Download presentation
Presentation is loading. Please wait.

1
The Traveling Salesman Problem in Theory & Practice Lecture 8: Lin-Kernighan and Beyond 11 March 2014 David S. Johnson dstiflerj@gmail.com http://davidsjohnson.net Seeley Mudd 523, Tuesdays and Fridays

2
Outline 1.k-Opt, k > 3 2.Lin-Kernighan 3.and Beyond…. 4.A quick tour of heuristics for the Asymmetric TSP

3
4-Opt Seems to be relatively straightforward to generalize from 3-opt. – Just need to now consider possibilities for t 7 and t 8. – Can further exploit the Partial Sum Theorem. – Can consider all possibilities for t5, but need to make sure that t7 breaks up the short cycle (or create a new one).
..")
4
t1t1 t2t2 t3t3 t4t4 t4t4 An alternative View: Maintain the path

5
t1t1 t4t4 t3t3 t2t2

6
t1t1 t2t2 t3t3 t4t4 An alternative View: Maintain the path, at least eventually… t5t5 t6t6

7
t1t1 t2t2 t4t4 t3t3 t5t5 t6t6 t5t5 t3t3 t6t6 t2t2

8
Double Bridge Move Cannot be produced by any sequential move. Best one can be found in O(N 2 ) time.
 time..")
9
Best Double Bridge Move in Time O(N 2 ) [Glover, “Finding a best traveling salesman 4-opt move in the same time as a best 2-opt move,” J. Heuristics 2 (1996), 169-179] Simpler algorithm due to Johnson & McGeoch, 2002
, ] Simpler algorithm due to Johnson & McGeoch,")
10
Normal Form for Double Bridge Move N1 2N-1 p j i+1 i j+1 p+1 q qp+1 C[h,k] = Cost of move that deletes {h,h+1} and {k,k+1} and adds {h,k+1} and {h+1,k} Smallest index of the first endpoint of a deleted edge
![Normal Form for Double Bridge Move N1 2N-1 p j i+1 i j+1 p+1 q qp+1 C[h,k] = Cost of move that deletes {h,h+1} and {k,k+1} and adds {h,k+1} and {h+1,k} Smallest index of the first endpoint of a deleted edge](http://images.slideplayer.com/14/4272708/slides/slide_10.jpg "Normal Form for Double Bridge Move N1 2N-1 p j i+1 i j+1 p+1 q qp+1 C[h,k] = Cost of move that deletes {h,h+1} and {k,k+1} and adds {h,k+1} and {h+1,k} Smallest index of the first endpoint of a deleted edge")
11
The Functions to be Computed f(p,j) = min {C[p,q] : j < q ≤ N}, 2 ≤ p < j ≤ N. g(i,j) = C[i,j] + min {f[p,j] : i < p < j}, 1 ≤ i < j-1 ≤ N-1. N 1 2 N-1 p j i+1 i j+1 p+1 q q+1 Theorem: The length of the best 2-bridge move is min {g(i,j): 1 ≤ i < j-1 ≤ N-2. Question: How is this O(N 2 )? There are θ(N 2 ) values of f(p,j) and g(i,j) to compute, and the average ones appears to take time θ(N) to compute.
![The Functions to be Computed f(p,j) = min {C[p,q] : j < q ≤ N}, 2 ≤ p < j ≤ N.](http://images.slideplayer.com/14/4272708/slides/slide_11.jpg "g(i,j) = C[i,j] + min {f[p,j] : i < p < j}, 1 ≤ i < j-1 ≤ N-1. N 1 2 N-1 p j i+1 i j+1 p+1 q q+1 Theorem: The length of the best 2-bridge move is min {g(i,j): 1 ≤ i < j-1 ≤ N-2. Question: How is this O(N 2 ). There are θ(N 2 ) values of f(p,j) and g(i,j) to compute, and the average ones appears to take time θ(N) to compute..")
12
The Functions to be Computed f(p,j) = min {C[p,q] : j < q ≤ N}, 2 ≤ p < j ≤ N. g(i,j) = C[i,j] + min {f[p,j] : i < p < j}, 1 ≤ i < j-1 ≤ N-1. N 1 2 N-1 p j i+1 i j+1 p+1 q q+1 Observation: The only difference between f(p,j) and f(p,j-1) is the inclusion of C[p,j] in the minimization. The only difference between g(i,j) and g(i-1,j) is the inclusion of f(i,j) in the minimization. So the values of each can be computed in constant time per value.
![The Functions to be Computed f(p,j) = min {C[p,q] : j < q ≤ N}, 2 ≤ p < j ≤ N.](http://images.slideplayer.com/14/4272708/slides/slide_12.jpg "g(i,j) = C[i,j] + min {f[p,j] : i < p < j}, 1 ≤ i < j-1 ≤ N-1. N 1 2 N-1 p j i+1 i j+1 p+1 q q+1 Observation: The only difference between f(p,j) and f(p,j-1) is the inclusion of C[p,j] in the minimization. The only difference between g(i,j) and g(i-1,j) is the inclusion of f(i,j) in the minimization. So the values of each can be computed in constant time per value..")
13
4-Opt Conclusions Can be implemented to run in O(N 2 ) per iteration. This is likely to be significantly slower than our 3-opt implementation. k-opt for k > 4 will be even worse: – Intermediate solutions can involve a path plus multiple cycles. – More possibilities for non-sequential moves that must be considered as special cases (triple-bridge moves, etc.), Improvement in tours over what 3-opt can produce may not be worth the effort (Shen Lin, private communication). Alternative approach: a highly-pruned N-opt approach: The Lin-Kernighan Algorithm
, Improvement in tours over what 3-opt can produce may not be worth the effort (Shen Lin, private communication). Alternative approach: a highly-pruned N-opt approach: The Lin-Kernighan Algorithm.")
14
The Lin-Kernighan Algorithm [Shen Lin & Brian Kernighan, Bell Labs, 1971] Built on top of 3-opt, augmented to allow choices of t 5 that create a short cycle, so long as there are legal choices of t 6, t 7, and t 8 that pull things together again. After each choice of t 6 (or t 8 in in the above special case), we invoke a deep-dive “LK-search,” assuming the gain criterion from the Partial Sum Theorem is met. The source of what follows is [Lin & Kernighan, “An effective heuristic algorithm for the traveling salesman problem,” Operations Research 21 (1973), 498-516] and the original Lin-Kernighan FORTRAN code.
![The Lin-Kernighan Algorithm [Shen Lin & Brian Kernighan, Bell Labs, 1971] Built on top of 3-opt, augmented to allow choices of t 5 that create a short cycle, so long as there are legal choices of t 6, t 7, and t 8 that pull things together again.](http://images.slideplayer.com/14/4272708/slides/slide_14.jpg "After each choice of t 6 (or t 8 in in the above special case), we invoke a deep-dive LK-search, assuming the gain criterion from the Partial Sum Theorem is met. The source of what follows is [Lin & Kernighan, An effective heuristic algorithm for the traveling salesman problem, Operations Research 21 (1973), ] and the original Lin-Kernighan FORTRAN code..")
15
t1t1 t 2i t 2i+1 t 2i+2 LK Search Candidates for t 2i+1 are the cities on the neighbor list for t 2i such that the length of the resulting “one-tree” is less than the length of the shortest tour seen so far. [Note that this is the same criterion as provided by the Partial Sum Theorem.] We abandon the choice if the edge to be deleted, {t 2i+1,t 2i+2 }, was added to the tour earlier in this search (is not an original tour edge). This limits the depth of the search to N.
. This limits the depth of the search to N..")
16
LK Search t1t1 t 2i+2 t 2i+1 t 2i Candidates for t 2i+1 are the cities on the neighbor list for t 2i such that the length of the resulting “one-tree” is less than the length of the shortest tour seen so far. [Note that this is the same criterion as provided by the Partial Sum Theorem.] We abandon the choice if edge to be deleted, {t 2i+1,t 2i+2 }, was added to the tour earlier (is not an original tour edge). This limits the depth of the search to N. If adding the edge {t 1,t 2i+2 } to this path yields a new champion tour, save that tour. As the starting path for the next level of the search, take the shortest path generated by any of the the valid choices for t 2i+1. The flips illustrated here are actually performed, and then undone as needed, eventually returning us to our starting point (or the improved tour, if found).
. This limits the depth of the search to N. If adding the edge {t 1,t 2i+2 } to this path yields a new champion tour, save that tour. As the starting path for the next level of the search, take the shortest path generated by any of the the valid choices for t 2i+1. The flips illustrated here are actually performed, and then undone as needed, eventually returning us to our starting point (or the improved tour, if found)..")
17
Differences between Algorithm Tested and Lin-Kernighan, as described We use pre-computed neighbor lists (k = 20). LK did not similarly restrict t 3, t 5, t 7, although their code restricted LK search to the 5 nearest neighbors. We use don’t-look-bits and queue order. LK cycled through t 1 candidates in input order. We use randomized Greedy starting tours, whereas LK used random starting tours. Lin-Kernighan not only forbids the deletion of a previously-added tour edge. It also forbids addition of a previously deleted edge. We allow this latter possibility. Lin-Kernighan also added a search for an improving double-bridge move (one that does not deleted added edges), used only whenever no further standard improving moves could be found. They used an exhaustive search, but even our O(N 2 ) algorithm is unlikely to scale well, so we omit this step. Lin-Kernighan used Array tour representation, while we switch to 2-level trees for N > 1,000. Lin-Kernighan coded in FORTRAN and ran on memory-constrained machines. The largest instance they could test had 318 cities and was considered “big” in 1971. We used C and modern machines, and go considerably bigger.
, used only whenever no further standard improving moves could be found. They used an exhaustive search, but even our O(N 2 ) algorithm is unlikely to scale well, so we omit this step. Lin-Kernighan used Array tour representation, while we switch to 2-level trees for N > 1,000. Lin-Kernighan coded in FORTRAN and ran on memory-constrained machines. The largest instance they could test had 318 cities and was considered big in We used C and modern machines, and go considerably bigger..")
18
Show Movie

19
Worst-Case Running Time per Iteration (Time to find the next improving move or determine there is none.) O(N) choices for t 1. Up to 2 choices for t 2. O(k) choices for t 3, each potentially involving a between + a flip. Up to 2 choices for t 4. O(k) choices for t 5, each potentially involving a between + a flip. Up to 2 choices for t 6. O(k) choices for t 7, each potentially involving a between + a flip. Up to 2 choices for t 8. O(N) levels of LK-search. O(k) choices for t 2i+1, each potentially involving a flip. Total = O(N 2 k 4 logN) using splay trees. In practice much smaller because of don’t-look-bits. In practice much smaller, since tour edges usually go to near neighbors Further restricted by the locking of edges Typically much smaller.
 choices for t 3, each potentially involving a between + a flip. Up to 2 choices for t 4. O(k) choices for t 5, each potentially involving a between + a flip. Up to 2 choices for t 6. O(k) choices for t 7, each potentially involving a between + a flip. Up to 2 choices for t 8. O(N) levels of LK-search. O(k) choices for t 2i+1, each potentially involving a flip. Total = O(N 2 k 4 logN) using splay trees. In practice much smaller because of don’t-look-bits. In practice much smaller, since tour edges usually go to near neighbors Further restricted by the locking of edges Typically much smaller..")
20
How Many Iterations? In practice, typically θ(N) on random Euclidean instances for all of 2-opt, 3- opt, and Lin-Kernighan. In theory, what? Theorem [Englert, Röglin, & Vöcking, “Worst case and probabilistic analysis of the 2-opt algorithm for the TSP,” Algorithmica 68 (2014), 190-264] : For any L p metric, 1 ≤ p ≤ ∞, and any N ≥ 1, there exists a set of 16N points in the unit square for which 2-opt can take as many as 2 N+4 -22 steps. One can get similar exponential lower bounds for k-opt, k > 2, if one considers instances not obeying the triangle inequality. [Chandra, Karloff, & Tovey, “New results on the old k-opt algorithm for the TSP,” SIAM J. Comput., 28 (1999), 1998–2029]. Note: This is doubly worst-case – not only must one be unfortunate enough to get the bad instance, one must also be unfortunate enough to pick the bad sequence of moves. What about average case, at least on the instances? For random Euclidean instances, one of these levels of worst-case can be removed.
 on random Euclidean instances for all of 2-opt, 3- opt, and Lin-Kernighan. In theory, what. Theorem [Englert, Röglin, & Vöcking, Worst case and probabilistic analysis of the 2-opt algorithm for the TSP, Algorithmica 68 (2014), ] : For any L p metric, 1 ≤ p ≤ ∞, and any N ≥ 1, there exists a set of 16N points in the unit square for which 2-opt can take as many as 2 N steps. One can get similar exponential lower bounds for k-opt, k > 2, if one considers instances not obeying the triangle inequality. [Chandra, Karloff, & Tovey, New results on the old k-opt algorithm for the TSP, SIAM J. Comput., 28 (1999), 1998–2029]. Note: This is doubly worst-case – not only must one be unfortunate enough to get the bad instance, one must also be unfortunate enough to pick the bad sequence of moves. What about average case, at least on the instances. For random Euclidean instances, one of these levels of worst-case can be removed..")
21
Iterations for Random Euclidean Instances Theorem [Kern, 1989]: With high probability, maximum length of a sequence of improving 2-opt moves is O(N 16 ). Theorem [Chandra, Karloff, & Tovey, 1999]: The expected length of a maximum sequence of 2-opt moves is O(N 10 logN) and O(N 6 logN) for the Manhattan (L 1 ) metric. Theorem [Englert, Röglin, & Vöcking, 2014]: The expected length of a maximum sequence of 2-opt moves is O(N 4+1/3 logN) and O(N 3.5 logN) for the Manhattan metric. (This latter result extends parametrically to higher dimensions and a variety of other point distributions.)
![Iterations for Random Euclidean Instances Theorem [Kern, 1989]: With high probability, maximum length of a sequence of improving 2-opt moves is O(N 16 ).](http://images.slideplayer.com/14/4272708/slides/slide_21.jpg "Theorem [Chandra, Karloff, & Tovey, 1999]: The expected length of a maximum sequence of 2-opt moves is O(N 10 logN) and O(N 6 logN) for the Manhattan (L 1 ) metric. Theorem [Englert, Röglin, & Vöcking, 2014]: The expected length of a maximum sequence of 2-opt moves is O(N 4+1/3 logN) and O(N 3.5 logN) for the Manhattan metric. (This latter result extends parametrically to higher dimensions and a variety of other point distributions.).")
22
Removing the Move Sequence from the Picture: PLS-completeness [Johnson, Papadimitriou, & Yannakakis, “How easy is local search?” J. Comp. Syst. Sci. 37 (1988), 79-100] Definition: A local search problem L in PLS (polynomial-time local search) consists of a)A type T L ε {min, max}. b)A polynomial-time recognizable set D L of instances. c)For each instance x D L, a set F L (x) of solutions that is recognizable in time polynomial in |x|. d)For each solution s F L (x), 1)a non-negative integer cost c L (s,x), and a 2)a subset N(s,x) ⊆ F L (x), called the neighborhood of x. e)Three polynomial-time algorithms: 1) A L, which, given x D L, produces a standard (starting) solution A L (x) F L (x). 2) B L, which, given x D L and s F L (x), computes c L (s,x). 3) C L, which, given x D L and s F L (x), either returns a solution s’ N(s,x) with a better cost (e,g., c L (s’,x) < c L (s,x) if T L = min), or reports truthfully that no such solution exists, and hence s is locally optimal.
, ] Definition: A local search problem L in PLS (polynomial-time local search) consists of a)A type T L ε {min, max}. b)A polynomial-time recognizable set D L of instances. c)For each instance x D L, a set F L (x) of solutions that is recognizable in time polynomial in |x|. d)For each solution s F L (x), 1)a non-negative integer cost c L (s,x), and a 2)a subset N(s,x) ⊆ F L (x), called the neighborhood of x. e)Three polynomial-time algorithms: 1) A L, which, given x D L, produces a standard (starting) solution A L (x) F L (x). 2) B L, which, given x D L and s F L (x), computes c L (s,x). 3) C L, which, given x D L and s F L (x), either returns a solution s’ N(s,x) with a better cost (e,g., c L (s’,x) < c L (s,x) if T L = min), or reports truthfully that no such solution exists, and hence s is locally optimal..")
23
Key Computational Question About a Problem L in PLS: Is there an algorithm that, given an instance x D L, finds a locally optimal solution s F L (x) in time polynomial in |x|? True if all sequences of improving moves are polynomially bounded, as they would be, for instance, if all costs are polynomially bounded in |x|. Examples include – Vertex Cover – Max Clique – TSP when all edge lengths are less than some constant (as in the case of our random Euclidean instance generator, where all coordinates are in [0, 10 7 ] and distances are rounded to the nearest integer) Also may be true if there is a better heuristic for choosing the next move than the one given by C L (s,x). Or if there is some way of finding a locally optimal solution without using a local search algorithm at all. – As when L is corresponds to the Simplex neighborhood for Linear Programming.
 Also may be true if there is a better heuristic for choosing the next move than the one given by C L (s,x). Or if there is some way of finding a locally optimal solution without using a local search algorithm at all. – As when L is corresponds to the Simplex neighborhood for Linear Programming..")
24
PLS-Reductions A reduction from PLS problem L to PLS problem K consists of two polynomial- time computable functions: 1) f, which maps instances of x D L to instances f(x) D K and 2) g, which maps pairs (x D L, s F K (f(x))) to solutions g(x,s) F L (x), such that for all x D L, if s is a locally optimal solution for instance f(x) of K, then g(x,s) is locally optimal for L. This notion is transitive, and has all the properties needed to define the concept of PLS-completeness, and yield the following: Theorem: If we can find locally optimal solutions in polynomial time for any PLS-complete problem, then we can do so for all problems in PLS. In addition, the running time of the “standard algorithm” for a PLS-complete problem is “typically” exponential, and the problem of determining the output of that algorithm is “typically” NP-hard. (This is a property of many particular proofs of PLS-completeness, rather than a known consequence of the definitions).
..")
25
PLS-Completeness and the TSP [Krentel, “Structure in locally optimal solutions,” FOCS 1989, IEEE Computer Society, pp. 216-221]: k-opt is PLS-complete for some k between 1,000 and 10,000. [Papadimtriou, “The complexity of the Lin-Kernighan heuristic for the traveling salesman problem,” SIAM J. Comput. 7 (1992), 450-465]. Lin- Kernighan is PLS-complete. This is for the variant in which, for LK-search, instead of not allowing an added edge to be subsequently deleted, we instead do not allow an edge that has been deleted to be subsequently added back. Note that under this variant, the LK-search can take as many as θ(N 2 ) steps, as compared to the O(N) bound for the other method. And recall that both criteria are used in the original Lin-Kernighan paper.
, ]. Lin- Kernighan is PLS-complete. This is for the variant in which, for LK-search, instead of not allowing an added edge to be subsequently deleted, we instead do not allow an edge that has been deleted to be subsequently added back. Note that under this variant, the LK-search can take as many as θ(N 2 ) steps, as compared to the O(N) bound for the other method. And recall that both criteria are used in the original Lin-Kernighan paper..")
26
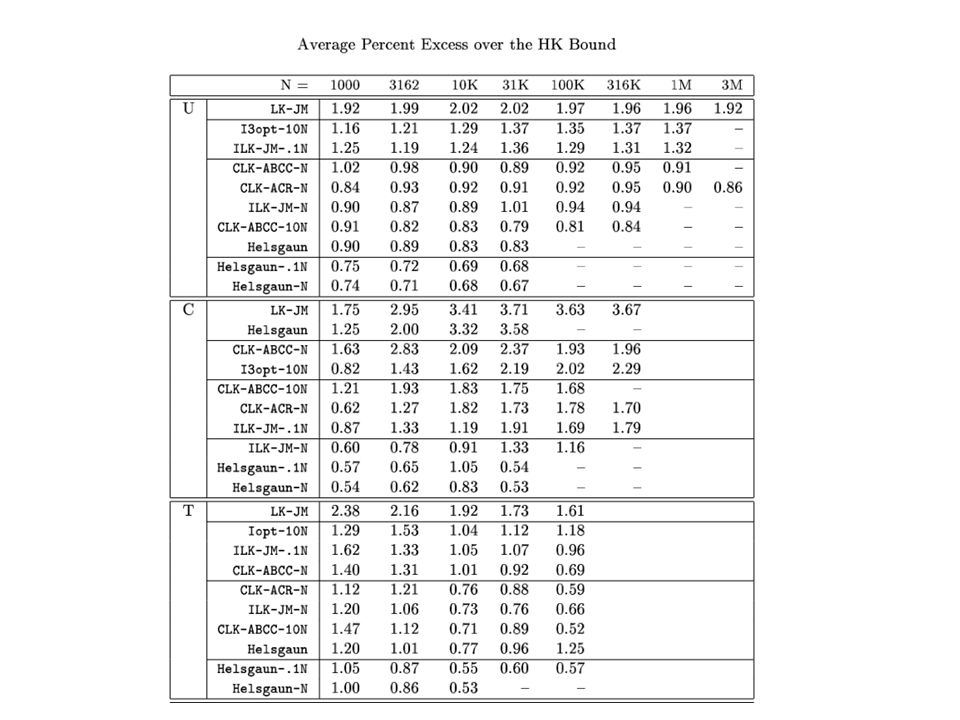
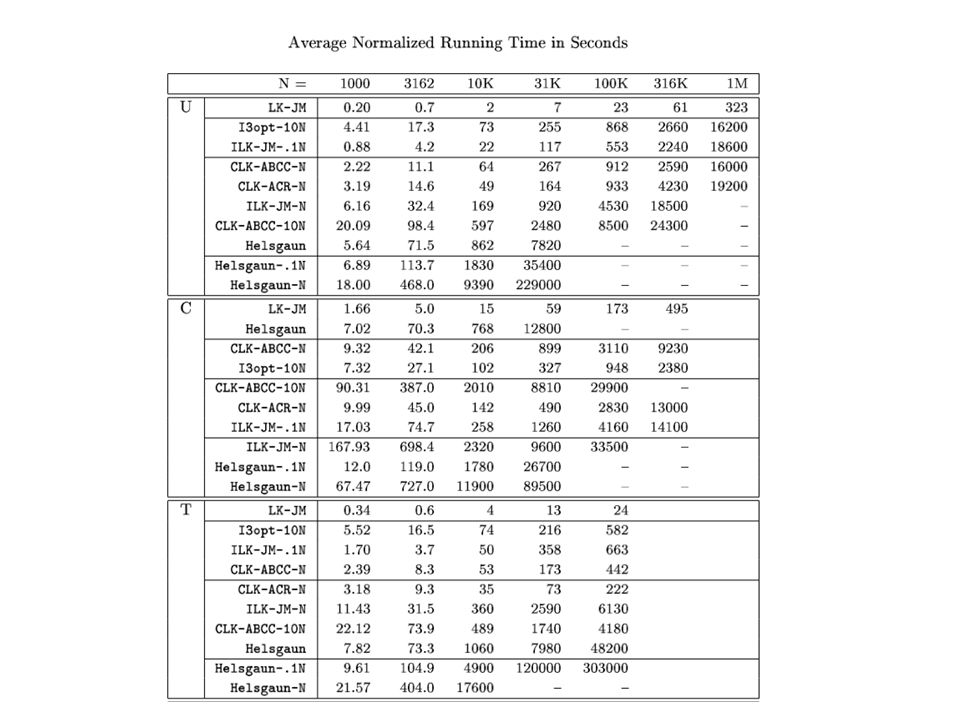
Computational Results, Random Euclidean Instances N =10 3 10 4 10 5 10 6 2-Opt [20]% Excess over HK4.95.04.9 150 Mhz Secs0.323.856.7928 3-Opt [20]% Excess3.13.0 150 Mhz Secs0.384.666.11054 LK [20]% Excess2.0 150 Mhz Secs0.779.81512650 Time on 3.06 Ghz Intel Core i3 processor at N = 10 6 : 25.4 sec (2-opt), 29.5 sec (3-opt), 61.5 (LK) Of this, 23.5 sec was for Preprocessing (input reading + neighbor list construction + initial tour generation)
![Computational Results, Random Euclidean Instances N = Opt [20]% Excess over HK Mhz Secs Opt [20]% Excess Mhz Secs LK [20]% Excess Mhz Secs Time on 3.06 Ghz Intel Core i3 processor at N = 10 6 : 25.4 sec (2-opt), 29.5 sec (3-opt), 61.5 (LK) Of this, 23.5 sec was for Preprocessing (input reading + neighbor list construction + initial tour generation)](http://images.slideplayer.com/14/4272708/slides/slide_26.jpg "Computational Results, Random Euclidean Instances N = Opt [20]% Excess over HK Mhz Secs Opt [20]% Excess Mhz Secs LK [20]% Excess Mhz Secs Time on 3.06 Ghz Intel Core i3 processor at N = 10 6 : 25.4 sec (2-opt), 29.5 sec (3-opt), 61.5 (LK) Of this, 23.5 sec was for Preprocessing (input reading + neighbor list construction + initial tour generation)")
30
Beating Lin-Kernighan, Part 1: Simulated Annealing [Kirkpatrick, Gelatt, & Vecchi, “Optimization by simulated annealing,” Science 220 (13 May 1983), 671-680] [Černy, “A thermodynamical approach to the travelling salesman problem: An efficient simulation algorithm,” J. Optimization Theory and Appl. 45 (1985), 41-51] [Kirkpatrick, “Optimization by simulated annealing: Quantitative studies,” J. Stat. Physics 34 (1984), 976-986] Based on an analogy: Physical SystemOptimization Problem StateFeasible Solution EnergyCost Ground StateOptimal Solution Rapid QuenchingLocal Optimization Careful AnnealingSimulated Annealing
![Beating Lin-Kernighan, Part 1: Simulated Annealing [Kirkpatrick, Gelatt, & Vecchi, Optimization by simulated annealing, Science 220 (13 May 1983), ] [Černy, A thermodynamical approach to the travelling salesman problem: An efficient simulation algorithm, J.](http://images.slideplayer.com/14/4272708/slides/slide_30.jpg "Optimization Theory and Appl. 45 (1985), 41-51] [Kirkpatrick, Optimization by simulated annealing: Quantitative studies, J. Stat. Physics 34 (1984), ] Based on an analogy: Physical SystemOptimization Problem StateFeasible Solution EnergyCost Ground StateOptimal Solution Rapid QuenchingLocal Optimization Careful AnnealingSimulated Annealing.")
32
Theoretical Results General Theorem [Proved by many]: If you run long enough, and cool slowly enough (say letting the temperature be C/log(n), where C is a constant and n is the number of moves tested so far), then, with high probability, you will converge to an optimal solution. General Drawback: For this to work, “long enough” will exceed the time to perform exhaustive search…
![Theoretical Results General Theorem [Proved by many]: If you run long enough, and cool slowly enough (say letting the temperature be C/log(n), where C is a constant and n is the number of moves tested so far), then, with high probability, you will converge to an optimal solution.](http://images.slideplayer.com/14/4272708/slides/slide_32.jpg "General Drawback: For this to work, long enough will exceed the time to perform exhaustive search….")
33
Implementations Details Initial temperature so high that most moves are accepted. Exponentials are evaluated by lookup from a pre-computed table. “Frozen” = No more moves being accepted. “At Equilibrium” = Having tried a given fixed number of moves at the current temperature. “Lower the temperature” = Multiply it by a fixed constant, say 0.95. A generic simulated annealing implementation reflecting these principles was developed by DSJ, together with interns Cecilia Aragon, Lyle McGeoch, and Cathy Schevon. We consulted with Scott Kirkpatrick and so that our implementation would reflect his own. It is described in [Johnson, Aragon, McGeoch, & Schevon, “Optimization by simulated annealing: an experimental evaluation; Part I, Graph Partitioning,” Oper. Res 37 (1989), 865-892] and [Johnson, Aragon, McGeoch, & Schevon, “Optimization by simulated annealing: an experimental evaluation; Part II, Graph coloring and number partitioning,” Oper. Res 39 (1991), 378-406]. The implementation was adapted to the TSP with Lyle McGeoch. Results are described in [Johnson & McGeoch, “The traveling salesman problem: A case study in local optimization,” in Local Search in Combinatorial Optimization, Aarts & Lenstra (editors), John-Wiley and Sons, Ltd., 1997, pp. 215-310].
, ] and [Johnson, Aragon, McGeoch, & Schevon, Optimization by simulated annealing: an experimental evaluation; Part II, Graph coloring and number partitioning, Oper. Res 39 (1991), ]. The implementation was adapted to the TSP with Lyle McGeoch. Results are described in [Johnson & McGeoch, The traveling salesman problem: A case study in local optimization, in Local Search in Combinatorial Optimization, Aarts & Lenstra (editors), John-Wiley and Sons, Ltd., 1997, pp ]..")
34
TSP-Specific Details Basic move: 2-opt (as done by Kirkpatrick). Initial tour: Random tour. Starting temperature: set so 97% of moves are accepted. Temperature length = N(N-1), approximately twice the neighborhood size. Temperature reduction factor = 0.95. Averages over 10 runs. Times are on a 150 Mhz processor “Excess” is percent over HK bound
, approximately twice the neighborhood size. Temperature reduction factor = Averages over 10 runs. Times are on a 150 Mhz processor Excess is percent over HK bound.")
35
Algorithm Engineering for Simulated Annealing Neighborhood Pruning (first suggested by [Bonomi & Lutton, 1984]). In our version, we only consider moves corresponding to an arbitrary city as t 1, one of its tour neighbors as t 2, and t 3 chosen from the 20 cities on t 2 ’s neighbor list, a total of 20N possibilities.. This is further restricted as follows. Let c = t 1 and let c’ be the tour neighbor of c that is farther away. We only consider candidates c’’ for t 3 such that either d(c,c”) ≤ d(c,c’) or the probability of accepting an uphill move of size d(c,c”) – d(c,c’) is greater than 0.01. At each temperature, we consider 20 α N candidate moves ( α ≥ 1 a parameter), so that each potential move has a reasonably probability of being chosen as a candidate. Low-temperature starts (suggested by Kirkpatrick). Start with a Nearest Neighbor tour and a temperature yielding an initial acceptance rate of about 50%. For random Euclidean instances we follow the suggestion of Bonomi and Lutton to use L/√N, where L is the length of our “unit” square.
![Algorithm Engineering for Simulated Annealing Neighborhood Pruning (first suggested by [Bonomi & Lutton, 1984]).](http://images.slideplayer.com/14/4272708/slides/slide_35.jpg "In our version, we only consider moves corresponding to an arbitrary city as t 1, one of its tour neighbors as t 2, and t 3 chosen from the 20 cities on t 2 ’s neighbor list, a total of 20N possibilities.. This is further restricted as follows. Let c = t 1 and let c’ be the tour neighbor of c that is farther away. We only consider candidates c’’ for t 3 such that either d(c,c ) ≤ d(c,c’) or the probability of accepting an uphill move of size d(c,c ) – d(c,c’) is greater than At each temperature, we consider 20 α N candidate moves ( α ≥ 1 a parameter), so that each potential move has a reasonably probability of being chosen as a candidate. Low-temperature starts (suggested by Kirkpatrick). Start with a Nearest Neighbor tour and a temperature yielding an initial acceptance rate of about 50%. For random Euclidean instances we follow the suggestion of Bonomi and Lutton to use L/√N, where L is the length of our unit square..")
36
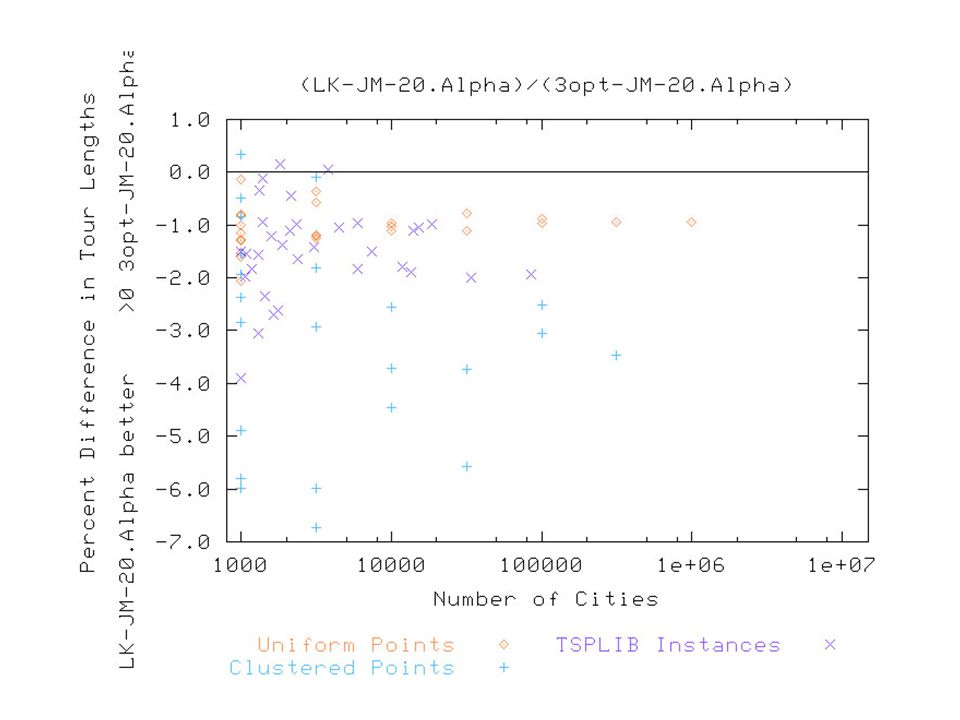
For more structured, instances, however, SA 2 can beat LK on a time equalized basis. In particular, for dsj1000 from TSPLIB (a clustered Euclidean instance which causes LK by a factor of 5 or more), SA 2 has 1.27% excess and time equalized LK gets 1.35%.
, SA 2 has 1.27% excess and time equalized LK gets 1.35%..")
37
dsj1000

38
More Algorithm Engineering: Using 3-opt Moves Proposed by Kirkpatrick in 1984, but his implementation did not exploit what we now know about fast 3-opt, and so his move set only contained moves where the segment moved was of length 10 or less (a generalization of Or-opt). In our version, we consider both 2- and 3-opt moves, choosing 2-opts for the first 10 α N candidates at each temperature, and 3-opts for the last 10 α N. A random 3-opt move is chosen as follows. Choose t 1 randomly from the N possibilities, t 2 randomly from the two possibilities, t 3 randomly from the (pruned) list of up to 20 possibilities, t 4 randomly from the two possibilities, t 5 randomly from the 20 possibilities (with up to four retries if the initial choices are topologically infeasible), and then, if t 6 is not topologically determined, choose it randomly from the two possibilities. This yields a total of at most 3200N possibilities.
 list of up to 20 possibilities, t 4 randomly from the two possibilities, t 5 randomly from the 20 possibilities (with up to four retries if the initial choices are topologically infeasible), and then, if t 6 is not topologically determined, choose it randomly from the two possibilities. This yields a total of at most 3200N possibilities..")
40
Other Metaheuristics Neural Nets [Hopfield & Tank, 1985] – Hopeless DNA computing [Adleman, 1994] – Parallel exhaustive search in a bathtub – does not scale Tabu Search [Glover, 1986] – Based on an idea implicit in LK-search - not competitive for TSP Genetic Algorithms [Holland, 1975] – Initial ideas were not competitive, but…
![Other Metaheuristics Neural Nets [Hopfield & Tank, 1985] – Hopeless DNA computing [Adleman, 1994] – Parallel exhaustive search in a bathtub – does not scale Tabu Search [Glover, 1986] – Based on an idea implicit in LK-search - not competitive for TSP Genetic Algorithms [Holland, 1975] – Initial ideas were not competitive, but…](http://images.slideplayer.com/14/4272708/slides/slide_40.jpg "Other Metaheuristics Neural Nets [Hopfield & Tank, 1985] – Hopeless DNA computing [Adleman, 1994] – Parallel exhaustive search in a bathtub – does not scale Tabu Search [Glover, 1986] – Based on an idea implicit in LK-search - not competitive for TSP Genetic Algorithms [Holland, 1975] – Initial ideas were not competitive, but…")
41
Genetic Algorithm Schema 1.Generate an initial population P consisting of a random set of k solutions. 2.While not yet converged, create a new generation of P as follows. 1)Select k’ distinct one- or two-item subsets of P (the mating strategy) 2)For each one-element subset, perform a random mutation to obtain a new solution. 3)For each two-element subset, perform a randomized crossover operation to obtain a new solution that reflects both parents. 4)Let P’ be the set of solutions generated by (2) and (3). 5)Using a selection strategy, choose k survivors from P ∪ P’ and replace P by these survivors. 3.Return the best solution in P. Standard “convergence” strategy: Stop if you have run for j generations without improving the best solution. Standard “selection” strategy: Choose the k best solutions.
Select k’ distinct one- or two-item subsets of P (the mating strategy) 2)For each one-element subset, perform a random mutation to obtain a new solution. 3)For each two-element subset, perform a randomized crossover operation to obtain a new solution that reflects both parents. 4)Let P’ be the set of solutions generated by (2) and (3). 5)Using a selection strategy, choose k survivors from P ∪ P’ and replace P by these survivors. 3.Return the best solution in P. Standard convergence strategy: Stop if you have run for j generations without improving the best solution. Standard selection strategy: Choose the k best solutions..")
42
abuhiqwopvnmszxlkerydfgjc Sample Crossover Operation Pick a segment S from tour A. Delete all the cities in S from tour B (keeping the remaining cities in the same order). Insert segment S into what is left of tour B. If you are skeptical that operations like this can lead to a competitive algorithm, you are right. A new idea is needed: The “Hybrid Genetic Algorithm” [Brady, “Optimization strategies gleaned biological evolution,” Nature 317 (1985), 804-806]. qwertyuopasdfghjklzxcvbnmqwertyuopadfghjcvbnqwertyuopadfghjcvbnqwertyuopadfghjcvbnmszxlk abuhiqwopvnmszxlkerydfgjc
. Insert segment S into what is left of tour B. If you are skeptical that operations like this can lead to a competitive algorithm, you are right. A new idea is needed: The Hybrid Genetic Algorithm [Brady, Optimization strategies gleaned biological evolution, Nature 317 (1985), ]. qwertyuopasdfghjklzxcvbnmqwertyuopadfghjcvbnqwertyuopadfghjcvbnqwertyuopadfghjcvbnmszxlk abuhiqwopvnmszxlkerydfgjc.")
43
Hybrid Genetic Algorithm Schema 1.Generate an initial population P consisting of a random set of k solutions. 2.Apply a given local optimization algorithm A to each solution s in P, letting the resulting local optimal solution s’ replace s in P. 3.While not yet converged, create a new generation of P as follows. 1)Select k’ distinct one- or two-item subsets of P (the mating strategy) 2)For each one-element subset, perform a random mutation to obtain a new solution. 3)For each two-element subset, perform a randomized crossover operation to obtain a new solution that reflects both parents. 4)Let P’ be the set of solutions generated by (2) and (3), after first applying algorithm A to each. 5)Using a selection strategy, choose k survivors from P ∪ P’ and replace P by these survivors. 4.Return the best solution in P. New
Select k’ distinct one- or two-item subsets of P (the mating strategy) 2)For each one-element subset, perform a random mutation to obtain a new solution. 3)For each two-element subset, perform a randomized crossover operation to obtain a new solution that reflects both parents. 4)Let P’ be the set of solutions generated by (2) and (3), after first applying algorithm A to each. 5)Using a selection strategy, choose k survivors from P ∪ P’ and replace P by these survivors. 4.Return the best solution in P. New.")
44
Advantages and Disadvantages + We can use Lin-Kernighan as the local optimization algorithm. Presumably we will get better tours than for basic Lin-Kernighan. - For a reasonably population size, we will need to perform lots of LK’s. Is this the most cost-effective way of investing all that extra time? - We still have the problem of the ad-hoc crossover to contend with. In 1989, Martin, Otto, & Felten suggested a way to remove both drawbacks. (Their paper was published as [“Large-step Markov chains for the TSP incorporating local search heuristics,” Complex Systems 5 (1991), 299-326].)
, ].).")
45
Martin, Otto, & Felten’s Approach Set population size to 1. Only do mutations (no matings). For the mutation, perform a random double- bridge 4-opt move. Note that, although this was originally viewed in the context of genetic algorithms, there is little left that is genetic about it. The common name for this approach (using Lin-Kernighan) is now – “Iterated Lin-Kernighan” or – “Chained Lin-Kernighan.”
. For the mutation, perform a random double- bridge 4-opt move. Note that, although this was originally viewed in the context of genetic algorithms, there is little left that is genetic about it. The common name for this approach (using Lin-Kernighan) is now – Iterated Lin-Kernighan or – Chained Lin-Kernighan. .")
46
Advantages of Iterated Lin-Kernighan Minimal extra programming needed to turn a local search heuristic into an iterated local search heuristic. Preprocessing is amortized (although this is true of multiple- independent-run LK as well). After the first run of LK, subsequent ones are all much faster, since they start with all but 8 don’t-look-bits still on. The damage done to the tour by just changing 4 edges still turns out to open up significant room for LK to find new improvements. Surprisingly good performance.
. After the first run of LK, subsequent ones are all much faster, since they start with all but 8 don’t-look-bits still on. The damage done to the tour by just changing 4 edges still turns out to open up significant room for LK to find new improvements. Surprisingly good performance..")
47
Random Euclidean Instances.96 1704 3.06 Ghz Intel Core i3 processor

48
Random Euclidean Instances

49
Selected TSPLIB Instances Except for instance fl3795, ILK(N) is always within 0.05% – 0.25% of optimal.
 is always within 0.05% – 0.25% of optimal.")
50
TSPLIB Instance fl3795 ILK(N), 20 nearest neighbors: 4.33% excess (1080 seconds, 3.06 Ghz processor) ILK(N), 20 quad neighbors: 1.09% excess ( 205 seconds, 3.06 Ghz processor)* *Average of three runs, one of which found the optimal and a second found optimal + 1.
, 20 nearest neighbors: 4.33% excess (1080 seconds, 3.06 Ghz processor) ILK(N), 20 quad neighbors: 1.09% excess ( 205 seconds, 3.06 Ghz processor)* *Average of three runs, one of which found the optimal and a second found optimal + 1.")
51
Random Distance Matrices

52
Beating Iterated Lin-Kernighan Chained Lin-Kernighan [Applegate, Cook, & Rohe, “Chained Lin-Kernighan for large traveling salesman problems,” INFORMS J. Comput. 15 (2003), 82-92 ] Broader and deeper search before LK-searches, More selective in choices of double-bridge moves (mixture of greedier choices, random walks, etc.) Hybrid Genetic Algorithm [Nguyen, Yoshihara, Yamamori, and Yasunaga, “Implementation of an effective hybrid GA for large-scale traveling salesman problems,” IEEE Trans. Syst., Man, Cybernetics B37 (2007), 92- 99] Genetic algorithm with crossovers + mutations + Lin-Kernighan, and large running times for bigger instances. Helsgaun’s algorithm [Helsgaun, “An effective implementation of the Lin- Kernighan traveling salesman heuristic,” European J. Oper. Res. 126 (2000), 106-130. Source code available at http://www.dat.ruk.dk/~keld/ ] http://www.dat.ruk.dk/~keld/ Different restart mechanism, broader initial search, … Tour merging [Cook & Seymour, “Tour merging via branch-decomposition,” INFORMS J. Comput. 15 (2003), 233-248]
, ] Broader and deeper search before LK-searches, More selective in choices of double-bridge moves (mixture of greedier choices, random walks, etc.) Hybrid Genetic Algorithm [Nguyen, Yoshihara, Yamamori, and Yasunaga, Implementation of an effective hybrid GA for large-scale traveling salesman problems, IEEE Trans. Syst., Man, Cybernetics B37 (2007), ] Genetic algorithm with crossovers + mutations + Lin-Kernighan, and large running times for bigger instances. Helsgaun’s algorithm [Helsgaun, An effective implementation of the Lin- Kernighan traveling salesman heuristic, European J. Oper. Res. 126 (2000), Source code available at ] Different restart mechanism, broader initial search, … Tour merging [Cook & Seymour, Tour merging via branch-decomposition, INFORMS J. Comput. 15 (2003), ].")
55
Random Distance Matrices N = 1000 3162 10,000 % Excess of HK boundSeconds on a 500 Mhz DEC Alpha Note: Helsgaun’s algorithm is the only heuristic we’ve seen that is not fazed by these instances.

56
Heuristics for the Asymmetric TSP (a quick tour) Tour Construction: Asymmetric Nearest Neighbor Asymmetric Greedy Match & Patch (Compute minimum-cost cycle cover, repeatedly patch together the two largest cyles) Contract or Patch Repeated Assignment Zhang’s Algorithm (Truncated Branch & Bound) Local Optimization: Asymmetric 3-Opt Iterated 3-Opt Kanellakis-Papadimitriou (Mimics Lin-Kernighan, and also uses “best double-bridge move” as a component) Helsgaun (Convert to symmetric instance and apply Helsgaun’s algorithm.
 Tour Construction: Asymmetric Nearest Neighbor Asymmetric Greedy Match & Patch (Compute minimum-cost cycle cover, repeatedly patch together the two largest cyles) Contract or Patch Repeated Assignment Zhang’s Algorithm (Truncated Branch & Bound) Local Optimization: Asymmetric 3-Opt Iterated 3-Opt Kanellakis-Papadimitriou (Mimics Lin-Kernighan, and also uses best double-bridge move as a component) Helsgaun (Convert to symmetric instance and apply Helsgaun’s algorithm.")
57
Matching-and-Patch

58
Contract-or-Patch Once all 2-cycles are removed, proceed as in Match & Patch.

59
Repeated Assignment Delete all but one city from each cycle, find new matching, and repeat. Theorem [Frieze, Galbiati, & Maffioli (1982]: Assuming Δ- Inequality, RA(I) ≤ log(N)OPT(I). The union of all the matching edges is a connected graph in which every vertex has equal in- and out-degrees. So there is an Euler tour. If we assume the Δ- Inequality, the Euler tour can be traversed using shortcuts at no extra cost. Each matching is no longer than an optimal tour, again by the triangle inequality. Since each matching involves no more than half the previous number of vertices, we have:
 ≤ log(N)OPT(I). The union of all the matching edges is a connected graph in which every vertex has equal in- and out-degrees. So there is an Euler tour. If we assume the Δ- Inequality, the Euler tour can be traversed using shortcuts at no extra cost. Each matching is no longer than an optimal tour, again by the triangle inequality. Since each matching involves no more than half the previous number of vertices, we have:.")
60
Heuristics for the Asymmetric TSP (a quick tour) Tour Construction: Asymmetric Nearest Neighbor Asymmetric Greedy Match & Patch (Compute minimum-cost cycle cover, repeatedly patch together the two largest cyles) Contract or Patch Repeated Assignment Zhang’s Algorithm (Truncated Branch & Bound) Local Optimization: Asymmetric 3-Opt (Only 3-opt moves that cause no reversals) Iterated Asymmetric 3-Opt Kanellakis-Papadimitriou (Mimics Lin-Kernighan, and also uses “best double-bridge move” as a component) Helsgaun (Convert to symmetric instance and apply Helsgaun’s algorithm.
 Tour Construction: Asymmetric Nearest Neighbor Asymmetric Greedy Match & Patch (Compute minimum-cost cycle cover, repeatedly patch together the two largest cyles) Contract or Patch Repeated Assignment Zhang’s Algorithm (Truncated Branch & Bound) Local Optimization: Asymmetric 3-Opt (Only 3-opt moves that cause no reversals) Iterated Asymmetric 3-Opt Kanellakis-Papadimitriou (Mimics Lin-Kernighan, and also uses best double-bridge move as a component) Helsgaun (Convert to symmetric instance and apply Helsgaun’s algorithm.")
61
Results for Instance Generators of [Cirasella, Johnson, McGeoch, & Zhang, “The asymmetric traveling salesman problem: Algorithms, instance generators, and tests,” ALENEX 2001, Lecture Notes in Computer Science 2153, Springer, pp. 32-59]

62
The Coin Collection Problem

63
The Stacker-Crane Problem

64
The No-Wait Shop Scheduling Problem

65
The Disk Scheduling Problem

66
The Shortest Common Superstring Problem

67
The Drilling on a Tilted Table Problem

68
Next Time Optimization Algorithms

Similar presentations








>")











 Given n £ n positive distance matrix (d ij ) find permutation on {0,1,2,..,n-1} minimizing i=0 n-1 d (i), (i+1.>")


