Download presentation
Presentation is loading. Please wait.

2
2 Less fish … More fish! Parallelism means doing multiple things at the same time: you can get more work done in the same time.

3
3

4
4 Suppose you want to do a jigsaw puzzle that has, say, a thousand pieces. We can imagine that it’ll take you a certain amount of time. Let’s say that you can put the puzzle together in an hour.

5
5 If Scott sits across the table from you, then he can work on his half of the puzzle and you can work on yours. Once in a while, you’ll both reach into the pile of pieces at the same time (you’ll contend for the same resource), which will cause a little bit of slowdown. And from time to time you’ll have to work together (communicate) at the interface between his half and yours. The speedup will be nearly 2-to-1: y’all might take 35 minutes instead of 30.
, which will cause a little bit of slowdown. And from time to time you’ll have to work together (communicate) at the interface between his half and yours. The speedup will be nearly 2-to-1: y’all might take 35 minutes instead of 30..")
6
6 Now let’s put Paul and Charlie on the other two sides of the table. Each of you can work on a part of the puzzle, but there’ll be a lot more contention for the shared resource (the pile of puzzle pieces) and a lot more communication at the interfaces. So y’all will get noticeably less than a 4-to-1 speedup, but you’ll still have an improvement, maybe something like 3-to-1: the four of you can get it done in 20 minutes instead of an hour.
 and a lot more communication at the interfaces. So y’all will get noticeably less than a 4-to-1 speedup, but you’ll still have an improvement, maybe something like 3-to-1: the four of you can get it done in 20 minutes instead of an hour..")
7
7 If we now put Dave and Tom and Kate and Brandon on the corners of the table, there’s going to be a whole lot of contention for the shared resource, and a lot of communication at the many interfaces. So the speedup y’all get will be much less than we’d like; you’ll be lucky to get 5-to-1. So we can see that adding more and more workers onto a shared resource is eventually going to have a diminishing return.

8
8 Now let’s try something a little different. Let’s set up two tables, and let’s put you at one of them and Scott at the other. Let’s put half of the puzzle pieces on your table and the other half of the pieces on Scott’s. Now y’all can work completely independently, without any contention for a shared resource. BUT, the cost per communication is MUCH higher (you have to scootch your tables together), and you need the ability to split up (decompose) the puzzle pieces reasonably evenly, which may be tricky to do for some puzzles.
, and you need the ability to split up (decompose) the puzzle pieces reasonably evenly, which may be tricky to do for some puzzles..")
9
9 It’s a lot easier to add more processors in distributed parallelism. But, you always have to be aware of the need to decompose the problem and to communicate among the processors. Also, as you add more processors, it may be harder to load balance the amount of work that each processor gets.

10
10 Load balancing means ensuring that everyone completes their workload at roughly the same time. For example, if the jigsaw puzzle is half grass and half sky, then you can do the grass and Scott can do the sky, and then y’all only have to communicate at the horizon – and the amount of work that each of you does on your own is roughly equal. So you’ll get pretty good speedup.

11
11 Load balancing can be easy, if the problem splits up into chunks of roughly equal size, with one chunk per processor. Or load balancing can be very hard. EASY HARD

12
Parallel computation = set of tasks Task ◦ Program ◦ Local memory ◦ Collection of I/O ports Tasks interact by sending messages through channels

13
Task Channel

14
Partitioning ◦ Dividing the Problem into Tasks Communication ◦ Determine what needs to be communicated between the Tasks over Channels Agglomeration ◦ Group or Consolidate Tasks to improve efficiency or simplify the programming solution Mapping ◦ Assign tasks to the Computer Processors 14

16
Domain/Data Decomposition – Data Centric Approach ◦ Divide up most frequently used data ◦ Associate the computations with the divided data Functional/Task Decomposition – Computation Centric Approach ◦ Divide up the computation ◦ Associate the data with the divided computations Primitive Tasks: Resulting Pieces from either Decomposition ◦ The goal is to have as many of these as possible

17
Task Decomposition Decompose a problem by the functions it performs Gardening analogy –Need to mow and weed –Two gardeners One mows One weeds –Need to synchronize a bit so we don’t weed the spot in the yard that is currently being mowed

18
Data Decomposition Decompose problem by the data worked on Gardening analogy –Need to mow and weed –Two gardeners Each mows and weeds ½ the yard –Each gets its own part of the yard, so less synchronization between mowing/weeding –However Gardeners can’t be specialized Contention for resources (single mower)
")
19
Scaling Task –Adding 8 more gardeners is only beneficial if: there are 8 more tasks (raking, blowing, etc) Data –Adding 8 more gardeners is only beneficial if: there are enough mowers for everyone the yard is big enough that the time it takes to get the mower out is worth it for the size mowed
 Data –Adding 8 more gardeners is only beneficial if: there are enough mowers for everyone the yard is big enough that the time it takes to get the mower out is worth it for the size mowed")
20
Hybrid Approaches Can combine both approaches –Gardener1 can mow/weed ½ the yard –Gardener2 can mow/weed ½ the yard –Gardener3 can rake/blow ½ the yard –Gardener4 can rake/blow ½ the yard

23
Lots of Tasks ◦ e.g, at least 10x more primitive tasks than processors in target computer Minimize redundant computations and data Load Balancing ◦ Primitive tasks roughly the same size Scalable ◦ Number of tasks an increasing function of problem size

24
Local Communication ◦ When Tasks need data from a small number of other Tasks ◦ Channel from Producing Task to Consuming Task Created Global Communication ◦ When Task need data from many or all other Tasks ◦ Channels for this type of communication are not created during this step

25
Balanced ◦ Communication operations balanced among tasks Small degree ◦ Each task communicates with only small group of neighbors Concurrency ◦ Tasks can perform communications concurrently ◦ Task can perform computations concurrently

26
Increase Locality ◦ remove communication by agglomerating Tasks that Communicate with one another ◦ Combine groups of sending & receiving task Send fewer, larger messages rather than more short messages which incur more message latency. Maintain Scalability of the Parallel Design ◦ Be careful not to agglomerate Tasks so much that moving to a machine with more processors will not be possible Reduce Software Engineering costs ◦ Leveraging existing sequential code can reduce the expense of engineering a parallel algorithm

27
Eliminate communication between primitive tasks agglomerated into consolidated task Combine groups of sending and receiving tasks

28
Locality of parallel algorithm has increased Tradeoff between agglomeration and code modifications costs is reasonable Agglomerated tasks have similar computational and communications costs Number of tasks increases with problem size Number of tasks suitable for likely target systems

29
Maximize Processor Utilization ◦ Ensure computation is evenly balanced across all processors Minimize Interprocess Communication 29

30
Finding optimal mapping is NP-hard Must rely on heuristics

32
Mapping based on one task per processor and multiple tasks per processor have been considered Both static and dynamic allocation of tasks to processors have been evaluated If a dynamic allocation of tasks to processors is chosen, the Task allocator is not a bottleneck If Static allocation of tasks to processors is chosen, the ratio of tasks to processors is at least 10 to 1 32

33
Boundary value problem Finding the maximum The n-body problem Adding data input

34
Ice waterRodInsulation

37
One data item per grid point Associate one primitive task with each grid point Two-dimensional domain decomposition

38
Identify communication pattern between primitive tasks: ◦ Each interior primitive task has three incoming and three outgoing channels

39
Agglomeration

40
– time to update element n – number of elements m – number of iterations Sequential execution time: mn p – number of processors – message latency Parallel execution time m( n/p +2 )
")
41
6.25%

42
Given associative operator a0 a1 a2 … an-1 Examples ◦ Add ◦ Multiply ◦ And, Or ◦ Maximum, Minimum

46
Subgraph of hypercube

47
4207 -35-6-3 8123 -446

48
17-64 4582

49
8-2 910

50
178

51
25 Binomial Tree

53
sum

56
Domain partitioning Assume one task per particle Task has particle’s position, velocity vector Iteration ◦ Get positions of all other particles ◦ Compute new position, velocity

61
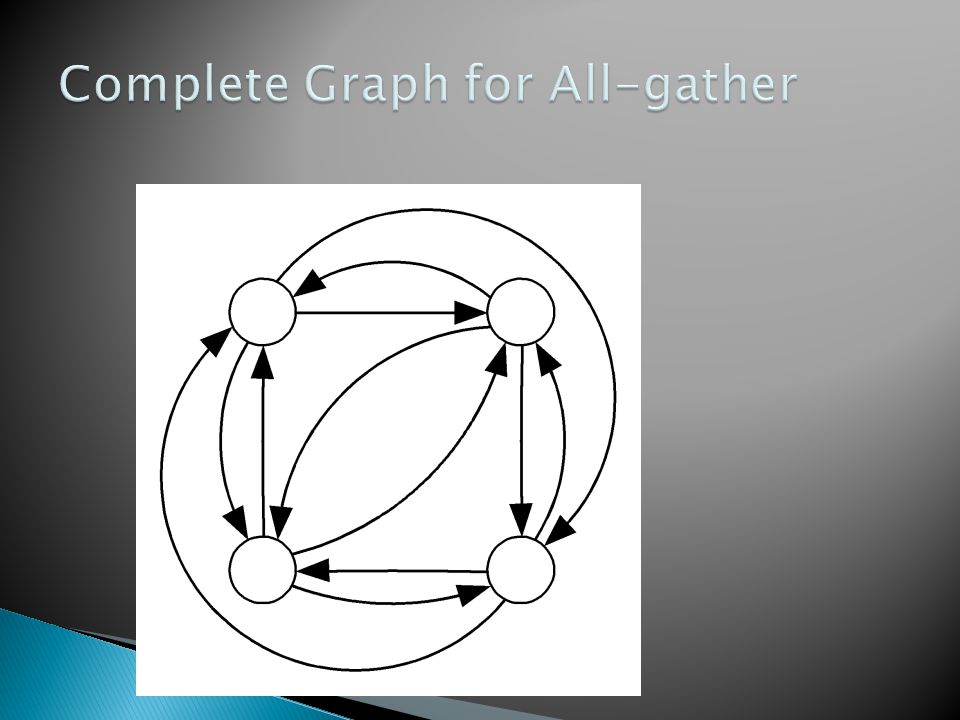
Hypercube Complete graph

64
12345678 567812345612 7834

65
Parallel computation ◦ Set of tasks ◦ Interactions through channels Good designs ◦ Maximize local computations ◦ Minimize communications ◦ Scale up

66
Partition computation Agglomerate tasks Map tasks to processors Goals ◦ Maximize processor utilization ◦ Minimize inter-processor communication

67
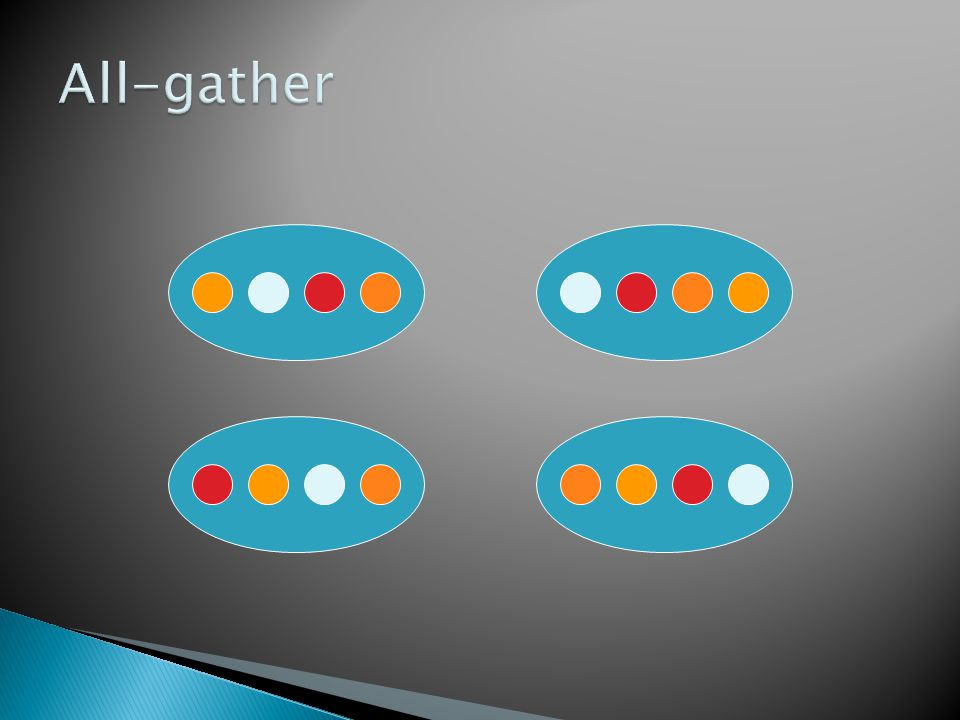
Reduction Gather and scatter All-gather

Similar presentations



















. One of the functions.>")
 S is the set of all feasible solutions f is the cost.>")















