreteAB) (Friedman’s wording)
 (Friedman’s wording)")
58
Discrete Adaboost (DiscreteAB) (Freund and Schapire’s wording)
 (Freund and Schapire’s wording)")
59
Adaboost with Confidence Weighted Predictions (RealAB)
The bigger absolute value of the output of classifier, the more confidence of the classifier.

60
Adaboost Variants Proposed By Friedman
LogitBoost

61
Adaboost Variants Proposed By Friedman
GentleBoost

62
Reference

64
Robust Real-time Object Detection
Key word : Features extraction, Integral Image , AdaBoost , Cascade

65
Outline 1. Introduction 2. Features 2.1 Features Extraction
2.2 Integral Image 3. AdaBoost 3.1 Training Process 3.2 Testing Process 4. The Attentional Cascade 5. Experimental Results 6. Conclusion 7. Reference

66
1. Introduction Frontal face detection system achieves :
This paper brings together new algorithms and insights to construct a framework for robust and extremely rapid object detection. Frontal face detection system achieves : High detection rates Low false positive rates Three main contributions: Integral image AdaBoost : Selecting a small number of important features. Cascaded structure

67
2. Features Based on the simple features value. Reason : 1. Knowledge-based system is difficult to learn using a finite quantity of training data. 2. Much faster than Image-based system. ps. Feature-based: Use extraction features like eye, nose pattern. Knowledge-based: Use rules of facial feature. Image-based: Use face segments and predefined face pattern. [3] A.S.S.Mohamed, Ying Weng, S. S Ipson, and Jianmin Jiang, ”Face Detection based on Skin Color in Image by Neural Networks”, ICIAS 2007, pp , 2007.

68
2.1 Feature Extraction (1/2)
Filter: Filter type. Feature: a. pattern 的座標位置. b. pattern 的大小 Feature value: Feature value = Filter Feature Ex: haar-like filter EX: eye , nose EX: convolution

69
2.1 Feature Extraction (2/2)
Haar-like filter: The sum of the pixels which lie within the white rectangles are subtracted from the sum of pixels in the grey rectangles. Filter type Figure 1 Filter C Feature 24 + - + feature value 24

70
2.2 Integral Image (1/6) Integral image
Rectangle features Computed very rapidly II(x , y) : sum of the pixels above and to the left of (x , y).
 : sum of the pixels above and to the left of (x , y).")
71
2.2 Integral Image (2/6) Known:
A: Sum of the pixels within rectangle A. B: Sum of the pixels within rectangle B. C: Sum of the pixels within rectangle C. D: Sum of the pixels within rectangle D. Location 1 value is A. Location 2 value is A+B. Location 3 value is A+C. Location 4 value is A+B+C+D. Equation: 1 = A = A + B. Figure 2: Integral image 3 = A + C 4 = A + B + C + D Q : The sum of the pixels within rectangle D = ? A : The sum within D can be computed as (2 + 3).
.")
72
2.2 Integral Image (3/6) Sum of the pixels
![]()
73
2.2 Integral Image (4/6) Using the following pair of recurrences to get integral image : is the integral image. is the original image. is the cumulative row sum. ps.

74
2.2 Integral Image (5/6) original image cumulative row sum
1 3 4 2 6 10
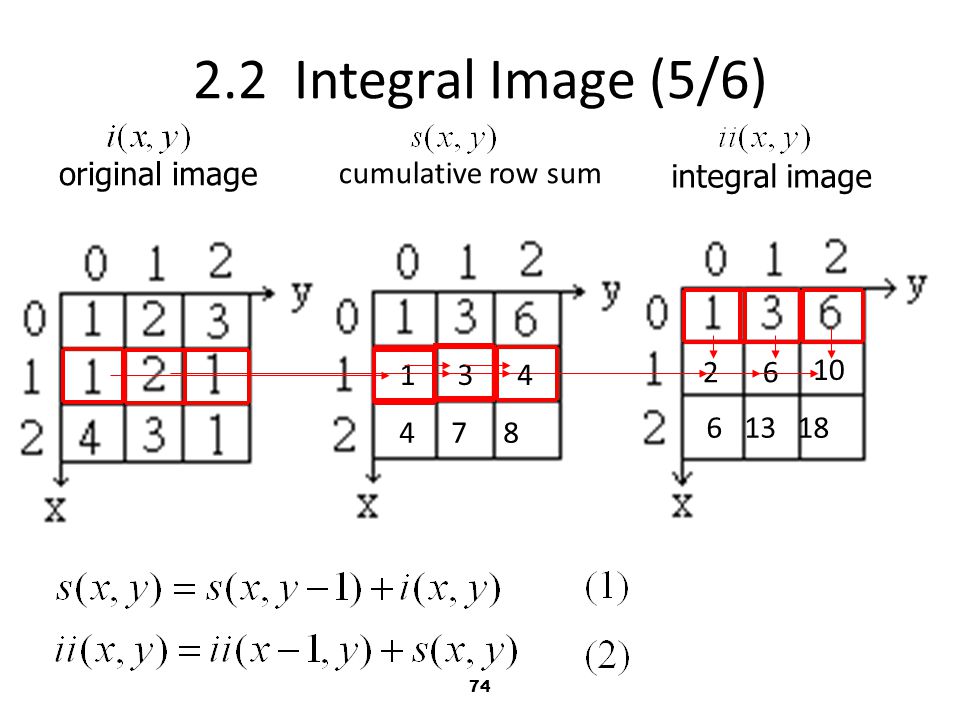
75
2.2 Integral Image (6/6) original image cumulative row sum
(3*3) (3*3) (3*3) = + = + = + =0+1=1 = + =0+1=1 = + =0+1=1 = + =1+1=2 = + =0+4=4 = + =2+4=6 = + =1+2=3 = + =0+3=3 + =1+2=3 = + =3+3=6 = … … = + =7+1=8 = + =10+8=18
 (3*3) (3*3) = + = + = + =0+1=1. = + =0+1=1. = + =0+1=1. = + =1+1=2. = + =0+4=4. = + =2+4=6. = + =1+2=3. = + =0+3=3. + =1+2=3. = + =3+3=6. = … … = + =7+1=8. = + =10+8=18.")
76
3. AdaBoost (1/2) AdaBoost (Adaptive Boosting) is a machine learning algorithm. AdaBoost works by choosing and combining weak classifiers together to form a more accurate strong classifier ! Weak classifier: Feature value Threshold Because training data has a large number of classifiers to consider, it spends a lot of time to compute. Image set 76

77
3. AdaBoost (2/2) Subsequent classifiers built are tweaked in favor of those instances misclassified by previous classifiers. [4] The goal is to minimize the number of features that need to be computed when given a new image, while still achieving high identification rates. [4] AdaBoost - Wikipedia, the free encyclopedia ,
![3. AdaBoost (2/2) Subsequent classifiers built are tweaked in favor of those instances misclassified by previous classifiers. [4]](http://slideplayer.com/slide/4273760/14/images/77/3.+AdaBoost+%282%2F2%29+Subsequent+classifiers+built+are+tweaked+in+favor+of+those+instances+misclassified+by+previous+classifiers.+%5B4%5D.jpg "The goal is to minimize the number of features that need to be computed when given a new image, while still achieving high identification rates. [4] AdaBoost - Wikipedia, the free encyclopedia ,")
78
3.1 Training Process - Flowchart
1. Input: Training image set X Face (24x24) l 張 Non-Face (24x24) m 張 設每張 image 可 extract 出 N 個 feature value 共有N*(l+m) 個 feature value 2. Feature Extraction: Using haar-like filter feature Candidate threshold θ 3. AdaBoost Algorithm: 3.0. Image weight initialization 3.1. Normalize image weight 3.2. Error calculation 3.3. Select a weak classifier ht with the lowest error εt 3.4. Image weight adjusting T 個 weak classifiers 4. Output: A strong classifier Weak classifier (24x24) Weak classifier weight
 l 張. Non-Face. (24x24) m 張. 設每張 image 可. extract 出 N 個 feature value 共有N*(l+m) 個 feature value. 2. Feature Extraction: Using haar-like filter. feature. Candidate threshold θ. 3. AdaBoost Algorithm: 3.0. Image weight initialization Normalize image weight Error calculation Select a weak classifier ht with the lowest error εt Image weight adjusting. T 個. weak classifiers. 4. Output: A strong classifier. Weak classifier. (24x24) Weak classifier weight.")
79
3.2 Training Process - Input
Training data set 以 X 表示 . 設有 l 張 positive image , m 張 negative image , 共 n (n=l+m) 張 image. { … } 設每張 image 可以 extract 出 N 個 local feature , 表示 image 裡的第 j 個 local feature value , 共有 N * n 個 local feature value.
 張 image. { … } 設每張 image 可以 extract 出 N 個 local feature , 表示 image. 裡的第 j 個 local feature value , 共有 N * n 個 local feature value.")
80
3.2 Training Process - Feature Extraction (1/2)
2. Feature Extraction: Using haar-like filter Haar-like filter : n 張 image … … Candidate feature value (n*N 個) … convolution … … … … Ps. 1張 image 可 extract 出 N 個 feature value ∴ N = 4 * f f: feature number
 … convolution. … … … … Ps. 1張 image 可 extract 出 N 個 feature value ∴ N = 4 * f. f: feature number.")
81
3.2 Training Process - Feature Extraction (2/2)
Define weak classifiers : Ex : 3 face & 1 non-face image extract by 5th feature Face Non-face : 即 image i 的第 j 個 local feature value : 即 image k 的第 j 個 local feature value θ1,5 θ2,5 θ3,5 θ4,5 Polarity : h1,5 h2,5 h3,5 h4,5 ε1,5 ε2,5 ε3,5 ε4,5

82
3.2 Training Process - AdaBoost Algorithm (1/4)
3-0. Image weight initialization : l is the quantity of positive images. m is the quantity of negative images.

83
3.2 Training Process - AdaBoost Algorithm (2/4)
Iterative: t = 1, … ,T T : weak classifier number 3-1. Normalize image weight: 3-2. Error calculation : 3-3. Select a weak classifier with the lowest error rate . 3-4. Image weight adjusting : Training data set X Candidate weak classifier error rate positive or negative

84
3.2 Training Process – Output (1/2)
threshold Weak classifier weight

85
3.2 Training Process – Output (2/2)
如 Fig. B,當ε (error rate)在 0 ~ 0.1 區間內與其他如 0.1 ~ 0.5 區間內即使ε有相同的變化量,所對應到的α (weak classifier weight)變化量差異也相當大,如此一來當ε越趨近於 0 時,即使ε只有些微改變,在 strong classifier 中其比重也會劇烈加大。因此,取 log 是為了縮小 weight 彼此間差距,使 strong classifier 中的各個 weak classifiers 均佔有一定比重。 ε α Fig. B ε ε 0.001 999 2.99 0.005 199 2.29 0.101 8.9 0.94 0.105 8.52 0.93 800 0.7 α 0.38 0.01 Fig. C
在 0 ~ 0.1 區間內與其他如 0.1 ~ 0.5 區間內即使ε有相同的變化量,所對應到的α (weak classifier weight)變化量差異也相當大,如此一來當ε越趨近於 0 時,即使ε只有些微改變,在 strong classifier 中其比重也會劇烈加大。因此,取 log 是為了縮小 weight 彼此間差距,使 strong classifier 中的各個 weak classifiers 均佔有一定比重。 ε. α. Fig. B. ε. ε α Fig. C.")
86
AdaBoost Algorithm – Image Weight Adjusting Example
If 取最小 , 則 t =1 時 初始值 0.167 經分類後 O X Update 0.167*0.2 Normalize 0.1 0.5 Weight 變化 每一輪都將分對的 image 調低其weight ,經過 Normalize 後,分錯的 image的 weight 會相對提高,如此一來,常分錯的 image 就會擁有較高 weight。如果一張 image 擁有較高 weight 表示在進行分類評估時,會著重在此 image。

87
3.3 Testing Process - Flowchart
1. Extract Sub-windows Test Image Downsampling … (360*420) (228*336) (24*28) (360*420) About sub-windows … (24*24) 2. Strong Classifier Detection (24*24) Load T weak classifiers Strong Classifier Sub-window … h1 h2 h3 hT For all sub-windows Accept windows Reject windows Result Image … … 3. Merge Result average coordinate …
 (228*336) (24*28) (360*420) About sub-windows. … (24*24) 2. Strong Classifier Detection. (24*24) Load T weak classifiers. Strong Classifier. Sub-window. … h1. h2. h3. hT. For all. sub-windows. Accept windows. Reject windows. Result Image. … … 3. Merge Result. average coordinate. …")
88
4. The Attentional Cascade (1/5)
Advantage: Reducing testing computation time. Method: Cascade stages. Idea: Reject as many negatives as possible at the earliest stage. More complex classifiers were then used in later stages. The detection process is that of a degenerate decision tree, so called “cascade”. Stage True positive False positive True negative False negative Figure 4 : Cascade Structure

89
4. The Attentional Cascade (2/4)
θ Stage 1 θ θ Stage 2 Stage 3

90
4. The Attentional Cascade (3/4)
True positive rates (detection rates): 將 positive 判斷為 positive 機率 False positive rates (FP): 將 negative 判斷為 positive 機率 True negative rates: 將 negative 判斷為 negative 機率 False negative rates (FN): 將 positive 判斷為 negative 機率 FP + FN => Error Rate
: 將 positive 判斷為 positive 機率. False positive rates (FP): 將 negative 判斷為 positive 機率. True negative rates: 將 negative 判斷為 negative 機率. False negative rates (FN): 將 positive 判斷為 negative 機率. FP. + FN. => Error Rate.")
91
4. The Attentional Cascade (4/4)
Training a cascade of classifiers: Involves two types of tradeoffs : Higher detection rates Lower false positive rates More features will achieve higher detection rates and lower false positive rates. But classifiers require more time to compute. Define an optimization framework: the number of stages the number of features in each stage the strong classifier threshold in each stage

92
4. The Attentional Cascade - Algorithm (1/3)
")
93
4. The Attentional Cascade - Algorithm (2/3)
f : Maximum acceptable false positive rate. (最大 negative 辨識成 positive 錯誤百分比) d : Minimum acceptable detection rate. (最小辨識出 positive 的百分比) : Target overall false positive rate. (最後可容許的 false positive rate) Initial value: P : Total positive images N : Total negative images f = 0.5 d = 初始 False positive rate. 初始 Detection rate. Threshold = AdaBoost threshold Threshold_EPS = Threshold adjust weight i = The number of cascade stage
 d : Minimum acceptable detection rate. (最小辨識出 positive 的百分比) : Target overall false positive rate. (最後可容許的 false positive rate) Initial value: P : Total positive images. N : Total negative images. f = 0.5. d = 初始 False positive rate. 初始 Detection rate. Threshold = 0.5 AdaBoost threshold. Threshold_EPS = Threshold adjust weight. i = 0 The number of cascade stage.")
94
4. The Attentional Cascade - Algorithm (3/3)
Iterative: While( ) { i=i+1 While( ) ( ) = AdaBoost(P,N, ) While( ) Threshold = Threshold – Threshold_EPS = Re-computer current strong classifier detection rate with Threshold (this also affects ) } If( ) N = false detections with current cascaded detector on the N f : Maximum acceptable false positive rate d : Minimum acceptable detection rate : Target overall false positive rate P : Total positive images N : Total negative images i : The number of cascade stage Fi : False positive rate at ith stage Di : Detection rate at ith stage ni : The number of features at ith stage Add Stage Add Feature Get New Di , Fi Threshold , 則Di ,Fi N = Fi *N
 { i=i+1. While( ) ( ) = AdaBoost(P,N, ) While( ) Threshold = Threshold – Threshold_EPS. = Re-computer current strong classifier detection rate with Threshold (this also affects ) } If( ) N = false detections with current cascaded detector on the N. f : Maximum acceptable false positive rate. d : Minimum acceptable detection rate. : Target overall false positive rate. P : Total positive images. N : Total negative images. i : The number of cascade stage. Fi : False positive rate at ith stage. Di : Detection rate at ith stage. ni : The number of features at ith stage. Add Stage. Add Feature. Get New Di , Fi. Threshold , 則Di ,Fi. N = Fi *N.")
95
5. Experimental Results (1/3)
Face training set: Extracted from the world wide web. Use face and non-face training images. Consisted of 4916 hand labeled faces. Scaled and aligned to base resolution of 24 by 24 pixels. The non-face sub-windows come from 9544 images which were manually inspected and found to not contain any faces. Fig. 5: Example of frontal upright face images used for training

96
5. Experimental Results (2/3)
In the cascade training: Use 4916 training faces. Use 10,000 non-face sub-windows. Use the AdaBoost training procedure. Evaluated on the MIT+CMU test set: An average of 10 features out of a stage are evaluated per sub-window. This is possible because a large majority of sub-windows are rejected by the first or second stage in the cascade. On a 700 Mhz Pentium III processor, the face detector can process a 384 by 288 pixel image in about .067 seconds .

97
5. Experimental Results (3/3)
θ Fig. 6: Create the ROC curve (receiver operating characteristic) the threshold of the final stage classifier is adjusted from
 the threshold of the final stage classifier is adjusted from .")
98
Reference [1] P. Viola and M. Jones, “Rapid Object Detection Using A Boosted Cascade of Simple Features”, Proc. IEEE Conf. Computer Vision and Pattern Recognition, vol.1, pp , 2001 [2] P. Viola and M. Jones, “Robust Real-time Object Detection”, IEEE International Journal of Computer Vision, vol.57, no.2, pp , 2001. [3] A.S.S.Mohamed, Ying Weng, S. S Ipson, and Jianmin Jiang, ”Face Detection based on Skin Color in Image by Neural Networks”, ICIAS 2007, pp , 2007. [4] AdaBoost - Wikipedia, the free encyclopedia ,

Similar presentations

















Boris Babenko.>")


 Viola-Jones and AdaBoost Guest Instructor: Andras Ferencz (Your Regular Instructor: Fei-Fei Li) Thanks to Fei-Fei Li,>")




>")

>")

>")

 Focus: Multiple Regression ( 多元迴歸、複迴歸 ) Spring 2007.>")


